ARCO: Adaptive Rubric with Co-Evolution for Multi-Step LLM-Based Agents
Pith reviewed 2026-06-26 14:32 UTC · model grok-4.3
The pith
ARCO co-evolves a shared-backbone model that generates per-step rubrics and scores them so the policy can receive step-level rewards without step labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
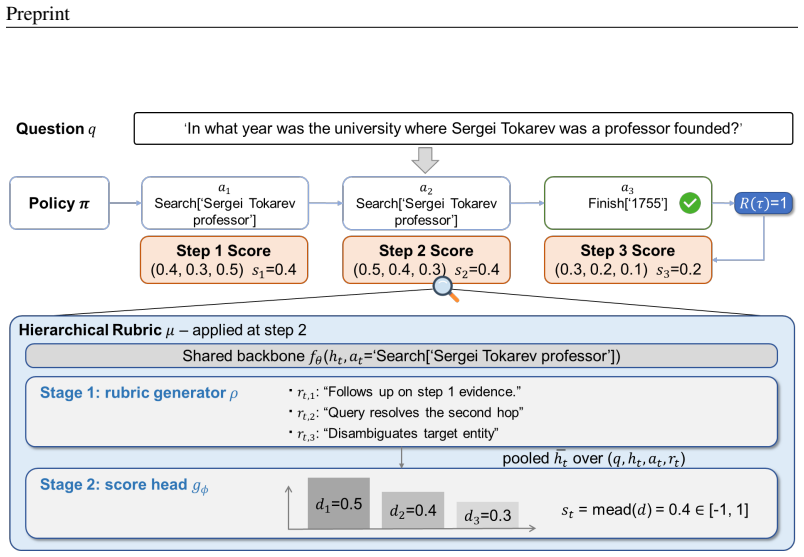
ARCO is a rubric framework in which a same-scale model μ shares a backbone with two heads: a generation head that produces per-step criteria, and a score head that predicts rubric-conditioned step-level rewards. A trajectory decomposition constraint ties the sum of step rewards to the terminal outcome, enabling credit assignment without step-level labels, while μ and the policy π are jointly updated on on-policy data so that the rubric content and the scoring function co-evolve at the parameter level.
What carries the argument
The joint training of the generation and score heads inside model μ with the agent policy π under the trajectory decomposition constraint that forces step rewards to sum to the terminal outcome.
If this is right
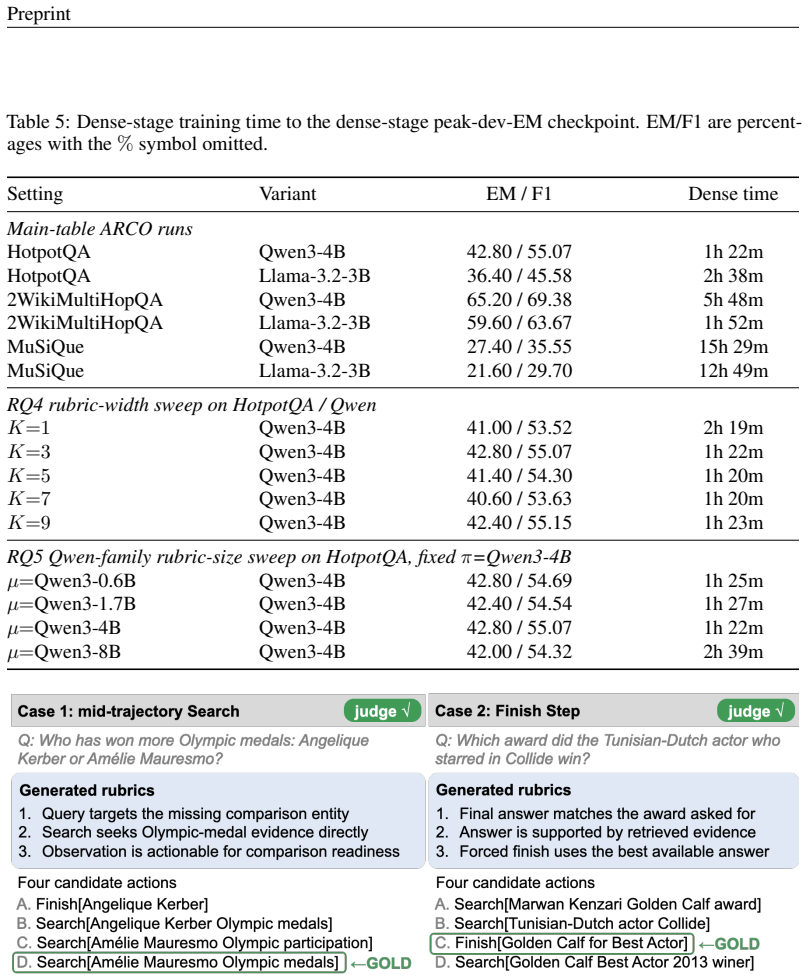
- Exact-match scores rise above the best outcome-reward, rubric-reward, and process-reward baselines on all three multi-hop QA datasets for both backbones tested.
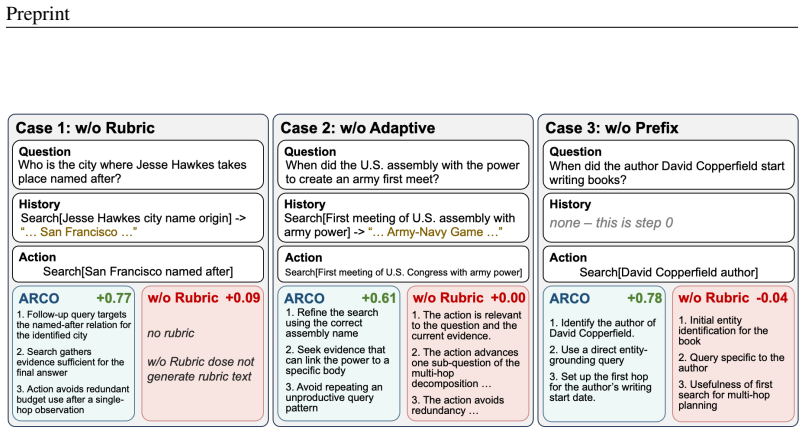
- The generated rubrics are step-specific rather than generic trajectory-level statements.
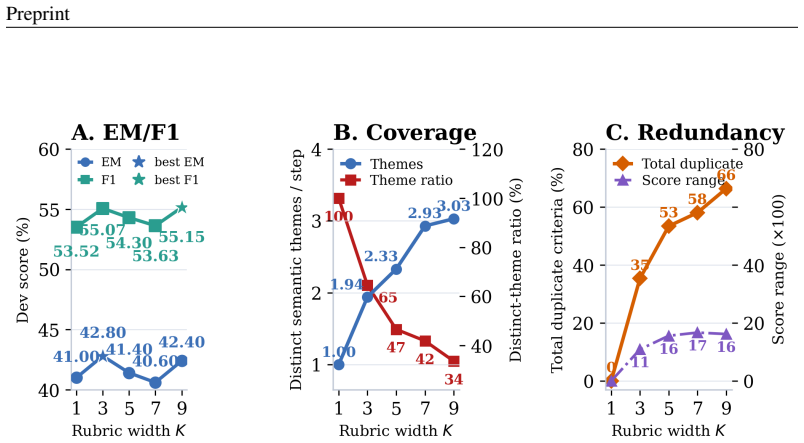
- The rubrics remain effective across different design choices for the generation prompt.
- The rubrics can be inspected to diagnose which steps the agent is handling well or poorly.
Where Pith is reading between the lines
- The same co-evolution pattern could be applied to agent tasks whose terminal signal is cheaper to obtain than step-by-step supervision, such as tool-use or web navigation.
- Because the rubric model stays at the same scale as the policy, the method may scale more readily than approaches that rely on a larger frozen judge.
- The step-level scores produced by the score head could serve as an auxiliary training signal for future process-supervised fine-tuning runs.
Load-bearing premise
The constraint that the sum of the predicted step rewards must equal the terminal outcome is enough to produce useful step-level credit assignment even though no step labels are available.
What would settle it
Ablating the trajectory decomposition constraint while keeping every other component of ARCO fixed and checking whether the exact-match gains on HotpotQA, 2WikiMultiHopQA, and MuSiQue disappear.
Figures








read the original abstract
Reinforcement learning for multi-step LLM agents often relies on scalar rewards that indicate success but cannot explain why a trajectory is good or bad. Rubric-based rewards improve interpretability through natural-language criteria, but existing methods score at the trajectory level and freeze the scorer behind a closed-source judge, leaving step-level credit assignment unresolved and the judge itself static. We propose ARCO (Adaptive Rubric CO-evolution), a rubric framework in which a same-scale model $\mu$ shares a backbone with two heads: a generation head that produces per-step criteria, and a score head that predicts rubric-conditioned step-level rewards. A trajectory decomposition constraint ties the sum of step rewards to the terminal outcome, enabling credit assignment without step-level labels, while $\mu$ and the policy $\pi$ are jointly updated on on-policy data so that the rubric content and the scoring function co-evolve at the parameter level. Across HotpotQA, 2WikiMultiHopQA, and MuSiQue with two open-source backbones, ARCO improves the best EM in every setting over strong outcome-, rubric-, and process-reward baselines, and analyses show that its rubrics are step-specific, robust to design choices, and useful for diagnosing agent behavior. Codes and data are available at https://github.com/zihangtian/ARCO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ARCO, a framework for multi-step LLM agents in which a single-scale model μ shares a backbone between a generation head (producing per-step natural-language rubrics) and a score head (producing rubric-conditioned step rewards). A trajectory decomposition constraint enforces that the sum of step-level rewards equals the terminal outcome reward, enabling credit assignment without step labels; μ and the policy π are jointly trained on on-policy trajectories so that rubric generation and scoring co-evolve. The authors report that ARCO raises exact-match scores over outcome-, rubric-, and process-reward baselines on HotpotQA, 2WikiMultiHopQA, and MuSiQue with two open-source backbones, and provide analyses indicating that the learned rubrics are step-specific and diagnostically useful. Code and data are released.
Significance. If the central empirical claims hold, the work supplies a practical route to interpretable, step-level credit assignment for LLM agents without requiring step-level human labels. The joint co-evolution of rubric content and scoring function at the parameter level, together with the open release of code and data, would constitute a reproducible contribution to the literature on process supervision and rubric-based RL.
major comments (2)
- [Training Objective / §3] The trajectory decomposition constraint (abstract and §3) that the sum of per-step rewards equals the terminal outcome is under-constrained: any assignment of step rewards whose sum matches the outcome satisfies the loss, including constant or front-loaded rewards that carry no information about individual step quality. The description does not mention auxiliary terms (entropy, variance, or contrastive penalties) that would force differentiation across steps; without such terms the observed EM gains could arise from improved trajectory-level selection rather than genuine step-level credit assignment.
- [Experiments / §4] The experimental section reports that ARCO improves the best EM in every setting, yet provides no ablation that isolates the decomposition constraint from the co-evolution mechanism, no statistical significance tests across runs, and no verification that the learned step rewards are non-uniform or predictive of step quality. These omissions leave the load-bearing claim—that the constraint produces useful step-level credit assignment—unverified.
minor comments (2)
- [Method] Notation for the shared backbone and the two heads (generation vs. score) is introduced only in the abstract; a diagram or explicit parameter-sharing equation in §3 would clarify the architecture.
- [Analysis] The abstract states that rubrics are “step-specific,” but the precise metric or qualitative protocol used to establish specificity is not summarized; a short table or example in the main text would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comments on the trajectory decomposition constraint and experimental validation. We address each point below, clarifying the role of per-step rubric generation in promoting differentiation and noting where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Training Objective / §3] The trajectory decomposition constraint (abstract and §3) that the sum of per-step rewards equals the terminal outcome is under-constrained: any assignment of step rewards whose sum matches the outcome satisfies the loss, including constant or front-loaded rewards that carry no information about individual step quality. The description does not mention auxiliary terms (entropy, variance, or contrastive penalties) that would force differentiation across steps; without such terms the observed EM gains could arise from improved trajectory-level selection rather than genuine step-level credit assignment.
Authors: The constraint is mathematically satisfied by any step-reward assignment summing to the outcome. However, because the generation head produces distinct natural-language rubrics for each step and the score head conditions directly on those rubrics, the learned scoring function must differentiate across steps to produce rubric-specific rewards; constant or front-loaded assignments would be inconsistent with the varying rubric content. Joint on-policy training of μ and π further selects for assignments that yield policy improvement, as only useful step-level signals allow the agent to correct individual steps. The reported analyses already show the rubrics are step-specific and diagnostically useful, supporting that differentiation occurs in practice. We did not add explicit auxiliary losses, but will add a paragraph in §3 clarifying why the rubric-conditioned architecture mitigates under-constraint. revision: partial
-
Referee: [Experiments / §4] The experimental section reports that ARCO improves the best EM in every setting, yet provides no ablation that isolates the decomposition constraint from the co-evolution mechanism, no statistical significance tests across runs, and no verification that the learned step rewards are non-uniform or predictive of step quality. These omissions leave the load-bearing claim—that the constraint produces useful step-level credit assignment—unverified.
Authors: We acknowledge the absence of an explicit ablation separating the decomposition constraint from co-evolution and the lack of statistical significance tests across independent runs. The existing analyses demonstrate that rubrics are step-specific and useful for diagnosis, which provides indirect evidence that the resulting rewards are non-uniform. Direct verification of reward non-uniformity and predictive power for step quality, together with an ablation and significance tests, would strengthen the central claim. We will add these elements in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmarks remain independent of training constraint
full rationale
The paper's central claims are empirical EM improvements on HotpotQA, 2WikiMultiHopQA, and MuSiQue using open-source backbones, measured against outcome-, rubric-, and process-reward baselines. The trajectory decomposition constraint (sum of step rewards equals terminal outcome) is a training mechanism for the score head without step-level labels, but this does not reduce the reported benchmark gains to the inputs by construction. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The co-evolution of rubric and scoring heads on on-policy data is a joint optimization procedure whose outputs are externally validated on held-out tasks. This is the common case of a self-contained empirical method against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The sum of step-level rewards equals the terminal outcome reward
invented entities (1)
-
Model μ with generation head and score head sharing the same backbone
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Process reward models for llm agents: Practical framework and directions
Sanjiban Choudhury. Process reward models for LLM agents: Practical framework and directions. arXiv preprint arXiv:2502.10325,
-
[2]
SimCSE: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 6894–6910,
2021
-
[3]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aieleen Letman, Akhil Mathur, Alan Schelten, Amy Yang, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Carmo: Dynamic criteria generation for context aware reward modelling
Taneesh Gupta, Shivam Shandilya, Xuchao Zhang, Rahul Madhavan, Supriyo Ghosh, Chetan Bansal, Huaxiu Yao, and Saravan Rajmohan. Carmo: Dynamic criteria generation for context aware reward modelling. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 2202–2261,
2025
-
[6]
10 Preprint Haitao Hong, Yuchen Yan, Xingyu Wu, Guiyang Hou, Wenqi Zhang, Weiming Lu, Yongliang Shen, and Jun Xiao. Cooper: Co-optimizing policy and reward models in reinforcement learning for large language models.arXiv preprint arXiv:2508.05613,
-
[7]
LoRA: Low-Rank Adaptation of Large Language Models
J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.ArXiv, abs/2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Changxin Huang, Yanbin Chang, Junfan Lin, Junyang Liang, Runhao Zeng, and Jianqiang Li
URL https://api.semanticscholar.org/CorpusID:235458009. Changxin Huang, Yanbin Chang, Junfan Lin, Junyang Liang, Runhao Zeng, and Jianqiang Li. Efficient language-instructed skill acquisition via reward-policy co-evolution. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp. 14576–14584, 2025a. Zenan Huang, Yihong Zhuang, Guosh...
-
[9]
Reinforcement learning for long-horizon multi-turn search agents
Vivek Kalyan and Martin Andrews. Reinforcement learning for long-horizon multi-turn search agents. arXiv preprint arXiv:2510.24126,
-
[10]
Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and Haoyu Wang. Openrubrics: Towards scalable synthetic rubric generation for reward modeling and llm alignment.arXiv preprint arXiv:2510.07743, 2025a. Xiaoqian Liu, Ke Wang, Yuchuan Wu, Fei Huang, Yongbin Li, Junge Zhang, and Jianbin Jiao. Agentic reinforcement learning with implicit step rewa...
-
[11]
Nils Reimers and Iryna Gurevych
MohammadHossein Rezaei, Robert Vacareanu, Zihao Wang, Clinton Wang, Bing Liu, Yunzhong He, and Afra Feyza Akyürek. Online rubrics elicitation from pairwise comparisons.arXiv preprint arXiv:2510.07284,
-
[12]
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamish Ivison, Varsha Kishore, Jingming Zhuo, Xinran Zhao, Molly Park, Samuel G Finlayson, David Sontag, et al. Dr tulu: Reinforcement learning with evolving rubrics for deep research.arXiv preprint arXiv:2511.19399,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, et al. R1-Searcher: Incentivizing the search capability in LLMs via reinforcement learning.arXiv preprint arXiv:2503.05592,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Zihang Tian, Rui Li, Jingsen Zhang, Xiaohe Bo, Wei Huo, and Xu Chen. Haps: Hierarchical llm routing with joint architecture and parameter search.arXiv preprint arXiv:2601.05903,
-
[15]
Co-Evolution of Policy and Internal Reward for Language Agents
Xinyu Wang, Hanwei Wu, Jingwei Song, Shuyuan Zhang, Jiayi Zhang, Fanqi Kong, Tung Sum Thomas Kwok, Xiao-Wen Chang, Yuyu Luo, Chenglin Wu, et al. Co-evolution of pol- icy and internal reward for language agents.arXiv preprint arXiv:2604.03098, 2026a. Yinjie Wang, Tianbao Xie, Ke Shen, Mengdi Wang, and Ling Yang. Rlanything: Forge environment, policy, and r...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Watch every step! LLM agent learning via iterative step-level process refinement
Weimin Xiong, Yifan Song, Xiutian Zhao, Wenhao Wu, Xun Wang, Ke Wang, Cheng Li, Wei Peng, and Sujian Li. Watch every step! LLM agent learning via iterative step-level process refinement. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
2024
-
[17]
Ran Xu, Tianci Liu, Zihan Dong, Tony Yu, Ilgee Hong, Carl Yang, Linjun Zhang, Tao Zhao, and Haoyu Wang. Alternating reinforcement learning for rubric-based reward modeling in non- verifiable LLM post-training.arXiv preprint arXiv:2602.01511,
-
[18]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380,
2018
-
[20]
Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment
Siliang Zeng, Quan Wei, William Brown, Oana Frunza, Yuriy Nevmyvaka, Yang Katie Zhao, and Mingyi Hong. Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment. In ICML 2025 Workshop on Computer Use Agents,
2025
-
[21]
Junkai Zhang, Zihao Wang, Lin Gui, Swarnashree Mysore Sathyendra, Jaehwan Jeong, Victor Veitch, Wei Wang, Yunzhong He, Bing Liu, and Lifeng Jin. Chasing the tail: Effective rubric-based reward modeling for large language model post-training.arXiv preprint arXiv:2509.21500,
-
[22]
Qingfei Zhao, Ruobing Wang, Dingling Xu, Daren Zha, and Limin Liu. R-search: Empowering llm reasoning with search via multi-reward reinforcement learning.arXiv preprint arXiv:2506.04185,
-
[23]
the missing person’s birth date
12 Preprint A TRAININGALGORITHM Algorithm 1 details the full ARCO training loop, covering rollout, rubric generation and scoring, and the co-evolution updates ofπandµ. Algorithm 1ARCO: Adaptive Rubric Co-Evolution Require: Policy π (SFT-initialized), rubric model µ (SFT-initialized), training examples E, retriever R, max stepsT, dense transition epochη 1:...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.