Measuring and mitigating overreliance to build human-compatible AI
Pith reviewed 2026-05-21 22:33 UTC · model grok-4.3
The pith
Measuring and mitigating overreliance must become central to LLM research and deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Large language models distinguish themselves from previous technologies by functioning as collaborative thought partners capable of engaging more fluidly in natural language on a range of tasks. As LLMs increasingly influence consequential decisions across diverse domains from healthcare to personal advice, the risk of overreliance grows. This paper argues that measuring and mitigating overreliance must become central to LLM research and deployment because LLM characteristics, system design features, and user cognitive biases together raise serious and unique concerns about overreliance in practice.
What carries the argument
Overreliance, defined as relying on LLMs beyond their capabilities, carried by the combined effects of LLM characteristics as fluid natural-language thought partners, system design features, and user cognitive biases.
Load-bearing premise
The premise that LLM characteristics, system design features, and user cognitive biases together raise serious and unique concerns about overreliance that prior technologies did not.
What would settle it
A controlled study finding comparable rates of overreliance and comparable downstream harms when users interact with LLMs versus earlier technologies such as web search tools or rule-based decision aids on matched tasks would undermine the claim of unique concerns.
Figures
read the original abstract
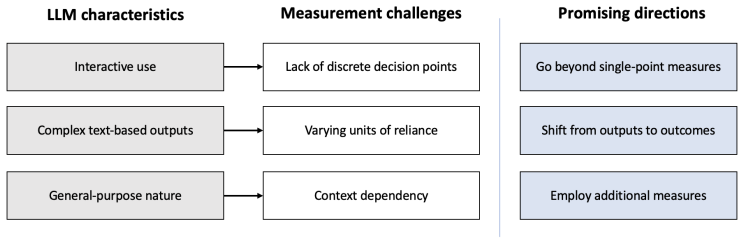
Large language models (LLMs) distinguish themselves from previous technologies by functioning as collaborative ``thought partners,'' capable of engaging more fluidly in natural language on a range of tasks. As LLMs increasingly influence consequential decisions across diverse domains from healthcare to personal advice, the risk of overreliance -- relying on LLMs beyond their capabilities -- grows. This paper argues that measuring and mitigating overreliance must become central to LLM research and deployment. First, we consolidate risks from overreliance at both the individual and societal levels, including high-stakes errors, governance challenges, and cognitive deskilling. Then, we explore LLM characteristics, system design features, and user cognitive biases that together raise serious and unique concerns about overreliance on LLMs in practice. We also examine historical approaches for measuring overreliance, identifying three important gaps and proposing three promising directions to improve measurement. Finally, we propose mitigation strategies that can be pursued to ensure LLMs augment rather than undermine human capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that overreliance on LLMs—relying on them beyond their capabilities—poses serious individual and societal risks (high-stakes errors, governance challenges, cognitive deskilling) that are qualitatively distinct from prior technologies due to LLMs' fluid natural-language collaboration. It consolidates these risks, attributes them to LLM characteristics, system design features, and user cognitive biases, reviews historical measurement approaches to identify three gaps, proposes three new measurement directions, and outlines mitigation strategies to ensure LLMs augment rather than replace human capabilities.
Significance. If the uniqueness premise holds and the proposed measurement directions can be operationalized, this position paper could usefully shift priorities in human-AI interaction and AI alignment research toward systematic evaluation of reliance behaviors. The consolidation of risks across domains and explicit identification of measurement gaps provide a clear agenda for subsequent empirical studies.
major comments (2)
- [Section 3] Section 3: The assertion that LLM traits, design features, and cognitive biases 'raise serious and unique concerns about overreliance' (abstract paragraph 2) rests on illustrative examples rather than comparative incidence rates, error-severity metrics, or longitudinal deskilling data against baselines such as rule-based expert systems, web search, or GPS navigation. This gap directly undermines the load-bearing premise that these issues warrant elevating measurement and mitigation to a central research priority.
- [Section 2] Section 2: The consolidation of individual and societal risks is logically structured but lacks quantitative contrasts (e.g., error rates or deskilling trajectories) with historical technologies, leaving the claim that LLM overreliance introduces qualitatively new governance and capability-undermining challenges without sufficient empirical anchoring for the central argument.
minor comments (1)
- [Abstract] The abstract would benefit from briefly enumerating the three proposed measurement directions and the main mitigation strategies to improve reader orientation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We appreciate the recognition that the paper could usefully shift priorities in human-AI interaction research if the uniqueness premise holds and the proposed directions are operationalized. As a position paper, our goal is to consolidate risks, identify measurement gaps, and outline an agenda rather than deliver new comparative empirical data. We address the major comments point by point below and have revised the manuscript to clarify the scope and nature of our arguments.
read point-by-point responses
-
Referee: [Section 3] Section 3: The assertion that LLM traits, design features, and cognitive biases 'raise serious and unique concerns about overreliance' (abstract paragraph 2) rests on illustrative examples rather than comparative incidence rates, error-severity metrics, or longitudinal deskilling data against baselines such as rule-based expert systems, web search, or GPS navigation. This gap directly undermines the load-bearing premise that these issues warrant elevating measurement and mitigation to a central research priority.
Authors: We agree that the paper relies on illustrative examples and qualitative distinctions rather than new comparative quantitative data. The central claim for uniqueness rests on LLMs' capacity for fluid, open-ended natural-language collaboration, which enables forms of interaction and potential cognitive integration not present in rule-based systems, search engines, or navigation tools. This distinction is drawn from existing human-AI interaction literature rather than asserted as proven by new metrics. We acknowledge the absence of direct incidence-rate or longitudinal comparisons as a limitation of the current evidence base. In the revised manuscript we have added explicit language in Section 3 stating that the uniqueness argument is a hypothesis to be tested through the measurement directions we propose, rather than a claim supported by new comparative data. This is a partial revision that clarifies scope without changing the position paper's core contribution. revision: partial
-
Referee: [Section 2] Section 2: The consolidation of individual and societal risks is logically structured but lacks quantitative contrasts (e.g., error rates or deskilling trajectories) with historical technologies, leaving the claim that LLM overreliance introduces qualitatively new governance and capability-undermining challenges without sufficient empirical anchoring for the central argument.
Authors: We accept that the risk consolidation would be strengthened by quantitative contrasts with prior technologies. The paper synthesizes risks reported across domains and attributes them to LLM-specific characteristics, but does not conduct or cite new comparative error-rate or deskilling analyses. Such direct contrasts remain limited in the literature precisely because LLMs are recent; this scarcity is one of the measurement gaps the paper identifies. We have revised Section 2 to include a short discussion noting the difficulty of apples-to-apples comparisons and explaining how the three proposed measurement directions are intended to generate the empirical anchors needed for future governance and deskilling studies. This partial revision improves anchoring while preserving the paper's focus on agenda-setting. revision: partial
Circularity Check
No significant circularity; position paper relies on external citations and observations
full rationale
The paper is a position and review piece that consolidates individual/societal risks, attributes concerns to LLM traits and design features via illustrative examples, reviews historical measurement approaches from prior literature, identifies gaps, and proposes mitigation strategies. No equations, fitted parameters, self-definitional constructs, or predictions appear in the provided abstract or described structure. The central argument draws on cited historical methods and domain observations rather than reducing to self-referential inputs or self-citation chains by construction. This is a standard self-contained review format with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs function as collaborative thought partners capable of engaging fluidly in natural language on a range of tasks
- domain assumption Overreliance on LLMs creates distinct individual and societal risks not fully addressed by prior technologies
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LLMs distinguish themselves from previous technologies by functioning as collaborative 'thought partners,' capable of engaging more fluidly in natural language.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
The efficiency-gain illusion: People underestimate the rate of AI use and overestimate its benefits on simple tasks
Three pre-registered studies with 2691 participants show people underestimate their AI usage rate and overestimate efficiency gains on simple tasks, with prior use entrenching further adoption.
-
Resume-ing Control: (Mis)Perceptions of Agency Around GenAI Use in Recruiting Workflows
Recruiters perceive themselves as retaining agency over GenAI in hiring pipelines, yet GenAI invisibly architects core evaluation inputs, producing only marginal efficiency gains at the cost of deskilling.
Reference graph
Works this paper leans on
-
[1]
Mirages: On anthropomorphism in dialogue systems.arXiv preprint arXiv:2305.09800, 2023
Gavin Abercrombie, Amanda Cercas Curry, Tanvi Dinkar, Verena Rieser, and Zeerak Talat. Mirages: On anthropomorphism in dialogue systems.arXiv preprint arXiv:2305.09800, 2023
-
[2]
AIID. Incident 838: Microsoft Copilot Allegedly Provides Unsafe Medical Advice with High Risk of Severe Harm — incidentdatabase.ai. https://incidentdatabase.ai/cite/838/,
-
[3]
[Accessed 09-05-2025]
work page 2025
-
[4]
J.E. Allen, C.I. Guinn, and E. Horvtz. Mixed-initiative interaction.IEEE Intelligent Systems and their Applications, 14(5):14–23, 1999
work page 1999
-
[5]
Guidelines for human-AI interaction
Saleema Amershi, Dan Weld, Mihaela V orvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N Bennett, Kori Inkpen, et al. Guidelines for human-AI interaction. InProceedings of the 2019 chi conference on human factors in computing systems, pages 1–13, 2019
work page 2019
-
[6]
Joshua Ashkinaze, Julia Mendelsohn, Qiwei Li, Ceren Budak, and Eric Gilbert. How AI ideas affect the creativity, diversity, and evolution of human ideas: Evidence from a large, dynamic experiment.arXiv preprint arXiv:2401.13481, 2024
-
[7]
Alessio Azzutti. Artificial intelligence and machine learning in finance: Key concepts, ap- plications, and regulatory considerations. InThe Emerald Handbook of Fintech: Reshaping Finance, pages 315–339. Emerald Publishing Limited, 2024
work page 2024
-
[8]
Agathe Balayn, Mireia Yurrita, Fanny Rancourt, Fabio Casati, and Ujwal Gadiraju. An empirical exploration of trust dynamics in llm supply chains.arXiv preprint arXiv:2405.16310, 2024
-
[9]
Sachin Banker and Salil Khetani. Algorithm overdependence: How the use of algorithmic recommendation systems can increase risks to consumer well-being.Journal of Public Policy & Marketing, 38(4):500–515, 2019
work page 2019
-
[10]
Feedbacklogs: Recording and incorporating stakeholder feedback into machine learning pipelines
Matthew Barker, Emma Kallina, Dhananjay Ashok, Katherine Collins, Ashley Casovan, Adrian Weller, Ameet Talwalkar, Valerie Chen, and Umang Bhatt. Feedbacklogs: Recording and incorporating stakeholder feedback into machine learning pipelines. InProceedings of the 3rd ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization, pages 1–15, 2023
work page 2023
-
[11]
Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021
work page 2021
-
[12]
Learning personalized decision support policies
Umang Bhatt, Valerie Chen, Katherine M Collins, Parameswaran Kamalaruban, Emma Kallina, Adrian Weller, and Ameet Talwalkar. Learning personalized decision support policies. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14203–14211, 2025
work page 2025
-
[13]
When should algorithms resign? a proposal for AI gover- nance.Computer, 57(10):99–103, 2024
Umang Bhatt and Holli Sargeant. When should algorithms resign? a proposal for AI gover- nance.Computer, 57(10):99–103, 2024. 10
work page 2024
-
[14]
Jessica Y Bo, Sophia Wan, and Ashton Anderson. To rely or not to rely? evaluating interven- tions for appropriate reliance on large language models.arXiv preprint arXiv:2412.15584, 2024
-
[15]
Silvia Bonaccio and Reeshad S. Dalal. Advice taking and decision-making: An integrative literature review, and implications for the organizational sciences.Organizational Behavior and Human Decision Processes, 101(2):127–151, 2006
work page 2006
-
[16]
We need an interventionist mindset, Mar 2025
danah boyd. We need an interventionist mindset, Mar 2025
work page 2025
-
[17]
Machine culture.Nature Human Behaviour, 7(11):1855–1868, 2023
Levin Brinkmann, Fabian Baumann, Jean-François Bonnefon, Maxime Derex, Thomas F Müller, Anne-Marie Nussberger, Agnieszka Czaplicka, Alberto Acerbi, Thomas L Griffiths, Joseph Henrich, et al. Machine culture.Nature Human Behaviour, 7(11):1855–1868, 2023
work page 2023
-
[18]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z Gajos. To trust or to think: Cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making.Proceedings of the ACM on Human-computer Interaction, 5(CSCW1):1–21, 2021
work page 2021
-
[19]
The need for cognition.Journal of personality and social psychology, 42(1):116, 1982
John T Cacioppo and Richard E Petty. The need for cognition.Journal of personality and social psychology, 42(1):116, 1982
work page 1982
-
[20]
Shiye Cao and Chien-Ming Huang. Understanding user reliance on AI in assisted decision- making.Proceedings of the ACM on Human-Computer Interaction, 6(CSCW2):1–23, 2022
work page 2022
-
[21]
Pitfalls of evidence-based AI policy.arXiv preprint arXiv:2502.09618, 2025
Stephen Casper, David Krueger, and Dylan Hadfield-Menell. Pitfalls of evidence-based AI policy.arXiv preprint arXiv:2502.09618, 2025
-
[22]
P. Kevin Castel. Mata v. avianca, inc. United States District Court, Southern District of New York, June 2023. No. 1:2022cv01461, Document 54 (S.D.N.Y . 2023)
work page 2023
-
[23]
Harms from increasingly agentic algorithmic systems
Alan Chan, Rebecca Salganik, Alva Markelius, Chris Pang, Nitarshan Rajkumar, Dmitrii Krasheninnikov, Lauro Langosco, Zhonghao He, Yawen Duan, Micah Carroll, et al. Harms from increasingly agentic algorithmic systems. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pages 651–666, 2023
work page 2023
-
[24]
Nick Chater, Jian-Qiao Zhu, Jake Spicer, Joakim Sundh, Pablo León-Villagrá, and Adam Sanborn. Probabilistic biases meet the bayesian brain.Current Directions in Psychological Science, 29(5):506–512, 2020
work page 2020
-
[25]
Kyle Chayka.Filterworld: How algorithms flattened culture. Random House, 2025
work page 2025
-
[26]
Allison Chen, Sunnie S. Y . Kim, Amaya Dharmasiri, Olga Russakovsky, and Judith E. Fan. Portraying large language models as machines, tools, or companions affects what mental capacities humans attribute to them. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, CHI EA ’25, New York, NY , USA,
-
[27]
Association for Computing Machinery
-
[28]
Understanding the role of human intuition on reliance in human-AI decision-making with explanations
Valerie Chen, Q Vera Liao, Jennifer Wortman Vaughan, and Gagan Bansal. Understanding the role of human intuition on reliance in human-AI decision-making with explanations. Proceedings of the ACM on Human-computer Interaction, 7(CSCW2):1–32, 2023
work page 2023
-
[29]
ELEPHANT: Measuring and understanding social sycophancy in LLMs
Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky. Social sycophancy: A broader understanding of llm sycophancy.arXiv preprint arXiv:2505.13995, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Rendi Chevi, Kentaro Inui, Thamar Solorio, and Alham Fikri Aji. How individual traits and language styles shape preferences in open-ended user-llm interaction: A preliminary study. arXiv preprint arXiv:2504.17083, 2025
-
[31]
Avishek Choudhury and Zaira Chaudhry. Large language models and user trust: consequence of self-referential learning loop and the deskilling of health care professionals.Journal of Medical Internet Research, 26:e56764, 2024
work page 2024
-
[32]
arXiv preprint arXiv:2501.10476 (2025)
Katherine M Collins, Umang Bhatt, and Ilia Sucholutsky. Revisiting rogers’ paradox in the context of human-AI interaction.arXiv preprint arXiv:2501.10476, 2025. 11
-
[33]
arXiv preprint arXiv:2407.12804 (2024)
Katherine M Collins, Valerie Chen, Ilia Sucholutsky, Hannah Rose Kirk, Malak Sadek, Holli Sargeant, Ameet Talwalkar, Adrian Weller, and Umang Bhatt. Modulating language model experiences through frictions.arXiv preprint arXiv:2407.12804, 2024
-
[34]
Building machines that learn and think with people.Nature human behaviour, 8(10):1851–1863, 2024
Katherine M Collins, Ilia Sucholutsky, Umang Bhatt, Kartik Chandra, Lionel Wong, Mina Lee, Cedegao E Zhang, Tan Zhi-Xuan, Mark Ho, Vikash Mansinghka, et al. Building machines that learn and think with people.Nature human behaviour, 8(10):1851–1863, 2024
work page 2024
-
[35]
Gabor Csapo, Jihyun Kim, Miha Klasinc, and Alia ElKattan. Survival of the best fit.USA. https://www. survivalofthebestfit. com, 2019
work page 2019
-
[36]
Can Democracy Survive the Disruptive Power of AI? — carnegieendowment.org
Raluca Csernatoni. Can Democracy Survive the Disruptive Power of AI? — carnegieendowment.org. https://carnegieendowment.org/research/2024/12/ can-democracy-survive-the-disruptive-power-of-ai?lang=en , 2024. [Accessed 09-05-2025]
work page 2024
-
[37]
AI and procurement.Manufacturing & Service Operations Management, 24(2):691–706, 2022
Ruomeng Cui, Meng Li, and Shichen Zhang. AI and procurement.Manufacturing & Service Operations Management, 24(2):691–706, 2022
work page 2022
-
[38]
Automation and accountability in decision support system interface design
Mary L Cummings. Automation and accountability in decision support system interface design. 2006
work page 2006
-
[39]
Mixed-initiative creative interfaces
Sebastian Deterding, Jonathan Hook, Rebecca Fiebrink, Marco Gillies, Jeremy Gow, Memo Akten, Gillian Smith, Antonios Liapis, and Kate Compton. Mixed-initiative creative interfaces. InProceedings of the 2017 CHI conference extended abstracts on human factors in computing systems, pages 628–635, 2017
work page 2017
-
[40]
Multicalibration for confidence scoring in llms.arXiv preprint arXiv:2404.04689, 2024
Gianluca Detommaso, Martin Bertran, Riccardo Fogliato, and Aaron Roth. Multicalibration for confidence scoring in llms.arXiv preprint arXiv:2404.04689, 2024
-
[41]
Berkeley J Dietvorst, Joseph P Simmons, and Cade Massey. Algorithm aversion: people erroneously avoid algorithms after seeing them err.Journal of experimental psychology: General, 144(1):114, 2015
work page 2015
-
[42]
Berkeley J Dietvorst, Joseph P Simmons, and Cade Massey. Overcoming algorithm aversion: People will use imperfect algorithms if they can (even slightly) modify them.Management Science, 64(3):1155–1170, 2018
work page 2018
-
[43]
Mary T Dzindolet, Scott A Peterson, Regina A Pomranky, Linda G Pierce, and Hall P Beck. The role of trust in automation reliance.International journal of human-computer studies, 58(6):697–718, 2003
work page 2003
-
[44]
Relational norms for human-AI cooperation.arXiv preprint arXiv:2502.12102, 2025
Brian D Earp, Sebastian Porsdam Mann, Mateo Aboy, Edmond Awad, Monika Betzler, Marietjie Botes, Rachel Calcott, Mina Caraccio, Nick Chater, Mark Coeckelbergh, et al. Relational norms for human-AI cooperation.arXiv preprint arXiv:2502.12102, 2025
-
[45]
Cathy Mengying Fang, Auren R Liu, Valdemar Danry, Eunhae Lee, Samantha WT Chan, Pat Pataranutaporn, Pattie Maes, Jason Phang, Michael Lampe, Lama Ahmad, et al. How AI and human behaviors shape psychosocial effects of chatbot use: A longitudinal randomized controlled study.arXiv preprint arXiv:2503.17473, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
K.J. Kevin Feng, Kevin Pu, Matt Latzke, Tal August, Pao Siangliulue, Jonathan Bragg, Daniel S Weld, Amy X Zhang, and Joseph Chee Chang. Cocoa: Co-planning and co-execution with AI agents.arXiv preprint arXiv:2412.10999, 2024
-
[47]
Michael Gerlich. The human factor of AI: Implications for critical thinking and societal anxieties.TECHNOLOGY AND SOCIETY: Boon or Bane?, page 8, 2025
work page 2025
-
[48]
Ella Glikson and Anita Williams Woolley. Human trust in artificial intelligence: Review of empirical research.Academy of management annals, 14(2):627–660, 2020
work page 2020
-
[49]
H. Paul Grice. Logic and conversation. In Donald Davidson, editor,The logic of grammar, pages 64–75. Dickenson Pub. Co., 1975. 12
work page 1975
- [50]
-
[51]
Thomas L Griffiths, Nick Chater, and Joshua B Tenenbaum.Bayesian models of cognition: reverse engineering the mind. MIT Press, 2024
work page 2024
-
[52]
A decision theoretic frame- work for measuring AI reliance
Ziyang Guo, Yifan Wu, Jason D Hartline, and Jessica Hullman. A decision theoretic frame- work for measuring AI reliance. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 221–236, 2024
work page 2024
-
[53]
Nigel Harvey and Ilan Fischer. Taking advice: Accepting help, improving judgment, and sharing responsibility.Organizational Behavior and Human Decision Processes, 70(2):117– 133, 1997
work page 1997
-
[54]
Gaole He, Gianluca Demartini, and Ujwal Gadiraju. Plan-then-execute: An empirical study of user trust and team performance when using llm agents as a daily assistant. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25, New York, NY , USA, 2025. Association for Computing Machinery
work page 2025
-
[55]
Knowing about knowing: An illusion of human competence can hinder appropriate reliance on AI systems
Gaole He, Lucie Kuiper, and Ujwal Gadiraju. Knowing about knowing: An illusion of human competence can hinder appropriate reliance on AI systems. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, CHI ’23, New York, NY , USA, 2023. Association for Computing Machinery
work page 2023
-
[56]
Kevin Anthony Hoff and Masooda Bashir. Trust in automation: Integrating empirical evidence on factors that influence trust.Human factors, 57(3):407–434, 2015
work page 2015
-
[57]
Principles of mixed-initiative user interfaces
Eric Horvitz. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’99, page 159–166, New York, NY , USA, 1999. Association for Computing Machinery
work page 1999
-
[58]
Yoyo Tsung-Yu Hou and Malte F Jung. Who is the expert? reconciling algorithm aversion and algorithm appreciation in AI-supported decision making.Proceedings of the ACM on Human-Computer Interaction, 5(CSCW2):1–25, 2021
work page 2021
-
[59]
Yue Huang, Chujie Gao, Yujun Zhou, Kehan Guo, Xiangqi Wang, Or Cohen-Sasson, Max Lamparth, and Xiangliang Zhang. Position: We need an adaptive interpretation of helpful, honest, and harmless principles.arXiv preprint arXiv:2502.06059, 2025
-
[60]
Decision theoretic foundations for experiments evaluating human decisions
Jessica Hullman, Alex Kale, and Jason Hartline. Decision theoretic foundations for experiments evaluating human decisions. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–15, 2025
work page 2025
-
[61]
Monitoring human dependence on AI systems with reliance drills.arXiv preprint arXiv:2409.14055, 2024
Rosco Hunter, Richard Moulange, Jamie Bernardi, and Merlin Stein. Monitoring human dependence on AI systems with reliance drills.arXiv preprint arXiv:2409.14055, 2024
-
[62]
Lujain Ibrahim, Canfer Akbulut, Rasmi Elasmar, Charvi Rastogi, Minsuk Kahng, Mered- ith Ringel Morris, Kevin R McKee, Verena Rieser, Murray Shanahan, and Laura Weidinger. Multi-turn evaluation of anthropomorphic behaviours in large language models.arXiv preprint arXiv:2502.07077, 2025
-
[63]
Lujain Ibrahim, Franziska Sofia Hafner, and Luc Rocher. Training language models to be warm and empathetic makes them less reliable and more sycophantic.arXiv preprint arXiv:2507.21919, 2025
-
[64]
Lujain Ibrahim, Saffron Huang, Umang Bhatt, Lama Ahmad, and Markus Anderljung. To- wards interactive evaluations for interaction harms in human-ai systems.arXiv preprint arXiv:2405.10632, 2024
-
[65]
Kahr, Gerrit Rooks, Chris Snijders, and Martijn C
Patricia K. Kahr, Gerrit Rooks, Chris Snijders, and Martijn C. Willemsen. The trust recovery journey. the effect of timing of errors on the willingness to follow AI advice. InProceedings of the 29th International Conference on Intelligent User Interfaces, IUI ’24, page 609–622, New York, NY , USA, 2024. Association for Computing Machinery. 13
work page 2024
-
[66]
Capturing humans’ mental models of AI: An item response theory approach
Markelle Kelly, Aakriti Kumar, Padhraic Smyth, and Mark Steyvers. Capturing humans’ mental models of AI: An item response theory approach. InProceedings of the 2023 ACM conference on fairness, accountability, and transparency, pages 1723–1734, 2023
work page 2023
-
[67]
Sunnie S. Y . Kim, Q Vera Liao, Mihaela V orvoreanu, Stephanie Ballard, and Jennifer Wortman Vaughan. "I’m Not Sure, But...": Examining the Impact of Large Language Models’ Uncer- tainty Expression on User Reliance and Trust. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 822–835, 2024
work page 2024
-
[68]
Sunnie S. Y . Kim, Jennifer Wortman Vaughan, Q. Vera Liao, Tania Lombrozo, and Olga Russakovsky. Fostering Appropriate Reliance on Large Language Models: The Role of Explanations, Sources, and Inconsistencies. InACM Conference on Human Factors in Computing Systems (CHI), 2025
work page 2025
-
[69]
Sunnie S. Y . Kim, Elizabeth Anne Watkins, Olga Russakovsky, Ruth Fong, and Andrés Monroy-Hernández. Humans, AI, and Context: Understanding End-Users’ Trust in a Real- World Computer Vision Application. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’23, page 77–88, New York, NY , USA, 2023. Association for C...
work page 2023
-
[70]
Jon Kleinberg and Manish Raghavan. Algorithmic monoculture and social welfare.Proceed- ings of the National Academy of Sciences, 118(22):e2018340118, 2021
work page 2021
-
[71]
Olya Kudina and Bas de Boer. Large language models, politics, and the functionalization of language.AI and Ethics, pages 1–13, 2024
work page 2024
-
[72]
Vivian Lai, Chacha Chen, Alison Smith-Renner, Q Vera Liao, and Chenhao Tan. Towards a science of human-AI decision making: An overview of design space in empirical human- subject studies. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pages 1369–1385, 2023
work page 2023
-
[73]
Vivian Lai, Yiming Zhang, Chacha Chen, Q Vera Liao, and Chenhao Tan. Selective ex- planations: Leveraging human input to align explainable AI.Proceedings of the ACM on Human-Computer Interaction, 7(CSCW2):1–35, 2023
work page 2023
-
[74]
Hao-Ping (Hank) Lee, Advait Sarkar, Lev Tankelevitch, Ian Drosos, Sean Rintel, Richard Banks, and Nicholas Wilson. The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25...
work page 2025
-
[75]
John D Lee and Neville Moray. Trust, control strategies and allocation of function in human- machine systems.Ergonomics, 35(10):1243–1270, 1992
work page 1992
-
[76]
Trust, self-confidence, and operators’ adaptation to automation
John D Lee and Neville Moray. Trust, self-confidence, and operators’ adaptation to automation. International journal of human-computer studies, 40(1):153–184, 1994
work page 1994
-
[77]
Trust in automation: Designing for appropriate reliance
John D Lee and Katrina A See. Trust in automation: Designing for appropriate reliance. Human factors, 46(1):50–80, 2004
work page 2004
- [78]
-
[79]
Ryan Liu, Jiayi Geng, Joshua C Peterson, Ilia Sucholutsky, and Thomas L Griffiths. Large language models assume people are more rational than we really are.arXiv preprint arXiv:2406.17055, 2024
-
[80]
Jennifer M. Logg, Julia A. Minson, and Don A. Moore. Algorithm appreciation: People prefer algorithmic to human judgment.Organizational Behavior and Human Decision Processes, 151:90–103, 2019. 14
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.