Can Reasoning Models Detect Changes to their Chains of Thought?
Pith reviewed 2026-06-26 11:39 UTC · model grok-4.3
The pith
Reasoning models detect edits to their chains of thought only modestly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
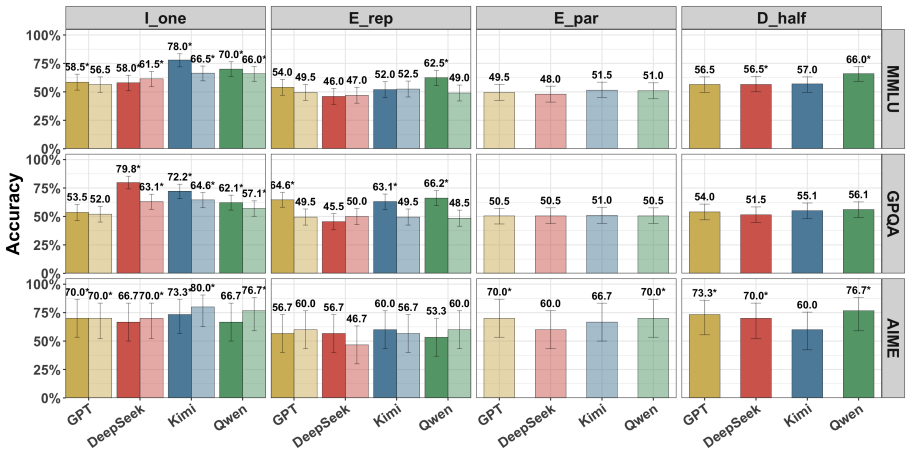
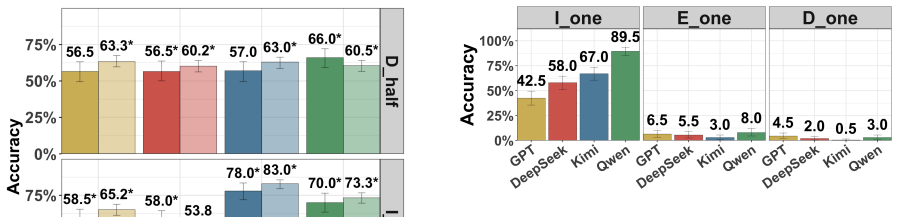
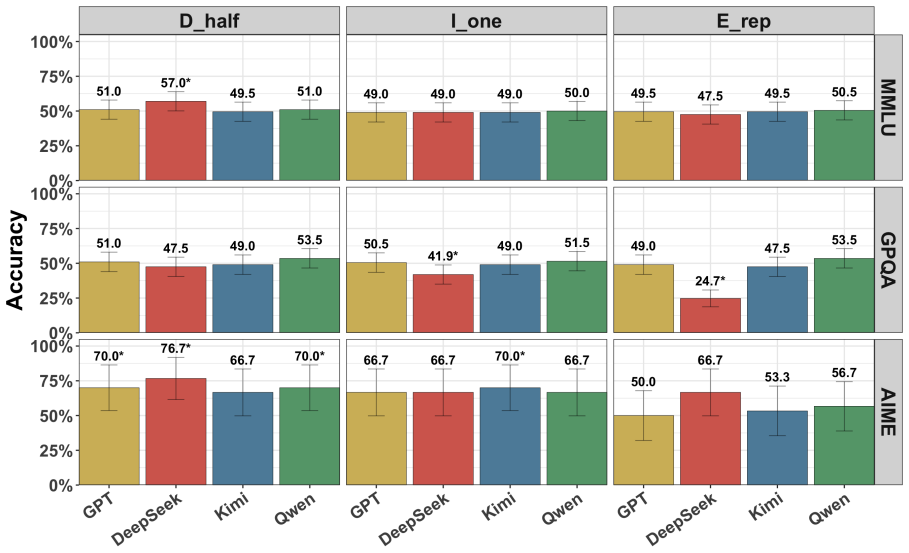
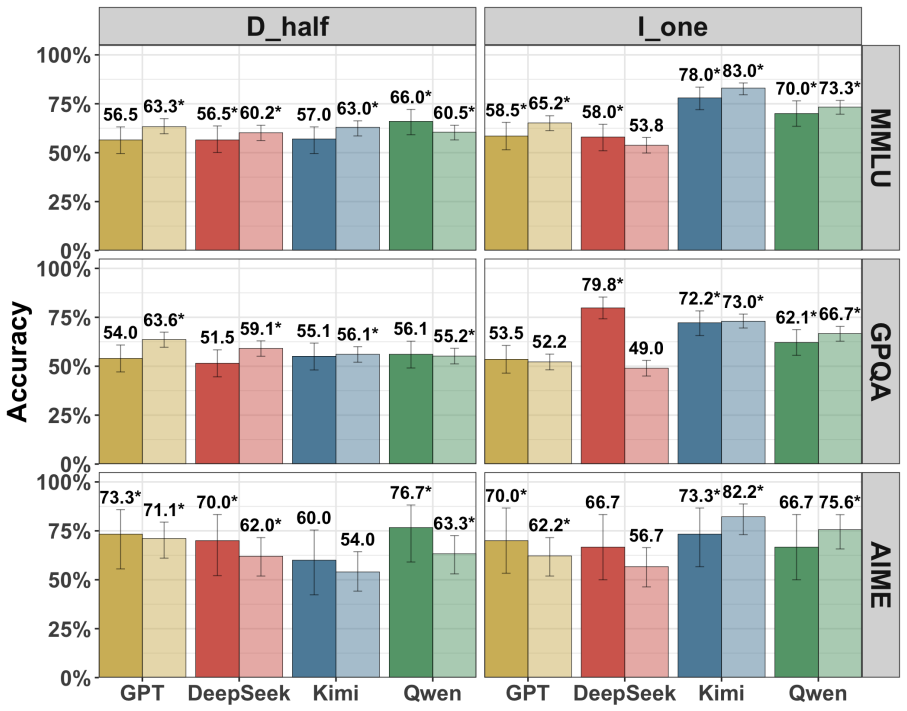
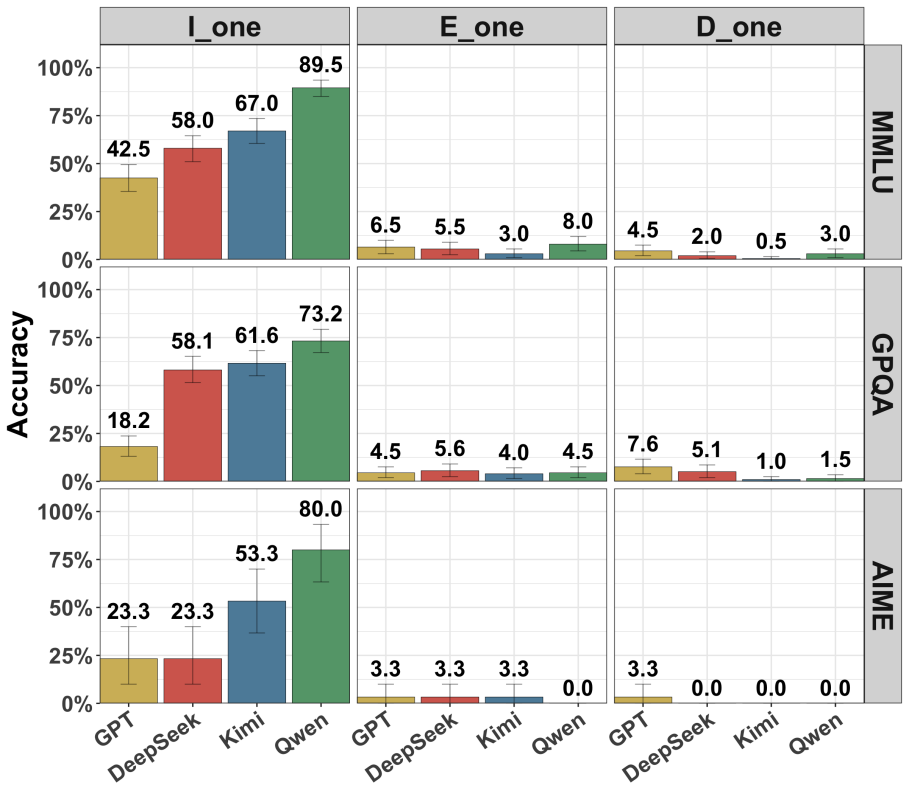
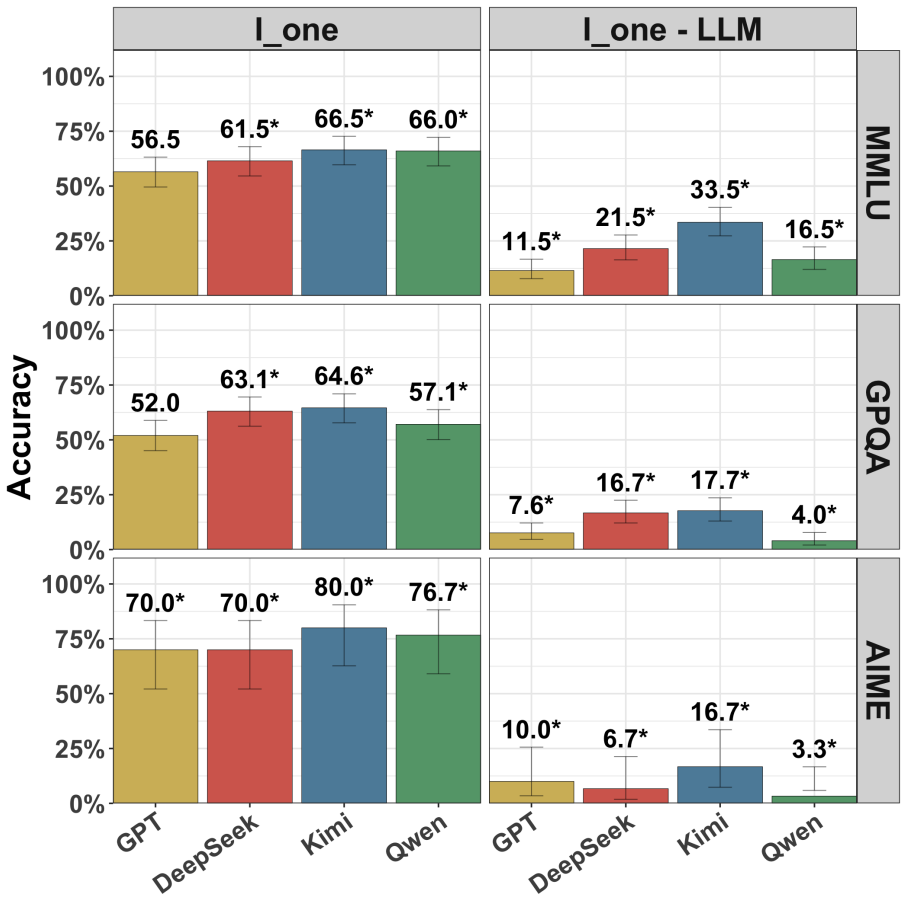
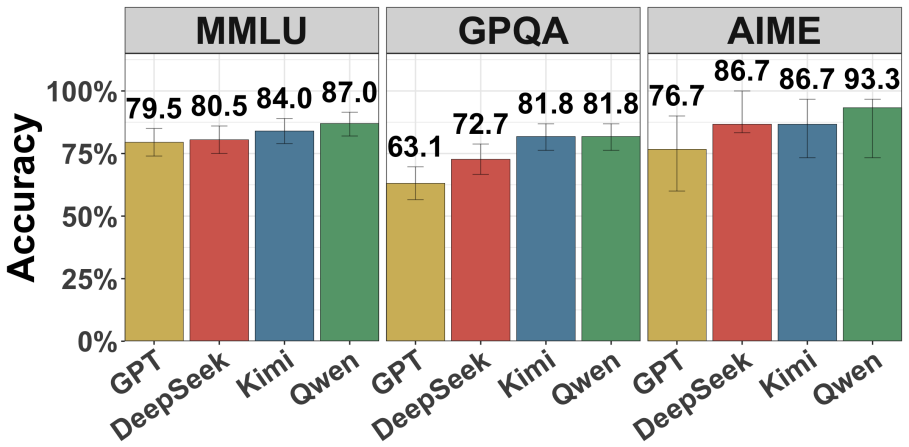
Recent reasoning models show only modest accuracy at detecting interventions on their chains of thought, whether those interventions occur during or after reasoning and whether the chains come from the model itself or from other models. Models also have difficulty specifying exactly how the chain was modified.
What carries the argument
The CoT detection task, in which models receive a reasoning trace that may have been prefilling or altered and are prompted to report whether and how it differs from what they would have generated.
If this is right
- CoT prefilling with stronger models' reasoning can likely proceed without the target model noticing the substitution.
- Interventions to remove unsafe reasoning steps may succeed because the model does not flag the alteration.
- Detection performance does not improve when the CoT belongs to the model being tested versus another model.
- Modest detection holds both while the model is still reasoning and after the chain is complete.
Where Pith is reading between the lines
- Developers could use CoT editing as a reliable way to steer model behavior without triggering internal consistency checks.
- Future experiments might vary the subtlety of the edits to find the threshold at which detection becomes reliable.
- Similar tests on non-reasoning models could reveal whether chain-of-thought use itself affects self-monitoring ability.
Load-bearing premise
The prompts and edit methods used in the experiments measure genuine detection ability rather than being influenced by how the questions are worded or how the changes are introduced.
What would settle it
A follow-up experiment that achieves high accuracy in identifying both the presence and the specific nature of CoT modifications across multiple models and edit types would falsify the claim of only modest detection.
Figures

read the original abstract
There are many reasons one may want to edit a model's chain of thought (CoT) -- e.g., to prefill it with reasoning from a stronger model or to remove steps that may yield unsafe outputs. The success of these interventions plausibly depends on a model's inability to notice them, as the model may alter its behavior if it suspects tampering. In this work, we study whether recent reasoning models are able to detect such interventions on their CoTs under a variety of conditions: both during reasoning and after it, and when prefilled both with their own CoTs and with those of other models. Broadly, we find that (i) models exhibit only very modest detection accuracy; (ii) models struggle to identify *how* their CoT was modified; and (iii) models are about as good at detecting changes to their own CoTs as to those of other models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether recent reasoning models can detect edits to their chains of thought (CoTs), both during and after generation and when the CoT is their own or from another model. It reports three main empirical findings: models achieve only modest accuracy in detecting such interventions, struggle to identify the specific type of modification, and show comparable detection performance on their own CoTs versus those of other models.
Significance. If the empirical results are robust, the work provides evidence that CoT interventions (e.g., for safety or capability enhancement) are unlikely to be noticed by the model itself, which bears on the feasibility of such techniques without triggering behavioral changes. The study contributes behavioral data on model introspection and self-monitoring in the context of reasoning traces.
major comments (2)
- [Methods] Methods (experimental design): The study does not report control conditions using unmodified CoTs to measure the base rate at which models report 'changes' in the absence of any intervention. Without these controls, the modest detection accuracy cannot be distinguished from generic prompt-induced affirmative responses, undermining interpretation of findings (i) and (iii).
- [Results] Results (detection accuracy): The abstract and reported findings provide no sample sizes, statistical tests, confidence intervals, or error bars, making it impossible to assess whether the 'modest accuracy' and 'no difference between own/other' claims are statistically supported or merely descriptive.
minor comments (1)
- [Abstract] The abstract refers to 'a variety of conditions' but does not enumerate them; a brief enumeration in the abstract or introduction would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of experimental design and reporting. We address each major point below and commit to revisions that strengthen the empirical claims.
read point-by-point responses
-
Referee: [Methods] The study does not report control conditions using unmodified CoTs to measure the base rate at which models report 'changes' in the absence of any intervention. Without these controls, the modest detection accuracy cannot be distinguished from generic prompt-induced affirmative responses, undermining interpretation of findings (i) and (iii).
Authors: We agree this is a valid concern. The current experiments focus on modified CoTs but do not explicitly include unmodified controls to quantify false-positive rates. In the revised manuscript we will add these control conditions (prompting models to detect changes on their original, unmodified CoTs) and report the resulting base rates alongside the main results. This will allow clearer interpretation of the reported detection accuracies. revision: yes
-
Referee: [Results] Results (detection accuracy): The abstract and reported findings provide no sample sizes, statistical tests, confidence intervals, or error bars, making it impossible to assess whether the 'modest accuracy' and 'no difference between own/other' claims are statistically supported or merely descriptive.
Authors: We acknowledge the omission. The full manuscript contains the underlying trial counts but does not present sample sizes, statistical tests, confidence intervals, or error bars in the abstract or main result summaries. We will revise to include these details (e.g., N per condition, appropriate tests for accuracy differences, and error bars on figures) so that the strength of the 'modest accuracy' and 'own vs. other' comparisons can be evaluated rigorously. revision: yes
Circularity Check
No circularity: purely empirical behavioral study with no derivations or self-referential structure
full rationale
The paper is an empirical investigation of model behavior under CoT interventions. It reports experimental results on detection accuracy, identification of modification type, and own-vs-other CoT performance. No equations, fitted parameters, uniqueness theorems, ansatzes, or derivation chains appear in the provided text. All claims rest on direct measurement of prompted responses rather than any reduction of outputs to inputs by construction. This is a standard non-circular empirical design.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 21st Workshop on Biomedical Language Processing. 2022
2022
-
[2]
Explainable Assessment of Healthcare Articles with QA
Boissonnet, Alodie and Saeidi, Marzieh and Plachouras, Vassilis and Vlachos, Andreas. Explainable Assessment of Healthcare Articles with QA. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.1
-
[3]
A sequence-to-sequence approach for document-level relation extraction
Giorgi, John and Bader, Gary and Wang, Bo. A sequence-to-sequence approach for document-level relation extraction. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.2
-
[4]
Position-based Prompting for Health Outcome Generation
Abaho, Micheal and Bollegala, Danushka and Williamson, Paula and Dodd, Susanna. Position-based Prompting for Health Outcome Generation. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.3
-
[5]
Farzana, Shahla and Deshpande, Ashwin and Parde, Natalie. How You Say It Matters: Measuring the Impact of Verbal Disfluency Tags on Automated Dementia Detection. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.4
-
[6]
Zero-Shot Aspect-Based Scientific Document Summarization using Self-Supervised Pre-training
Soleimani, Amir and Nikoulina, Vassilina and Favre, Benoit and Ait Mokhtar, Salah. Zero-Shot Aspect-Based Scientific Document Summarization using Self-Supervised Pre-training. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.5
-
[7]
Data Augmentation for Biomedical Factoid Question Answering
Pappas, Dimitris and Malakasiotis, Prodromos and Androutsopoulos, Ion. Data Augmentation for Biomedical Factoid Question Answering. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.6
-
[8]
Slot Filling for Biomedical Information Extraction
Papanikolaou, Yannis and Staib, Marlene and Grace, Justin Joshua and Bennett, Francine. Slot Filling for Biomedical Information Extraction. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.7
-
[9]
Automatic Biomedical Term Clustering by Learning Fine-grained Term Representations
Zeng, Sihang and Yuan, Zheng and Yu, Sheng. Automatic Biomedical Term Clustering by Learning Fine-grained Term Representations. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.8
-
[10]
B io BART : Pretraining and Evaluation of A Biomedical Generative Language Model
Yuan, Hongyi and Yuan, Zheng and Gan, Ruyi and Zhang, Jiaxing and Xie, Yutao and Yu, Sheng. B io BART : Pretraining and Evaluation of A Biomedical Generative Language Model. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.9
-
[11]
Incorporating Medical Knowledge to Transformer-based Language Models for Medical Dialogue Generation
Naseem, Usman and Bandi, Ajay and Raza, Shaina and Rashid, Junaid and Chakravarthi, Bharathi Raja. Incorporating Medical Knowledge to Transformer-based Language Models for Medical Dialogue Generation. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.10
-
[12]
Memory-aligned Knowledge Graph for Clinically Accurate Radiology Image Report Generation
Yan, Sixing. Memory-aligned Knowledge Graph for Clinically Accurate Radiology Image Report Generation. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.11
-
[13]
Simple Semantic-based Data Augmentation for Named Entity Recognition in Biomedical Texts
Phan, Uyen and Nguyen, Nhung. Simple Semantic-based Data Augmentation for Named Entity Recognition in Biomedical Texts. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.12
-
[14]
Auxiliary Learning for Named Entity Recognition with Multiple Auxiliary Biomedical Training Data
Watanabe, Taiki and Ichikawa, Tomoya and Tamura, Akihiro and Iwakura, Tomoya and Ma, Chunpeng and Kato, Tsuneo. Auxiliary Learning for Named Entity Recognition with Multiple Auxiliary Biomedical Training Data. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.13
-
[15]
SNP 2 V ec: Scalable Self-Supervised Pre-Training for Genome-Wide Association Study
Cahyawijaya, Samuel and Yu, Tiezheng and Liu, Zihan and Zhou, Xiaopu and Mak, Tze Wing Tiffany and Ip, Yuk Yu Nancy and Fung, Pascale. SNP 2 V ec: Scalable Self-Supervised Pre-Training for Genome-Wide Association Study. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.14
-
[16]
Biomedical NER using Novel Schema and Distant Supervision
Khandelwal, Anshita and Kar, Alok and Chikka, Veera Raghavendra and Karlapalem, Kamalakar. Biomedical NER using Novel Schema and Distant Supervision. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.15
-
[17]
Improving Supervised Drug-Protein Relation Extraction with Distantly Supervised Models
Iinuma, Naoki and Miwa, Makoto and Sasaki, Yutaka. Improving Supervised Drug-Protein Relation Extraction with Distantly Supervised Models. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.16
-
[18]
Named Entity Recognition for Cancer Immunology Research Using Distant Supervision
Trieu, Hai-Long and Miwa, Makoto and Ananiadou, Sophia. Named Entity Recognition for Cancer Immunology Research Using Distant Supervision. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.17
-
[19]
Intra-Template Entity Compatibility based Slot-Filling for Clinical Trial Information Extraction
Witte, Christian and Cimiano, Philipp. Intra-Template Entity Compatibility based Slot-Filling for Clinical Trial Information Extraction. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.18
-
[20]
Pretrained Biomedical Language Models for Clinical NLP in S panish
Carrino, Casimiro Pio and Llop, Joan and P \`a mies, Marc and Guti \'e rrez-Fandi \ n o, Asier and Armengol-Estap \'e , Jordi and Silveira-Ocampo, Joaqu \'i n and Valencia, Alfonso and Gonzalez-Agirre, Aitor and Villegas, Marta. Pretrained Biomedical Language Models for Clinical NLP in S panish. Proceedings of the 21st Workshop on Biomedical Language Proc...
-
[21]
Few-Shot Cross-lingual Transfer for Coarse-grained De-identification of Code-Mixed Clinical Texts
Amin, Saadullah and Pokaratsiri Goldstein, Noon and Wixted, Morgan and Garcia-Rudolph, Alejandro and Mart \'i nez-Costa, Catalina and Neumann, Guenter. Few-Shot Cross-lingual Transfer for Coarse-grained De-identification of Code-Mixed Clinical Texts. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.20
-
[22]
Li, Bin and Weng, Yixuan and Xia, Fei and Sun, Bin and Li, Shutao. VPAI \_ L ab at M ed V id QA 2022: A Two-Stage Cross-modal Fusion Method for Medical Instructional Video Classification. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.21
-
[23]
G en C ompare S um: a hybrid unsupervised summarization method using salience
Bishop, Jennifer and Xie, Qianqian and Ananiadou, Sophia. G en C ompare S um: a hybrid unsupervised summarization method using salience. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.22
-
[24]
B io C ite: A Deep Learning-based Citation Linkage Framework for Biomedical Research Articles
Singha Roy, Sudipta and Mercer, Robert E. B io C ite: A Deep Learning-based Citation Linkage Framework for Biomedical Research Articles. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.23
-
[25]
Low Resource Causal Event Detection from Biomedical Literature
Liang, Zhengzhong and Noriega-Atala, Enrique and Morrison, Clayton and Surdeanu, Mihai. Low Resource Causal Event Detection from Biomedical Literature. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.24
-
[26]
Overview of the M ed V id QA 2022 Shared Task on Medical Video Question-Answering
Gupta, Deepak and Demner-Fushman, Dina. Overview of the M ed V id QA 2022 Shared Task on Medical Video Question-Answering. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.25
-
[27]
Richie, Russell and Grover, Sachin and Tsui, Fuchiang (Rich). Inter-annotator agreement is not the ceiling of machine learning performance: Evidence from a comprehensive set of simulations. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.26
-
[28]
and Zuo, Xu and Hu, Yan and Kuttichi Keloth, Vipina and Li, Jianfu and Zheng, W
Das, Avisha and Selek, Salih and Warner, Alia R. and Zuo, Xu and Hu, Yan and Kuttichi Keloth, Vipina and Li, Jianfu and Zheng, W. Jim and Xu, Hua. Conversational Bots for Psychotherapy: A Study of Generative Transformer Models Using Domain-specific Dialogues. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bi...
-
[29]
BEEDS : Large-Scale Biomedical Event Extraction using Distant Supervision and Question Answering
Wang, Xing David and Leser, Ulf and Weber, Leon. BEEDS : Large-Scale Biomedical Event Extraction using Distant Supervision and Question Answering. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.28
-
[30]
Data Augmentation for Rare Symptoms in Vaccine Side-Effect Detection
Kim, Bosung and Nakashole, Ndapa. Data Augmentation for Rare Symptoms in Vaccine Side-Effect Detection. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.29
-
[31]
Improving R omanian B io NER Using a Biologically Inspired System
Mitrofan, Maria and Pais, Vasile. Improving R omanian B io NER Using a Biologically Inspired System. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.30
-
[32]
B angla B io M ed: A Biomedical Named-Entity Annotated Corpus for B angla ( B engali)
Sazzed, Salim. B angla B io M ed: A Biomedical Named-Entity Annotated Corpus for B angla ( B engali). Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.31
-
[33]
ICDB ig B ird: A Contextual Embedding Model for ICD Code Classification
Michalopoulos, George and Malyska, Michal and Sahar, Nicola and Wong, Alexander and Chen, Helen. ICDB ig B ird: A Contextual Embedding Model for ICD Code Classification. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.32
-
[34]
Doctor XA v I er: Explainable Diagnosis on Physician-Patient Dialogues and XAI Evaluation
Ngai, Hillary and Rudzicz, Frank. Doctor XA v I er: Explainable Diagnosis on Physician-Patient Dialogues and XAI Evaluation. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.33
-
[35]
Dhrangadhariya, Anjani and M. DISTANT - CTO : A Zero Cost, Distantly Supervised Approach to Improve Low-Resource Entity Extraction Using Clinical Trials Literature. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.34
-
[36]
Tang, Liyan and Kooragayalu, Shravan and Wang, Yanshan and Ding, Ying and Durrett, Greg and Rousseau, Justin F. and Peng, Yifan. E cho G en: Generating Conclusions from Echocardiogram Notes. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.35
-
[37]
Quantifying Clinical Outcome Measures in Patients with Epilepsy Using the Electronic Health Record
Xie, Kevin and Litt, Brian and Roth, Dan and Ellis, Colin A. Quantifying Clinical Outcome Measures in Patients with Epilepsy Using the Electronic Health Record. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.36
-
[38]
Sarrouti, Mourad and Tao, Carson and Mamy Randriamihaja, Yoann. Comparing Encoder-Only and Encoder-Decoder Transformers for Relation Extraction from Biomedical Texts: An Empirical Study on Ten Benchmark Datasets. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.37
-
[39]
Utility Preservation of Clinical Text After De-Identification
Vakili, Thomas and Dalianis, Hercules. Utility Preservation of Clinical Text After De-Identification. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.38
-
[40]
Horses to Zebras: Ontology-Guided Data Augmentation and Synthesis for ICD -9 Coding
Falis, Mat \'u s and Dong, Hang and Birch, Alexandra and Alex, Beatrice. Horses to Zebras: Ontology-Guided Data Augmentation and Synthesis for ICD -9 Coding. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.39
-
[41]
Chandak, Sidhant and Zhang, Liqing and Brown, Connor and Huang, Lifu. Towards Automatic Curation of Antibiotic Resistance Genes via Statement Extraction from Scientific Papers: A Benchmark Dataset and Models. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.40
-
[42]
Model Distillation for Faithful Explanations of Medical Code Predictions
Wood-Doughty, Zach and Cachola, Isabel and Dredze, Mark. Model Distillation for Faithful Explanations of Medical Code Predictions. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.41
-
[43]
Liang, Jennifer J and Lehman, Eric and Iyengar, Ananya and Mahajan, Diwakar and Raghavan, Preethi and Chang, Cindy Y. and Szolovits, Peter. Towards Generalizable Methods for Automating Risk Score Calculation. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.42
-
[44]
D o SSIER at M ed V id QA 2022: Text-based Approaches to Medical Video Answer Localization Problem
Kusa, Wojciech and Peikos, Georgios and Espitia, \'O scar and Hanbury, Allan and Pasi, Gabriella. D o SSIER at M ed V id QA 2022: Text-based Approaches to Medical Video Answer Localization Problem. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.43
-
[45]
Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. 2022
2022
-
[46]
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
Jin, Xisen and Zhang, Dejiao and Zhu, Henghui and Xiao, Wei and Li, Shang-Wen and Wei, Xiaokai and Arnold, Andrew and Ren, Xiang. Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. 2022. doi:10.18653/v1/2022.bigsc...
-
[47]
Using ASR -Generated Text for Spoken Language Modeling
Herv \'e , Nicolas and Pelloin, Valentin and Favre, Benoit and Dary, Franck and Laurent, Antoine and Meignier, Sylvain and Besacier, Laurent. Using ASR -Generated Text for Spoken Language Modeling. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. 2022. doi:10.18653/v1/2022.bigscience-1.2
-
[48]
You reap what you sow: On the Challenges of Bias Evaluation Under Multilingual Settings
Talat, Zeerak and N \'e v \'e ol, Aur \'e lie and Biderman, Stella and Clinciu, Miruna and Dey, Manan and Longpre, Shayne and Luccioni, Sasha and Masoud, Maraim and Mitchell, Margaret and Radev, Dragomir and Sharma, Shanya and Subramonian, Arjun and Tae, Jaesung and Tan, Samson and Tunuguntla, Deepak and Van Der Wal, Oskar. You reap what you sow: On the C...
-
[49]
Diverse Lottery Tickets Boost Ensemble from a Single Pretrained Model
Kobayashi, Sosuke and Kiyono, Shun and Suzuki, Jun and Inui, Kentaro. Diverse Lottery Tickets Boost Ensemble from a Single Pretrained Model. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. 2022. doi:10.18653/v1/2022.bigscience-1.4
-
[50]
UNIREX : A Unified Learning Framework for Language Model Rationale Extraction
Chan, Aaron and Sanjabi, Maziar and Mathias, Lambert and Tan, Liang and Nie, Shaoliang and Peng, Xiaochang and Ren, Xiang and Firooz, Hamed. UNIREX : A Unified Learning Framework for Language Model Rationale Extraction. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. 2022. doi:10.18653/v1/...
-
[51]
Pipelines for Social Bias Testing of Large Language Models
Nozza, Debora and Bianchi, Federico and Hovy, Dirk. Pipelines for Social Bias Testing of Large Language Models. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. 2022. doi:10.18653/v1/2022.bigscience-1.6
-
[52]
Entities, Dates, and Languages: Zero-Shot on Historical Texts with T0
De Toni, Francesco and Akiki, Christopher and De La Rosa, Javier and Fourrier, Cl \'e mentine and Manjavacas, Enrique and Schweter, Stefan and Van Strien, Daniel. Entities, Dates, and Languages: Zero-Shot on Historical Texts with T0. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. 2022. do...
-
[53]
A Holistic Assessment of the Carbon Footprint of Noor, a Very Large A rabic Language Model
Lakim, Imad and Almazrouei, Ebtesam and Abualhaol, Ibrahim and Debbah, Merouane and Launay, Julien. A Holistic Assessment of the Carbon Footprint of Noor, a Very Large A rabic Language Model. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. 2022. doi:10.18653/v1/2022.bigscience-1.8
-
[54]
GPT - N eo X -20 B : An Open-Source Autoregressive Language Model
Black, Sidney and Biderman, Stella and Hallahan, Eric and Anthony, Quentin and Gao, Leo and Golding, Laurence and He, Horace and Leahy, Connor and McDonell, Kyle and Phang, Jason and Pieler, Michael and Prashanth, Usvsn Sai and Purohit, Shivanshu and Reynolds, Laria and Tow, Jonathan and Wang, Ben and Weinbach, Samuel. GPT - N eo X -20 B : An Open-Source ...
-
[55]
Dataset Debt in Biomedical Language Modeling
Fries, Jason and Seelam, Natasha and Altay, Gabriel and Weber, Leon and Kang, Myungsun and Datta, Debajyoti and Su, Ruisi and Garda, Samuele and Wang, Bo and Ott, Simon and Samwald, Matthias and Kusa, Wojciech. Dataset Debt in Biomedical Language Modeling. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large La...
-
[56]
Emergent Structures and Training Dynamics in Large Language Models
Teehan, Ryan and Clinciu, Miruna and Serikov, Oleg and Szczechla, Eliza and Seelam, Natasha and Mirkin, Shachar and Gokaslan, Aaron. Emergent Structures and Training Dynamics in Large Language Models. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Perspectives in Creating Large Language Models. 2022. doi:10.18653/v1/2022.bigscience-1.11
-
[57]
Horawalavithana, Sameera and Ayton, Ellyn and Sharma, Shivam and Howland, Scott and Subramanian, Megha and Vasquez, Scott and Cosbey, Robin and Glenski, Maria and Volkova, Svitlana. Foundation Models of Scientific Knowledge for Chemistry: Opportunities, Challenges and Lessons Learned. Proceedings of BigScience Episode \# 5 -- Workshop on Challenges & Pers...
-
[58]
Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022
2022
-
[59]
Kwako, Alexander and Wan, Yixin and Zhao, Jieyu and Chang, Kai-Wei and Cai, Li and Hansen, Mark. Using Item Response Theory to Measure Gender and Racial Bias of a BERT -based Automated E nglish Speech Assessment System. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.1
-
[60]
Automatic scoring of short answers using justification cues estimated by BERT
Takano, Shunya and Ichikawa, Osamu. Automatic scoring of short answers using justification cues estimated by BERT. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.2
-
[61]
Mitigating Learnerese Effects for CEFR Classification
Jalota, Rricha and Bourgonje, Peter and Van Sas, Jan and Huang, Huiyan. Mitigating Learnerese Effects for CEFR Classification. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.3
-
[62]
Automatically Detecting Reduced-formed E nglish Pronunciations by Using Deep Learning
Chen, Lei and Jiang, Chenglin and Gu, Yiwei and Liu, Yang and Yuan, Jiahong. Automatically Detecting Reduced-formed E nglish Pronunciations by Using Deep Learning. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.4
-
[63]
A Baseline Readability Model for C ebuano
Imperial, Joseph Marvin and Reyes, Lloyd Lois Antonie and Ibanez, Michael Antonio and Sapinit, Ranz and Hussien, Mohammed. A Baseline Readability Model for C ebuano. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.5
-
[64]
Generation of Synthetic Error Data of Verb Order Errors for S wedish
Casademont Moner, Judit and Volodina, Elena. Generation of Synthetic Error Data of Verb Order Errors for S wedish. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.6
-
[65]
A Dependency Treebank of Spoken Second Language E nglish
Kyle, Kristopher and Eguchi, Masaki and Miller, Aaron and Sither, Theodore. A Dependency Treebank of Spoken Second Language E nglish. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.7
-
[66]
Jia, Qinjin and Cao, Yupeng and Gehringer, Edward. Starting from ``Zero'': An Incremental Zero-shot Learning Approach for Assessing Peer Feedback Comments. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.8
-
[67]
On Assessing and Developing Spoken `Grammatical Error Correction' Systems
Lu, Yiting and Bann \`o , Stefano and Gales, Mark. On Assessing and Developing Spoken `Grammatical Error Correction' Systems. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.9
-
[68]
Automatic True/False Question Generation for Educational Purpose
Zou, Bowei and Li, Pengfei and Pan, Liangming and Aw, Ai Ti. Automatic True/False Question Generation for Educational Purpose. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.10
-
[69]
Suresh, Abhijit and Jacobs, Jennifer and Perkoff, Margaret and Martin, James H. and Sumner, Tamara. Fine-tuning Transformers with Additional Context to Classify Discursive Moves in Mathematics Classrooms. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.11
-
[70]
Bann \`o , Stefano and Matassoni, Marco. Cross-corpora experiments of automatic proficiency assessment and error detection for spoken E nglish. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.12
-
[71]
Activity focused Speech Recognition of Preschool Children in Early Childhood Classrooms
Dutta, Satwik and Irvin, Dwight and Buzhardt, Jay and Hansen, John H.L. Activity focused Speech Recognition of Preschool Children in Early Childhood Classrooms. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.13
-
[72]
Loginova, Ekaterina and Benoit, Dries. Structural information in mathematical formulas for exercise difficulty prediction: a comparison of NLP representations. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.14
-
[73]
The Specificity and Helpfulness of Peer-to-Peer Feedback in Higher Education
Rietsche, Roman and Caines, Andrew and Schramm, Cornelius and Pf. The Specificity and Helpfulness of Peer-to-Peer Feedback in Higher Education. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.15
-
[74]
Similarity-Based Content Scoring - How to Make S - BERT Keep Up With BERT
Bexte, Marie and Horbach, Andrea and Zesch, Torsten. Similarity-Based Content Scoring - How to Make S - BERT Keep Up With BERT. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.16
-
[75]
Don ' t Drop the Topic - The Role of the Prompt in Argument Identification in Student Writing
Ding, Yuning and Bexte, Marie and Horbach, Andrea. Don ' t Drop the Topic - The Role of the Prompt in Argument Identification in Student Writing. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.17
-
[76]
ALEN App: Argumentative Writing Support To Foster E nglish Language Learning
Wambsganss, Thiemo and Caines, Andrew and Buttery, Paula. ALEN App: Argumentative Writing Support To Foster E nglish Language Learning. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.18
-
[77]
Weiss, Zarah and Meurers, Detmar. Assessing sentence readability for G erman language learners with broad linguistic modeling or readability formulas: When do linguistic insights make a difference?. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.19
-
[78]
Heck, Tanja and Meurers, Detmar. Parametrizable exercise generation from authentic texts: Effectively targeting the language means on the curriculum. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.20
-
[79]
Selecting Context Clozes for Lightweight Reading Compliance
Keim, Greg and Littman, Michael. Selecting Context Clozes for Lightweight Reading Compliance. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.21
-
[80]
Laarmann-Quante, Ronja and Schwarz, Leska and Horbach, Andrea and Zesch, Torsten. `Meet me at the ribary' -- Acceptability of spelling variants in free-text answers to listening comprehension prompts. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.