SORA: Free Second-Order Attacks in Fast Adversarial Training
Pith reviewed 2026-06-28 19:02 UTC · model grok-4.3
The pith
SORA adapts perturbation step sizes during fast adversarial training using a gradient alignment metric to prevent catastrophic overfitting and improve both robustness and clean accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
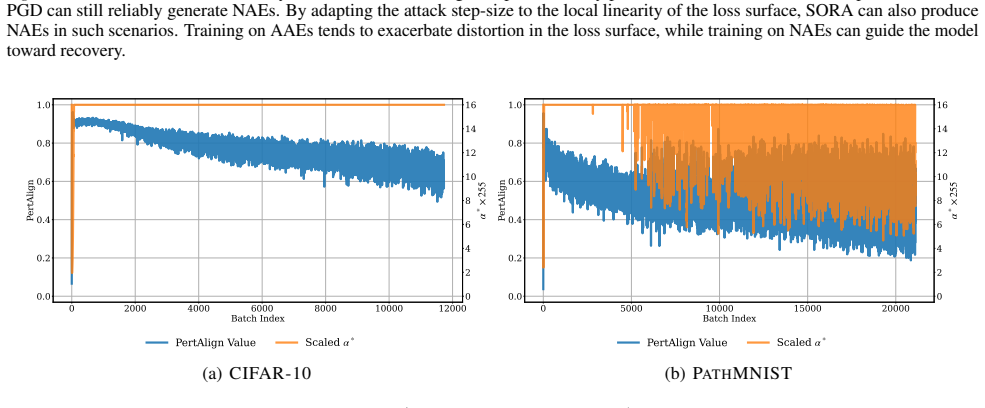
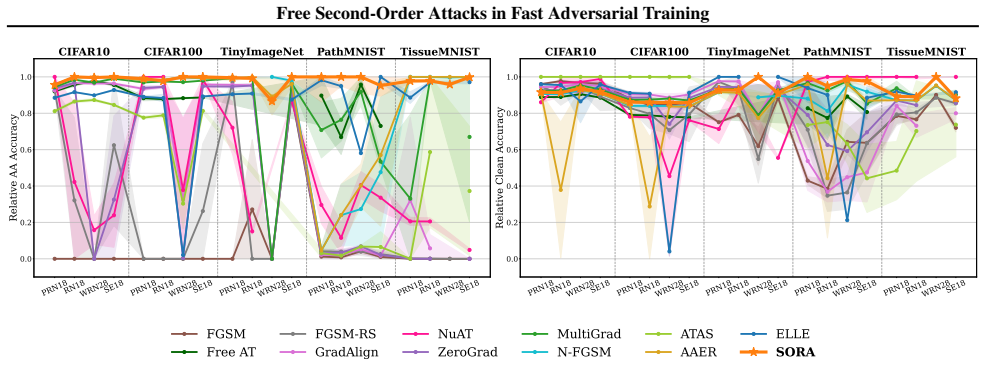
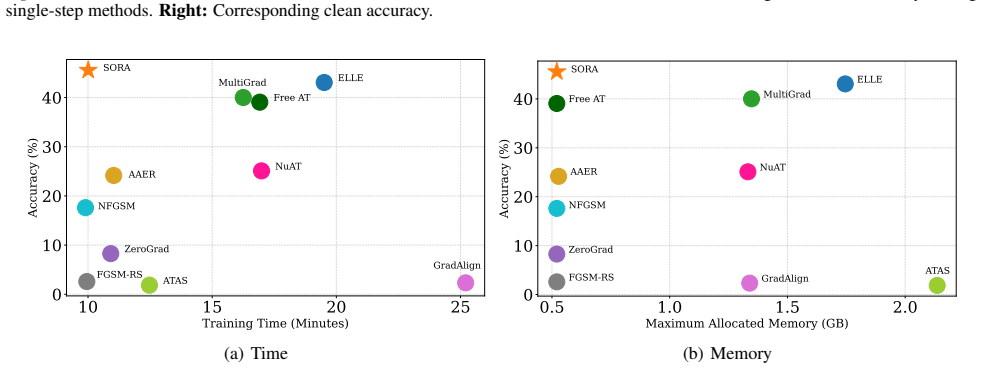
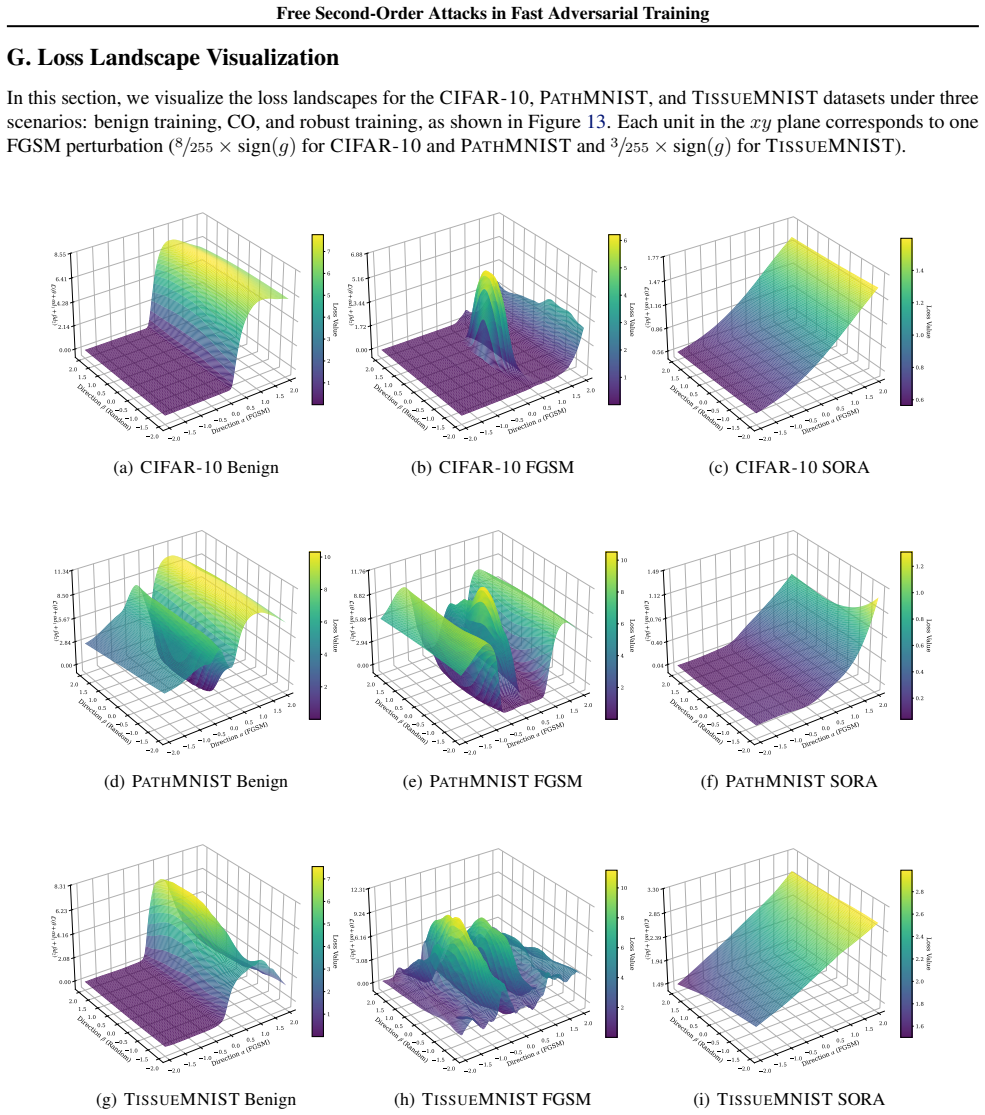
SORA is an adaptive step-size adversarial training procedure that dynamically changes perturbation magnitudes according to the PertAlign score. PertAlign measures how aligned the gradients remain across attack iterations and thereby signals the onset of catastrophic overfitting. By responding to this signal the method eliminates the collapse, reaches state-of-the-art robust and clean accuracy, and transfers across data sets and models with unchanged hyperparameters.
What carries the argument
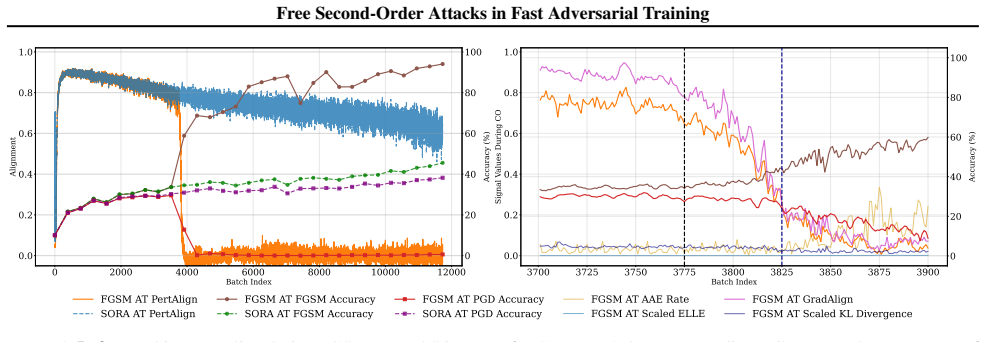
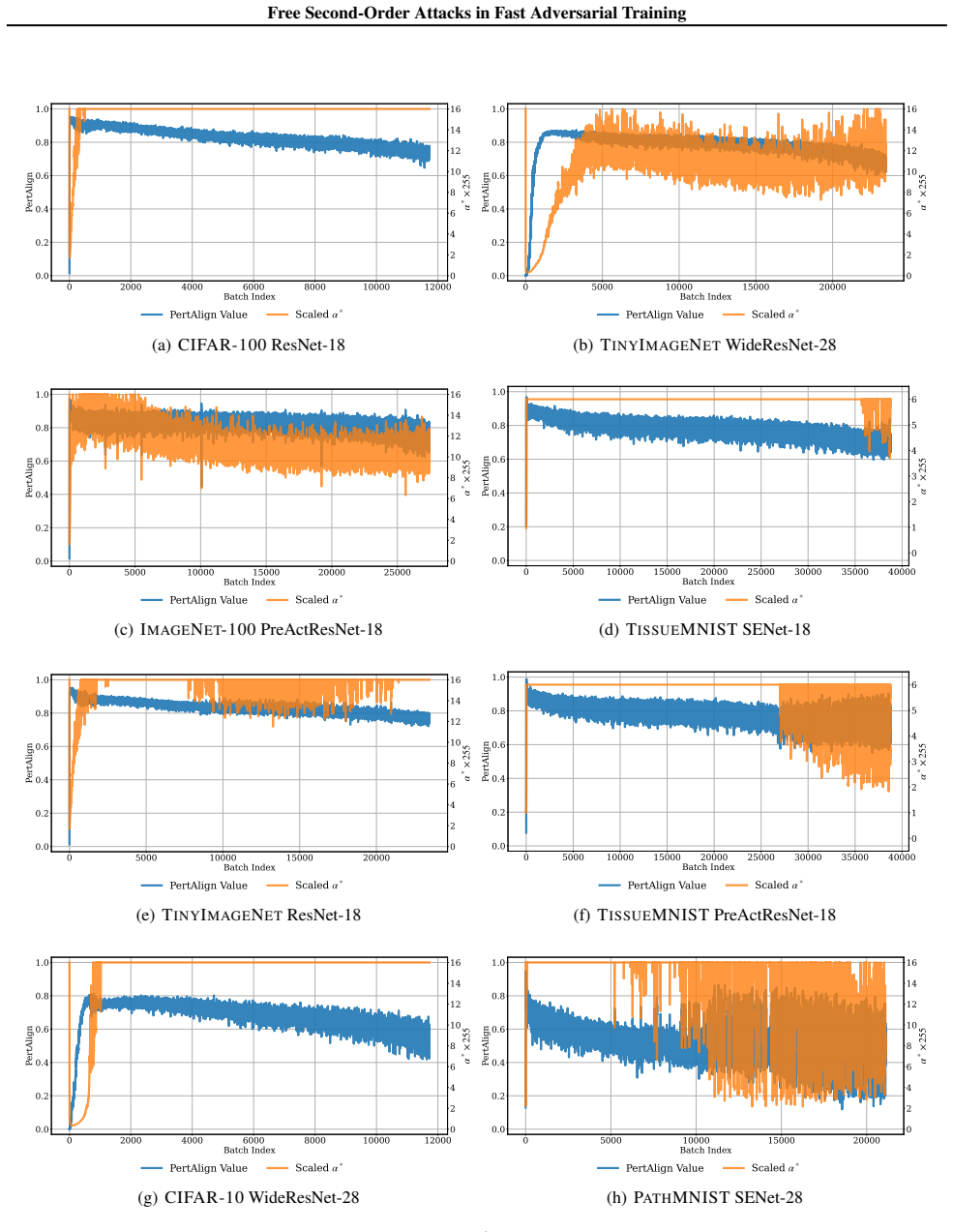
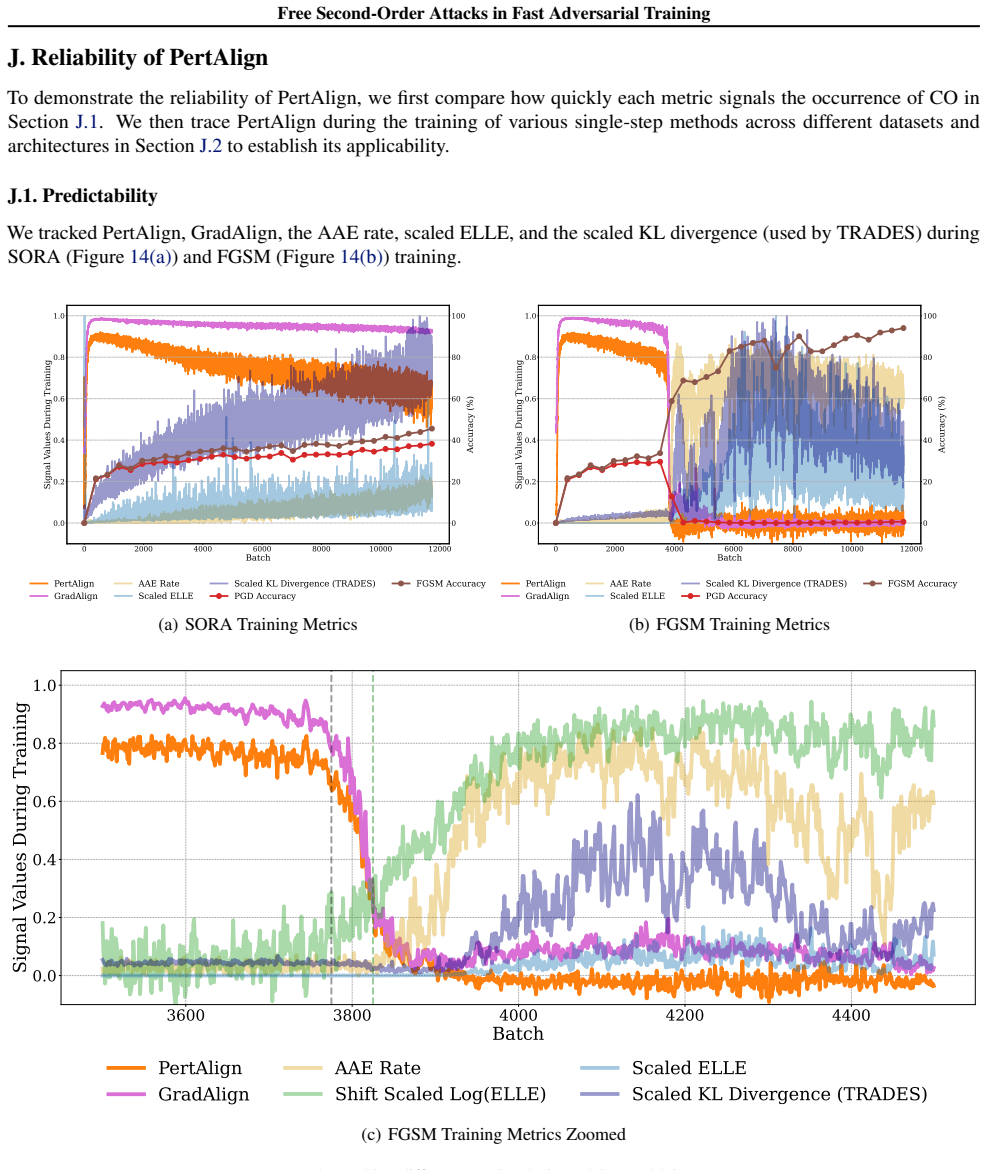
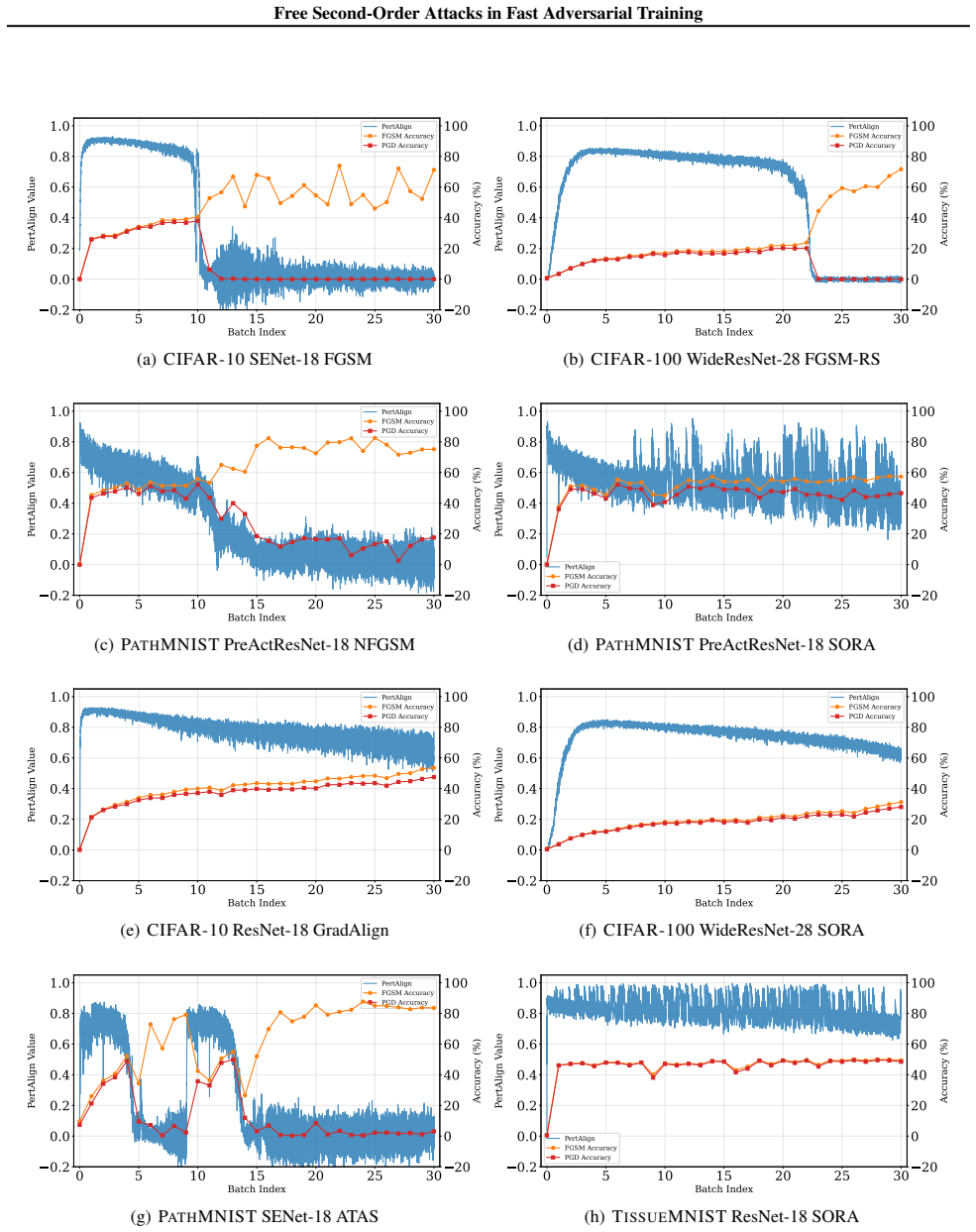
PertAlign, a metric that quantifies gradient alignment across attack stages to predict catastrophic overfitting onset and drives the adaptive step-size rule inside SORA.
If this is right
- SORA removes the need for dataset-specific hyperparameter search in fast adversarial training.
- The same fixed hyperparameter set yields both higher clean accuracy and competitive robustness on multiple benchmarks.
- Perturbation variability introduced by the adaptive rule improves robust generalization beyond what fixed-magnitude attacks achieve.
- The method remains computationally negligible because PertAlign adds almost no overhead.
Where Pith is reading between the lines
- If gradient alignment tracks a general property of adversarial loss surfaces, the same signal could guide step-size choice in multi-step or certified training pipelines.
- The success with fixed hyperparameters suggests that earlier methods may have required per-dataset tuning partly because they lacked an online indicator of overfitting risk.
- Monitoring loss-surface geometry through cheap alignment statistics may be useful in other robust-optimization settings where sudden performance drops occur.
Load-bearing premise
PertAlign derived from gradient alignment across attack stages reliably forecasts the start of catastrophic overfitting in time for the adaptation rule to act without dataset-specific retuning.
What would settle it
Run SORA on a previously unseen architecture or data set and check whether multi-step adversarial accuracy still drops sharply after the PertAlign threshold is crossed.
Figures


read the original abstract
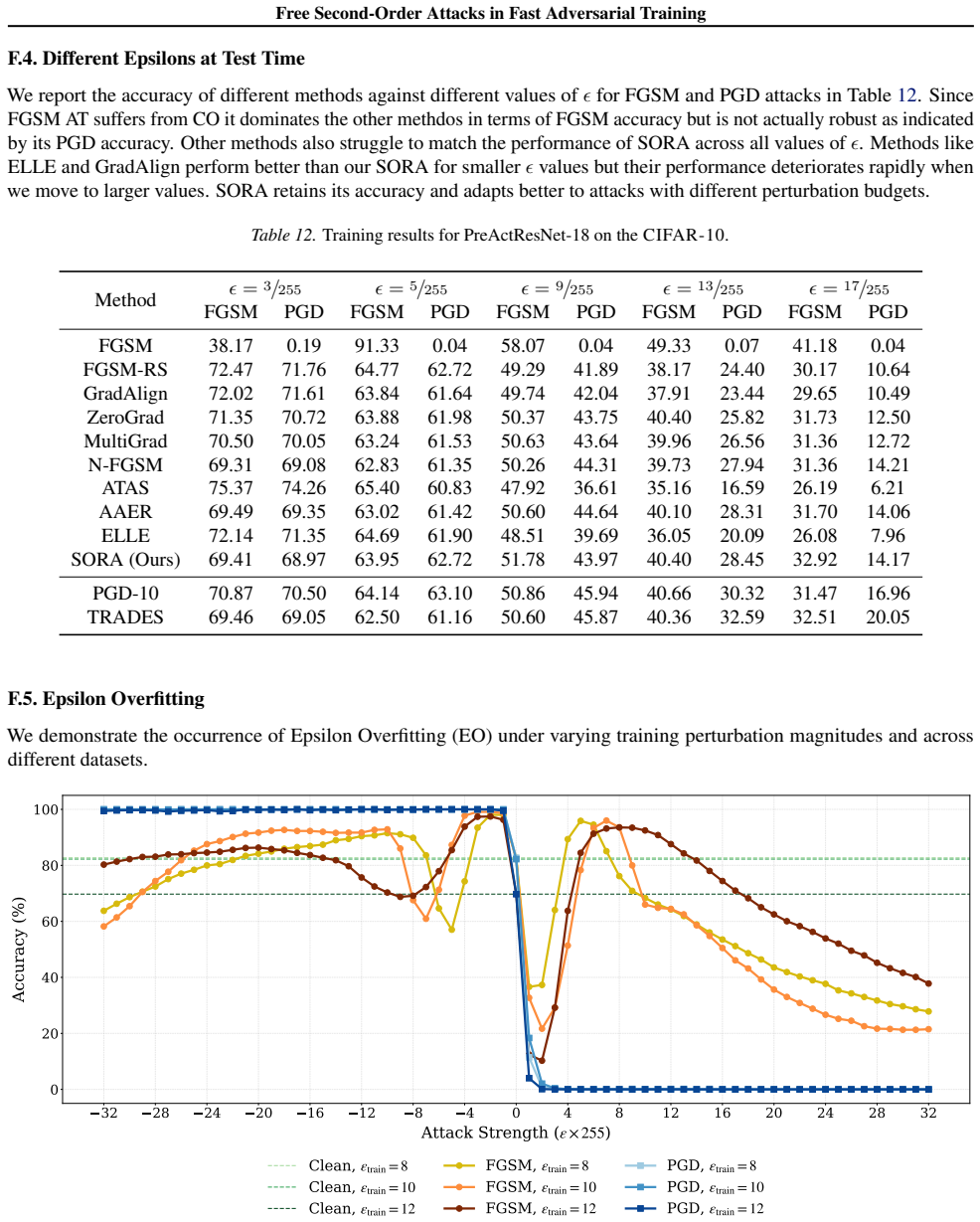
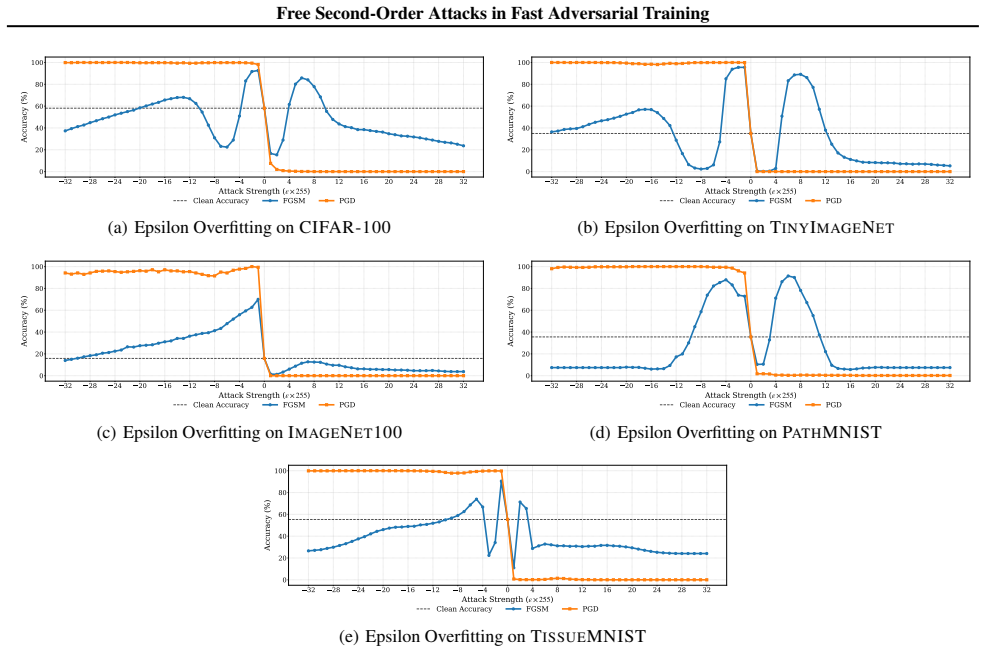
Adversarial Training (AT) is a leading defense against adversarial examples but often suffers from Catastrophic Overfitting (CO) in efficient single-step variants, where robustness to multi-step attacks collapses despite high single-step performance. We address this failure mode with two contributions. First, we formalize Epsilon Overfitting (EO), a perspective in which fixed perturbation magnitudes and directions exacerbate CO, and show that introducing perturbation variability significantly improves robust generalization across different architectures and datasets. Second, we propose PertAlign (Perturbation Alignment), a theoretically grounded, computationally negligible metric that predicts CO onset by measuring gradient alignment across attack stages. Leveraging these insights, we introduce SORA, an adaptive step-size AT method that dynamically adjusts perturbations based on loss surface geometry. SORA consistently prevents CO, achieves state-of-the-art robustness and clean accuracy, and generalizes across datasets and architectures using a single fixed set of hyperparameters, which is essential for applicability in fast AT. Extensive experiments on diverse datasets and architectures show that SORA matches or surpasses the robustness of prior methods while delivering higher clean accuracy and superior efficiency. Code is available at https://github.com/SecondOrderAT/SORA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address catastrophic overfitting (CO) in fast adversarial training by formalizing Epsilon Overfitting (EO) as arising from fixed perturbation magnitudes/directions, introducing PertAlign as a theoretically grounded metric that predicts CO onset via gradient alignment across attack stages, and proposing SORA as an adaptive step-size method that dynamically adjusts perturbations based on loss surface geometry. It asserts that SORA prevents CO, achieves SOTA robustness and clean accuracy, and generalizes across datasets/architectures with one fixed hyperparameter set, backed by extensive experiments and public code.
Significance. If the results hold, the work would be significant for practical adversarial robustness, as a method that avoids CO and dataset-specific tuning while maintaining efficiency would improve applicability of fast AT. The public code availability is a clear strength for reproducibility.
major comments (3)
- [Abstract] Abstract: the central claim that PertAlign is 'theoretically grounded' and enables a 'single fixed set of hyperparameters' without post-hoc tuning rests on an unshown mapping from the alignment statistic to the step-size rule; no equation or derivation is provided to establish independence from the training loss surface.
- [Method (PertAlign)] Method section on PertAlign: the metric is described as derived from gradient alignment on the same loss surface used for training, which creates a potential circularity risk for predicting CO onset; an explicit test showing that the statistic tracks multi-step robustness collapse independently of the fitted adaptive behavior is required to support the no-tuning claim.
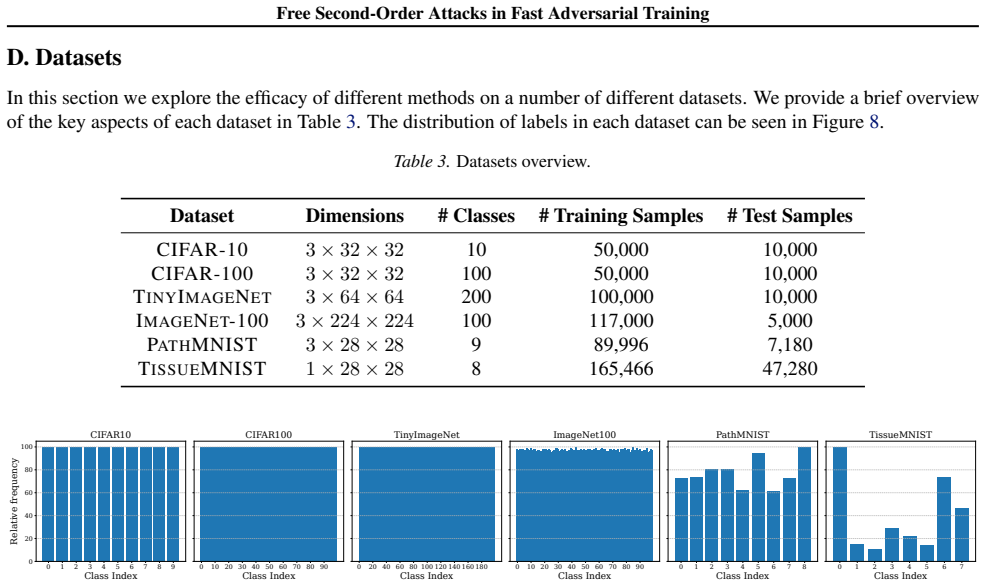
- [Experiments] Experiments: the generalization and SOTA claims are load-bearing, yet the absence of error bars, multiple random seeds, or statistical tests leaves open whether observed improvements over baselines are robust or could be explained by variance.
minor comments (2)
- The abstract states 'negligible cost' for PertAlign; the experiments should report wall-clock overhead relative to standard fast AT to substantiate this.
- Tables comparing to prior methods should explicitly state whether all baselines use the same hyperparameter search budget as SORA.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that PertAlign is 'theoretically grounded' and enables a 'single fixed set of hyperparameters' without post-hoc tuning rests on an unshown mapping from the alignment statistic to the step-size rule; no equation or derivation is provided to establish independence from the training loss surface.
Authors: We agree that the abstract's reference to theoretical grounding would be strengthened by an explicit derivation of the mapping from PertAlign to the step-size rule and its independence from the training loss surface. In the revised manuscript we will add this derivation in the Method section, including the relevant equation linking the alignment statistic to the adaptive rule. revision: yes
-
Referee: [Method (PertAlign)] Method section on PertAlign: the metric is described as derived from gradient alignment on the same loss surface used for training, which creates a potential circularity risk for predicting CO onset; an explicit test showing that the statistic tracks multi-step robustness collapse independently of the fitted adaptive behavior is required to support the no-tuning claim.
Authors: We acknowledge the circularity concern. To support the no-tuning claim we will add an explicit experiment in the revised paper that evaluates PertAlign on fixed-step-size training runs (independent of SORA) and shows that the metric still tracks the onset of multi-step robustness collapse. revision: yes
-
Referee: [Experiments] Experiments: the generalization and SOTA claims are load-bearing, yet the absence of error bars, multiple random seeds, or statistical tests leaves open whether observed improvements over baselines are robust or could be explained by variance.
Authors: We agree that the absence of error bars and multi-seed statistics weakens the load-bearing claims. In the revision we will report all main results over at least three random seeds with error bars and include statistical significance tests for the key comparisons. revision: yes
Circularity Check
No circularity; derivation self-contained against external benchmarks
full rationale
The provided abstract and description introduce EO as a formalization and PertAlign as a new metric based on gradient alignment across attack stages, with SORA as the resulting adaptive method. No equations, self-citations, or fitted parameters are shown that reduce any prediction or central claim to its own inputs by construction. The claims rest on the metric's independent predictive power for CO onset and generalization with fixed hyperparameters, which the text presents as externally verifiable through experiments rather than tautological. This is the most common honest finding for papers without explicit self-referential reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2014 , eprint=
Intriguing properties of neural networks , author=. 2014 , eprint=
2014
-
[2]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow and Jonathon Shlens and Christian Szegedy , year=. 1412.6572 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Universal adversarial perturbations
Seyed-Mohsen Moosavi-Dezfooli and Alhussein Fawzi and Omar Fawzi and Pascal Frossard , year=. 1610.08401 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry and Aleksandar Makelov and Ludwig Schmidt and Dimitris Tsipras and Adrian Vladu , year=. 1706.06083 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Dimitris Tsipras and Shibani Santurkar and Logan Engstrom and Alexander Turner and Aleksander Madry , year=. 1805.12152 , archivePrefix=
-
[6]
Davis and Tom Goldstein , year=
Ali Shafahi and Mahyar Najibi and Zheng Xu and John Dickerson and Larry S. Davis and Tom Goldstein , year=. 1811.11304 , archivePrefix=
-
[7]
Gavin Weiguang Ding and Yash Sharma and Kry Yik Chau Lui and Ruitong Huang , year=. 1812.02637 , archivePrefix=
-
[8]
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
Anish Athalye and Nicholas Carlini and David Wagner , year=. 1802.00420 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Theoretically Principled Trade-off between Robustness and Accuracy
Hongyang Zhang and Yaodong Yu and Jiantao Jiao and Eric P. Xing and Laurent El Ghaoui and Michael I. Jordan , year=. 1901.08573 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[10]
Davis and Gavin Taylor and Tom Goldstein , year=
Ali Shafahi and Mahyar Najibi and Amin Ghiasi and Zheng Xu and John Dickerson and Christoph Studer and Larry S. Davis and Gavin Taylor and Tom Goldstein , year=. 1904.12843 , archivePrefix=
-
[11]
Dinghuai Zhang and Tianyuan Zhang and Yiping Lu and Zhanxing Zhu and Bin Dong , year=. 1905.00877 , archivePrefix=
-
[12]
Haizhong Zheng and Ziqi Zhang and Juncheng Gu and Honglak Lee and Atul Prakash , year=. 1912.11969 , archivePrefix=
-
[13]
Francesco Croce and Matthias Hein , year=. 2003.01690 , archivePrefix=
-
[14]
Rulin Shao and Zhouxing Shi and Jinfeng Yi and Pin-Yu Chen and Cho-Jui Hsieh , year=. 2103.15670 , archivePrefix=
-
[15]
2020 , eprint=
Fast is better than free: Revisiting adversarial training , author=. 2020 , eprint=
2020
-
[16]
Leo Schwinn and René Raab and Björn Eskofier , year=. 2002.10097 , archivePrefix=
- [17]
-
[18]
Bai Li and Shiqi Wang and Suman Jana and Lawrence Carin , year=. 2006.03089 , archivePrefix=
-
[19]
Maksym Andriushchenko and Nicolas Flammarion , year=. 2007.02617 , archivePrefix=
-
[20]
Hoki Kim and Woojin Lee and Jaewook Lee , year=. 2010.01799 , archivePrefix=
-
[21]
2021 , url=
Gaurang Sriramanan and Sravanti Addepalli and Arya Baburaj and Venkatesh Babu Radhakrishnan , booktitle=. 2021 , url=
2021
-
[22]
Gaurang Sriramanan and Sravanti Addepalli and Arya Baburaj and R. Venkatesh Babu , year=. 2011.14969 , archivePrefix=
-
[23]
Zeinab Golgooni and Mehrdad Saberi and Masih Eskandar and Mohammad Hossein Rohban , year=. 2103.15476 , archivePrefix=
-
[24]
Peilin Kang and Seyed-Mohsen Moosavi-Dezfooli , year=. 2105.02942 , archivePrefix=
-
[25]
2021 , eprint=
Adaptive perturbation adversarial training: based on reinforcement learning , author=. 2021 , eprint=
2021
-
[26]
Yihua Zhang and Guanhua Zhang and Prashant Khanduri and Mingyi Hong and Shiyu Chang and Sijia Liu , year=. 2112.12376 , archivePrefix=
- [27]
-
[28]
Zhichao Huang and Yanbo Fan and Chen Liu and Weizhong Zhang and Yong Zhang and Mathieu Salzmann and Sabine Süsstrunk and Jue Wang , year=. 2206.02417 , archivePrefix=
-
[29]
Xiaojun Jia and Yong Zhang and Xingxing Wei and Baoyuan Wu and Ke Ma and Jue Wang and Xiaochun Cao , year=. 2207.08859 , archivePrefix=
-
[30]
Boxi Wu and Jindong Gu and Zhifeng Li and Deng Cai and Xiaofei He and Wei Liu , year=. 2207.10498 , archivePrefix=
-
[31]
Xiaojun Jia and Yong Zhang and Xingxing Wei and Baoyuan Wu and Ke Ma and Jue Wang and Xiaochun Cao , year=. 2304.00202 , archivePrefix=
-
[32]
Runqi Lin and Chaojian Yu and Bo Han and Tongliang Liu , year=. 2310.08847 , archivePrefix=
-
[33]
Mahdi Salmani and Alireza Dehghanpour Farashah and Mohammad Azizmalayeri and Mahdi Amiri and Navid Eslami and Mohammad Taghi Manzuri and Mohammad Hossein Rohban , year=. 2310.18975 , archivePrefix=
-
[34]
Elias Abad Rocamora and Fanghui Liu and Grigorios G. Chrysos and Pablo M. Olmos and Volkan Cevher , year=. 2401.11618 , archivePrefix=
-
[35]
Runqi Lin and Chaojian Yu and Tongliang Liu , year=. 2404.08154 , archivePrefix=
-
[36]
Runqi Lin and Chaojian Yu and Bo Han and Hang Su and Tongliang Liu , year=. 2405.16262 , archivePrefix=
-
[37]
Zhaoxin Wang and Handing Wang and Cong Tian and Yaochu Jin , year=. 2407.12443 , archivePrefix=
-
[38]
Jie Gui and Chengze Jiang and Minjing Dong and Kun Tong and Xinli Shi and Yuan Yan Tang and Dacheng Tao , year=. 2408.03944 , archivePrefix=
-
[39]
PLOS ONE , publisher =. 2025 , month =. doi:10.1371/journal.pone.0317023 , author =
-
[40]
FastAT Benchmark: A Comprehensive Framework for Fair Evaluation of Fast Adversarial Training Methods
Chao Pan and Xin Yao , year=. 2604.22853 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Robustness of classifiers: from adversarial to random noise
Alhussein Fawzi and Seyed-Mohsen Moosavi-Dezfooli and Pascal Frossard , year=. 1608.08967 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Classification regions of deep neural networks
Alhussein Fawzi and Seyed-Mohsen Moosavi-Dezfooli and Pascal Frossard and Stefano Soatto , year=. 1705.09552 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Robustness via curvature regularization, and vice versa
Seyed-Mohsen Moosavi-Dezfooli and Alhussein Fawzi and Jonathan Uesato and Pascal Frossard , year=. 1811.09716 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Avery Ma and Fartash Faghri and Nicolas Papernot and Amir Massoud Farahmand , year=. 2004.01832 , archivePrefix=
-
[45]
Sahil Singla and Soheil Feizi , year=. 2006.00731 , archivePrefix=
-
[46]
Theodoros Tsiligkaridis and Jay Roberts , year=. 2009.04923 , archivePrefix=
-
[47]
Benyamin Ghojogh and Ali Ghodsi and Fakhri Karray and Mark Crowley , year=. 2110.01858 , archivePrefix=
-
[48]
Yaguan Qian and Yuqi Wang and Bin Wang and Zhaoquan Gu and Yuhan Guo and Wassim Swaileh , year=. 2207.01396 , archivePrefix=
-
[49]
Deep Residual Learning for Image Recognition
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , year=. 1512.03385 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Identity Mappings in Deep Residual Networks
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , year=. 1603.05027 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Sergey Zagoruyko and Nikos Komodakis , year=. 1605.07146 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Squeeze-and-Excitation Networks
Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu , year=. 1709.01507 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , year=. 2010.11929 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[54]
Alex Krizhevsky , year=
-
[55]
ImageNet Large Scale Visual Recognition Challenge
Olga Russakovsky and Jia Deng and Hao Su and Jonathan Krause and Sanjeev Satheesh and Sean Ma and Zhiheng Huang and Andrej Karpathy and Aditya Khosla and Michael Bernstein and Alexander C. Berg and Li Fei-Fei , year=. 1409.0575 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
2009 , volume=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. 2009 , volume=
2009
-
[57]
Ng , booktitle=
Yuval Netzer and Tao Wang and Adam Coates and Alessandro Bissacco and Bo Wu and Andrew Y. Ng , booktitle=. 2011 , url=
2011
-
[58]
2015 , url=
Le, Ya and Yang, Xuan , journal=. 2015 , url=
2015
-
[59]
2023 , publisher=
Yang, Jiancheng and Shi, Rui and Wei, Donglai and Liu, Zequan and Zhao, Lin and Ke, Bilian and Pfister, Hanspeter and Ni, Bingbing , journal=. 2023 , publisher=
2023
-
[60]
2026 , url =
The Emerging Science of Machine Learning Benchmarks , author =. 2026 , url =
2026
-
[61]
2026 , publisher=
High-Dimensional Probability: An Introduction with Applications in Data Science , author=. 2026 , publisher=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.