Reinforcement Learning-Based Control for an Inline Skating Humanoid Robot
Pith reviewed 2026-07-01 05:14 UTC · model grok-4.3
The pith
Reinforcement learning produces a control policy for a humanoid robot on passive inline skates that cuts energy cost by up to 50 percent versus walking and transfers zero-shot to hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An RL policy trained without human motion data or imitation enables precise 6-DoF control of passive inline skates on a humanoid robot. Propulsion and balance strategies emerge from the reward structure when the policy is trained across spherical and ellipsoidal wheel geometries plus a custom curriculum and rolling reward. The policy reduces Cost of Transport by up to 50 percent relative to walking gaits and transfers directly to the Booster T1 hardware, where it maintains dynamic balance, rejects physical perturbations, and executes agile turns at speed.
What carries the argument
The reinforcement learning policy trained with multiple geometric wheel models during simulation, a success-based command curriculum, and a specialized rolling reward to produce edge-driven skating.
If this is right
- The policy achieves up to 50 percent lower Cost of Transport than standard walking gaits.
- Locomotion transfers zero-shot from simulation to the physical Booster T1 hardware.
- The robot demonstrates dynamic balance and rejection of active physical perturbations.
- Agile turning at speed becomes possible through the learned skating strategies.
Where Pith is reading between the lines
- Similar reward and curriculum techniques could be tested on other passive-wheeled platforms to check whether the 50 percent energy reduction generalizes beyond this robot.
- If the approach scales, it opens a path to energy-efficient locomotion that combines legged versatility with wheeled efficiency without adding motors to the wheels.
- The absence of motion capture data suggests the method could be applied to robots whose human-like skating motion has no prior examples.
Load-bearing premise
Training with two different wheel shapes in simulation plus the custom curriculum and rolling reward is enough to overcome contact modeling errors and produce policies that work on real passive skates with no hardware fine-tuning.
What would settle it
Deploy the same policy on the physical robot after training with only one wheel geometry instead of both spherical and ellipsoidal models; if balance fails or Cost of Transport stays comparable to walking, the claim does not hold.
Figures


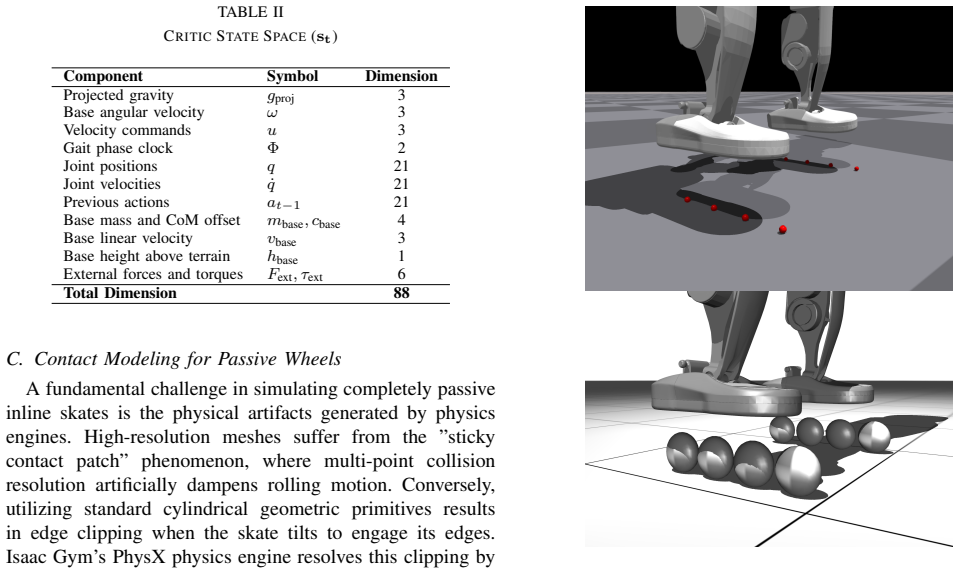
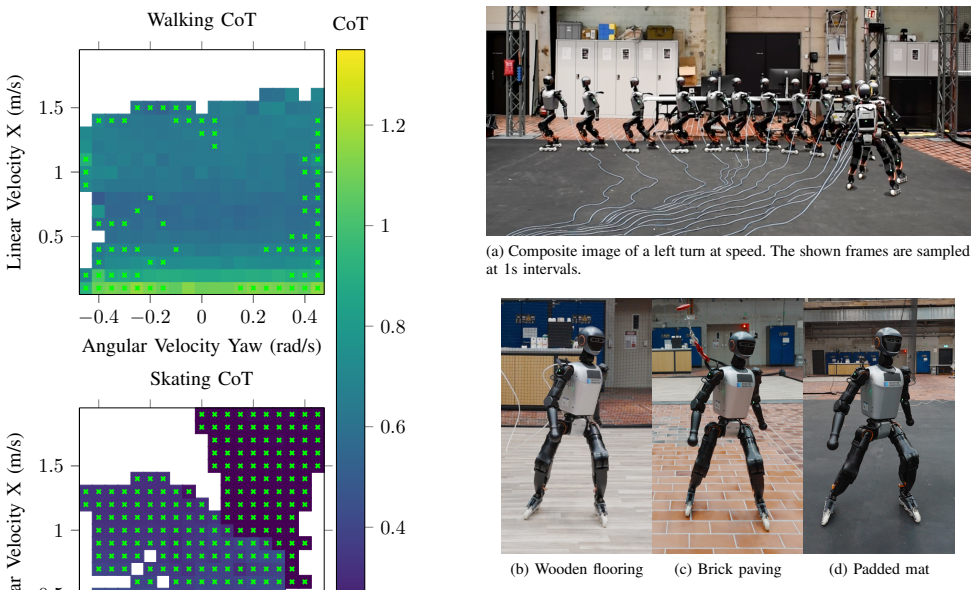
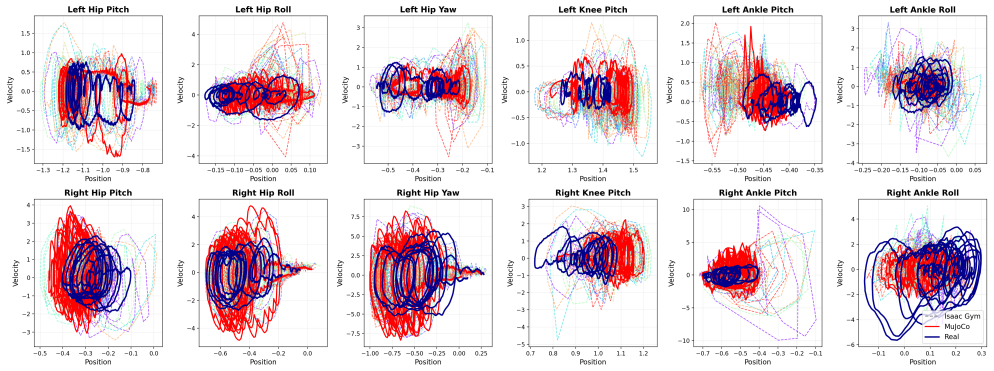
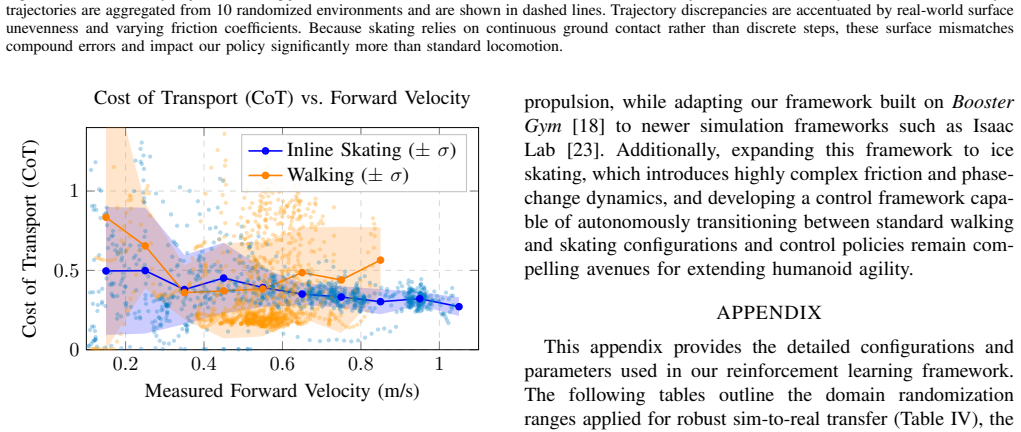
read the original abstract
As humanoid robots become increasingly dynamic, coupling them with reinforcement learning offers a promising approach to solving the complex, underactuated mechanics of passive inline skating. Equipping a humanoid robot with passive inline skating wheels presents an opportunity to combine the versatile agility of humanoids with the high-speed, energy-efficient locomotion strategies utilized by human skaters. In this paper, we train and deploy a reinforcement learning control policy that enables novel locomotion strategies for a humanoid robot modified to equip consumer inline skates instead of conventional feet. Unlike previous work limited to quadrupedal robots or actively driven wheels, our system allows for precise 6-DoF control of the skates to execute dynamic, edge-driven propulsion strategies. Our skating strategies emerge entirely from our reward structure, without reliance on human motion data, imitation learning, or kinematic priors. We overcome the inherent instability of passive wheels and simulation contact artifacts by utilizing different geometric wheel models (spherical and ellipsoidal) during training and validation, along with a custom success-based command curriculum and a specialized rolling reward. Consequently, our policy demonstrates up to a 50% reduction in Cost of Transport (CoT) compared to standard walking gaits. The resulting policy successfully transfers zero-shot to the physical Booster T1 hardware. Real-world deployments demonstrate dynamic balance, the ability to reject active physical perturbations, and agile locomotion strategies capable of turning at speed. A video of our results can be found at https://www.youtube.com/watch?v=-_APcOS7uFo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a reinforcement learning policy for controlling a humanoid robot equipped with passive inline skates on the Booster T1 platform. Training alternates between spherical and ellipsoidal wheel geometries, incorporates a success-based command curriculum and rolling reward, and produces emergent skating gaits without imitation learning or kinematic priors. The central claims are up to 50% reduction in Cost of Transport relative to walking gaits and successful zero-shot sim-to-real transfer, with real-world demonstrations of dynamic balance, perturbation rejection, and agile turning maneuvers.
Significance. If the zero-shot transfer and CoT reduction hold under rigorous validation, the work would advance RL control of underactuated passive-wheeled humanoids by showing that energy-efficient, dynamic locomotion strategies can be obtained purely from reward design. The multi-geometry wheel modeling technique for mitigating contact artifacts constitutes a practical methodological contribution for sim-to-real problems in contact-rich locomotion.
major comments (2)
- [Abstract] Abstract: The claim of reliable zero-shot transfer to passive inline skates is load-bearing on the spherical/ellipsoidal wheel models plus curriculum and rolling reward overcoming simulation contact artifacts, yet no quantitative evidence (measured vs. simulated normal/tangential force traces, identified rolling-resistance coefficients, or ablation on model fidelity) is supplied to confirm these choices close the gap for the real Booster T1 skates.
- [Abstract] Abstract: The reported 50% CoT reduction is presented as a headline result, but the abstract does not specify the exact baseline walking gait, the CoT measurement protocol (simulation vs. hardware), or error bars, making it impossible to assess whether the improvement is robust or sensitive to the free reward-structure weights.
minor comments (1)
- [Abstract] Abstract: The provided video link is a positive addition for conveying the locomotion behaviors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We will revise the abstract for greater precision on the CoT claim and to clarify the nature of the zero-shot validation. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of reliable zero-shot transfer to passive inline skates is load-bearing on the spherical/ellipsoidal wheel models plus curriculum and rolling reward overcoming simulation contact artifacts, yet no quantitative evidence (measured vs. simulated normal/tangential force traces, identified rolling-resistance coefficients, or ablation on model fidelity) is supplied to confirm these choices close the gap for the real Booster T1 skates.
Authors: The manuscript validates zero-shot transfer through successful hardware deployment, including balance, perturbation rejection, and turning maneuvers on the physical Booster T1, without policy fine-tuning. Direct force trace comparisons, rolling-resistance identification, or model-fidelity ablations are not included, as the evaluation prioritized end-to-end locomotion metrics over contact-level instrumentation. We will revise the abstract to state that transfer success is demonstrated via hardware performance rather than force matching, and we will add a sentence noting this as a limitation of the current validation. revision: partial
-
Referee: [Abstract] Abstract: The reported 50% CoT reduction is presented as a headline result, but the abstract does not specify the exact baseline walking gait, the CoT measurement protocol (simulation vs. hardware), or error bars, making it impossible to assess whether the improvement is robust or sensitive to the free reward-structure weights.
Authors: We will revise the abstract to specify: (1) the baseline is a walking policy trained with the identical RL framework and reward structure on the Booster T1 platform without skates; (2) CoT is computed using the standard mechanical power / forward velocity formulation and reported for both simulation and hardware; (3) the up-to-50% figure includes standard deviation across repeated trials; and (4) the reduction remained consistent under moderate variations of the free reward weights. These details will be added while preserving the abstract length. revision: yes
- No quantitative force traces, identified rolling-resistance coefficients, or model-fidelity ablations are present in the manuscript to directly confirm that the spherical/ellipsoidal modeling closes the sim-to-real gap.
Circularity Check
No circularity: empirical RL training and hardware results are independent of inputs
full rationale
The paper reports an RL policy trained with geometric wheel models, a success-based curriculum, and a rolling reward to achieve skating locomotion. The 50% CoT reduction and zero-shot hardware transfer are presented as measured outcomes of this training process on the Booster T1, not as quantities derived by algebraic construction or by renaming fitted parameters. No equations reduce the reported performance metrics to the training inputs by definition, and no self-citation chain is invoked to justify uniqueness or force the result. The derivation chain consists of standard RL optimization whose outputs are externally validated on physical hardware.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward structure weights
axioms (1)
- domain assumption Simulation contact dynamics with spherical and ellipsoidal wheel models sufficiently approximate real passive inline skate behavior for zero-shot transfer.
Reference graph
Works this paper leans on
-
[1]
Perceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching
Z. Wuet al., “Perceptive humanoid parkour: Chaining dynamic human skills via motion matching,” 2026. [Online]. Available: https://arxiv.org/abs/2602.15827
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Humanoid whole-body locomotion on narrow terrain via dynamic balance and reinforcement learning,
W. Xie, C. Bai, J. Shi, J. Yang, Y . Ge, W. Zhang, and X. Li, “Humanoid whole-body locomotion on narrow terrain via dynamic balance and reinforcement learning,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 4751– 4758
2025
-
[3]
(2025) Booster t1: High-performance humanoid robot
Booster Robotics. (2025) Booster t1: High-performance humanoid robot. [Online]. Available: https://www.booster.tech/booster-t1/
2025
-
[4]
Study on roller-walker — improvement of locomotive efficiency of quadruped robots by passive wheels,
G. Endo and S. Hirose, “Study on roller-walker — improvement of locomotive efficiency of quadruped robots by passive wheels,” Advanced Robotics, vol. 26, no. 8-9, pp. 969–988, 2012
2012
-
[5]
Skating with a force controlled quadrupedal robot,
M. Bjelonic, C. D. Bellicoso, M. E. Tiryaki, and M. Hutter, “Skating with a force controlled quadrupedal robot,” in2018 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS), 2018, pp. 7555–7561
2018
-
[6]
Design and gait control of a rollerblading robot,
S. Chitta, F. Heger, and V . Kumar, “Design and gait control of a rollerblading robot,” in2004 IEEE International Conference on Robotics and Automation (ICRA), vol. 4, 2004, pp. 3944–3949
2004
-
[7]
Storytelling through characters at disney parks — sxsw 2023,
Walt Disney Imagineering, “Storytelling through characters at disney parks — sxsw 2023,” YouTube video, 2023. [Online]. Available: https://www.youtube.com/watch?v=lPqzLE4KjhI
2023
-
[8]
J. Guet al., “Skater: Synthesized kinematics for advanced traversing efficiency on a humanoid robot via roller skate swizzles,”arXiv preprint arXiv:2601.04948, 2026
-
[9]
Keep rollin’—whole-body motion control and planning for wheeled quadrupedal robots,
M. Bjelonic, C. D. Bellicoso, Y . de Viragh, D. Sako, F. D. Tresoldi, F. Jenelten, and M. Hutter, “Keep rollin’—whole-body motion control and planning for wheeled quadrupedal robots,”IEEE Robotics and Automation Letters, vol. 4, no. 2, p. 2116–2123, Apr. 2019
2019
-
[10]
A simple 2-dimensional model of speed skating which mimics observed forces and motions,
D. Fintelman, O. Braver, and A. Schwab, “A simple 2-dimensional model of speed skating which mimics observed forces and motions,” inMultibody dynamics, ECCOMAS Thematic Conference, Brugge, Belgium, vol. 511, 2011
2011
-
[11]
Zero-moment point - thirty five years of its life
M. Vukobratovic and B. Borovac, “Zero-moment point - thirty five years of its life.”I. J. Humanoid Robotics, vol. 1, pp. 157–173, 2004
2004
-
[12]
Locomotion approach of bipedal robot utilizing passive wheel without swing leg based on stability margin maximization and fall prevention functions,
K. Kimura, N. Imaoka, S. Noda, Y . Kakiuchi, K. Okada, and M. Inaba, “Locomotion approach of bipedal robot utilizing passive wheel without swing leg based on stability margin maximization and fall prevention functions,”ROBOMECH Journal, vol. 7, no. 1, p. 35, Oct 2020
2020
-
[13]
Inline skating motion genera- tor with passive wheels for small size humanoid robots,
N. Ziv, Y . Lee, and G. Ciaravella, “Inline skating motion genera- tor with passive wheels for small size humanoid robots,” in2010 IEEE/ASME International Conference on Advanced Intelligent Mecha- tronics, 2010, pp. 1391–1395
2010
-
[14]
Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills,
W. Xieet al., “Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[15]
Hitter: A humanoid table tennis robot via hierarchical planning and learning,
Z. Suet al., “Hitter: A humanoid table tennis robot via hierarchical planning and learning,”arXiv preprint arXiv:2508.21043, 2025
-
[16]
Real-time skating motion control of humanoid robots for acceleration and balancing,
N. Takasugi, K. Kojima, S. Nozawa, Y . Kakiuchi, K. Okada, and M. Inaba, “Real-time skating motion control of humanoid robots for acceleration and balancing,” in2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2016, pp. 1356– 1363
2016
-
[17]
HUSKY: Humanoid Skateboarding System via Physics-Aware Whole-Body Control
J. Han, D. Wang, C. Zhang, X. Liu, P. Luo, C. Bai, and X. Li, “Husky: Humanoid skateboarding system via physics-aware whole- body control,”arXiv preprint arXiv:2602.03205, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Booster gym: An end-to-end reinforcement learning framework for humanoid robot locomotion,
Y . Wang, P. Chen, X. Han, F. Wu, and M. Zhao, “Booster gym: An end-to-end reinforcement learning framework for humanoid robot locomotion,”arXiv preprint arXiv:2506.15132, 2025
-
[19]
Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning,
I. M. A. Nahrendra, B. Yu, and H. Myung, “Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 5078–5084
2023
-
[20]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Isaac gym: High performance gpu-based robotic simulation for robot learning,
V . Makoviychuket al., “Isaac gym: High performance gpu-based robotic simulation for robot learning,” inThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[22]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” in2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2012, pp. 5026–5033
2012
-
[23]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittalet al., “Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning,” 2025. [Online]. Available: https://arxiv.org/abs/2511.04831
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Curriculum learning,
Y . Bengio, J. Louradour, R. Collobert, and J. Weston, “Curriculum learning,” inProceedings of the 26th annual international conference on machine learning, 2009, pp. 41–48
2009
-
[25]
Automatic goal gen- eration for reinforcement learning agents,
C. Florensa, D. Held, X. Geng, and P. Abbeel, “Automatic goal gen- eration for reinforcement learning agents,” inInternational conference on machine learning. PMLR, 2018, pp. 1515–1528
2018
-
[26]
Rapid locomotion via reinforcement learning,
G. B. Margolis, G. Yang, K. Paigwar, T. Chen, and P. Agrawal, “Rapid locomotion via reinforcement learning,”The International Journal of Robotics Research, vol. 43, no. 4, pp. 572–587, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.