Large language models reorganize representational geometry during in-context learning
Pith reviewed 2026-06-30 18:48 UTC · model grok-4.3
The pith
Large language models reorganize their internal representations during in-context learning to increase separability of task features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
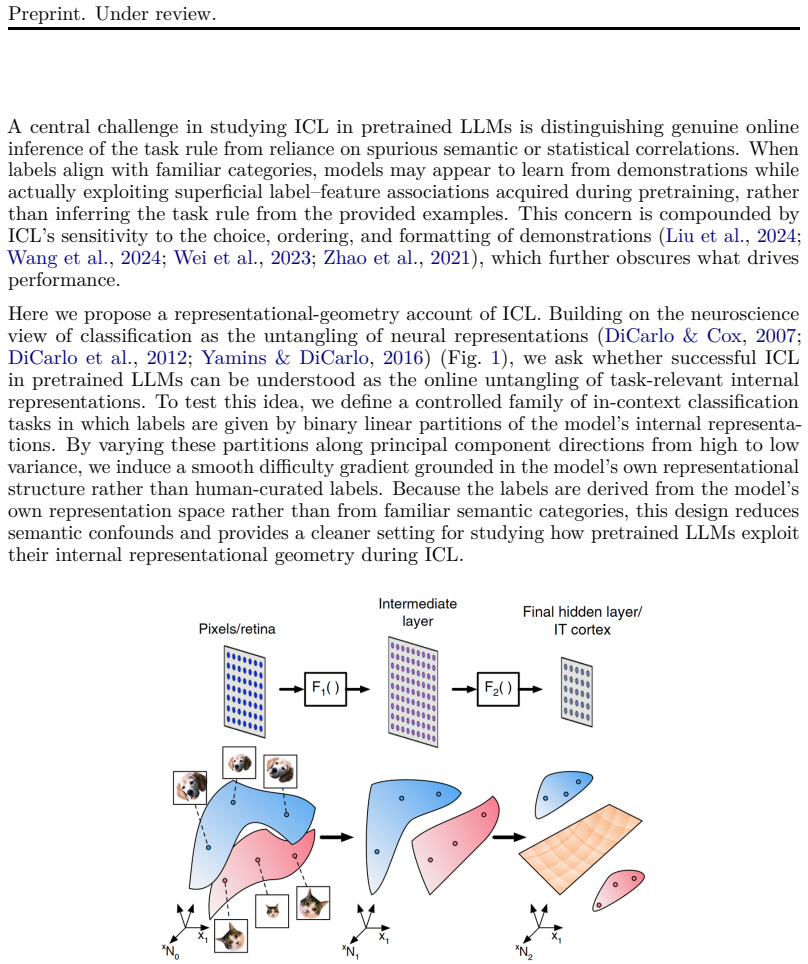
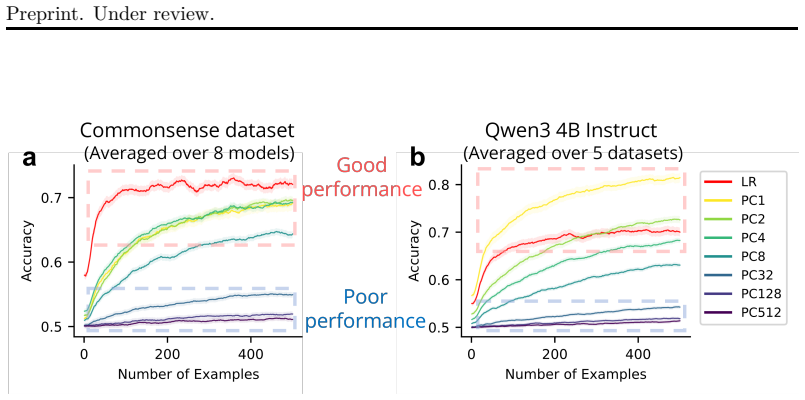
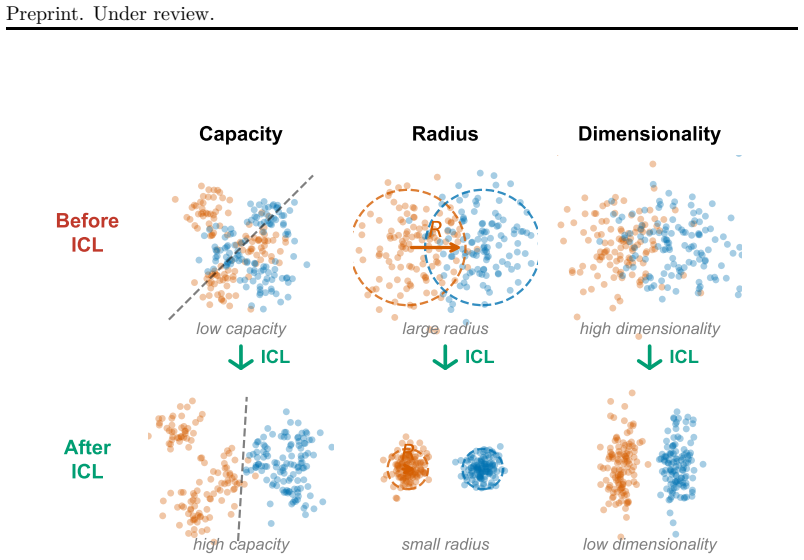
Successful in-context learning in LLMs is accompanied by geometric reorganization of representations that increases online separability, and this behavior is well described by a prototype-like algorithm that integrates evidence while reshaping representations to support classification. ICL performance correlates systematically with the representational structure of the underlying classification task.
What carries the argument
Geometric reorganization of representations that increases online separability, carried out by a prototype-like algorithm integrating evidence from examples.
If this is right
- ICL performance varies systematically with the structure of the classification task in the model's representations.
- Successful ICL produces geometric changes that increase online separability of task features.
- LLM in-context behavior matches a prototype-like algorithm that integrates evidence while reshaping representations.
- Representational geometry serves as a mechanistic constraint on what ICL can exploit from pretrained models.
Where Pith is reading between the lines
- Pretraining methods that produce more separable initial representations for common tasks could improve ICL across a wider range of examples.
- The same reorganization mechanism may limit or enable other forms of adaptation without weight updates in transformer models.
- Comparing reorganization patterns across model scales or architectures could test whether this geometric account generalizes beyond the studied LLMs.
Load-bearing premise
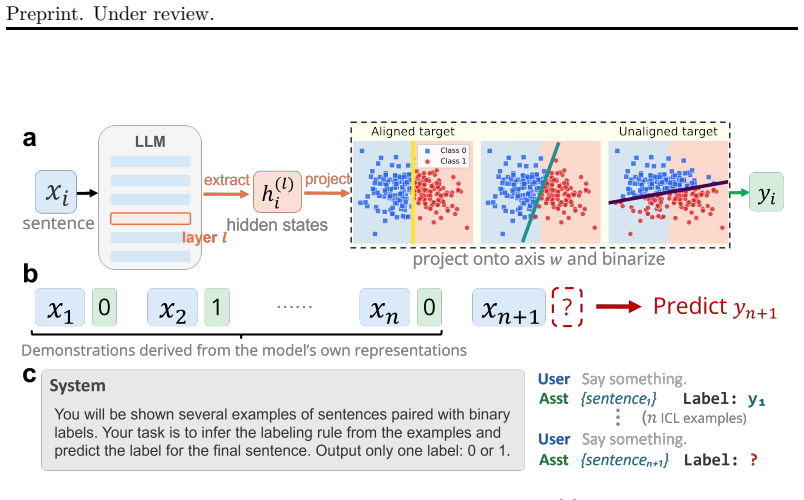
Defining classification labels from the model's own internal representations with known structure provides a valid test of whether ICL depends on successful online untangling of task-relevant representations.
What would settle it
Experiments showing no systematic correlation between ICL performance and the structure of the classification task in representations, or no increase in separability during successful ICL, would falsify the claim.
Figures
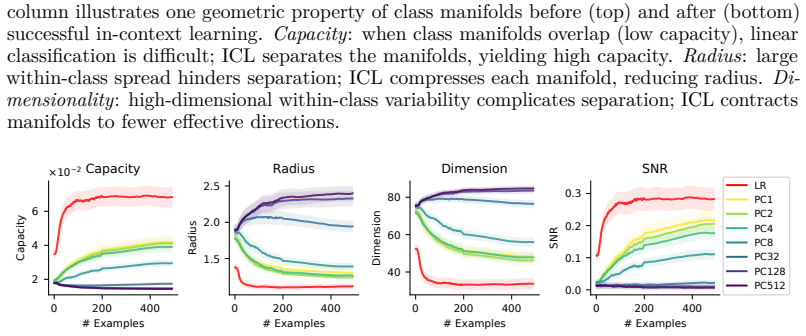
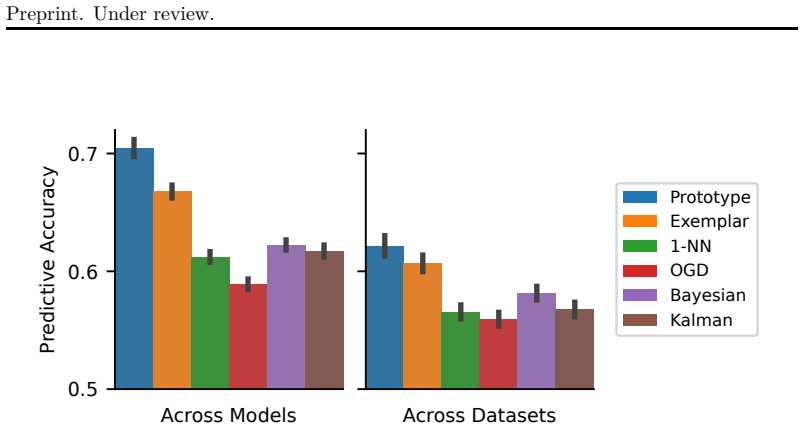
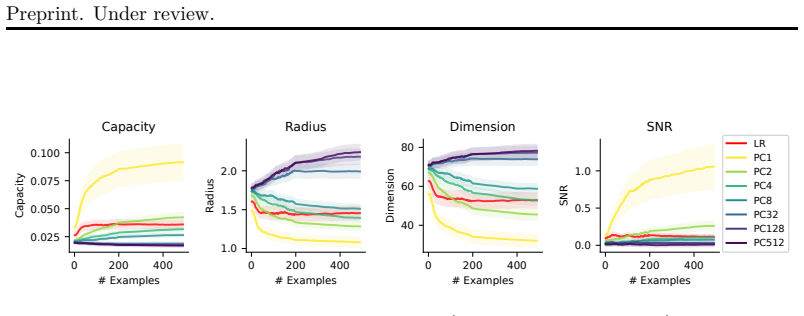
read the original abstract
Large language models (LLMs) exhibit remarkable flexibility: they can adapt to novel tasks from in-context examples without any parameter updates, a capability known as in-context learning (ICL). Prior work on synthetic tasks has shown that ICL can implement specific algorithms, demonstrating architectural competence, and mechanistic analyses have identified key circuits that support this behavior. However, because in-context computation -- regardless of its algorithmic form -- relies on transformations in high-dimensional representation space, it remains unclear how the geometry of that space shapes ICL effectiveness. Motivated by the neuroscience view of classification as the untangling of neural representations, we hypothesize that ICL depends on the successful online untangling of task-relevant representations. To test this idea, we study how LLMs classify in-context examples whose labels are defined by the model's own internal representations with known structure. We show that ICL performance correlates systematically with the representational structure of the underlying classification task and that successful ICL is accompanied by geometric reorganization that increases online separability. We further find that LLM behavior is well described by a prototype-like algorithm that integrates evidence while reshaping representations to support classification. These findings offer a geometric account of ICL in pretrained LLMs, establish representational geometry as a mechanistic constraint on ICL, and quantify the gap between what pretrained representations afford and what in-context learning can exploit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in-context learning (ICL) in large language models depends on the successful online untangling of task-relevant representations. By defining classification labels directly from the model's own internal representations (with known structure), the authors report that ICL performance correlates systematically with the representational structure of the task, that successful ICL is accompanied by geometric reorganization increasing online separability, and that LLM behavior is well described by a prototype-like algorithm integrating evidence while reshaping representations to support classification. These results are presented as establishing representational geometry as a mechanistic constraint on ICL.
Significance. If the central claims hold after addressing methodological concerns, the work provides a geometric account of ICL that bridges neuroscience-inspired views of representation untangling with empirical LLM behavior. The identification of a prototype-like algorithm is a concrete strength, offering a falsifiable description of the mechanism. The use of model-derived tasks is a direct way to probe internal geometry, though its validity for testing the untangling hypothesis requires additional validation. This could inform mechanistic interpretability research if the correlation and reorganization findings are shown to be independent of task-selection artifacts.
major comments (1)
- [Task construction procedure (abstract and methods)] Task construction procedure (abstract and methods): defining classification labels from the LLM's pre-existing internal representations with known structure selects for tasks where some geometry is already detectable. This risks making the reported correlation between representational structure and ICL performance, as well as the reorganization that increases separability, an artifact of pre-alignment rather than evidence that ICL requires successful online untangling. The manuscript should include controls with labels defined independently of the same representations (e.g., random or external labels) to test whether ICL fails specifically when initial separability is low, independent of the selection procedure.
minor comments (2)
- Clarify the exact metrics used to quantify 'representational structure' and 'online separability' (e.g., which distance or clustering measures) and report effect sizes or statistical tests for the claimed systematic correlations.
- The description of the prototype-like algorithm would benefit from an explicit comparison to alternative models (e.g., linear classifiers) to substantiate that it 'well describes' the behavior.
Simulated Author's Rebuttal
We thank the referee for highlighting this important methodological consideration regarding task construction. We agree that additional controls are warranted to rule out selection artifacts and will incorporate them in the revision. Below we respond to the major comment.
read point-by-point responses
-
Referee: Task construction procedure (abstract and methods): defining classification labels from the LLM's pre-existing internal representations with known structure selects for tasks where some geometry is already detectable. This risks making the reported correlation between representational structure and ICL performance, as well as the reorganization that increases separability, an artifact of pre-alignment rather than evidence that ICL requires successful online untangling. The manuscript should include controls with labels defined independently of the same representations (e.g., random or external labels) to test whether ICL fails specifically when initial separability is low, independent of the selection procedure.
Authors: We agree that the task-construction procedure merits additional controls to strengthen the claim that ICL depends on online untangling rather than pre-existing alignment. Our design intentionally uses model-derived labels to probe the geometry that the model itself has learned, allowing a direct test of whether ICL performance tracks the structure already present in the representations. The observed reorganization during ICL and the match to a prototype-like algorithm provide evidence that the model is actively reshaping representations rather than merely exploiting static structure. Nevertheless, to address the referee's concern directly, we will add two sets of control experiments in the revised manuscript: (1) tasks with randomly assigned labels (zero initial separability) and (2) tasks whose labels are defined by an external, non-representational criterion. These controls will test whether ICL performance collapses when initial separability is low, independent of the selection procedure used in the main experiments. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's abstract and described methods present an empirical study correlating ICL performance with representational structure on tasks whose labels are drawn from the model's own internal representations. No equations, fitted parameters renamed as predictions, or self-citation chains are provided that reduce any claimed result to its inputs by construction. The methodological choice to define labels from internal representations is a design decision for testing the untangling hypothesis rather than a self-definitional loop or load-bearing reduction in the derivation. The findings remain externally falsifiable via the reported correlations and geometric measures.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
In-context Learning and Induction Heads
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/p17-2067 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.