Expert-Aware Refusal Steering
Pith reviewed 2026-06-28 10:02 UTC · model grok-4.3
The pith
Refusal in mixture-of-experts LLMs can be steered using the output of a single expert.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying steering vectors to three open-source MoE LLMs, the authors show that refusal suppression works despite complex routing. They introduce two expert-aware methods using refusal-specific routing and expert directions. Refusal can be steered from a single expert, and the captured signals differ from routing behavior, indicating attention's substantial role in MoE refusal.
What carries the argument
Expert-aware refusal steering methods that leverage refusal-specific expert routing patterns and expert-specific steering directions to suppress normal refusal behavior.
Load-bearing premise
The refusal-specific expert routing patterns identified are stable across different harmful prompts and not artifacts of the particular datasets or models tested.
What would settle it
Testing the single-expert steering and routing-pattern analysis on a fresh set of harmful prompts or an additional unseen MoE model and finding that suppression fails or the identified patterns shift substantially.
Figures
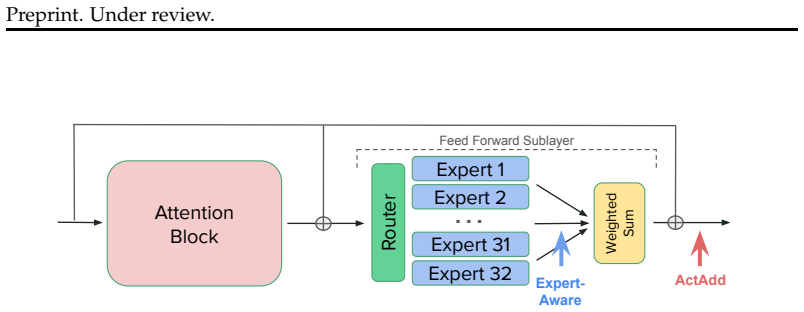
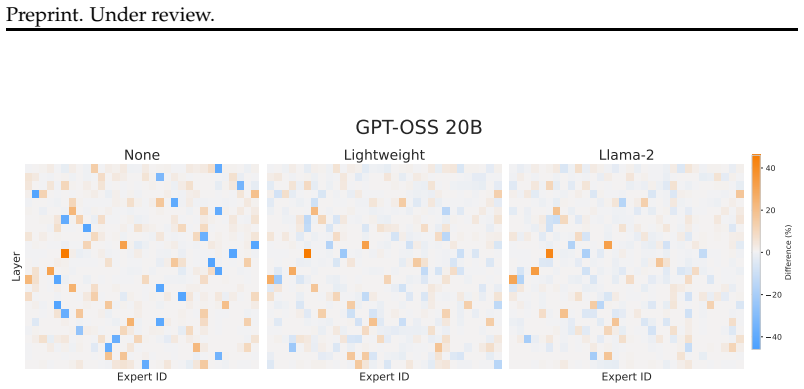
read the original abstract
Safety alignment in instruction-tuned large language models (LLMs) depends on a model's ability to reliably refuse to respond to harmful or disallowed requests. Recent work has shown that a steering vector can be applied to a dense LLM during inference to effectively suppress refusal behavior, inducing response to harmful requests. We extend this refusal steering method to three open-source Mixture-of-Experts (MoE) LLMs and find that steering performance is uninhibited by the complex routing patterns inherent to the MoE architecture. We then propose two expert-aware refusal steering methods that leverage refusal-specific expert routing patterns and expert-specific steering directions to suppress normal refusal behavior. We find that refusal behavior can be effectively steered based on the output of a single expert. Our results show that refusal signals captured by steering methods differ from expert routing behavior, suggesting a substantial role for attention in MoE refusal behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends refusal steering from dense LLMs to three open-source MoE models, showing that standard steering remains effective despite MoE routing. It introduces two expert-aware steering variants that exploit refusal-specific routing patterns and expert-specific directions, reporting that refusal can be steered from the output of a single expert. The results are interpreted as evidence that steering-derived refusal signals differ from routing behavior, implying a substantial role for attention in MoE refusal.
Significance. If the empirical claims hold after quantitative reporting and stability checks, the work would advance mechanistic understanding of safety alignment in MoE architectures by demonstrating that single-expert interventions suffice and by separating routing from attention-based refusal signals. This could support more efficient, targeted safety methods for large MoE systems.
major comments (3)
- [Abstract] Abstract: the abstract asserts empirical findings on steering performance and single-expert effectiveness but supplies no quantitative results, success rates, error bars, dataset sizes, or statistical controls; this absence is load-bearing for evaluating the central claim that refusal behavior can be effectively steered based on a single expert.
- [Experimental setup] Experimental setup (implied by the description of routing-pattern identification): refusal-specific expert routing patterns are identified without reported cross-validation, consistency metrics, or tests on held-out prompt distributions; if these patterns shift with new disallowed-request categories or phrasings, the single-expert steering method and the inference that steering differs from routing would not generalize.
- [Results/Discussion] Results/Discussion: the claim that 'refusal signals captured by steering methods differ from expert routing behavior' and therefore imply 'a substantial role for attention' lacks explicit comparison metrics, ablation controls, or quantitative separation between routing and attention contributions, which is required to support the mechanistic interpretation.
minor comments (2)
- [Methods] The two proposed expert-aware methods would benefit from explicit pseudocode or equations detailing how refusal-specific routing is combined with expert-specific steering vectors.
- [Abstract] Model names, sizes, and exact datasets used for the three MoE LLMs should be stated with references for reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate quantitative details, validation metrics, and additional controls as suggested.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts empirical findings on steering performance and single-expert effectiveness but supplies no quantitative results, success rates, error bars, dataset sizes, or statistical controls; this absence is load-bearing for evaluating the central claim that refusal behavior can be effectively steered based on a single expert.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revision we will add reported success rates for steering on the three MoE models, single-expert steering effectiveness, dataset sizes, and any error bars or statistical controls from the experiments. revision: yes
-
Referee: [Experimental setup] Experimental setup (implied by the description of routing-pattern identification): refusal-specific expert routing patterns are identified without reported cross-validation, consistency metrics, or tests on held-out prompt distributions; if these patterns shift with new disallowed-request categories or phrasings, the single-expert steering method and the inference that steering differs from routing would not generalize.
Authors: The routing patterns were identified from analyses across the prompt sets used in the main experiments. To address generalization concerns we will add explicit cross-validation details, consistency metrics across multiple runs, and results on held-out prompt categories in the methods section. revision: yes
-
Referee: [Results/Discussion] Results/Discussion: the claim that 'refusal signals captured by steering methods differ from expert routing behavior' and therefore imply 'a substantial role for attention' lacks explicit comparison metrics, ablation controls, or quantitative separation between routing and attention contributions, which is required to support the mechanistic interpretation.
Authors: We agree the mechanistic claim would benefit from stronger quantitative support. We will add ablation studies and direct comparison metrics (e.g., cosine similarity or correlation between steering vectors and routing activations) in the results to quantify the separation between routing and attention-based signals. revision: yes
Circularity Check
No circularity: purely empirical steering experiments
full rationale
The paper reports results from applying and measuring steering vectors on three open-source MoE LLMs, identifying single-expert effects and comparing routing vs. steering signals. No equations, fitted parameters, or derivations are presented whose outputs reduce to the inputs by construction. All claims rest on observed experimental outcomes rather than self-referential definitions or self-citation chains that would force the reported findings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear directions in activation space correspond to refusal behavior
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.09660 , year=
Steering moe llms via expert (de) activation , author=. arXiv preprint arXiv:2509.09660 , year=
-
[2]
arXiv preprint arXiv:2506.17368 , year=
Safex: Analyzing vulnerabilities of moe-based llms via stable safety-critical expert identification , author=. arXiv preprint arXiv:2506.17368 , year=
-
[3]
arXiv preprint arXiv:2502.11096 , year=
Mixture of Tunable Experts--Behavior Modification of DeepSeek-R1 at Inference Time , author=. arXiv preprint arXiv:2502.11096 , year=
-
[4]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Steering Language Models With Activation Engineering
Steering language models with activation engineering , author=. arXiv preprint arXiv:2308.10248 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2506.00085 , year=
COSMIC: Generalized Refusal Direction Identification in LLM Activations , author=. arXiv preprint arXiv:2506.00085 , year=
-
[7]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2411.09003 , year=
Refusal in llms is an affine function , author=. arXiv preprint arXiv:2411.09003 , year=
-
[9]
Advances in neural information processing systems , volume=
Towards understanding the mixture-of-experts layer in deep learning , author=. Advances in neural information processing systems , volume=
-
[10]
arXiv preprint arXiv:2402.14800 , year=
Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models , author=. arXiv preprint arXiv:2402.14800 , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
On the representation collapse of sparse mixture of experts , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
OLMoE: Open Mixture-of-Experts Language Models
Olmoe: Open mixture-of-experts language models , author=. arXiv preprint arXiv:2409.02060 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2502.10928 , year=
Probing Semantic Routing in Large Mixture-of-Expert Models , author=. arXiv preprint arXiv:2502.10928 , year=
-
[14]
arXiv preprint arXiv:2402.01739 , year=
Openmoe: An early effort on open mixture-of-experts language models , author=. arXiv preprint arXiv:2402.01739 , year=
-
[15]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Artprompt: Ascii art-based jailbreak attacks against aligned llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
DeepInception: Hypnotize Large Language Model to Be Jailbreaker , author=
-
[17]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Large Language Models Are Involuntary Truth-Tellers: Exploiting Fallacy Failure for Jailbreak Attacks , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[18]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
A closer look into mixture-of-experts in large language models , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[19]
2025 , howpublished =
Open LLM Leaderboard , author =. 2025 , howpublished =
2025
-
[20]
Neural computation , volume=
Adaptive mixtures of local experts , author=. Neural computation , volume=. 1991 , publisher=
1991
-
[21]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models , author=. arXiv preprint arXiv:2401.06066 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[25]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[27]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[28]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
The instruction hierarchy: Training llms to prioritize privileged instructions , author=. arXiv preprint arXiv:2404.13208 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[31]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
On the impact of fine-tuning on chain-of-thought reasoning , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[33]
arXiv preprint arXiv:2505.14810 , year=
Scaling reasoning, losing control: Evaluating instruction following in large reasoning models , author=. arXiv preprint arXiv:2505.14810 , year=
-
[34]
arXiv preprint arXiv:2402.05119 , year=
A Closer Look at the Limitations of Instruction Tuning , author=. arXiv preprint arXiv:2402.05119 , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
Jailbreakbench: An open robustness benchmark for jailbreaking large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[37]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Hotflip: White-box adversarial examples for text classification , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[40]
arXiv preprint arXiv:2603.14278 , year=
Activation Surgery: Jailbreaking White-box LLMs without Touching the Prompt , author=. arXiv preprint arXiv:2603.14278 , year=
-
[41]
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
International conference on learning representations , year=
Isotropy in the contextual embedding space: Clusters and manifolds , author=. International conference on learning representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.