Can MLLMs Critique Like Humans? Evaluating Open-Ended Aesthetic Reasoning in Multimodal Large Language Models
Pith reviewed 2026-06-30 06:44 UTC · model grok-4.3
The pith
Reference-based similarity metrics overrate multimodal models' aesthetic critiques by favoring comprehensive style over human selectivity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When scored against ranked human critiques using reference-based metrics, multimodal models show superficial alignment that disappears under stricter lexical and embedding measures. A control experiment feeding wrong photographs reveals that apparent topical overlap stems from a stable model-specific style rather than observation of the given image. Behaviorally, the models generate critiques two to three times longer than humans, address nearly all aesthetic aspects uniformly instead of being selective, and repeat content across different photos where humans vary their responses.
What carries the argument
The wrong-photograph grounding control that isolates whether topical similarity arises from image-specific reasoning or from the model's default critique style.
If this is right
- Reference-based similarity metrics reward fluent and comprehensive critique styles rather than the selectivity and specificity of human critiques.
- Multimodal models produce critiques two to three times longer than humans even under length caps and cover nearly every aesthetic aspect where humans remain selective.
- Models engage each aspect more uniformly and at greater depth while repeating themselves across critiques of the same photo where humans vary.
- Current evaluation practices for open-ended multimodal generation require methods beyond reference similarity to capture human-like qualities.
Where Pith is reading between the lines
- Evaluation of open-ended generation may need metrics that directly test whether specific observations change with the input image rather than measuring style match.
- The consistent house style observed could limit usefulness in applications where critique must adapt to unique image details.
- Similar mismatches between model output patterns and human selectivity may occur in other open-ended multimodal tasks such as captioning or visual reasoning.
Load-bearing premise
The ranked human references in the Reddit Photo Critique Dataset form the right target distribution for human-like aesthetic critique and the wrong-image control successfully separates house style from image-specific content.
What would settle it
Models producing substantially different specific observations when given the correct photograph versus the wrong one would challenge the finding that their critiques lack image grounding.
Figures


read the original abstract
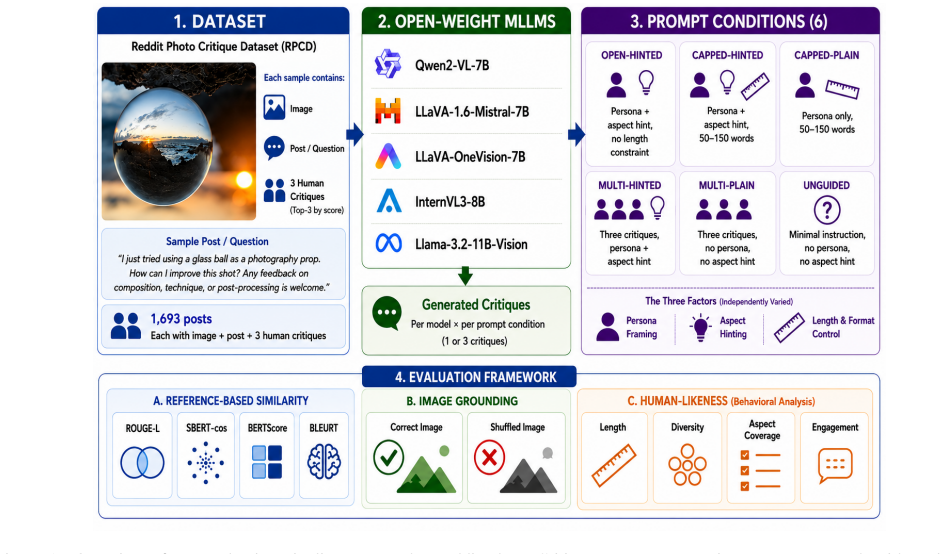
Open-ended aesthetic critique is a challenge for multimodal large language models (MLLMs): unlike multiple-choice aesthetic benchmarks, it has no single correct answer, and most aesthetic evaluation has measured models against numeric scores rather than the written critiques people actually give. We evaluate MLLM critiques against ranked human references and ask whether they are close to human ones. Using the Reddit Photo Critique Dataset, we score five open-weight MLLMs against multiple ranked human critiques per photo with reference-based similarity metrics, under six prompt conditions that disentangle persona framing, aspect hinting, length control, and single- versus multi-pass generation, and add an image-grounding control that feeds each model the wrong photograph. We find that reference-based similarity gives a misleading picture. Stricter lexical and learned metrics show only weak alignment with human critiques, while a coarse embedding cosine reports broad topical overlap that the grounding control traces to a stable house style rather than image-specific observation. Behaviorally, the models diverge from humans in consistent ways the scores do not surface: even under a length cap they write two to three times as much, cover nearly every aesthetic aspect where humans are selective, engage each aspect more uniformly and at greater depth, and repeat themselves across critiques of the same photo where humans vary. We argue that reference-based similarity rewards a fluent, comprehensive critique style rather than the selectivity and specificity of human critique, and discuss implications for evaluating and training open-ended multimodal generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates five open-weight MLLMs on open-ended aesthetic critique generation against ranked human references from the Reddit Photo Critique Dataset. Using six prompt conditions (disentangling persona, aspect hints, length, and generation passes) plus an image-grounding ablation with wrong photographs, it compares outputs via reference-based similarity metrics. The central claim is that these metrics mislead: stricter lexical/learned metrics show only weak human alignment, while coarse embedding cosine overlap traces to stable model house style rather than image-specific observation. Models also diverge behaviorally by producing longer, less selective, more uniform, and repetitive critiques.
Significance. If the empirical results and controls hold, the work is significant for multimodal evaluation. It shows that reference-based metrics can reward fluent comprehensive style over the selectivity and specificity characteristic of human aesthetic writing, with implications for training and benchmarking open-ended MLLM generation beyond numeric scores. The multi-condition prompt design and grounding ablation are positive features for isolating effects.
major comments (3)
- [Dataset section] Dataset section: The paper treats the ranked Reddit Photo Critique Dataset references as the appropriate target distribution for human aesthetic critique without explicit justification or comparison to other sources of aesthetic writing. This premise is load-bearing for the claim that models diverge from humans in selectivity and aspect coverage; if Reddit critiques differ systematically in those dimensions, the divergence interpretation does not follow.
- [Image-grounding control] Image-grounding control (abstract and methods): The wrong-photograph ablation attributes residual coarse cosine similarity to house style. However, the description provides no details on wrong-photo selection criteria (e.g., visual statistics, scene similarity, or prompt-induced generic language), leaving open whether the control cleanly isolates house style from image-specific reasoning. This assumption underpins the interpretation that reference-based metrics are misleading.
- [Results on metrics] Results on metrics (likely §4 or evaluation subsection): The abstract states that stricter lexical and learned metrics show only weak alignment while coarse cosine reports broad overlap, but without naming the exact metrics, reporting their numerical values, or showing statistical tests in the provided description, the strength of the 'misleading picture' conclusion cannot be fully assessed.
minor comments (2)
- [Prompt conditions] The six prompt conditions are described at a high level in the abstract; a concise enumeration or table in the main text would improve reproducibility.
- [Behavioral analysis] Behavioral observations (length, aspect coverage, repetition) are summarized qualitatively; quantitative tables or figures with effect sizes would strengthen the divergence claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important areas for clarification, and we address each major point below with targeted revisions where the manuscript can be strengthened. All responses are based on the submitted manuscript content.
read point-by-point responses
-
Referee: [Dataset section] Dataset section: The paper treats the ranked Reddit Photo Critique Dataset references as the appropriate target distribution for human aesthetic critique without explicit justification or comparison to other sources of aesthetic writing. This premise is load-bearing for the claim that models diverge from humans in selectivity and aspect coverage; if Reddit critiques differ systematically in those dimensions, the divergence interpretation does not follow.
Authors: We agree that the Dataset section would benefit from explicit justification. In the revised manuscript we have added a dedicated paragraph explaining the choice: the Reddit Photo Critique Dataset supplies ranked, open-ended, image-specific human critiques on consumer photographs, which directly matches the open-ended aesthetic critique task. We also include a brief comparison noting that, unlike professional art criticism or curated exhibition reviews, this source provides diverse non-expert perspectives with explicit ranking, making it suitable for measuring selectivity and aspect coverage against human distributions. revision: yes
-
Referee: [Image-grounding control] Image-grounding control (abstract and methods): The wrong-photograph ablation attributes residual coarse cosine similarity to house style. However, the description provides no details on wrong-photo selection criteria (e.g., visual statistics, scene similarity, or prompt-induced generic language), leaving open whether the control cleanly isolates house style from image-specific reasoning. This assumption underpins the interpretation that reference-based metrics are misleading.
Authors: We accept that additional detail on the control is warranted. The revised Methods section now specifies the selection procedure: wrong photographs were drawn from the same dataset but chosen to have low CLIP embedding cosine similarity (<0.3) and to belong to different high-level scene categories (e.g., landscape vs. portrait) to reduce both visual and prompt-induced generic overlap. This strengthens the isolation of house style from image-specific reasoning. revision: yes
-
Referee: [Results on metrics] Results on metrics (likely §4 or evaluation subsection): The abstract states that stricter lexical and learned metrics show only weak alignment while coarse cosine reports broad overlap, but without naming the exact metrics, reporting their numerical values, or showing statistical tests in the provided description, the strength of the 'misleading picture' conclusion cannot be fully assessed.
Authors: The full manuscript already names the metrics in §4 (BLEU-4, ROUGE-L, METEOR, BERTScore, Sentence-BERT cosine, and CLIP cosine) and reports numerical values with standard errors in Table 2. We have now added explicit statistical comparisons (paired Wilcoxon tests against human inter-annotator baselines) with p-values in the same section and an appendix table to make the strength of the conclusion easier to assess without relying on the high-level abstract alone. revision: partial
Circularity Check
No significant circularity; purely empirical evaluation against external human data
full rationale
The paper performs an empirical comparison of MLLM-generated critiques against ranked human references from the Reddit Photo Critique Dataset, using reference-based similarity metrics (lexical, learned, and embedding cosine) under controlled prompt variations and an image-grounding ablation. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing steps; the central claims rest on direct measurement against independent human data and off-the-shelf metrics rather than any self-definitional or self-referential reduction. The assumptions about the dataset and control are empirical premises open to external challenge, not circular by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ranked human critiques in the Reddit Photo Critique Dataset represent the appropriate target for human-like aesthetic reasoning.
Reference graph
Works this paper leans on
-
[1]
Can llms reason like hu- mans? assessing theory of mind reasoning in llms for open- ended questions
Maryam Amirizaniani, Elias Martin, Maryna Sivachenko, Afra Mashhadi, and Chirag Shah. Can llms reason like hu- mans? assessing theory of mind reasoning in llms for open- ended questions. InProceedings of the 33rd ACM Interna- tional Conference on Information and Knowledge Manage- ment, pages 34–44, 2024. 1, 3
2024
-
[2]
From filters to vlms: Benchmarking defogging methods through object detection and segmentation performance
Ardalan Aryashad, Parsa Razmara, Amin Mahjoub, Seyedarmin Azizi, Mahdi Salmani, and Arad Firouzkouhi. From filters to vlms: Benchmarking defogging methods through object detection and segmentation performance. In Proceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision, pages 1106–1115, 2026. 4
2026
-
[3]
Aesthetic critiques generation for photos
Kuang-Yu Chang, Kung-Hung Lu, and Chu-Song Chen. Aesthetic critiques generation for photos. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 3514–3523, 2017. 3
2017
-
[4]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Bal ´azs Galambosi, Percy Liang, and Tat- sunori B Hashimoto. Length-controlled alpacaeval: A sim- ple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475, 2024. 4, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Perceptual quality assessment of smartphone photog- raphy
Yuming Fang, Hanwei Zhu, Yan Zeng, Kede Ma, and Zhou Wang. Perceptual quality assessment of smartphone photog- raphy. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 3677– 3686, 2020. 1, 3
2020
-
[6]
Sajjad Ghiasvand, Mahnoosh Alizadeh, and Ramtin Pedarsani. pfedmma: Personalized federated fine-tuning with multi-modal adapter for vision-language models.arXiv preprint arXiv:2507.05394, 2025. 3, 8
-
[7]
Sajjad Ghiasvand, Haniyeh Ehsani Oskouie, Mahnoosh Al- izadeh, and Ramtin Pedarsani. Few-shot adversarial low- rank fine-tuning of vision-language models.arXiv preprint arXiv:2505.15130, 2025. 8
-
[8]
Mmlop: Multi-modal low- rank prompting for efficient vision-language adaptation
Sajjad Ghiasvand, Haniyeh Ehsani Oskouie, Mahnoosh Al- izadeh, and Ramtin Pedarsani. Mmlop: Multi-modal low- rank prompting for efficient vision-language adaptation. arXiv preprint arXiv:2602.21397, 2026. 3
-
[9]
Aes- thetic image captioning from weakly-labelled photographs
Koustav Ghosal, Aakanksha Rana, and Aljosa Smolic. Aes- thetic image captioning from weakly-labelled photographs. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 0–0, 2019. 3
2019
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Vaughan, An- gela Yang, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 1, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
arXiv preprint arXiv:2401.08276 (2024)
Yipo Huang, Quan Yuan, Xiangfei Sheng, Zhichao Yang, Haoning Wu, Pengfei Chen, Yuzhe Yang, Leida Li, and Weisi Lin. Aesbench: An expert benchmark for multimodal large language models on image aesthetics perception.arXiv preprint arXiv:2401.08276, 2024. 1, 3
-
[12]
Eva: An explainable visual aesthetics dataset
Chen Kang, Giuseppe Valenzise, and Fr ´ed´eric Dufaux. Eva: An explainable visual aesthetics dataset. InJoint Workshop on Aesthetic and Technical Quality Assessment of Multime- dia and Media Analytics for Societal Trends, pages 5–13,
-
[13]
Tina Khezresmaeilzadeh, Parsa Razmara, Seyedarmin Az- izi, Mohammad Erfan Sadeghi, and Erfan Baghaei Po- traghloo. Vista: Vision-language inference for training-free stock time-series analysis.arXiv preprint arXiv:2505.18570,
-
[14]
Morfi: Mutimodal zero-shot reasoning for financial time- series inference
Tina Khezresmaeilzadeh, Parsa Razmara, Mohammad Erfan Sadeghi, Seyedarmin Azizi, and Erfan Baghaei Potraghloo. Morfi: Mutimodal zero-shot reasoning for financial time- series inference. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4236–4245,
-
[15]
Photo aesthetics ranking network with attributes and content adaptation
Shu Kong, Xiaohui Shen, Zhe Lin, Radomir Mech, and Charless Fowlkes. Photo aesthetics ranking network with attributes and content adaptation. InEuropean Conference on Computer Vision (ECCV), pages 662–679, Cham, 2016. Springer International Publishing. 1, 3
2016
-
[16]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024. 1, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 3
2023
-
[18]
Aesbiasbench: Evaluat- ing bias and alignment in multimodal language models for personalized image aesthetic assessment
Kun Li, Lai Man Po, Hongzheng Yang, Xuyuan Xu, Kangcheng Liu, and Yuzhi Zhao. Aesbiasbench: Evaluat- ing bias and alignment in multimodal language models for personalized image aesthetic assessment. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP), pages 7618–7631, 2025. 3
2025
-
[19]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004. 1, 3, 5
2004
-
[20]
Llava-next: Im- proved reasoning, ocr, and world knowledge.https: / / llava - vl
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge.https: / / llava - vl . github . io / blog / 2024 - 01 - 30 - llava-next/, 2024. Blog post. 1, 3, 4
2024
-
[21]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettle- moyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[22]
G-eval: Nlg evaluation using gpt- 4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt- 4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language pro- cessing, pages 2511–2522, 2023. 4
2023
-
[23]
Tan- gled up in bleu: Reevaluating the evaluation of automatic machine translation evaluation metrics
Nitika Mathur, Timothy Baldwin, and Trevor Cohn. Tan- gled up in bleu: Reevaluating the evaluation of automatic machine translation evaluation metrics. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4984–4997, 2020. 1, 3
2020
-
[24]
Ava: A large-scale database for aesthetic visual analysis
Naila Murray, Luca Marchesotti, and Florent Perronnin. Ava: A large-scale database for aesthetic visual analysis. 9 In2012 IEEE conference on computer vision and pattern recognition, pages 2408–2415. IEEE, 2012. 1, 3
2012
-
[25]
Why we need new evaluation metrics for nlg
Jekaterina Novikova, Ond ˇrej Duˇsek, Amanda Cercas Curry, and Verena Rieser. Why we need new evaluation metrics for nlg. InProceedings of the 2017 conference on empirical methods in natural language processing, pages 2241–2252,
2017
-
[26]
GPT-4V(ision) system card.https://openai
OpenAI. GPT-4V(ision) system card.https://openai. com/index/gpt- 4v- system- card/, 2023. Ac- cessed: 2026-06-25. 3
2023
-
[27]
Llm evaluators recognize and favor their own generations
Arjun Panickssery, Samuel R Bowman, and Shi Feng. Llm evaluators recognize and favor their own generations. Advances in Neural Information Processing Systems, 37: 68772–68802, 2024. 4, 8
2024
-
[28]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318,
-
[29]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 3
2021
-
[30]
M Saberi, C Zhang, and M Akcakaya. Training-free mitiga- tion of adversarial attacks on deep learning-based mri recon- struction.arXiv preprint arXiv:2501.01908, 2025. 6
-
[31]
Bleurt: Learning robust metrics for text generation
Thibault Sellam, Dipanjan Das, and Ankur Parikh. Bleurt: Learning robust metrics for text generation. InProceedings of the 58th annual meeting of the association for computa- tional linguistics, pages 7881–7892, 2020. 1, 3, 5
2020
-
[32]
Nima: Neural image assessment.IEEE transactions on image processing, 27(8): 3998–4011, 2018
Hossein Talebi and Peyman Milanfar. Nima: Neural image assessment.IEEE transactions on image processing, 27(8): 3998–4011, 2018. 1, 3
2018
-
[33]
Yasaman Torabi, Parsa Razmara, Hamed Ajorlou, and Bar- dia Baraeinejad. Neuromamballm: Dynamic graph learn- ing of fmri functional connectivity in autistic brains us- ing mamba and language model reasoning.arXiv preprint arXiv:2602.13770, 2026. 8
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Understanding aesthetics with language: A photo critique dataset for aesthetic assessment.Advances in Neural Information Processing Systems (NeurIPS), 35: 34148–34161, 2022
Daniel Vera Nieto, Luigi Celona, and Clara Fernan- dez Labrador. Understanding aesthetics with language: A photo critique dataset for aesthetic assessment.Advances in Neural Information Processing Systems (NeurIPS), 35: 34148–34161, 2022. 2, 3, 4
2022
-
[35]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 1, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Large language models are not fair evaluators
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, et al. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 9440–9450, 2024. 4, 8
2024
-
[37]
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Q-bench: A benchmark for general-purpose foundation models on low-level vision
Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Chunyi Li, Wenxiu Sun, Qiong Yan, Guangtao Zhai, et al. Q-bench: A benchmark for general-purpose foundation models on low-level vision. InInternational Conference on Learning Representations, pages 12547–12573, 2024. 1, 3
2024
-
[39]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Wein- berger, and Yoav Artzi. Bertscore: Evaluating text genera- tion with bert.arXiv preprint arXiv:1904.09675, 2019. 1, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[40]
Moverscore: Text generation eval- uating with contextualized embeddings and earth mover dis- tance
Wei Zhao, Maxime Peyrard, Fei Liu, Yang Gao, Christian M Meyer, and Steffen Eger. Moverscore: Text generation eval- uating with contextualized embeddings and earth mover dis- tance. InProceedings of the 2019 conference on empiri- cal methods in natural language processing and the 9th in- ternational joint conference on natural language processing (EMNLP-I...
2019
-
[41]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023. 4
2023
-
[42]
Zhaokun Zhou, Qiulin Wang, Bin Lin, Yiwei Su, Rui Chen, Xin Tao, Amin Zheng, Li Yuan, Pengfei Wan, and Di Zhang. Uniaa: A unified multi-modal image aesthetic assessment baseline and benchmark.arXiv preprint arXiv:2404.09619,
-
[43]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 1, 3, 4 10 Supplementary Material: Can MLLMs Critique Like Humans? Evaluating Open-...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.