A Switching System Theory of Q-Learning with Linear Function Approximation
Pith reviewed 2026-05-20 22:30 UTC · model grok-4.3
The pith
Q-learning with linear function approximation converges when its mean dynamics form a stable switched linear system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
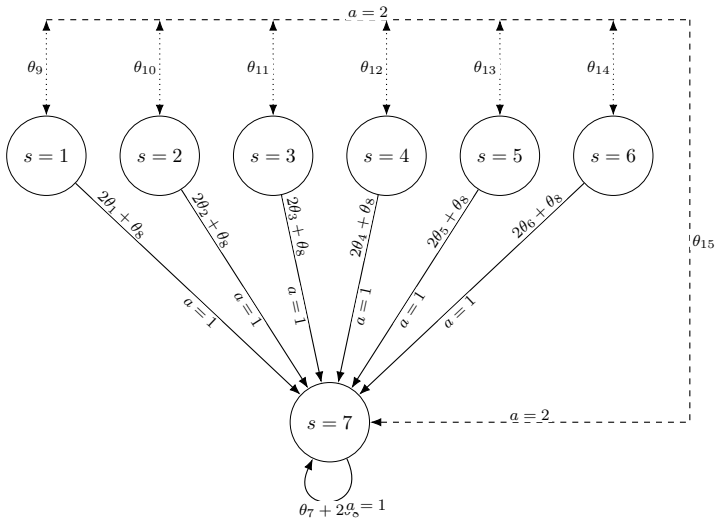
The mean dynamics of Q-learning with linear function approximation admit an exact representation as a finite-mode linear switched system. The switching signal is determined by the sequence of observations or actions selected. Global convergence of the iterates is equivalent to asymptotic stability of the origin in this switched system, which can be characterized by the joint spectral radius of the set of mode matrices being less than one. The same switched model extends directly to the stochastic case with i.i.d. or Markovian data, and to regularized Q-learning.
What carries the argument
The exact finite-mode linear switched model of the mean Q-learning dynamics, where each mode matrix activates according to the current observation or action sequence and the joint spectral radius of the full set of modes determines stability.
If this is right
- Global convergence holds whenever the joint spectral radius of the mode matrices is strictly less than one.
- A certificate based on products of several modes can be tighter than one-step norm bounds on the individual matrices.
- The same switched-system condition applies unchanged to stochastic Q-learning under both i.i.d. and Markovian sampling.
- Regularized Q-learning with linear approximation receives an identical stability characterization.
Where Pith is reading between the lines
- The mode matrices could be computed or bounded in advance on modest problems to certify convergence before training begins.
- The switched-system lens may extend to other temporal-difference algorithms by identifying the corresponding mode sets.
- Dependence induced by Markovian observations could be handled with existing tools for switched systems under constrained switching signals.
Load-bearing premise
The average update at each step is exactly linear in the current parameter vector, with the linear map chosen from a finite collection according to the data sequence.
What would settle it
For a small tabular or linear Q-learning problem, derive the explicit mode matrices, compute their joint spectral radius, and verify that parameter iterates diverge for some observation sequence precisely when that radius exceeds one.
Figures

read the original abstract
This paper develops a switching-system interpretation of Q-learning with linear function approximation (LFA) based on the joint spectral radius (JSR). We derive an exact linear switched model for the mean dynamics and relate convergence to stability of the corresponding switched system. The same construction is then used for stochastic linear Q-learning with independent and identically distributed (i.i.d.) observations and with Markovian observations. Although exact JSR computation is difficult in general, the certificate captures products of switching modes and can be less conservative than one-step norm bounds. The framework also yields a JSR-based view of regularized Q-learning with LFA. The resulting analysis connects projected Bellman equations, finite-difference stochastic-policy switching, and switched-system stability in a single parameter-space formulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a switching-system interpretation of Q-learning with linear function approximation based on the joint spectral radius. It derives an exact linear switched model for the mean dynamics of the Q-learning update and relates convergence to stability of the corresponding switched system. The construction is extended to stochastic linear Q-learning under i.i.d. and Markovian observations, and applied to regularized Q-learning, connecting projected Bellman equations with finite-difference stochastic-policy switching in a parameter-space formulation.
Significance. If the exact switched-model derivation holds without hidden approximations, the framework offers a parameter-space view that unifies projected Bellman operators with switched-system stability and may produce less conservative certificates than one-step norm bounds by considering products of modes. The extension to Markovian observations and regularization would be a useful contribution to convergence analysis of approximate Q-learning.
major comments (1)
- [Abstract] Abstract: the central claim of an 'exact linear switched model for the mean dynamics' whose 'switching is fully captured by the observation or action sequence' is load-bearing for the stability equivalence and JSR application. In Q-learning with LFA the target is r + gamma max_a' phi(s',a')^T theta; the argmax index depends on the numerical value of theta, so the effective matrix in the mean update is piecewise linear with boundaries that are hyperplanes in parameter space. This produces a state-dependent switched system, not an exogenous switched linear system to which standard joint spectral radius results apply directly. State-dependent switching can admit sliding modes or limit cycles even when all individual matrices are stable, undermining the claimed equivalence.
minor comments (1)
- [Abstract] The abstract refers to 'finite-difference stochastic-policy switching' without defining the finite-difference construction or showing how it renders the switching exogenous; a dedicated subsection with explicit matrix constructions for the modes would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for raising this important clarification regarding the switched-system model. We address the concern point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of an 'exact linear switched model for the mean dynamics' whose 'switching is fully captured by the observation or action sequence' is load-bearing for the stability equivalence and JSR application. In Q-learning with LFA the target is r + gamma max_a' phi(s',a')^T theta; the argmax index depends on the numerical value of theta, so the effective matrix in the mean update is piecewise linear with boundaries that are hyperplanes in parameter space. This produces a state-dependent switched system, not an exogenous switched linear system to which standard joint spectral radius results apply directly. State-dependent switching can admit sliding modes or limit cycles even when all individual matrices are stable, undermining the claimed equivalence.
Authors: We agree that the argmax in the target depends on the current theta, so mode selection is formally state-dependent. Our derivation nevertheless produces an exact linear switched representation of the mean dynamics in which each mode corresponds to a particular choice of maximizing action for a given observation (s, a, r, s'). The sequence of observations and actions determines which mode is active at each step, but the active mode itself is selected by the argmax evaluated at the current theta. Standard JSR results apply directly as a sufficient condition because JSR < 1 guarantees uniform exponential stability for every possible switching sequence. Any state-dependent switching rule (including the one induced by the argmax) is simply a particular selection among those sequences; hence the contraction property carries over and precludes sliding modes or limit cycles that would produce growth. We therefore maintain that the stability equivalence holds in the sufficient direction that is relevant for convergence certificates. We will revise the manuscript to explicitly distinguish the exogenous versus state-dependent interpretations and to state that the JSR bound supplies a sufficient (not necessary) condition that remains valid under state-dependent switching. revision: yes
Circularity Check
Derivation of switched model from Q-learning mean dynamics is independent of result
full rationale
The paper derives an exact linear switched model directly from the Q-learning update equations with linear function approximation and then applies the joint spectral radius to analyze stability of the resulting modes. No step in the provided abstract or description reduces the stability conclusion to a fitted parameter defined from the same data, a self-citation chain that is load-bearing, or an ansatz smuggled in from prior work by the same authors. The central construction begins from the standard projected Bellman operator and observation sequence, yielding an independent switched-system representation whose properties are then analyzed with external JSR tools. This is the most common honest non-finding for a first-principles derivation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Joint spectral radius less than one implies asymptotic stability for arbitrary switching sequences in linear systems
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery; no switched-system or JSR content unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive an exact linear switched model for the mean dynamics … the Bellman optimality error induces a stochastic-policy-based switching system, and the stability object is the joint spectral radius (JSR) of the associated switching matrix family
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel; J-cost uniqueness unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 3 (Stochastic-policy linearization) … Vθ − V¯θ = Π_μ Φ(θ − ¯θ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Error bounds for co nstant step-size Q-learning
Carolyn L Beck and Rayadurgam Srikant. Error bounds for co nstant step-size Q-learning. Systems & control letters , 61(12):1203–1208, 2012
work page 2012
-
[2]
Dynamic programming and optimal con trol 4th edition, volume ii
Dimitri P Bertsekas. Dynamic programming and optimal con trol 4th edition, volume ii. Athena Scientific , 2015
work page 2015
-
[3]
The ODE method for convergen ce of stochastic approxima- tion and reinforcement learning
Vivek S Borkar and Sean P Meyn. The ODE method for convergen ce of stochastic approxima- tion and reinforcement learning. SIAM Journal on Control and Optimization , 38(2):447–469, 2000
work page 2000
-
[4]
Diogo Carvalho, Francisco S. Melo, and Pedro Santos. A ne w convergent variant of Q-learning with linear function approximation. In Advances in Neural Information Processing Systems , volume 33, pages 19412–19421, 2020. 22
work page 2020
-
[5]
Fengdi Che, Chenjun Xiao, Jincheng Mei, Bo Dai, Ramki Gumm adi, Oscar A. Ramirez, Christopher K. Harris, A. Rupam Mahmood, and Dale Schuurman s. Target networks and over-parameterization stabilize off-policy bootstrappin g with function approximation. In Pro- ceedings of the 41st International Conference on Machine Le arning, volume 235 of Proceedings of M...
work page 2024
-
[6]
Zaiwei Chen, Siva Theja Maguluri, Sanjay Shakkottai, an d Karthikeyan Shanmugam. A Lya- punov theory for finite-sample guarantees of asynchronous Q -learning and TD-learning variants. arXiv preprint arXiv:2102.01567 , 2021
-
[7]
Doan, John-Paul Clark e, and Siva Theja Maguluri
Zaiwei Chen, Sheng Zhang, Thinh T. Doan, John-Paul Clark e, and Siva Theja Maguluri. Finite- sample analysis of nonlinear stochastic approximation wit h applications in reinforcement learn- ing. Automatica, 146:110623, 2022. doi: 10.1016/j.automatica.2022.1106 23
-
[8]
Target network and truncation overcome the deadly triad in Q-learning
Zaiwei Chen, John-Paul Clarke, and Siva Theja Maguluri. Target network and truncation overcome the deadly triad in Q-learning. SIAM Journal on Mathematics of Data Science , 5(4): 1078–1101, 2023. doi: 10.1137/22M1499261
-
[9]
Learning rates for Q-l earning
Eyal Even-Dar and Yishay Mansour. Learning rates for Q-l earning. Journal of machine learning Research, 5(Dec):1–25, 2003
work page 2003
-
[10]
A first-order ap proach to accelerated value iteration
Vineet Goyal and Julien Grand-Clement. A first-order ap proach to accelerated value iteration. Operations research, 71(2):517–535, 2023
work page 2023
-
[11]
Generating fu nctions of switched linear systems: analysis, computation, and stability applications
Jianghai Hu, Jinglai Shen, and Wei Zhang. Generating fu nctions of switched linear systems: analysis, computation, and stability applications. IEEE transactions on automatic control , 56 (5):1059–1074, 2010
work page 2010
-
[12]
The joint spectral radius: Theory and applications , volume 385
Raphaël Jungers. The joint spectral radius: Theory and applications , volume 385. Springer Science & Business Media, 2009
work page 2009
-
[13]
Finite-sample conv ergence rates for Q-learning and indirect algorithms
Michael Kearns and Satinder Singh. Finite-sample conv ergence rates for Q-learning and indirect algorithms. Advances in neural information processing systems , 11, 1998
work page 1998
-
[14]
Final iteration convergence bound of Q-l earning: Switching system approach
Donghwan Lee. Final iteration convergence bound of Q-l earning: Switching system approach. IEEE Transactions on Automatic Control , 69(7):4765–4772, 2024
work page 2024
-
[15]
Lyapunov-Certified Direct Switching Theory for Q-Learning
Donghwan Lee. Lyapunov-certified direct switching the ory for q-learning. arXiv preprint arXiv:2604.19569, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
A unified switching system pers pective and convergence analysis of Q-learning algorithms
Donghwan Lee and Niao He. A unified switching system pers pective and convergence analysis of Q-learning algorithms. In 34th Conference on Neural Information Processing Systems, NeurIPS 2020, 2020
work page 2020
-
[17]
A discrete-time switching system analysis of Q- learning
Donghwan Lee, Jianghai Hu, and Niao He. A discrete-time switching system analysis of Q- learning. SIAM Journal on Control and Optimization , 61(3):1861–1880, 2023
work page 2023
-
[18]
Sample complexity of asyn- chronous Q-learning: Sharper analysis and variance reduct ion
Gen Li, Yuting Wei, Yuejie Chi, Yuantao Gu, and Yuxin Che n. Sample complexity of asyn- chronous Q-learning: Sharper analysis and variance reduct ion. IEEE Transactions on Infor- mation Theory , 68(1):448–473, 2021
work page 2021
-
[19]
Switching in systems and control
Daniel Liberzon. Switching in systems and control . Springer Science & Business Media, 2003. 23
work page 2003
-
[20]
Han-Dong Lim and Donghwan Lee. Finite-time analysis of asynchronous Q-learning under diminishing step-size from control-theoretic view. IEEE Access, 12:149916–149939, 2024
work page 2024
-
[21]
Han-Dong Lim and Donghwan Lee. Regularized q-learning . In Advances in Neural Information Processing Systems, volume 37, pages 129855–129887, 2024
work page 2024
-
[22]
Han-Dong Lim and Donghwan Lee. Understanding the theor etical properties of pro- jected bellman equation, linear q-learning, and approxima te value iteration. arXiv preprint arXiv:2504.10865, 2025
-
[23]
Stability and stabilizab ility of switched linear systems: A survey of recent results
Hai Lin and Panos J Antsaklis. Stability and stabilizab ility of switched linear systems: A survey of recent results. IEEE Transactions on Automatic control , 54(2):308–322, 2009
work page 2009
-
[24]
Linear Q-le arning does not diverge: Convergence rates to a bounded set
Xinyu Liu, Zixuan Xie, and Shangtong Zhang. Linear Q-le arning does not diverge: Convergence rates to a bounded set. arXiv preprint arXiv:2501.19254 , 2025
-
[25]
Francisco S. Melo and M. Isabel Ribeiro. Convergence of Q-learning with linear function approximation. In 2007 European Control Conference (ECC) , pages 2671–2678. IEEE, 2007
work page 2007
-
[26]
Sean P. Meyn. The projected bellman equation in reinfor cement learning. IEEE Transactions on Automatic Control , 69(12):8323–8337, 2024. doi: 10.1109/TAC.2024.3409647
- [27]
-
[28]
Finite-time analysis of as ynchronous stochastic approxima- tion and Q-learning
Guannan Qu and Adam Wierman. Finite-time analysis of as ynchronous stochastic approxima- tion and Q-learning. In Conference on learning theory , pages 3185–3205, 2020
work page 2020
-
[29]
A note on the joint s pectral radius
Gian-Carlo Rota and Gilbert Strang. A note on the joint s pectral radius. Indag. Math , 22(4): 379–381, 1960
work page 1960
-
[30]
Richard S. Sutton and Andrew G. Barto. Reinforcement learning: An introduction . MIT Press, 1998
work page 1998
-
[31]
The asymptotic convergence-rate of Q-learning
Csaba Szepesvári. The asymptotic convergence-rate of Q-learning. In Advances in Neural Information Processing Systems , pages 1064–1070, 1998
work page 1998
-
[32]
Asynchronous stochastic approxima tion and Q-learning
John N Tsitsiklis. Asynchronous stochastic approxima tion and Q-learning. Machine learning , 16(3):185–202, 1994
work page 1994
-
[33]
John N Tsitsiklis and Vincent D Blondel. The lyapunov exp onent and joint spectral radius of pairs of matrices are hard—when not impossible—to compute a nd to approximate. Mathematics of Control, Signals and Systems , 10(1):31–40, 1997
work page 1997
-
[34]
Christopher JCH Watkins and Peter Dayan. Q-learning. Machine learning, 8(3):279–292, 1992
work page 1992
-
[35]
Br eaking the deadly triad with a target network
Shangtong Zhang, Hengshuai Yao, and Shimon Whiteson. Br eaking the deadly triad with a target network. In Proceedings of the 38th International Conference on Machin e Learning , volume 139 of Proceedings of Machine Learning Research, pages 12621–12631. PMLR, 2021. 24 A Proof of the Equivalence Between the Projected Equation an d the Normal Equation The fir...
work page 2021
-
[36]
145θ, θ ≥ 0, − 0. 8θ, θ < 0. Consequently, θ⋆ = 0 is a projected Bellman fixed point. The two deterministic-po licy direct modes are A1 = 1 − 0. 9 ·1. 3 + 0. 9 · 1 2 ·0. 7 ·1 = 0 . 145, A2 = 1 − 0. 9 ·1. 3 + 0. 9 · 1 2 ·0. 7 ·(− 2) = − 0. 8. Now choose the initial parameter θ0 = − 2. The deterministic Q-learning trajectory is θ1 = Tα (− 2) = 1 . 6, θ 2 = T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.