Steal the Patch Size: Adversarially Manipulate Vision-Language Models
Pith reviewed 2026-07-02 19:28 UTC · model grok-4.3
The pith
A black-box attack recovers private patch sizes and preprocessing pipelines in vision-language models by exploiting grid alignment side channels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
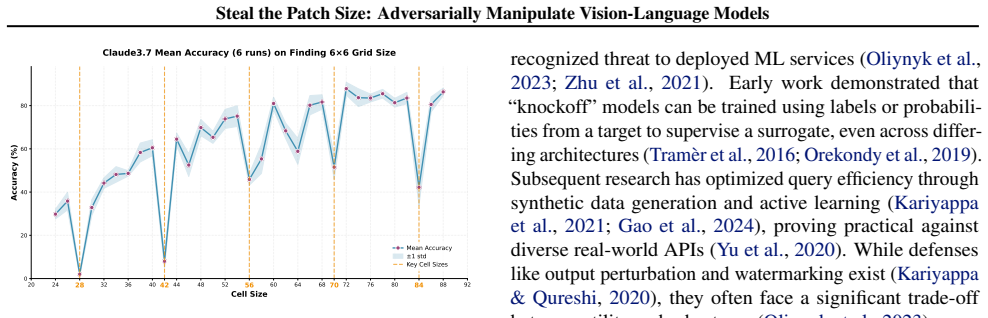
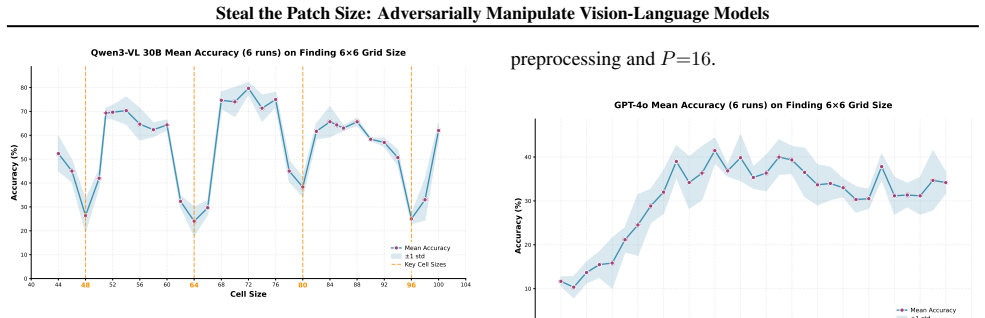
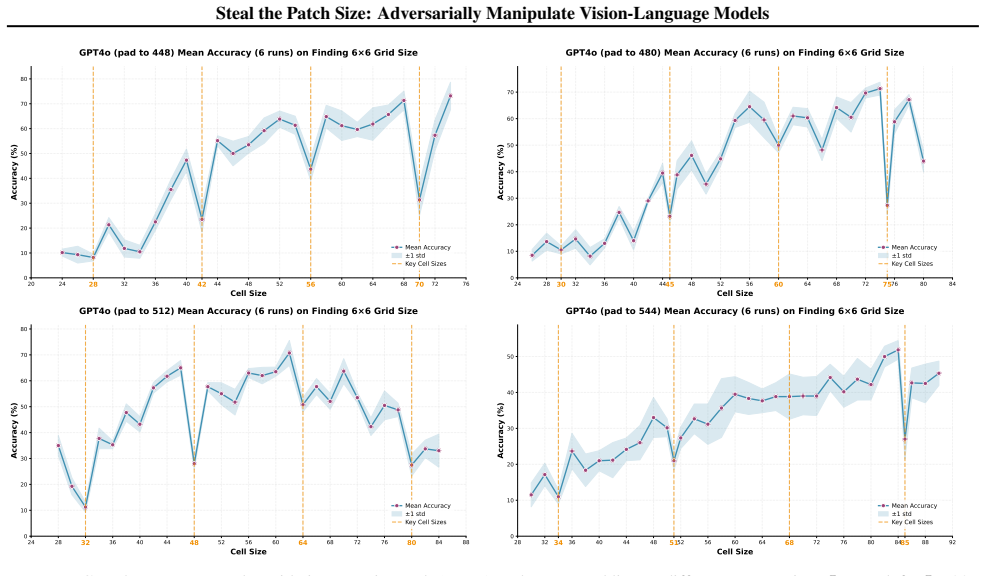
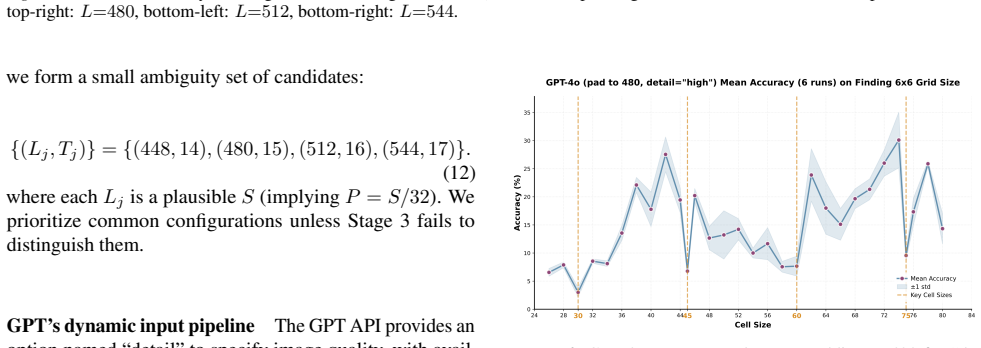
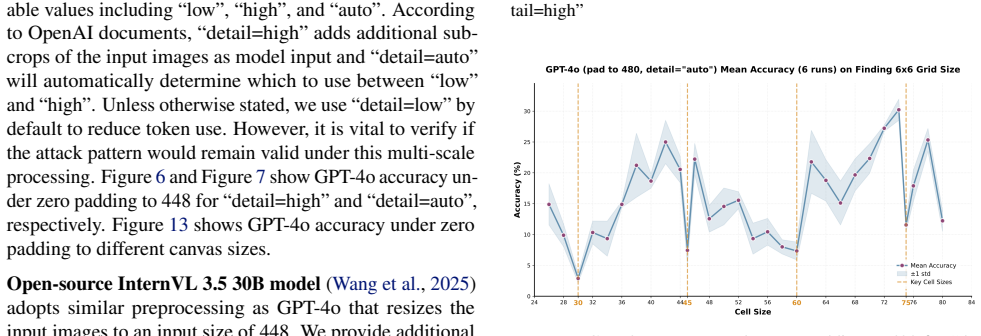
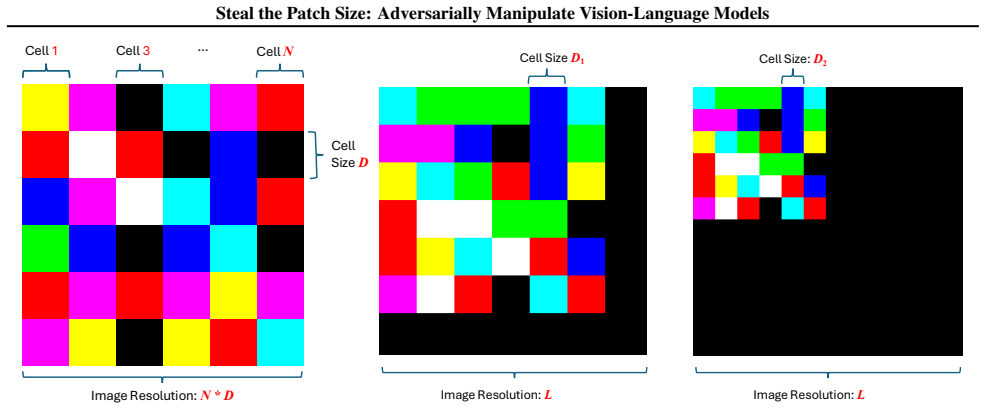
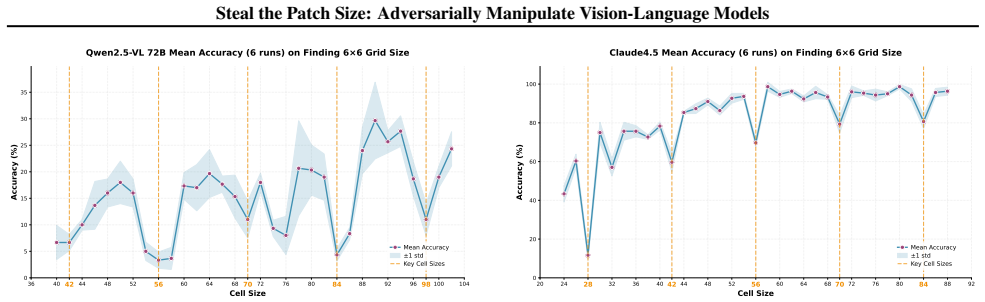
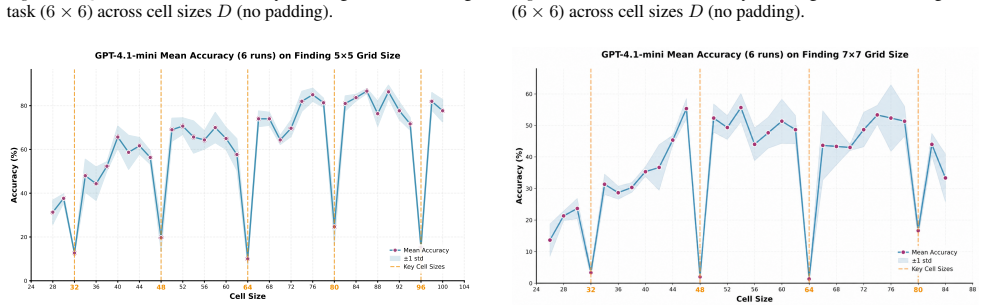
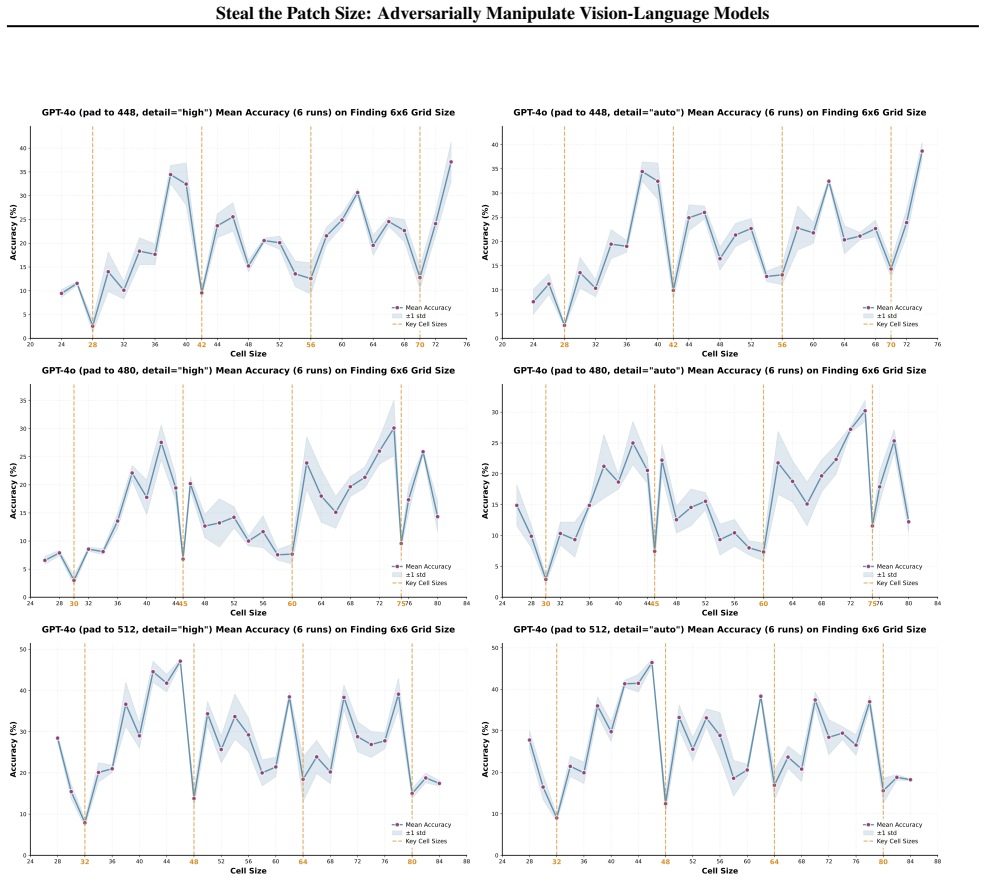
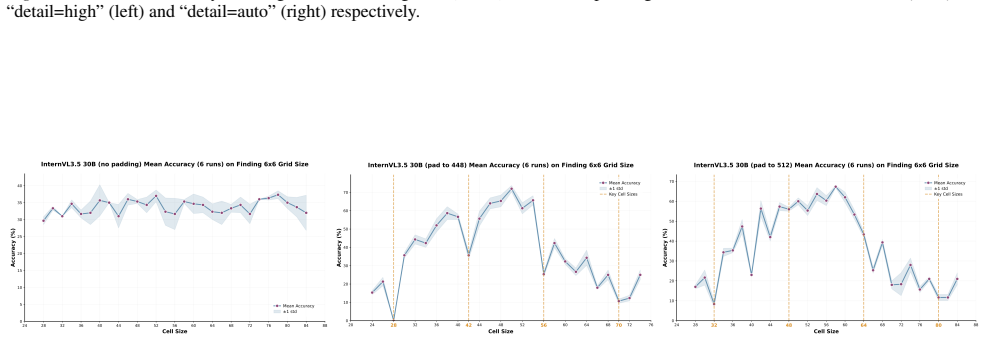
The patch size is recovered by measuring periodic accuracy collapses on synthetic grid images aligned to the hidden patch grid; padding and consistency checks further identify whether preprocessing uses dynamic or fixed resolution and recover the target resize value, allowing full recovery of private vision-tokenizer configurations.
What carries the argument
ViT-style patchification side channel that erases boundary cues and produces accuracy drops when a synthetic grid aligns with the hidden patch grid.
If this is right
- Recovered tokenizer parameters enable preprocessing-aware transfer attacks on vision-language models.
- The leakage supports model-targeted adversarial manipulation that accounts for the actual input pipeline.
- The attack applies equally to open-source models and to closed models such as GPT and Claude.
Where Pith is reading between the lines
- The same grid-sweep technique could be tested on other patch-based vision encoders outside the VLM setting.
- Randomizing patch alignment or adding input noise might reduce the reliability of the observed accuracy collapses.
- Knowledge of the exact resize resolution could be used to craft more precise synthetic inputs for further black-box probing.
Load-bearing premise
The periodic accuracy drops are caused specifically by alignment with the hidden patch grid erasing boundary cues at tokenization, rather than by other unrelated factors in the model's pipeline or input handling.
What would settle it
If accuracy does not exhibit periodic drops at cell sizes that are multiples of the suspected patch size when grids are aligned, or if drops occur at the same rate regardless of alignment, the side-channel explanation would be falsified.
Figures

read the original abstract
We present a black-box model-stealing attack that recovers private vision-tokenizer configurations of deployed vision-language models (VLMs), including the visual patch size and input preprocessing pipeline. The key idea is a task-level side channel induced by ViT-style patchification: when a synthetic grid image is aligned with the hidden patch grid, boundary cues are erased at tokenization, causing periodic accuracy drop. By sweeping the grid cell size and measuring these collapses, we infer the patch size; by introducing padding and a consistency-check test, we further identify whether preprocessing is dynamic- or fixed-resolution and recover the target resize resolution. Across open-source Qwen-VL variants and proprietary models including GPT and Claude, we reliably recover tokenizer-related parameters. Finally, we show that such leakage enables preprocessing-aware transfer attacks and model-targeted adversarial manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a black-box attack to recover private vision-tokenizer parameters (patch size and preprocessing pipeline) of VLMs. The attack exploits periodic accuracy collapses on synthetic grid images whose cell size is swept; collapses are attributed to boundary-cue erasure when the grid aligns with the hidden ViT patch grid. Padding and a consistency-check test are used to distinguish dynamic vs. fixed-resolution preprocessing and recover the target resize resolution. Experiments report successful recovery on open Qwen-VL variants and proprietary models (GPT, Claude), with downstream use for preprocessing-aware transfer attacks.
Significance. If the periodicity-to-patch-size mapping is robustly causal, the work provides a practical, task-level side channel for extracting tokenizer configuration from deployed VLMs. This is relevant for understanding leakage in production systems and for designing preprocessing-aware adversarial attacks. The empirical nature on both open and closed models is a strength, though the result remains an observational measurement procedure rather than a parameter-free derivation.
major comments (2)
- [§3, §4] §3 (method) and §4 (experiments): the central inference that observed periodic accuracy drops are produced specifically by alignment with the hidden patch grid (erasing boundary cues at tokenization) is load-bearing for the entire attack. No control is described that rules out alternative sources of commensurate periodicity, such as the convolutional stem, positional embeddings, or language-head sensitivity to regular-grid token statistics. Without such a disambiguation experiment (e.g., non-grid periodic patterns or task-ablated runs), the recovered “patch size” could be an artifact of the measurement pipeline.
- [Table 2, Figure 3] Table 2 / Figure 3 (proprietary-model results): recovery rates are reported without error bars, multiple random seeds, or statistical tests for the periodicity detection threshold. Given that the reader’s strongest claim rests on reliable detection of collapses, the absence of these quantifications weakens the claim that the method “reliably recover[s] tokenizer-related parameters” across GPT and Claude.
minor comments (2)
- [§3] Notation for grid cell size and padding parameters is introduced without a consolidated table; a single reference table would improve readability.
- [Abstract, §4] The abstract states success on “open-source Qwen-VL variants” but the experimental section does not list the exact model identifiers or checkpoint versions used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline revisions to strengthen the causal claims and statistical reporting.
read point-by-point responses
-
Referee: [§3, §4] §3 (method) and §4 (experiments): the central inference that observed periodic accuracy drops are produced specifically by alignment with the hidden patch grid (erasing boundary cues at tokenization) is load-bearing for the entire attack. No control is described that rules out alternative sources of commensurate periodicity, such as the convolutional stem, positional embeddings, or language-head sensitivity to regular-grid token statistics. Without such a disambiguation experiment (e.g., non-grid periodic patterns or task-ablated runs), the recovered “patch size” could be an artifact of the measurement pipeline.
Authors: We agree that additional controls are needed to strengthen the causal attribution to patch-grid alignment. While the observed periods align with known patch sizes on open Qwen-VL models (where ground truth is available) and the effect is consistent with boundary-cue erasure at tokenization, we will add disambiguation experiments in the revision. These will include sweeps with non-grid periodic patterns and task-ablated runs on open models to rule out contributions from the convolutional stem, positional embeddings, or language-head statistics. revision: yes
-
Referee: [Table 2, Figure 3] Table 2 / Figure 3 (proprietary-model results): recovery rates are reported without error bars, multiple random seeds, or statistical tests for the periodicity detection threshold. Given that the reader’s strongest claim rests on reliable detection of collapses, the absence of these quantifications weakens the claim that the method “reliably recover[s] tokenizer-related parameters” across GPT and Claude.
Authors: We agree that the presentation of proprietary-model results would benefit from greater statistical rigor. In the revised manuscript we will rerun the periodicity sweeps on GPT and Claude with multiple random seeds (where query access permits), add error bars to Table 2 and Figure 3, and include statistical tests for the periodicity detection threshold to quantify reliability. revision: yes
Circularity Check
Empirical side-channel measurement procedure is self-contained with no derivations or self-referential reductions
full rationale
The paper describes a black-box attack that infers patch size and preprocessing by sweeping synthetic grid cell sizes and observing periodic accuracy collapses, then using padding and consistency checks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method. The central claim is an empirical procedure whose validity rests on external verification against open-source models and proprietary APIs rather than internal definitions or prior author work. This matches the default case of a non-circular empirical measurement.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Periodic accuracy drops on synthetic grid images are caused by boundary cue erasure at tokenization when the grid aligns with the hidden patch grid.
Reference graph
Works this paper leans on
-
[1]
2018 IEEE symposium on security and privacy (SP) , pages=
Stealing hyperparameters in machine learning , author=. 2018 IEEE symposium on security and privacy (SP) , pages=. 2018 , organization=
2018
-
[2]
Stealing Neural Networks via Timing Side Channels
Stealing neural networks via timing side channels , author=. arXiv preprint arXiv:1812.11720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[4]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[5]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[6]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[7]
Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security , pages=
Stolenencoder: stealing pre-trained encoders in self-supervised learning , author=. Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security , pages=
2022
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Fingerprinting Deep Neural Networks Globally via Universal Adversarial Perturbations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[9]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
InternVL3. 5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Anyattack: Towards Large-scale Self-supervised Adversarial Attacks on Vision-language Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[11]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Instructional fingerprinting of large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[12]
International Conference on Machine Learning , pages=
Understanding and Defending Patched-based Adversarial Attacks for Vision Transformer , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Language Models as Black-Box Optimizers for Vision-Language Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[14]
Imgtrojan: Jailbreaking vision-language models with one image , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[15]
MMBench: Is Your Multi-modal Model an All-around Player?
MMBench: Is Your Multi-modal Model an All-around Player? , author=. arXiv preprint arXiv:2307.06281 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
IEEE Transactions on Information Forensics and Security , volume=
AugSteal: advancing model steal with data augmentation in active learning frameworks , author=. IEEE Transactions on Information Forensics and Security , volume=. 2024 , publisher=
2024
-
[17]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maze: Data-free model stealing attack using zeroth-order gradient estimation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[18]
2022 IEEE Symposium on Security and Privacy (SP) , pages=
Model stealing attacks against inductive graph neural networks , author=. 2022 IEEE Symposium on Security and Privacy (SP) , pages=. 2022 , organization=
2022
-
[19]
30th USENIX Security Symposium (USENIX Security 21) , year=
Hermes attack: Steal \ DNN \ models with lossless inference accuracy , author=. 30th USENIX Security Symposium (USENIX Security 21) , year=
-
[20]
25th USENIX security symposium (USENIX Security 16) , pages=
Stealing machine learning models via prediction \ APIs \ , author=. 25th USENIX security symposium (USENIX Security 16) , pages=
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Knockoff nets: Stealing functionality of black-box models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
29th USENIX security symposium (USENIX Security 20) , pages=
High accuracy and high fidelity extraction of neural networks , author=. 29th USENIX security symposium (USENIX Security 20) , pages=
-
[23]
ACM Computing Surveys , volume=
I know what you trained last summer: A survey on stealing machine learning models and defences , author=. ACM Computing Surveys , volume=. 2023 , publisher=
2023
-
[24]
2019 IEEE European Symposium on Security and Privacy (EuroS&P) , pages=
PRADA: protecting against DNN model stealing attacks , author=. 2019 IEEE European Symposium on Security and Privacy (EuroS&P) , pages=. 2019 , organization=
2019
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Defending against model stealing attacks with adaptive misinformation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[26]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards data-free model stealing in a hard label setting , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[27]
, author=
CloudLeak: Large-scale deep learning models stealing through adversarial examples. , author=. NDSS , volume=
-
[28]
arXiv preprint arXiv:2505.01050 , year=
Transferable adversarial attacks on black-box vision-language models , author=. arXiv preprint arXiv:2505.01050 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
On evaluating adversarial robustness of large vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
arXiv preprint arXiv:2309.11751 , year=
How Robust is Google's Bard to Adversarial Image Attacks? , author=. arXiv preprint arXiv:2309.11751 , year=
-
[31]
European conference on computer vision , pages=
Mmbench: Is your multi-modal model an all-around player? , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[32]
K, Alex and Hamner, Benand and Goodfellow, Ian , title =
-
[33]
arXiv preprint arXiv:2309.17425 , year=
Data Filtering Networks , author=. arXiv preprint arXiv:2309.17425 , year=
-
[34]
Sigmoid Loss for Language Image Pre-Training
Sigmoid loss for language image pre-training , author=. arXiv preprint arXiv:2303.15343 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Advances in Neural Information Processing Systems , volume=
Datacomp: In search of the next generation of multimodal datasets , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Proceedings of the 40th International Conference on Machine Learning , volume=
Understanding and Defending Patched-based Adversarial Attacks for Vision Transformer , author=. Proceedings of the 40th International Conference on Machine Learning , volume=
-
[37]
Computer Vision -- ECCV 2022 , volume=
ViP: Unified Certified Detection and Recovery for Patch Attack with Vision Transformers , author=. Computer Vision -- ECCV 2022 , volume=
2022
-
[38]
Advances in Neural Information Processing Systems , volume=
Decision-based Black-box Attack Against Vision Transformers via Patch-wise Adversarial Removal , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.