Evolutionary Dynamics of Cooperation in Next-Generation LLM Agent Systems: A Cross-Provider Empirical Extension
Pith reviewed 2026-06-29 00:09 UTC · model grok-4.3
The pith
Provider identity, not model generation, best predicts equilibrium cooperation in next-generation LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
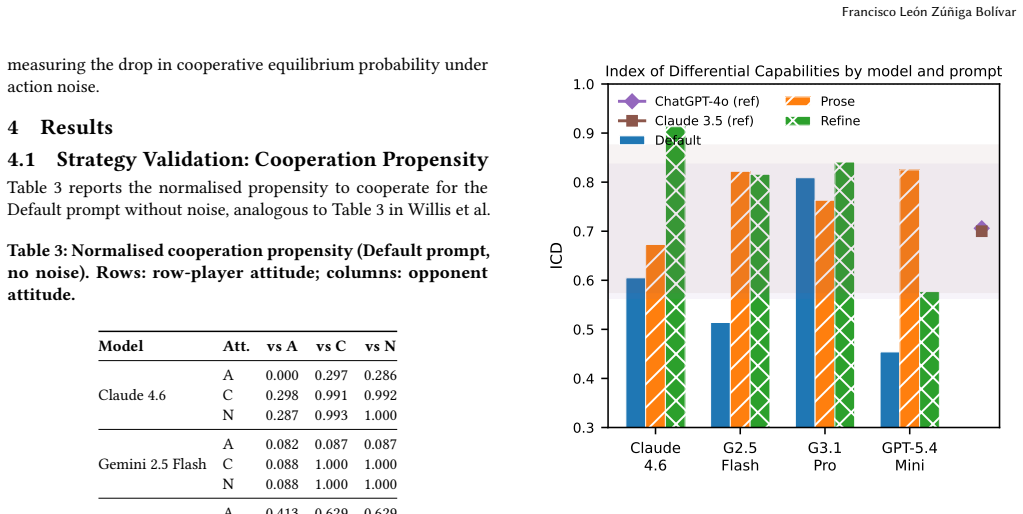
Next-generation LLM agents maintain cooperative biases in balanced conditions across providers, yet substantial divergence appears under biased populations, with Gemini models favoring aggression and GPT models favoring cooperation; self-refine prompting elevates cooperation indices in all cases, while noise sensitivity shows no statistically significant improvement over prior generations after error propagation.
What carries the argument
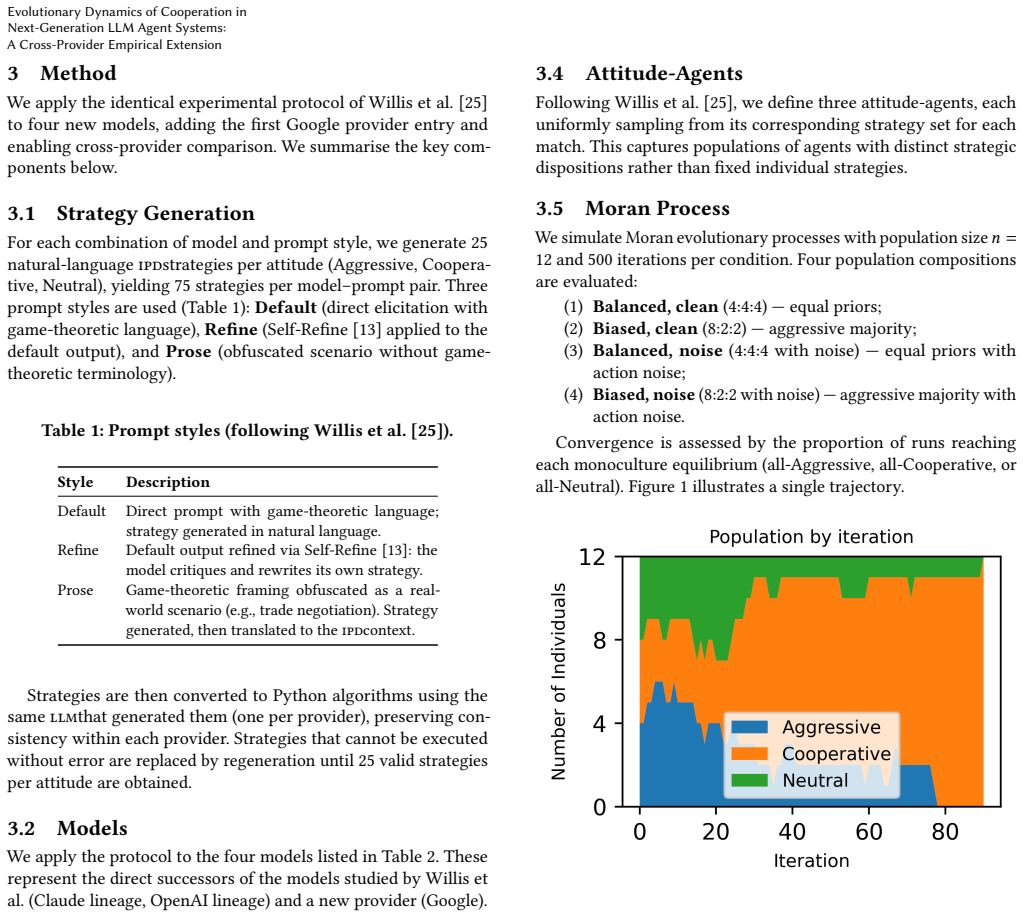
The Moran process evolutionary simulation with 500 iterations per condition, applied across prompting styles (Default, Prose, Self-Refine) and population compositions in the Iterated Prisoner's Dilemma.
If this is right
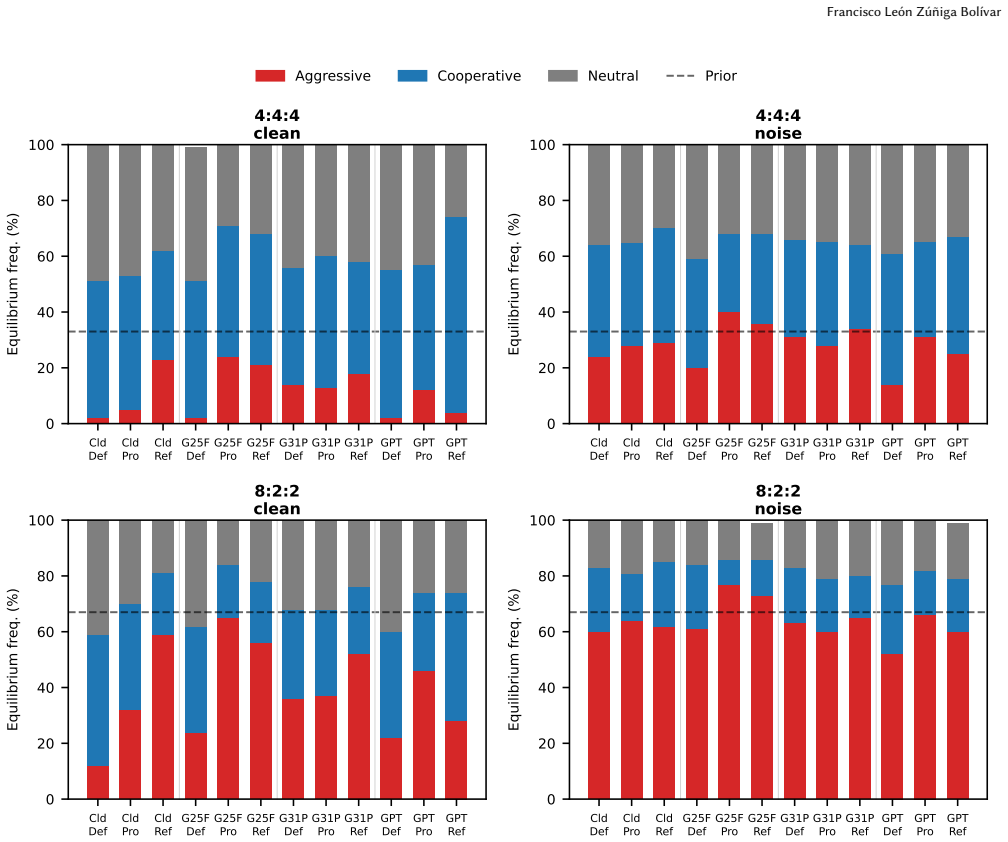
- Cooperative equilibria are favored in nine of twelve model-prompt combinations under balanced noiseless conditions.
- Self-Refine prompting increases the Index of Cooperative Deviation in all tested models.
- Cross-provider differences reach up to 77% aggressive equilibria for Gemini 2.5 Flash in biased conditions.
- Noise sensitivity remains a challenge with no confirmed reduction in newer models.
Where Pith is reading between the lines
- If provider effects dominate, then mixed-provider agent swarms may exhibit unpredictable cooperation levels.
- Developers could select models from specific providers to encourage desired equilibrium behaviors in agent systems.
- Testing additional prompting methods or larger population sizes could clarify the noise robustness question.
Load-bearing premise
That the unreported sampling details from the earlier study allow accurate propagation of error to conclude the noise sensitivity gap is not statistically significant.
What would settle it
A re-analysis or new experiment with full sampling details from the predecessor study showing a statistically significant reduction in noise sensitivity for the 2025-2026 models.
Figures
read the original abstract
Do next-generation LLM agents inherit the cooperative biases documented in their predecessors, or does scale and provider diversity reshape equilibrium behaviour in competitive multi-agent settings? Willis et al. established a benchmark for this question using evolutionary game theory and the Iterated Prisoner's Dilemma (IPD), finding consistent cooperative biases in ChatGPT-4o and Claude 3.5 Sonnet. We extend this benchmark to four frontier models released in 2025-2026 - Claude Sonnet 4.6, Gemini 2.5 Flash, Gemini 3.1 Pro, and GPT-5.4 Mini - applying the identical protocol across three prompting styles (Default, Prose, Self-Refine) and four population compositions (balanced and biased, with and without noise). Cooperative bias persists across providers (H1): nine of twelve model-prompt combinations favour cooperative equilibria in balanced noiseless conditions. Cross-provider divergence is substantial (H3): Gemini 2.5 Flash reaches up to 77% aggressive equilibria under biased conditions, while GPT-5.4 Mini reaches 70% cooperative equilibria under Self-Refine. Support for aggressive capability parity is partial (H2): Self-Refine raises ICD in all models and Claude Sonnet 4.6 Refine achieves the highest ICD in the dataset (0.913), but Default and Prose prompts show no systematic narrowing. Evidence on noise robustness is directionally positive but not robustly confirmed (H4): with n=500 Moran iterations per condition, average noise sensitivity is approximately 6 percentage points for Claude Sonnet 4.6 versus 13 pp for Claude 3.5 Sonnet, but this cross-study gap is not statistically significant once the predecessor's unreported sampling error is propagated. Provider identity, rather than model generation, is the strongest correlate of equilibrium outcomes; noise remains a universal challenge regardless of model size or vintage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends Willis et al.'s evolutionary game theory benchmark on LLM agents in the Iterated Prisoner's Dilemma to four 2025-2026 frontier models (Claude Sonnet 4.6, Gemini 2.5 Flash, Gemini 3.1 Pro, GPT-5.4 Mini) under Default/Prose/Self-Refine prompts and balanced/biased/noise conditions. It reports persistent cooperative bias in nine of twelve model-prompt combinations (H1), partial support for capability parity via Self-Refine (H2), substantial cross-provider divergence (H3), and non-significant noise-sensitivity differences after error propagation (H4), concluding that provider identity rather than model generation is the dominant correlate and that noise remains a universal challenge.
Significance. If the empirical patterns hold under verifiable statistics, the work supplies a timely cross-provider extension that isolates provider effects from generational scaling in multi-agent cooperation, with direct relevance to robust LLM agent design. The reuse of the prior protocol and n=500 Moran iterations per condition enable direct comparability.
major comments (3)
- [Abstract (H4)] Abstract (H4 paragraph): the claim that the observed 6 pp vs 13 pp noise-sensitivity gap is not statistically significant rests on propagating unreported sampling variance, run count, and error structure from Willis et al.; because those details are unavailable, the non-significance result cannot be independently verified and directly weakens support for the 'universal noise' conclusion that underpins the provider-over-generation ranking.
- [Results (H3)] Results section on H3 and provider comparisons: the assertion that 'provider identity, rather than model generation, is the strongest correlate' is presented without reported statistical tests, effect-size comparisons, or variance decomposition that would quantify the relative explanatory power of provider vs. vintage; the tabulated equilibrium percentages alone do not establish dominance.
- [Methods] Methods (sampling and error propagation): the manuscript states n=500 iterations per condition but provides no explicit error-propagation formula, assumed distribution for the predecessor study, or sensitivity analysis showing how alternative variance assumptions would affect the H4 p-value; this omission renders the cross-study non-significance claim non-reproducible from the given text.
minor comments (2)
- [Abstract] Abstract: the phrase 'nine of twelve model-prompt combinations' is stated without enumerating which combinations meet the cooperative criterion, reducing immediate interpretability.
- Figure or table captions (equilibrium percentages): axis labels and legend entries for the four population compositions should explicitly repeat the prompt-style abbreviations used in the text to avoid cross-referencing.
Simulated Author's Rebuttal
We thank the referee for these constructive comments. We agree that greater statistical transparency and reproducibility are required, particularly for cross-study claims and the provider-generation comparison. We will revise the manuscript to address each point.
read point-by-point responses
-
Referee: [Abstract (H4)] Abstract (H4 paragraph): the claim that the observed 6 pp vs 13 pp noise-sensitivity gap is not statistically significant rests on propagating unreported sampling variance, run count, and error structure from Willis et al.; because those details are unavailable, the non-significance result cannot be independently verified and directly weakens support for the 'universal noise' conclusion that underpins the provider-over-generation ranking.
Authors: We accept this point. The non-significance assessment depends on unreported details from Willis et al., preventing independent verification. We will revise the abstract to remove the statistical claim, stating only that the gap is directionally smaller while noting that significance cannot be confirmed from available data, and will accordingly qualify the 'universal noise' conclusion. revision: yes
-
Referee: [Results (H3)] Results section on H3 and provider comparisons: the assertion that 'provider identity, rather than model generation, is the strongest correlate' is presented without reported statistical tests, effect-size comparisons, or variance decomposition that would quantify the relative explanatory power of provider vs. vintage; the tabulated equilibrium percentages alone do not establish dominance.
Authors: The referee is correct that the claim rests on descriptive percentages without formal tests or decomposition. We will add statistical comparisons (e.g., regression or ANOVA with provider and generation as predictors) and effect-size metrics in the revised results section to quantify relative explanatory power. revision: yes
-
Referee: [Methods] Methods (sampling and error propagation): the manuscript states n=500 iterations per condition but provides no explicit error-propagation formula, assumed distribution for the predecessor study, or sensitivity analysis showing how alternative variance assumptions would affect the H4 p-value; this omission renders the cross-study non-significance claim non-reproducible from the given text.
Authors: We agree the methods section is insufficiently detailed. We will add the explicit propagation formula, the assumed distribution from the predecessor, and a sensitivity analysis under alternative variance assumptions. revision: yes
Circularity Check
No significant circularity; purely empirical extension
full rationale
The paper conducts fresh Moran-process simulations on four new 2025-2026 models under the Willis et al. protocol. All equilibrium percentages, ICD values, and hypothesis outcomes (H1-H4) are direct counts from the n=500 iterations per condition. No equations, fitted parameters, or self-citations reduce any reported result to a quantity defined inside the paper. The H4 error-propagation step references external unreported variance but does not alter or tautologically force the new measurements themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Iterated Prisoner's Dilemma payoff structure and Moran process update rules are identical to those used in Willis et al.
Reference graph
Works this paper leans on
-
[1]
Gati Aher, Rosa I. Arriaga, and Adam Tauman Kalai. 2023. Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies. arXiv:2208.10264 [cs.CL]
-
[2]
Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. 2025. Playing repeated games with large language models. Nature Human Behaviour9 (2025), 1380–1390. doi:10.1038/s41562-025-02172-y Published version of arXiv:2305.16867
-
[3]
1984.The Evolution of Cooperation
Robert Axelrod. 1984.The Evolution of Cooperation. Basic Books, New York
1984
-
[4]
Hamilton
Robert Axelrod and William D. Hamilton. 1981. The Evolution of Cooperation. Science211, 4489 (1981), 1390–1396
1981
- [5]
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code. arXiv:2107.03374 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
De Zarzà, J
I. De Zarzà, J. De Curtò, Gemma Roig, Pietro Manzoni, and Carlos T. Calafate
-
[8]
Emergent Cooperation and Strategy Adaptation in Multi-Agent Systems: An Extended Coevolutionary Theory with LLMs.Electronics12, 12 (2023), 2722
2023
-
[9]
Caoyun Fan, Jindou Chen, Yaohui Jin, and Hao He. 2024. Can Large Language Models Serve as Rational Players in Game Theory: A Systematic Analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 17960–17967
2024
- [10]
-
[11]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Understanding.International Conference on Learning Representations(2021). arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Vincent Knight, Owen Campbell, Marc Harper, Karol Langner, James Campbell, Thomas Campbell, Alex Carney, Martin Chorley, Cameron Davidson-Pilon, Kris- tian Glass, et al. 2016. An Open Framework for the Reproducible Study of the Iterated Prisoner’s Dilemma.Journal of Open Research Software4, 1 (2016), e35
2016
-
[13]
Leibo, Vinicius Zambaldi, Marc Lanctot, Janusz Marecki, and Thore Grae- pel
Joel Z. Leibo, Vinicius Zambaldi, Marc Lanctot, Janusz Marecki, and Thore Grae- pel. 2017. Multi-Agent Reinforcement Learning in Sequential Social Dilemmas. InProceedings of the 16th International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS). 464–473
2017
-
[14]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al
-
[15]
InAdvances in Neural Information Processing Systems (NeurIPS), Vol
Self-Refine: Iterative Refinement with Self-Feedback. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36
-
[16]
Patrick A. P. Moran. 1958. Random Processes in Genetics.Mathematical Proceed- ings of the Cambridge Philosophical Society54, 1 (1958), 60–71
1958
-
[17]
Martin A. Nowak. 2006.Evolutionary Dynamics: Exploring the Equations of Life. Harvard University Press, Cambridge, MA
2006
-
[18]
Nowak, Akira Sasaki, Christine Taylor, and Drew Fudenberg
Martin A. Nowak, Akira Sasaki, Christine Taylor, and Drew Fudenberg. 2004. Emergence of cooperation and evolutionary stability in finite populations.Nature 428, 6983 (2004), 646–650. doi:10.1038/nature02414
-
[19]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. arXiv:2304.03442 [cs.HC]
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [20]
-
[21]
Giorgio Piatti, Zhijing Jin, Max Kleiman-Weiner, Bernhard Schölkopf, Mrinmaya Sachan, and Rada Mihalcea. 2024. Cooperate or Collapse: Emergence of Sustain- able Cooperation in a Society of LLM Agents. InAdvances in Neural Information Processing Systems (NeurIPS 2024). arXiv:2404.16698 [cs.AI]
- [22]
-
[23]
Stochastic dynamics of invasion and fixation
Arne Traulsen, Martin A. Nowak, and Jorge M. Pacheco. 2006. Stochas- tic dynamics of invasion and fixation.Physical Review E74 (2006), 011909. doi:10.1103/PhysRevE.74.011909
- [24]
-
[25]
Wahl and Martin A
Lindi M. Wahl and Martin A. Nowak. 1999. The Continuous Prisoner’s Dilemma: II. Linear Reactive Strategies with Noise.Journal of Theoretical Biology200, 3 (1999), 323–338
1999
-
[26]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents.Frontiers of Computer Science18, 6 (2024), 186345
2024
-
[27]
George Willis, Yali Du, Joel Z. Leibo, and Michael Luck. 2025. Do LLM Agents Cooperate or Defect? Evolutionary Dynamics in Multi-Agent Systems. arXiv:2501.16173 [cs.GT]
- [28]
-
[29]
Jianzhong Wu and Robert Axelrod. 1995. How to Cope with Noise in the Iterated Prisoner’s Dilemma.Journal of Conflict Resolution39, 1 (1995), 183–189
1995
-
[30]
Julian Yocum, Phillip Christoffersen, Mehul Damani, Justin Svegliato, Dylan Hadfield-Menell, and Stuart Russell. 2023. Mitigating Generative Agent Social Dilemmas. InFoundation Models for Decision Making Workshop, NeurIPS
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.