When Is an LLM Worth It for Hyperparameter Optimization? A Budget-Matched Study on Tabular Data Finds the Warm-Start Is a Default Configuration, Not the Model
Pith reviewed 2026-06-29 04:34 UTC · model grok-4.3
The pith
A fixed default configuration accounts for nearly all performance in LLM-based hyperparameter optimization on tabular data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
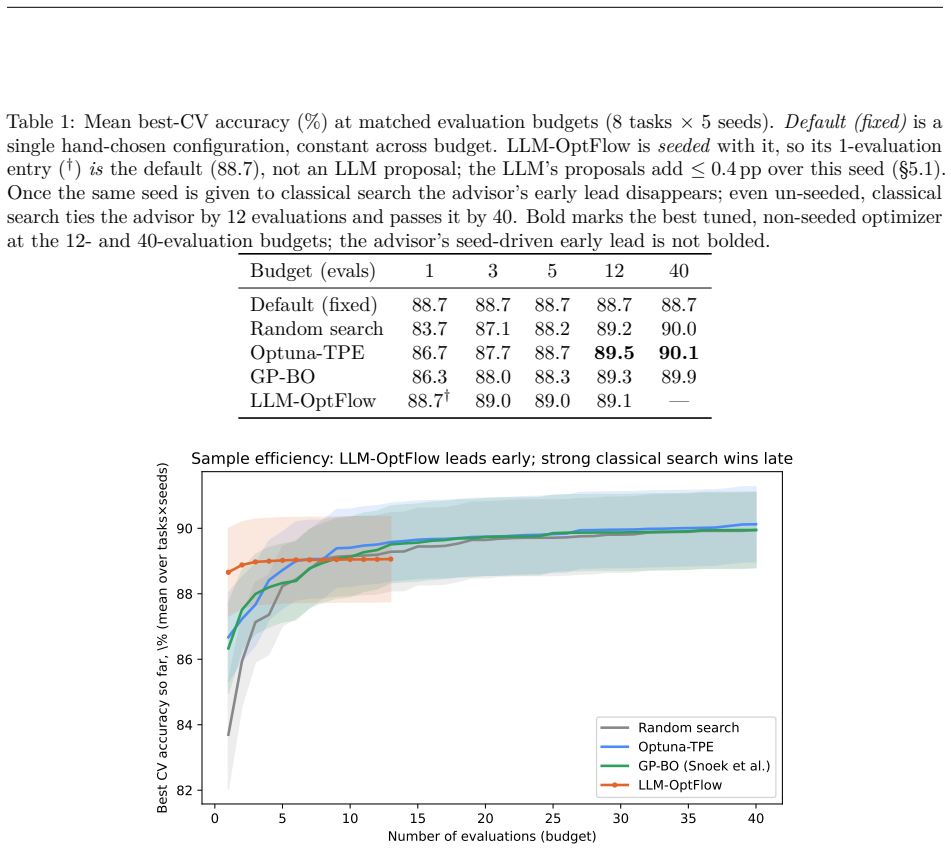
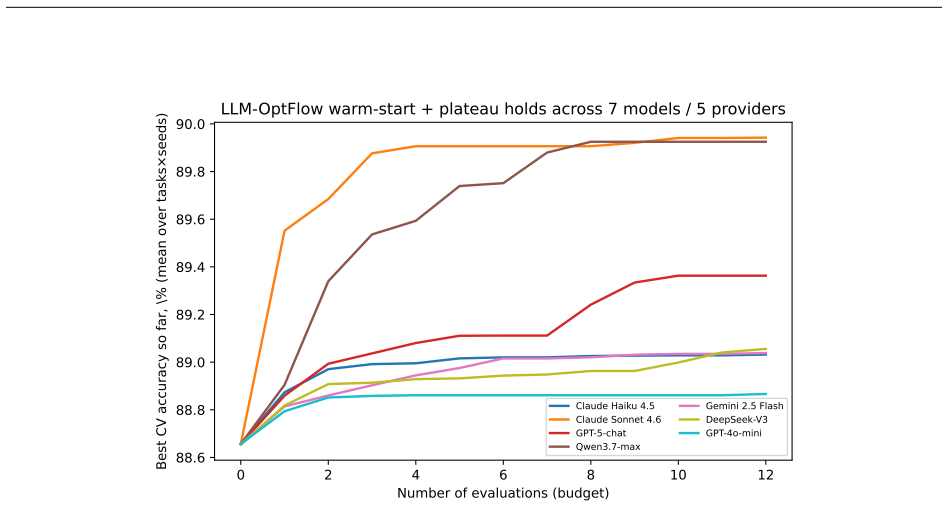
The initial default configuration, evaluated before any model call, reaches 88.7 percent mean best-CV accuracy and is identical within 0.01 pp across all seven advisor models tested. LLM proposals add only +0.40 pp of cross-validation accuracy over that seed and nothing on held-out test. When the same seed is granted to classical search, the advisor's lead collapses within a handful of evaluations, and unseeded classical methods tie the advisor by 12 evaluations and beat it by 40.
What carries the argument
The fixed default configuration used as the first evaluation point that seeds the search loop before any LLM calls.
If this is right
- Seeded random search matches the LLM advisor by five evaluations and falls behind only at two evaluations.
- Unseeded classical methods tie the LLM advisor by twelve evaluations and outperform it by 0.6 to 0.8 pp after forty evaluations.
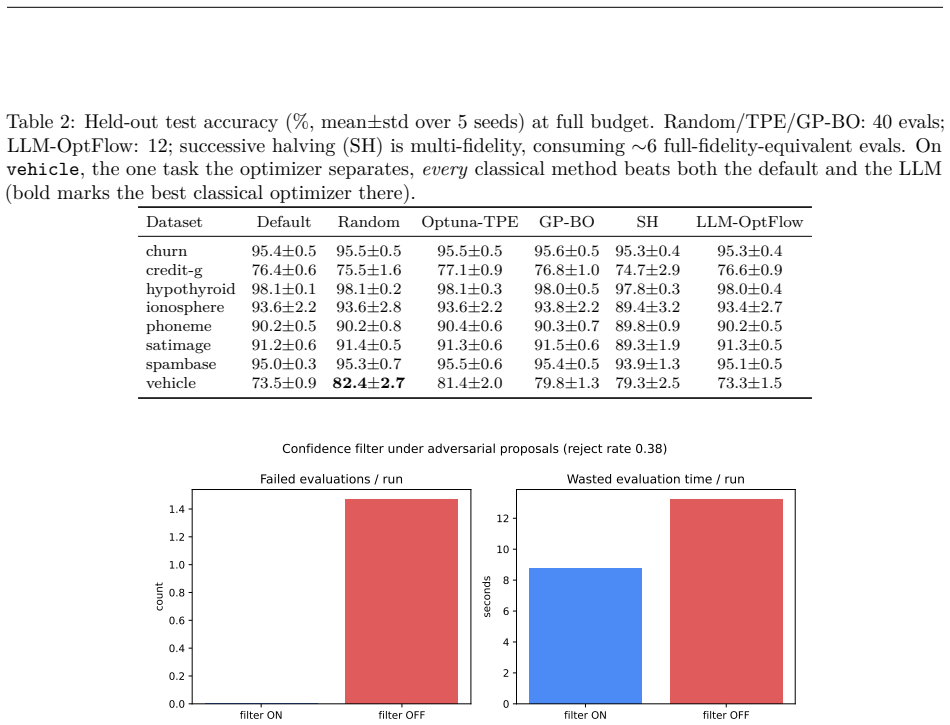
- A rule-based confidence filter removes roughly one-third of wasted compute without changing final accuracy.
- The LLM advisor exhibits a single-task exploration failure on the vehicle dataset.
Where Pith is reading between the lines
- The results imply that effort on tabular HPO should focus on selecting or learning strong defaults rather than on language-model integration.
- The negative finding may not extend to non-tabular domains or search spaces where sensible defaults are harder to identify in advance.
- A natural extension would be to test whether the same pattern holds when the default is deliberately poor or when the search space is much larger.
Load-bearing premise
The eight PMLB tabular benchmarks, the shared search space, and the chosen default configuration are representative of typical tabular hyperparameter optimization practice.
What would settle it
Re-running the identical protocol on a fresh set of tabular datasets drawn from a different source or with a different default configuration that was not selected with knowledge of these benchmarks.
Figures
read the original abstract
Large language models (LLMs) have been proposed as hyperparameter-optimization (HPO) advisors that "warm-start" search from prior knowledge, proposing strong configurations in very few evaluations. We test that claim under a budget-matched, multi-seed protocol on eight PMLB tabular benchmarks, comparing an LLM advisor (LLM-OptFlow) against four classical baselines (random search, Optuna-TPE, Gaussian-process Bayesian optimization, and successive halving) over one shared search space, with paired tests and bootstrap 95% CIs across 8 x 5 = 40 (task, seed) units. The finding is cautionary. The advisor's strong first point is not an LLM output at all: like prior LLM-HPO systems the loop is seeded with a fixed default configuration, evaluated before any model call, which alone reaches 88.7% mean best-CV, identical to within 0.01 pp across all seven advisor models tested. The LLM's own proposals add only +0.40 pp of cross-validation accuracy over that seed and nothing on held-out test (LLM-Default = -0.01 pp, p = 0.92). When the same seed is granted to classical search, the apparent lead collapses: against seeded random search it leads by +0.20 pp at 2 evaluations, is tied by 5, and is behind by 12 (-0.37 pp). Without the seed, classical search ties the advisor by 12 evaluations and beats it by 40 (+0.6 to +0.8 pp, p <= 1e-4). Two LLM-specific behaviors survive: a single-task exploration failure (vehicle), and a rule-based confidence filter that removes ~33% of wasted compute without changing accuracy. The recommendation is deflationary: on tabular HPO, seed classical search with a sensible default; an LLM advisor adds no measurable generalization benefit and is overtaken within a handful of evaluations. We release the harness and a script that reproduces every statistic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a budget-matched empirical comparison of an LLM advisor (LLM-OptFlow) against classical HPO methods (random search, TPE, GP-BO, successive halving) on eight PMLB tabular classification tasks. Using a shared search space, paired tests, and bootstrap CIs over 40 (task, seed) units, it finds that a fixed default configuration evaluated before any LLM call reaches 88.7% mean best-CV accuracy; LLM proposals add only +0.40 pp on CV and nothing on held-out test. Classical methods granted the same seed match or exceed the advisor within a few evaluations, leading to the recommendation that sensible defaults suffice and LLM advisors add no measurable benefit for tabular HPO.
Significance. If the protocol and results hold, the work supplies a clear, reproducible empirical counter-example to claims that LLM warm-starts deliver substantial gains in low-evaluation regimes for tabular HPO. The release of the full harness and reproduction script is a concrete strength that allows direct verification of every reported statistic. The finding is deflationary but directly relevant to practical HPO design.
major comments (2)
- [Methods (default configuration and search space)] The central negative result on LLM value rests on the fixed default reaching 88.7% mean best-CV. The manuscript does not state the provenance of this default (e.g., whether it is an a-priori sklearn-style choice or was selected after inspecting the eight PMLB tasks). Without this information, it is impossible to judge whether the comparison is to a generic sensible seed or to an already-strong baseline tuned to the test distribution.
- [Discussion and conclusion] The recommendation that 'an LLM advisor adds no measurable generalization benefit' is scoped to the eight PMLB tasks and the chosen shared search space. No ablation or sensitivity check is reported on regression tasks, larger tables, or alternative hyperparameter spaces where LLM priors might differ; this limits the scope of the deflationary claim.
minor comments (2)
- [Methods] The exact prompting template and rule-based confidence filter are described only at high level; a short appendix excerpt would improve reproducibility.
- [Figures] Figure captions and axis labels should explicitly note that all curves include the shared default seed evaluation at step 0.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for recognizing the reproducibility of the study. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Methods (default configuration and search space)] The central negative result on LLM value rests on the fixed default reaching 88.7% mean best-CV. The manuscript does not state the provenance of this default (e.g., whether it is an a-priori sklearn-style choice or was selected after inspecting the eight PMLB tasks). Without this information, it is impossible to judge whether the comparison is to a generic sensible seed or to an already-strong baseline tuned to the test distribution.
Authors: We agree that the provenance of the default configuration should be stated explicitly. The default is the standard scikit-learn library default for each classifier, selected a priori without reference to the PMLB tasks or any post-hoc tuning. This matches the initialization used in prior LLM-HPO literature. We will revise the manuscript to include this clarification in the Methods section. revision: yes
-
Referee: [Discussion and conclusion] The recommendation that 'an LLM advisor adds no measurable generalization benefit' is scoped to the eight PMLB tasks and the chosen shared search space. No ablation or sensitivity check is reported on regression tasks, larger tables, or alternative hyperparameter spaces where LLM priors might differ; this limits the scope of the deflationary claim.
Authors: The manuscript intentionally scopes its claims to the eight PMLB tabular classification tasks and the shared search space, as stated in the abstract and conclusion. We do not claim results for regression, larger datasets, or different spaces. The deflationary recommendation is presented within this context. We will ensure the discussion section makes the scope even more explicit if needed, but no new experiments are warranted for this focused study. revision: partial
Circularity Check
No circularity: purely empirical benchmark comparison with no derivations or self-referential reductions
full rationale
The paper reports results from a controlled empirical protocol on eight fixed PMLB tabular tasks using one shared search space and a single fixed default seed evaluated before any LLM call. All claims (e.g., default alone reaches 88.7% mean best-CV, LLM adds +0.40 pp CV but 0 on test, classical seeded search matches or exceeds) are direct measurements with paired tests and bootstrap CIs across 40 (task,seed) units. No equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes appear; the central deflationary recommendation follows from the observed numbers rather than reducing to any input by construction. This is the expected non-finding for an experimental methods paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption PMLB tabular benchmarks are representative of typical tabular HPO tasks
- domain assumption The fixed default configuration is a fair and non-LLM baseline that prior LLM-HPO systems also use
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Practical Bayesian Optimization of Machine Learning Algorithms , author =. Advances in Neural Information Processing Systems , volume =
-
[2]
2019 , url =
Keras Tuner , author =. 2019 , url =
2019
-
[3]
Journal of Machine Learning Research , volume =
Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization , author =. Journal of Machine Learning Research , volume =
-
[4]
Proceedings of LION 2011 , pages =
Sequential Model-Based Optimization for General Algorithm Configuration , author =. Proceedings of LION 2011 , pages =
2011
-
[5]
2023 , eprint =
Using Large Language Models for Hyperparameter Optimization , author =. 2023 , eprint =
2023
-
[6]
Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =
Optuna: A Next-generation Hyperparameter Optimization Framework , author =. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2019 , doi =
2019
-
[7]
International Conference on Learning Representations (ICLR) , year=
Large Language Models as Optimizers , author=. International Conference on Learning Representations (ICLR) , year=
-
[10]
International Conference on Learning Representations (ICLR) , year=
Large Language Models to Enhance Bayesian Optimization , author=. International Conference on Learning Representations (ICLR) , year=
-
[11]
International Conference on Machine Learning (ICML) , year=
MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation , author=. International Conference on Machine Learning (ICML) , year=
-
[12]
International Conference on Learning Representations (ICLR) , year=
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering , author=. International Conference on Learning Representations (ICLR) , year=
-
[13]
and Tan, Shangyin and Soylu, Dilara and Ziems, Noah and Khare, Rishi and Opsahl-Ong, Krista and Singhvi, Arnav and Shandilya, Herumb and Ryan, Michael J
Agrawal, Lakshya A. and Tan, Shangyin and Soylu, Dilara and Ziems, Noah and Khare, Rishi and Opsahl-Ong, Krista and Singhvi, Arnav and Shandilya, Herumb and Ryan, Michael J. and Jiang, Meng and Potts, Christopher and Sen, Koushik and Dimakis, Alexandros G. and Stoica, Ion and Klein, Dan and Zaharia, Matei and Khattab, Omar , booktitle=. 2026 , note=
2026
-
[14]
Journal of Machine Learning Research , volume=
Random Search for Hyper-Parameter Optimization , author=. Journal of Machine Learning Research , volume=
-
[15]
BioData Mining , volume=
PMLB: A Large Benchmark Suite for Machine Learning Evaluation and Comparison , author=. BioData Mining , volume=
-
[16]
Statistical Science , volume=
Bootstrap Methods for Standard Errors, Confidence Intervals, and Other Measures of Statistical Accuracy , author=. Statistical Science , volume=
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Initializing Bayesian Hyperparameter Optimization via Meta-Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[18]
Advances in Neural Information Processing Systems , volume=
Efficient and Robust Automated Machine Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Naphade, Om and Bansal, Saksham and Pareek, Parikshit , journal=. Small
-
[22]
Revisiting
Zhang, Tuo and Yuan, Jinyue and Avestimehr, Salman , journal=. Revisiting
-
[23]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A. Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J. Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. GEPA : Reflective prompt evolution can outperform reinforcement learning. In International C...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Takuya Akiba, Shotaro Sano, Toshihiro Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp.\ 2623--2631, 2019. doi:10.1145/3292500.3330701
-
[25]
Random search for hyper-parameter optimization
James Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization. Journal of Machine Learning Research, 13: 0 281--305, 2012
2012
-
[26]
Mle-bench: Evaluating machine learning agents on machine learning engineering
Jun Shern Chan et al. Mle-bench: Evaluating machine learning agents on machine learning engineering. International Conference on Learning Representations (ICLR), 2025
2025
-
[27]
Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy
Bradley Efron and Robert Tibshirani. Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy. Statistical Science, 1 0 (1): 0 54--75, 1986
1986
-
[28]
Efficient and robust automated machine learning
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Tobias Springenberg, Manuel Blum, and Frank Hutter. Efficient and robust automated machine learning. In Advances in Neural Information Processing Systems, volume 28, 2015 a
2015
-
[29]
Initializing bayesian hyperparameter optimization via meta-learning
Matthias Feurer, Jost Tobias Springenberg, and Frank Hutter. Initializing bayesian hyperparameter optimization via meta-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 29, 2015 b
2015
-
[30]
Mlagentbench: Evaluating language agents on machine learning experimentation
Qian Huang, Jian Vora, Percy Liang, and Jure Leskovec. Mlagentbench: Evaluating language agents on machine learning experimentation. In International Conference on Machine Learning (ICML), 2024
2024
-
[31]
Hoos, and Kevin Leyton-Brown
Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Sequential model-based optimization for general algorithm configuration. In Proceedings of LION 2011, pp.\ 507--523, 2011
2011
-
[32]
Hyperband: A novel bandit-based approach to hyperparameter optimization
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization. Journal of Machine Learning Research, 18 0 (185): 0 1--52, 2018
2018
-
[33]
Large language model agent for hyper-parameter optimization
Siyi Liu, Chen Gao, and Yong Li. Large language model agent for hyper-parameter optimization. arXiv preprint arXiv:2402.01881, 2024 a
-
[34]
Large language models to enhance bayesian optimization
Tennison Liu, Nicol \'a s Astorga, Nabeel Seedat, and Mihaela van der Schaar. Large language models to enhance bayesian optimization. In International Conference on Learning Representations (ICLR), 2024 b
2024
-
[35]
Sequential large language model-based hyper-parameter optimization
Kanan Mahammadli and Seyda Ertekin. Sequential large language model-based hyper-parameter optimization. arXiv preprint arXiv:2410.20302, 2024
-
[36]
Small LLMs with expert blocks are good enough for hyperparameter tuning
Om Naphade, Saksham Bansal, and Parikshit Pareek. Small LLMs with expert blocks are good enough for hyperparameter tuning. arXiv preprint arXiv:2509.15561, 2025
-
[37]
Pmlb: A large benchmark suite for machine learning evaluation and comparison
Randal S Olson, William La Cava, Patryk Orzechowski, Ryan J Urbanowicz, and Jason H Moore. Pmlb: A large benchmark suite for machine learning evaluation and comparison. BioData Mining, 10 0 (36), 2017
2017
-
[38]
Keras tuner, 2019
Tom O'Malley, Elie Bursztein, James Long, François Chollet, Haifeng Jin, Luca Invernizzi, et al. Keras tuner, 2019. URL https://github.com/keras-team/keras-tuner
2019
-
[39]
Reproducibility study of large language model bayesian optimization
Adam Rychert, Gasper Spagnolo, and Evgenii Posashkov. Reproducibility study of large language model bayesian optimization. arXiv preprint arXiv:2511.18891, 2025
-
[40]
Jasper Snoek, Hugo Larochelle, and Ryan P. Adams. Practical bayesian optimization of machine learning algorithms. In Advances in Neural Information Processing Systems, volume 25, 2012
2012
-
[41]
Srinath Srinivasan and Tim Menzies. Beyond the prompt: Assessing domain knowledge strategies for high-dimensional hyperparameter optimization. arXiv preprint arXiv:2602.02752, 2026
-
[42]
Large language models as optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. In International Conference on Learning Representations (ICLR), 2024
2024
-
[43]
Zhang, Nishkrit Desai, Juhan Bae, Jonathan Lorraine, and Jimmy Ba
Michael R. Zhang, Nishkrit Desai, Juhan Bae, Jonathan Lorraine, and Jimmy Ba. Using large language models for hyperparameter optimization, 2023
2023
-
[44]
Revisiting OPRO : The limitations of small-scale LLMs as optimizers
Tuo Zhang, Jinyue Yuan, and Salman Avestimehr. Revisiting OPRO : The limitations of small-scale LLMs as optimizers. arXiv preprint arXiv:2405.10276, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.