Hide to See: Reasoning-prefix Masking for Visual-anchored Thinking in VLM Distillation
Pith reviewed 2026-05-19 16:53 UTC · model grok-4.3
The pith
Masking the student's salient reasoning prefixes during distillation makes VLMs anchor their thinking more directly on visual evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing the standard causal mask with a salient reasoning-prefix mask during distillation, the student is trained to rely on visual evidence for its next-token predictions. The mask is applied selectively to prefixes that most influence the student's output, with the amount of masking increased gradually according to the gap between teacher and student distributions. This setup directly targets visual forgetting by blocking both future tokens and the student's own reasoning cues.
What carries the argument
Token-wise salient reasoning-prefix masking paired with self-paced masking budget scheduling, which identifies and hides high-influence prefixes for each next-token prediction while scaling the masking difficulty to the current teacher-student discrepancy.
If this is right
- The distilled student outperforms recent open-source VLMs, VLM distillation, and self-distillation methods on multimodal reasoning benchmarks.
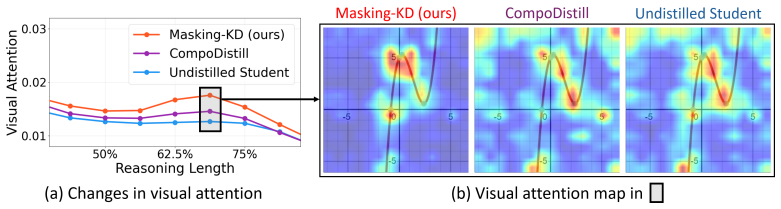
- Analyses confirm increased visual utilization throughout the student's thinking process.
- The framework adapts masking scale to distillation difficulty via self-paced scheduling.
Where Pith is reading between the lines
- The same controlled hiding of internal cues could be tested in text-only distillation to reduce reliance on language priors.
- Extending the masking to video or multi-image inputs might improve temporal or cross-image grounding.
- The scheduling rule could be reused as an adaptive curriculum in other teacher-student alignment settings.
Load-bearing premise
That removing the student's own salient reasoning prefixes will cause it to substitute visual evidence for the missing textual information.
What would settle it
If attention weights on image tokens fail to rise during the student's reasoning steps under the prefix mask compared with standard distillation, the visual-anchoring mechanism would be falsified.
Figures











read the original abstract
Recent think-answer approaches in VLMs, such as Qwen3-VL-Thinking, boost reasoning performance by leveraging intermediate thinking steps before the final answer, but their computational cost becomes substantial, especially for larger VLMs. To distill such capabilities into compact think-answer VLMs, a primary objective is to improve the student's ability to utilize visual evidence throughout its reasoning trace, as long think-answer traces suffer from visual forgetting issues. To this end, we introduce a novel think-answer distillation framework that encourages the student to anchor its thinking on visual information by masking the student's salient reasoning prefixes. To compensate for such masked textual cues, the student is encouraged to rely more on visual evidence as an alternative source of information during distillation. Our masking strategies include: 1) token-wise salient reasoning-prefix masking, which masks high-influence reasoning prefixes selectively for each next-token prediction, and 2) self-paced masking budget scheduling, which gradually increases the masking scale according to distillation difficulty, measured by the discrepancy between teacher--student distributions. In the distillation phase, the student is guided by our salient reasoning-prefix mask, which blocks both future tokens and salient reasoning cues, in place of the standard causal mask used for auto-regressive language modeling. Experimental results show that our approach outperforms recent open-source VLMs, VLM distillation, and self-distillation methods on multimodal reasoning benchmarks, while further analyzes confirm enhanced visual utilization along the student thinking process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a think-answer distillation framework for compact VLMs that applies two masking strategies—token-wise salient reasoning-prefix masking and self-paced masking budget scheduling—to block high-influence textual reasoning prefixes during training. This is intended to force the student to anchor its intermediate thinking steps on visual evidence rather than imitating the teacher's textual cues, thereby mitigating visual forgetting in long reasoning traces. The authors report that the resulting student models outperform recent open-source VLMs, VLM distillation baselines, and self-distillation methods on multimodal reasoning benchmarks, with additional analyses indicating improved visual utilization along the student's reasoning process.
Significance. If the central claims hold after rigorous controls, the work would provide a lightweight, architecture-agnostic technique for distilling complex multimodal reasoning into smaller models while explicitly promoting visual grounding. The self-paced scheduling and influence-based prefix selection are technically interesting contributions that could generalize beyond the reported setting. The paper would benefit from stronger isolation of the proposed mechanism from generic regularization effects.
major comments (3)
- [§3.1–3.2] §3.1–3.2: The central mechanistic claim—that masking salient reasoning prefixes causes the student to substitute visual evidence for blocked textual cues—is not isolated from confounding training effects. No ablation is presented that compares the proposed masking against random prefix masking, uniform difficulty scaling, or equivalent loss-landscape alterations to demonstrate that gains arise specifically from visual anchoring rather than increased training difficulty.
- [§4] §4 (Experiments): The reported outperformance on multimodal reasoning benchmarks lacks error bars, number of random seeds, statistical significance tests, and precise descriptions of baseline re-implementations and hyper-parameter matching. These omissions make it impossible to assess whether the claimed gains are robust or reproducible, which directly bears on the primary empirical claim.
- [§4.3] §4.3 (Analyses): The 'further analyzes' confirming enhanced visual utilization are described only at a high level; the manuscript should include quantitative metrics (e.g., attention scores on visual tokens, grounding accuracy on intermediate steps) with controls that rule out post-hoc correlation rather than causation.
minor comments (3)
- [Abstract] Abstract: The phrase 'further analyzes confirm' should be replaced with a brief enumeration of the specific analyses performed.
- [Notation] Notation: Define 'influence' for salient prefix selection explicitly (e.g., gradient-based, attention-based, or loss-based) and state whether it is computed on the teacher or student at each step.
- [Figures] Figure captions: Ensure all figures reporting benchmark scores include the exact number of evaluation samples and any filtering criteria applied.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for strengthening the isolation of our proposed mechanism and improving empirical robustness. We have revised the manuscript to address these points and provide detailed responses below.
read point-by-point responses
-
Referee: [§3.1–3.2] §3.1–3.2: The central mechanistic claim—that masking salient reasoning prefixes causes the student to substitute visual evidence for blocked textual cues—is not isolated from confounding training effects. No ablation is presented that compares the proposed masking against random prefix masking, uniform difficulty scaling, or equivalent loss-landscape alterations to demonstrate that gains arise specifically from visual anchoring rather than increased training difficulty.
Authors: We agree that stronger isolation of the salient prefix masking effect is valuable. In the revised manuscript we have added an ablation comparing token-wise salient reasoning-prefix masking against random prefix masking performed at identical masking ratios and budgets. The results show that random masking produces noticeably smaller gains on the target benchmarks, indicating that the performance improvement is not explained by generic increases in training difficulty alone. We have also clarified in Section 3.2 that our self-paced schedule is driven by the evolving teacher-student distribution discrepancy rather than a fixed difficulty ramp, distinguishing it from uniform scaling. revision: yes
-
Referee: [§4] §4 (Experiments): The reported outperformance on multimodal reasoning benchmarks lacks error bars, number of random seeds, statistical significance tests, and precise descriptions of baseline re-implementations and hyper-parameter matching. These omissions make it impossible to assess whether the claimed gains are robust or reproducible, which directly bears on the primary empirical claim.
Authors: We acknowledge the need for greater statistical transparency. The revised experimental section now reports mean performance with standard-deviation error bars computed across three independent random seeds for all main results. We have added paired t-test p-values comparing our method against each baseline and included these in the result tables. We have also expanded the description of baseline re-implementations, confirming that all methods were trained with identical data splits, optimizer settings, and total training steps to ensure fair hyper-parameter matching. revision: yes
-
Referee: [§4.3] §4.3 (Analyses): The 'further analyzes' confirming enhanced visual utilization are described only at a high level; the manuscript should include quantitative metrics (e.g., attention scores on visual tokens, grounding accuracy on intermediate steps) with controls that rule out post-hoc correlation rather than causation.
Authors: We have substantially expanded Section 4.3. The revised version now reports quantitative attention scores averaged over visual tokens at each intermediate reasoning step, together with a visual grounding accuracy metric computed on a held-out set of examples. To address potential post-hoc correlation, we include an additional control ablation that applies masking without the self-paced schedule; the full method yields statistically higher visual attention and grounding scores than this control, supporting a causal contribution of the combined masking strategy. revision: yes
Circularity Check
No circularity; masking strategies are independent heuristic additions
full rationale
The paper introduces token-wise salient reasoning-prefix masking and self-paced masking budget scheduling as new components in a think-answer distillation framework. These are described as mechanisms to encourage visual reliance by blocking textual cues, with no equations or derivations shown that reduce the claimed visual-anchoring effect to fitted parameters, self-citations, or prior ansatzes by construction. Performance gains are tied to benchmark experiments and qualitative analyses rather than any self-definitional loop or renamed known result. The derivation chain remains self-contained against external benchmarks, with the central premise being an empirical training intervention rather than a mathematical equivalence to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- masking budget schedule parameters
axioms (1)
- domain assumption Masking salient reasoning prefixes encourages the student to rely on visual evidence during distillation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
token-wise salient reasoning-prefix masking, which masks high-influence reasoning prefixes selectively for each next-token prediction
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
self-paced masking budget scheduling, which gradually increases the masking scale according to distillation difficulty, measured by the discrepancy between teacher–student distributions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
ZPPO improves distillation to small vision-language models by using binary and negative candidate prompts plus a replay buffer for hard questions, outperforming standard distillation and GRPO on a 31-benchmark suite w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.