Reasoning as Intersection: Consensus-Frame Alignment for Visual Focus in Video-MLLMs
Pith reviewed 2026-06-27 00:59 UTC · model grok-4.3
The pith
A consensus frame prior built from intrinsic video cues provides a high-contrast reward that aligns Video-MLLMs to relevant evidence without human temporal labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
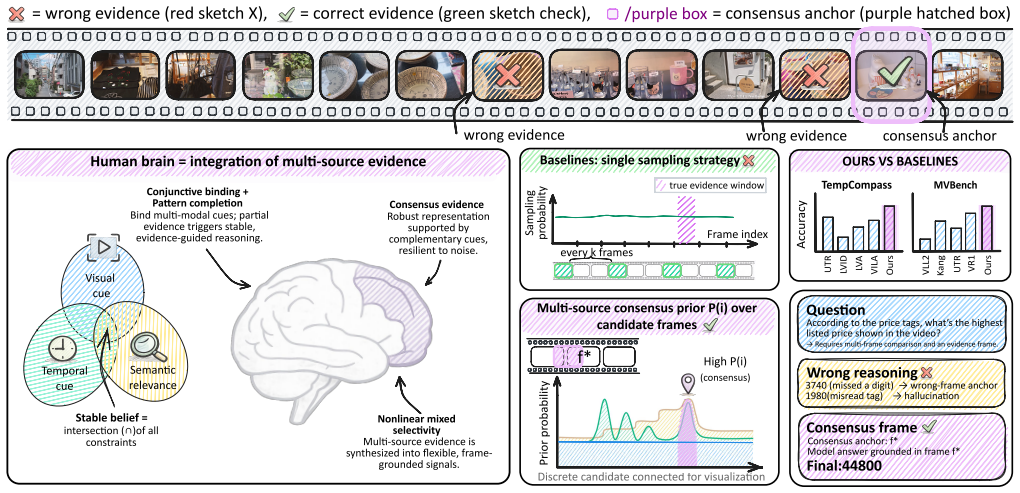
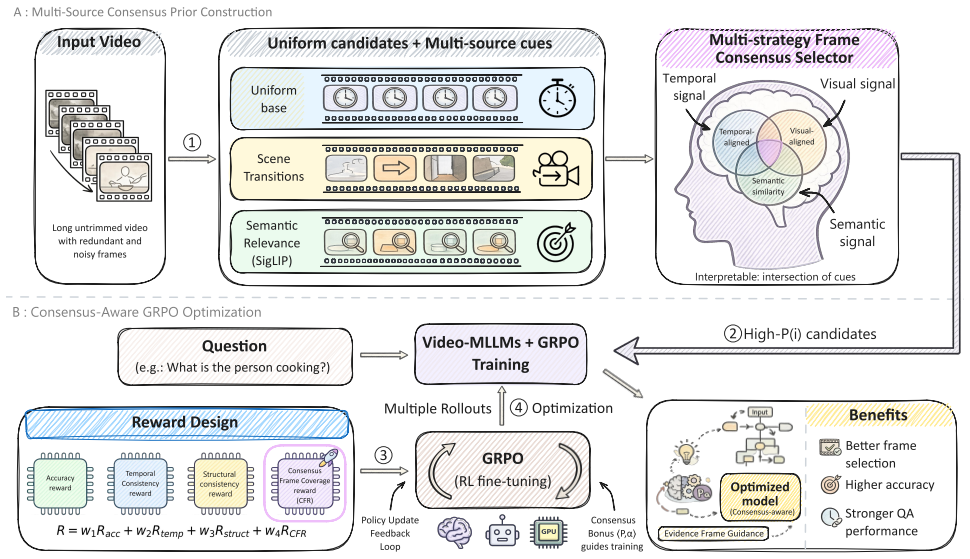
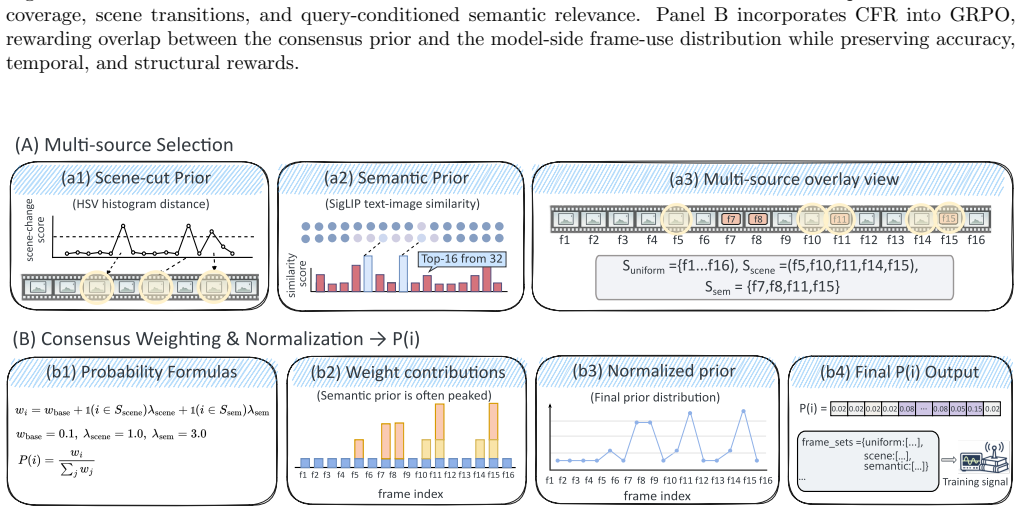
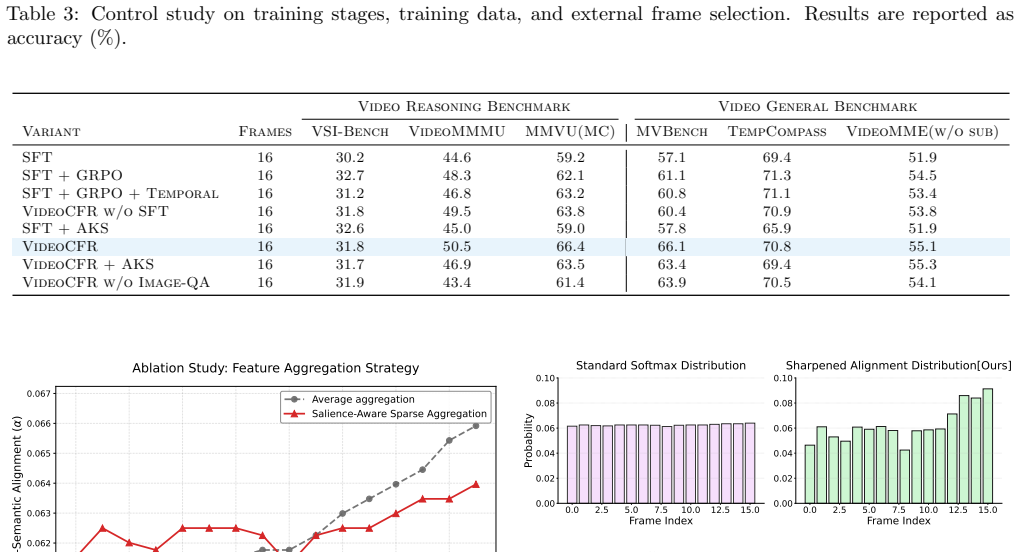
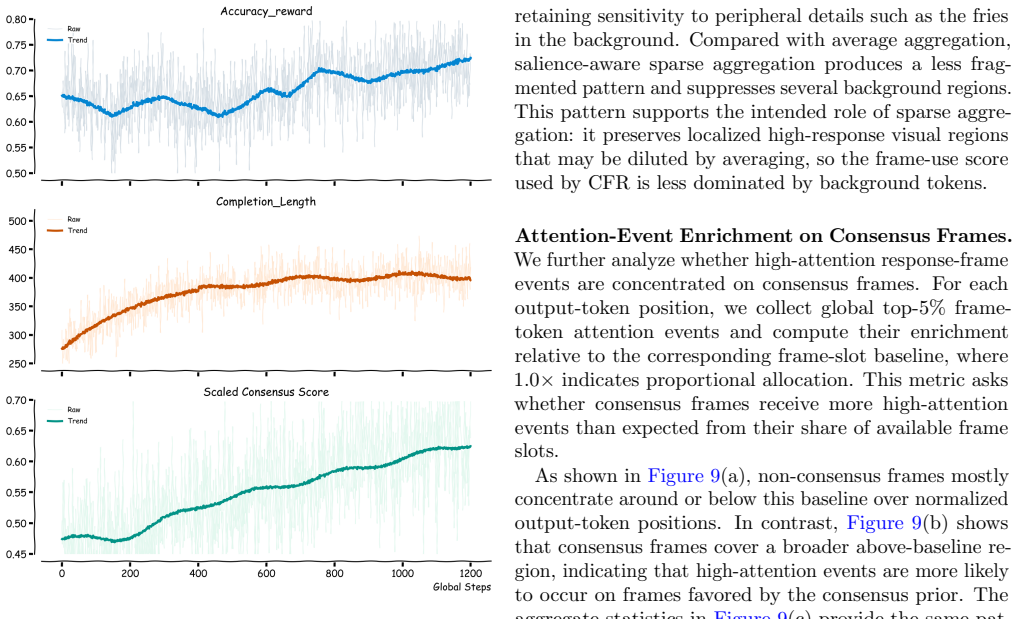
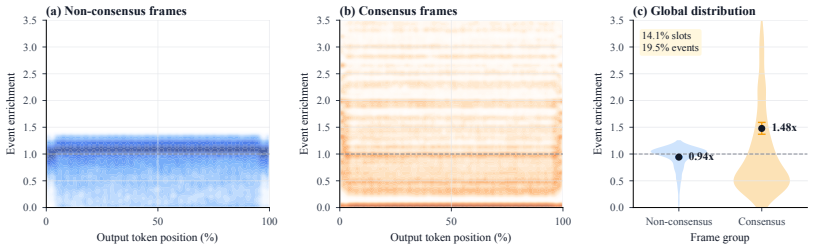
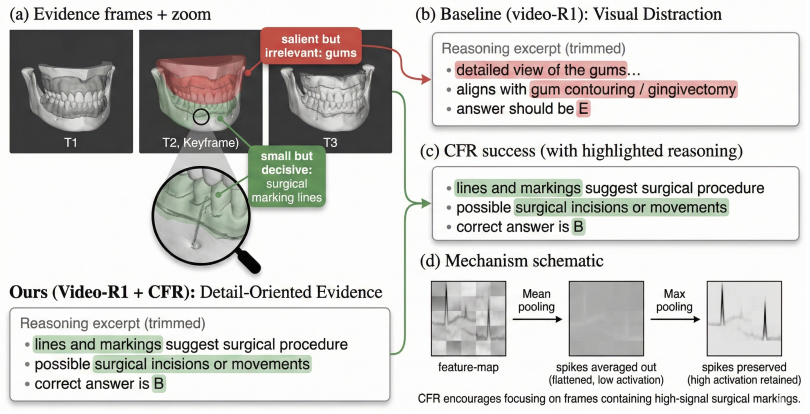
CF-GRPO constructs a consensus frame prior from intrinsic video cues, including temporal coverage, scene-transition cues, and query-conditioned visual relevance. It then computes a model-side frame-use score from visual and response representations and optimizes their agreement through the Consensus Frame Reward (CFR). With salience-aware sparse aggregation and distribution sharpening, CFR supplies a high-contrast reward signal that improves evidence-aware reasoning without any human temporal annotations.
What carries the argument
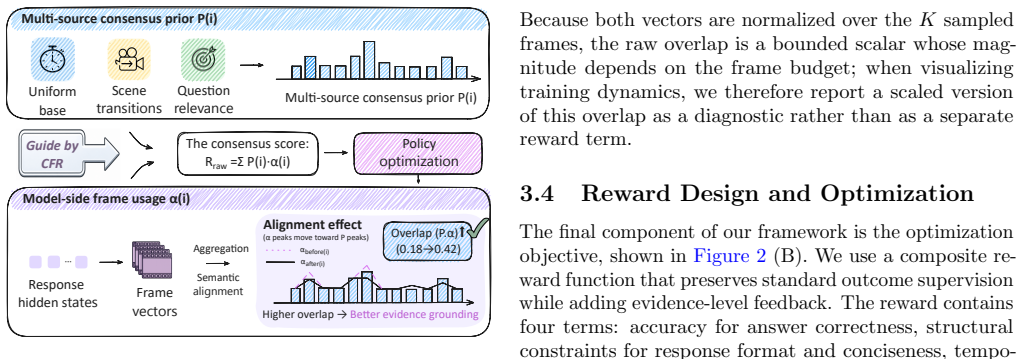
The Consensus Frame Reward (CFR), which measures and reinforces agreement between an intrinsic consensus frame prior and the model's learned frame-use distribution.
If this is right
- Video-MLLMs trained with CFR achieve competitive accuracy on complex video reasoning benchmarks.
- Several evaluation metrics improve relative to representative Video-MLLM and RL baselines.
- The consensus prior yields an interpretable record of which frames the model is encouraged to emphasize.
- No human temporal annotations are required at any stage of training.
Where Pith is reading between the lines
- The same intrinsic-cue construction could be tested on longer videos or multi-shot clips to check whether scene-transition detection remains reliable.
- If CFR is removed after training, one could measure whether the model retains the learned focus or reverts to uniform attention.
- The method could be extended to audio or subtitle cues to see whether adding another modality to the prior further sharpens the reward.
Load-bearing premise
Intrinsic video cues alone are enough to identify the exact frames that support a correct reasoning answer.
What would settle it
Replace the consensus prior with frames chosen uniformly at random and measure whether CFR training still improves accuracy or frame alignment over the outcome-only baseline.
Figures



read the original abstract
Reinforcement learning has improved the reasoning ability of large language models, but applying outcome-only rewards to video multimodal large language models (Video-MLLMs) provides limited guidance on which visual evidence should support the answer. Inspired by multisensory integration, where consistent cues can enhance the salience and reliability of perceptual estimates, we introduce Consensus Frame GRPO (CF-GRPO), a temporal-annotation-free process-level reward framework for evidence-aware video reasoning. CF-GRPO constructs a consensus frame prior from intrinsic video cues, including temporal coverage, scene-transition cues, and query-conditioned visual relevance. It then computes a model-side frame-use score from visual and response representations and optimizes their agreement through the Consensus Frame Reward (CFR). With salience-aware sparse aggregation and distribution sharpening, CFR provides a high-contrast reward signal without requiring human temporal annotations. Experiments show that VideoCFR achieves competitive performance across complex video reasoning benchmarks and improves several metrics over representative Video-MLLM and RL baselines, while the consensus prior provides an interpretable view of the evidence frames emphasized during training. The implementation is available at https://github.com/1Pansy/VideoCFR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Consensus Frame GRPO (CF-GRPO), a temporal-annotation-free RL framework for Video-MLLMs. It builds a consensus frame prior from intrinsic cues (temporal coverage, scene-transition cues, query-conditioned visual relevance), computes model-side frame-use scores from visual/response representations, and optimizes their agreement via the Consensus Frame Reward (CFR) augmented with salience-aware sparse aggregation and distribution sharpening. Experiments report competitive performance on complex video reasoning benchmarks, metric improvements over baselines, and an interpretable view of emphasized evidence frames.
Significance. If the central assumption holds, the work offers a practical route to process-level supervision for evidence-aware video reasoning without human temporal labels, potentially improving both performance and interpretability in Video-MLLMs. The annotation-free construction and high-contrast reward signal are notable strengths if the prior can be shown to align with reasoning-needed frames.
major comments (3)
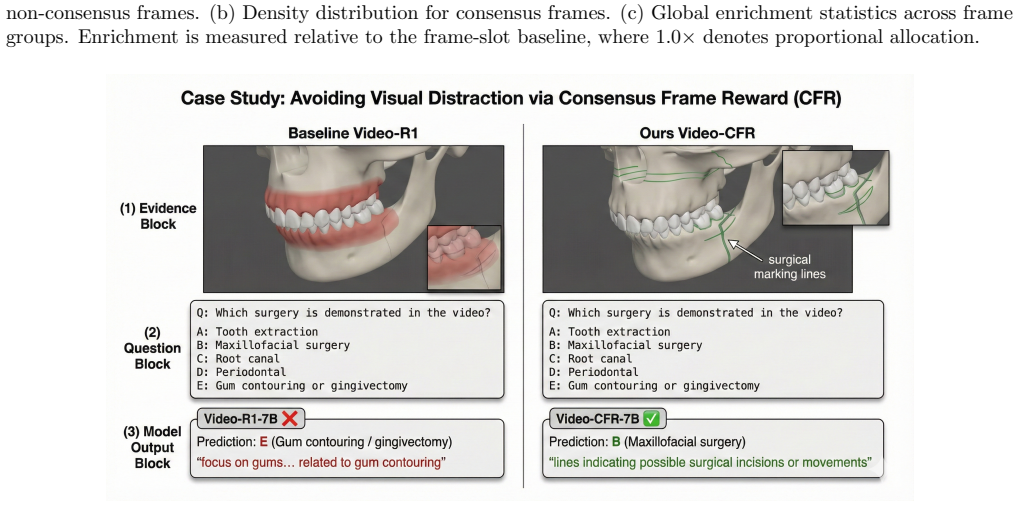
- [Method and Experiments] The manuscript provides no independent validation (human overlap, oracle frame comparison, or failure-case analysis) that the consensus prior accurately identifies frames supporting correct answers. This is load-bearing for the central claim because CFR is defined directly from the prior; without such a check, reported gains could arise solely from salience-aware aggregation or sharpening rather than evidence alignment (§3, Experiments).
- [Experiments] No ablation results are reported on the individual intrinsic cues (temporal coverage, scene-transition, query-conditioned relevance) or on the CFR components. This leaves unclear whether the consensus construction is necessary or if simpler salience mechanisms suffice (Experiments section).
- [Method] The abstract and method description omit quantitative details on prior/reward computation (exact formulas, weighting of cues, any learned parameters) and report no error bars or statistical significance tests, weakening support for the performance claims.
minor comments (2)
- [Method] Notation for frame-use score and CFR should be introduced with explicit equations rather than descriptive text only.
- [Experiments] Figure captions and table headers could more clearly distinguish baseline variants from the proposed VideoCFR model.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Method and Experiments] The manuscript provides no independent validation (human overlap, oracle frame comparison, or failure-case analysis) that the consensus prior accurately identifies frames supporting correct answers. This is load-bearing for the central claim because CFR is defined directly from the prior; without such a check, reported gains could arise solely from salience-aware aggregation or sharpening rather than evidence alignment (§3, Experiments).
Authors: We agree that direct validation of the consensus prior would strengthen the central claim. The reported gains are tied to the full CFR construction, but we acknowledge the possibility that aggregation and sharpening contribute independently. In revision we will add failure-case analysis and oracle-frame comparisons (using existing benchmark answer alignments where available) to the Experiments section. A new human-overlap study is not feasible within the current scope and is noted as future work; we will clarify this limitation explicitly. revision: partial
-
Referee: [Experiments] No ablation results are reported on the individual intrinsic cues (temporal coverage, scene-transition, query-conditioned relevance) or on the CFR components. This leaves unclear whether the consensus construction is necessary or if simpler salience mechanisms suffice (Experiments section).
Authors: We accept this criticism. The revised manuscript will include a dedicated ablation study that isolates each cue and each CFR component (salience-aware sparse aggregation and distribution sharpening). These results will be added to the Experiments section to demonstrate necessity of the full consensus construction. revision: yes
-
Referee: [Method] The abstract and method description omit quantitative details on prior/reward computation (exact formulas, weighting of cues, any learned parameters) and report no error bars or statistical significance tests, weakening support for the performance claims.
Authors: We will expand the Method section with the precise formulas for consensus-prior construction, the fixed heuristic weights for each cue, and the CFR computation. No learned parameters are used. We will also report standard deviations across multiple random seeds and include statistical significance tests for the main performance comparisons in the revised Experiments section. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper defines the consensus frame prior from explicit intrinsic cues (temporal coverage, scene transitions, query-conditioned relevance) and constructs the CFR as an agreement measure between this prior and separately computed model-side frame-use scores, followed by salience-aware aggregation. No equations, self-citations, or steps are presented that reduce the reward signal, predictions, or central claims to fitted parameters or prior results by construction. The annotation-free design and experimental performance claims rest on the independent construction of the prior rather than tautological redefinition or load-bearing self-citation. This matches the default case of a self-contained method without circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intrinsic video cues (temporal coverage, scene transitions, query-conditioned relevance) are sufficient to form a reliable consensus frame prior for reasoning tasks.
Reference graph
Works this paper leans on
-
[1]
Training language models to follow in- structions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wain- wright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow in- structions with human feedback,”Advances in Neural Information Processing Systems, vol. 35, pp. 27 730– 27 744, 2022
2022
-
[2]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. K. Li, Y. Wu, and D. Guo, “DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Video-R1: Reinforcing video reasoning in MLLMs,
K. Feng, K. Gong, B. Li, Z. Guo, Y. Wang, T. Peng, J. Wu, X. Zhang, B. Wang, and X. Yue, “Video-R1: Reinforcing video reasoning in MLLMs,” inAdvances in Neural Information Processing Systems, vol. 38, 2025
2025
-
[4]
DeepVideo- R1: Video reinforcement fine-tuning via difficulty- aware regressive GRPO,
J. Park, J. Na, J. Kim, and H. J. Kim, “DeepVideo- R1: Video reinforcement fine-tuning via difficulty- aware regressive GRPO,” inAdvances in Neural In- formation Processing Systems, vol. 38, 2025
2025
-
[5]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
X. Li, Z. Yan, D. Meng, L. Dong, X. Zeng, Y. He, Y. Wang, Y. Qiao, Y. Wang, and L. Wang, “VideoChat-R1: Enhancing spatio-temporal percep- tion via reinforcement fine-tuning,”arXiv preprint arXiv:2504.06958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Videorft: Incentivizing video reasoning capability in mllms via reinforced fine-tuning,
Q. Wang, Y. Yu, Y. Yuan, R. Mao, and T. Zhou, “VideoRFT: Incentivizing video reasoning capability in MLLMs via reinforced fine-tuning,”arXiv preprint arXiv:2505.12434, 2025
-
[7]
Reinforcement learning tuning for videollms: Reward design and data efficiency,
H. Li, S. Han, Y. Liao, J. Luo, J. Gao, S. Yan, and S. Liu, “Reinforcement learning tuning for Vide- oLLMs: Reward design and data efficiency,”arXiv preprint arXiv:2506.01908, 2025
-
[8]
Incentivizing versatile video reasoning in MLLMs via data-efficient reinforcement learning,
X. Wang, Z. Wu, L. Huang, Y. Zheng, and P. Peng, “Incentivizing versatile video reasoning in MLLMs via data-efficient reinforcement learning,” inProceedings 13 of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 5444–5454
2026
-
[9]
Thinking with videos: Multimodal tool-augmented reinforce- ment learning for long video reasoning,
H. Zhang, X. Gu, J. Li, C. Ma, S. Bai, C. Zhang, B. Zhang, Z. Zhou, D. He, and Y. Tang, “Thinking with videos: Multimodal tool-augmented reinforce- ment learning for long video reasoning,” inProceed- ings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), June 2026, pp. 32 903–32 914
2026
-
[10]
Adaptive keyframe sampling for long video under- standing,
X. Tang, J. Qiu, L. Xie, Y. Tian, J. Jiao, and Q. Ye, “Adaptive keyframe sampling for long video under- standing,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 29 118–29 128
2025
-
[11]
arXiv preprint arXiv:2510.27280 , year=
Z. Zhu, H. Xu, Y. Luo, Y. Liu, K. Sarkar, Z. Yang, and Y. You, “FOCUS: Efficient keyframe selec- tion for long video understanding,”arXiv preprint arXiv:2510.27280, 2025
-
[12]
Se- ViCES: Unifying semantic-visual evidence consen- sus for long video understanding,
Y. Sheng, Y. Hao, C. Li, S. Wang, and X. He, “Se- ViCES: Unifying semantic-visual evidence consen- sus for long video understanding,”arXiv preprint arXiv:2510.20622, 2025
-
[13]
Efficient frame se- lection for long video understanding via reinforcement learning,
Y. Qin, H. Li, W. Mu, and Y. He, “Efficient frame se- lection for long video understanding via reinforcement learning,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 16 944–16 953
2026
-
[14]
MARC: Memory-augmented RL token compression for efficient video understanding,
P. Wu, Z. Yu, Y. Liu, C.-H. Wu, E. Zhou, and J. Shen, “MARC: Memory-augmented RL token compression for efficient video understanding,” inInternational Conference on Learning Representations, 2026
2026
-
[15]
SpaceVLLM: Endowing multimodal large language model with spatio-temporal video grounding capability,
J. Wang, Z. Zhang, Z. Liu, Y. Li, J. Ge, H. Xie, and Y. Zhang, “SpaceVLLM: Endowing multimodal large language model with spatio-temporal video grounding capability,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 12, 2026, pp. 9912–9920
2026
-
[16]
Multisensory inte- gration: Current issues from the perspective of the single neuron,
B. E. Stein and T. R. Stanford, “Multisensory inte- gration: Current issues from the perspective of the single neuron,”Nature Reviews Neuroscience, vol. 9, no. 4, pp. 255–266, 2008
2008
-
[17]
Humans integrate visual and haptic information in a statistically opti- mal fashion,
M. O. Ernst and M. S. Banks, “Humans integrate visual and haptic information in a statistically opti- mal fashion,”Nature, vol. 415, no. 6870, pp. 429–433, 2002
2002
-
[18]
The ventriloquist effect results from near-optimal bimodal integration,
D. Alais and D. Burr, “The ventriloquist effect results from near-optimal bimodal integration,”Current Bi- ology, vol. 14, no. 3, pp. 257–262, 2004
2004
-
[19]
The bayesian brain: The role of uncertainty in neural coding and computation,
D. C. Knill and A. Pouget, “The bayesian brain: The role of uncertainty in neural coding and computation,” Trends in Neurosciences, vol. 27, no. 12, pp. 712–719, 2004
2004
-
[20]
Solving math word problems with process- and outcome-based feedback
J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins, “Solv- ing math word problems with process- and outcome- based feedback,”arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Let’s verify step by step,
H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,” inIn- ternational Conference on Learning Representations, 2024
2024
-
[22]
VisualPRM: An effective process reward model for multimodal rea- soning,
W. Wang, Z. Gao, L. Chen, Z. Chen, J. Zhu, X. Zhao, Y. Liu, Y. Cao, S. Ye, X. Zhu, L. Lu, H. Duan, Y. Qiao, J. Dai, and W. Wang, “VisualPRM: An effective process reward model for multimodal rea- soning,”arXiv preprint arXiv:2503.10291, 2025
-
[23]
Perceptual-evidence anchored reinforced learning for multimodal reason- ing,
C. Zhang, H. Qiu, Q. Zhang, Y. Xu, Z. Zeng, S. Yang, P. Shi, L. Ma, and J. Zhang, “Perceptual-evidence anchored reinforced learning for multimodal reason- ing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 41 111–41 120
2026
-
[24]
Tinyllava- video-r1: Towards smaller lmms for video reasoning,
X. Zhang, S. Wen, W. Wu, and L. Huang, “TinyLLaVA-Video-R1: Towards smaller LMMs for video reasoning,”arXiv preprint arXiv:2504.09641, 2025
-
[25]
Unhackable temporal rewarding for scalable video mllms,
E. Yu, K. Lin, L. Zhao, Y. Wei, Z. Zhu, H. Wei, J. Sun, Z. Ge, X. Zhang, J. Wanget al., “Unhack- able temporal rewarding for scalable video MLLMs,” arXiv preprint arXiv:2502.12081, 2025
-
[26]
LLaMA-VID: An image is worth 2 tokens in large language models,
Y. Li, C. Wang, and J. Jia, “LLaMA-VID: An image is worth 2 tokens in large language models,” inEu- ropean Conference on Computer Vision. Springer, 2024, pp. 323–340
2024
-
[27]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Z. Cheng, S. Leng, H. Zhang, Y. Xin, X. Li, G. Chen, Y. Zhu, W. Zhang, Z. Luo, D. Zhaoet al., “VideoL- LaMA 2: Advancing spatial-temporal modeling and audio understanding in Video-LLMs,”arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Long Context Transfer from Language to Vision
P. Zhang, K. Zhang, B. Li, G. Zeng, J. Yang, Y. Zhang, Z. Wang, H. Tan, C. Li, and Z. Liu, “Long context transfer from language to vision,”arXiv preprint arXiv:2406.16852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
LLaVA-OneVision: Easy Visual Task Transfer
B. Li, Y. Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y. Li, Z. Liuet al., “LLaVA- OneVision: Easy visual task transfer,”arXiv preprint arXiv:2408.03326, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Video-LLaV A: Learning united visual representation by alignment before projection
J. Liu, Y. Wang, H. Ma, X. Wu, X. Ma, X. Wei, J. Jiao, E. Wu, and J. Hu, “Kangaroo: A powerful video-language model supporting long-context video input,”arXiv preprint arXiv:2408.15542, 2024
-
[31]
Thinking in space: How multimodal large language models see, remember, and recall spaces,
J. Yang, S. Yang, A. W. Gupta, R. Han, F.-F. Li, and S. Xie, “Thinking in space: How multimodal large language models see, remember, and recall spaces,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), June 2025, pp. 10 632–10 643
2025
-
[32]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
K. Hu, P. Wu, F. Pu, Wang Xiao, Y. Zhang, X. Yue, B. Li, and Z. Liu, “Video-MMMU: Evaluating knowl- edge acquisition from multi-discipline professional videos,”arXiv preprint arXiv:2501.13826, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
MMVU: Measur- ing expert-level multi-discipline video understanding,
Y. Zhao, H. Zhang, L. Xie, T. Hu, G. Gan, Y. Long, Z. Hu, W. Chen, C. Li, Z. Xuet al., “MMVU: Measur- ing expert-level multi-discipline video understanding,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), June 2025, pp. 8475–8489
2025
-
[34]
MVBench: A comprehensive multi-modal video understanding benchmark,
K. Li, Y. Wang, Y. He, Y. Li, Y. Wang, Y. Liu, Z. Wang, J. Xu, G. Chen, P. Luoet al., “MVBench: A comprehensive multi-modal video understanding benchmark,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 22 195–22 206
2024
-
[35]
TempCompass: Do Video LLMs Really Understand Videos?
Y. Liu, S. Li, Y. Liu, Y. Wang, S. Ren, L. Li, S. Chen, X. Sun, and L. Hou, “TempCompass: Do video LLMs really understand videos?”arXiv preprint arXiv:2403.00476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Video- MME: The first-ever comprehensive evaluation bench- mark of multi-modal LLMs in video analysis,
C. Fu, Y. Dai, Y. Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y. Shen, M. Zhanget al., “Video- MME: The first-ever comprehensive evaluation bench- mark of multi-modal LLMs in video analysis,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 24 108–24 118
2025
-
[37]
VILA: On pre-training for visual lan- guage models,
J. Lin, H. Yin, W. Ping, P. Molchanov, M. Shoeybi, and S. Han, “VILA: On pre-training for visual lan- guage models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), June 2024, pp. 26 689–26 699
2024
-
[38]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang et al., “Qwen2.5-VL technical report,”arXiv preprint arXiv:2502.13923, 2025. 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.