REVIEW 3 major objections 2 minor 1 cited by
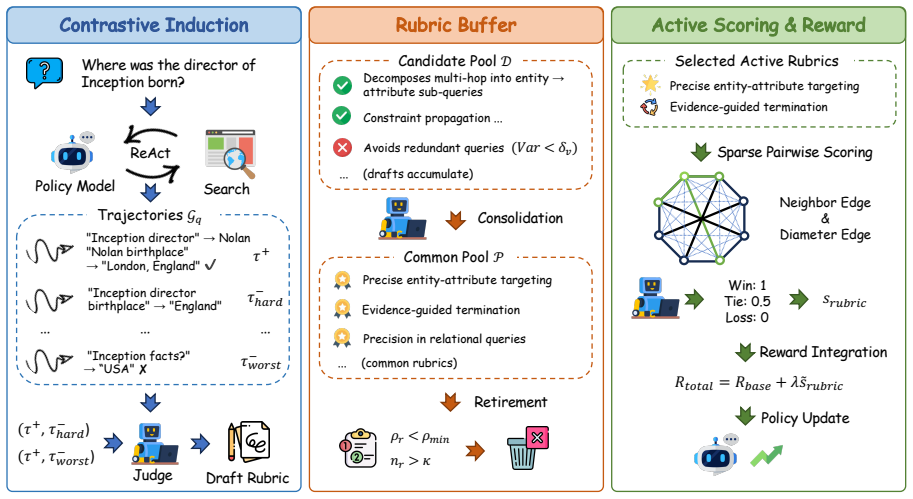
A shared rubric buffer consolidates contrastive drafts into reusable criteria that supply process rewards to search agents when outcome signals are uniform.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-06-28 10:34 UTC pith:ZYL2MQ34
load-bearing objection ARBOR's shared rubric buffer is a sensible attempt at reusable process rewards, but consolidation reliability and experimental details need checking. the 3 major comments →
ARBOR: Online Process Rewards via a Reusable Rubric Buffer for Search Agents
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARBOR maintains a rubric memory shared across queries. Query-local drafts induced from contrastive trajectories are admitted, consolidated into cross-query common rubrics, and retired as the policy evolves. A small active subset of common rubrics scores trajectories via sparse pairwise judging, and the resulting scores are added to the base reward, providing process-level gradient even when outcome reward is uniform.
What carries the argument
The Adaptive Rubric Buffer that admits query-local drafts, consolidates them into reusable cross-query rubrics, and applies sparse pairwise judging to augment outcome rewards.
Load-bearing premise
Query-local drafts induced from contrastive trajectories can be reliably consolidated into stable cross-query common rubrics that remain useful and unbiased as the policy evolves without the consolidation step introducing inconsistencies.
What would settle it
Training on the four multi-hop QA benchmarks and observing neither accuracy gains nor conversion of zero-gradient groups into informative ones would falsify the utility of the consolidated rubrics.
If this is right
- Outperforms GRPO and DAPO baselines on four multi-hop QA benchmarks.
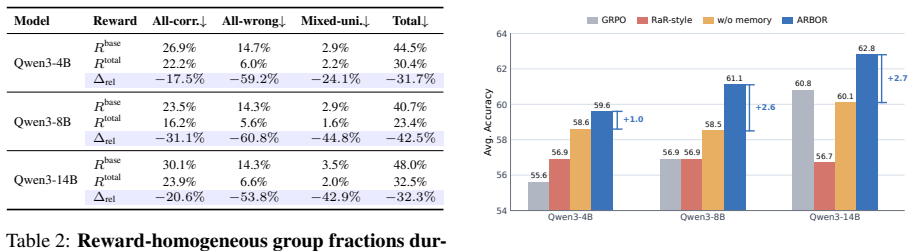
- Raises average LLM-judge accuracy by up to 4.2 points.
- Converts up to 42 percent of otherwise-zero-gradient training groups into informative ones.
- Supplies process-level gradient on groups where every sampled trajectory shares the same outcome correctness.
Where Pith is reading between the lines
- The buffer approach might reduce reliance on dense outcome supervision in long-horizon agent tasks.
- Periodic retirement of rubrics could be extended to test whether older criteria begin to bias newer policy versions.
- If consolidation remains unbiased, the same memory could be shared across multiple agent domains rather than kept task-specific.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ARBOR, a framework for online process rewards in LLM-based search agents using a reusable rubric buffer. It admits query-local drafts from contrastive trajectories, consolidates them into cross-query common rubrics, and uses sparse pairwise judging to add process scores to the outcome reward. This addresses zero-gradient issues in outcome-homogeneous groups. The method is evaluated on four multi-hop QA benchmarks, claiming consistent outperformance over GRPO and DAPO baselines with up to 4.2 points improvement in average LLM-judge accuracy and converting up to 42% of zero-gradient training groups into informative ones.
Significance. If the results hold, ARBOR provides a practical mechanism for process-level supervision in search agent training without per-query rubric inconsistency or expensive learned verifiers. The reusable buffer approach directly targets the zero-gradient problem in outcome-homogeneous groups, and the reported gains on multi-hop QA tasks indicate potential for broader applicability in RL for agents.
major comments (3)
- [§3.3] §3.3: The consolidation step that merges query-local drafts into stable cross-query common rubrics is presented at a high level with no explicit mechanism or invariant for detecting/resolving contradictions, query-specific artifacts, or drift; this is load-bearing for the claim that the added pairwise scores remain unbiased as the policy evolves.
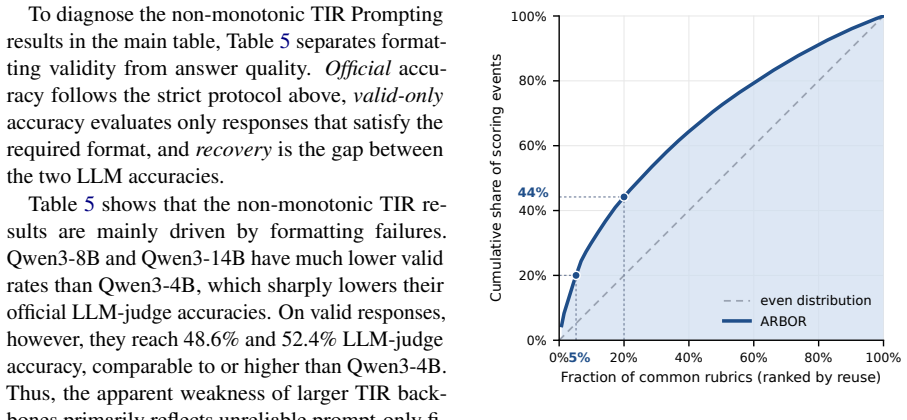
- [§4.2, Table 2] §4.2, Table 2: The 42% conversion rate of zero-gradient groups and the 4.2-point accuracy lift are reported without details on baseline re-implementations, random seeds, statistical tests, or how zero-gradient groups were identified and measured, making it impossible to assess whether the gains are robust or affected by post-hoc choices.
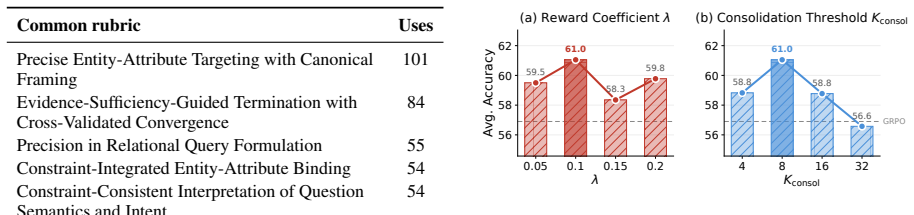
- [§4.4] §4.4: No ablation isolates the effect of rubric retirement or consolidation frequency on process-reward quality, which is required to substantiate that the buffer remains useful without introducing inconsistencies over training.
minor comments (2)
- [Abstract] Abstract: The phrase 'up to 4.2 points' should specify the per-benchmark breakdown and whether it is an average or maximum across the four tasks.
- [§2.1] §2.1: Notation for the active rubric subset and pairwise judging could be clarified with a small diagram or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, committing to revisions where the manuscript requires clarification or additional evidence.
read point-by-point responses
-
Referee: [§3.3] §3.3: The consolidation step that merges query-local drafts into stable cross-query common rubrics is presented at a high level with no explicit mechanism or invariant for detecting/resolving contradictions, query-specific artifacts, or drift; this is load-bearing for the claim that the added pairwise scores remain unbiased as the policy evolves.
Authors: We agree the consolidation procedure is described at too high a level. In the revised manuscript we will expand §3.3 with an explicit algorithm: drafts are embedded and clustered by cosine similarity; contradictions are flagged when intra-cluster variance exceeds a threshold and resolved by retaining the majority-vote rubric; drift is monitored via a stability invariant (average pairwise agreement across consecutive consolidation rounds must remain above 0.85). Pseudocode and a short bias analysis will be added to show that the resulting pairwise scores stay unbiased under these rules. revision: yes
-
Referee: [§4.2, Table 2] §4.2, Table 2: The 42% conversion rate of zero-gradient groups and the 4.2-point accuracy lift are reported without details on baseline re-implementations, random seeds, statistical tests, or how zero-gradient groups were identified and measured, making it impossible to assess whether the gains are robust or affected by post-hoc choices.
Authors: We acknowledge the missing experimental details. The revision will augment §4.2 with: (i) exact re-implementation notes for GRPO and DAPO matching the original papers, (ii) results averaged over 5 random seeds with standard deviations, (iii) paired t-test p-values for the accuracy lifts, and (iv) the precise zero-gradient criterion (a group is zero-gradient if every trajectory receives the identical outcome reward). These additions will appear in the main text and appendix. revision: yes
-
Referee: [§4.4] §4.4: No ablation isolates the effect of rubric retirement or consolidation frequency on process-reward quality, which is required to substantiate that the buffer remains useful without introducing inconsistencies over training.
Authors: We agree an ablation on retirement threshold and consolidation frequency is needed. We will add a new paragraph and figure in §4.4 reporting results from additional runs that vary the retirement age (every 200 vs. 500 steps) and consolidation interval (every 50 vs. 100 queries), confirming that process-reward quality and final accuracy remain stable within the chosen operating range. revision: yes
Circularity Check
No circularity: method relies on independent contrastive trajectories and pairwise judging with no self-referential derivations
full rationale
The paper describes an empirical framework (ARBOR) using contrastive trajectories to induce rubrics, consolidation into a shared buffer, and sparse pairwise scoring added to outcome reward. No equations, derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text. The central claims are benchmark improvements (up to 4.2 points, 42% zero-gradient conversion) presented as experimental outcomes, not reductions to inputs by construction. The consolidation step is an algorithmic choice whose validity is tested externally via benchmarks rather than defined circularly. This is the common honest non-finding for method papers without mathematical self-reference.
Axiom & Free-Parameter Ledger
read the original abstract
LLM-based search agents are trained predominantly with outcome-only reward, leaving the search process itself unsupervised. This signal degenerates on outcome-homogeneous groups where all sampled trajectories share the same correctness, yielding zero within-group advantage and no gradient. Existing process supervision either trains a costly verifier or generates per-query rubrics that are inconsistent across queries and discarded after one use. We propose ARBOR (Adaptive Rubric Buffer for Online Reward), a reusable process-reward framework that maintains a rubric memory shared across queries. Query-local drafts induced from contrastive trajectories are admitted, consolidated into cross-query common rubrics, and retired as the policy evolves. A small active subset of common rubrics scores trajectories via sparse pairwise judging, and the resulting scores are added to the base reward, providing process-level gradient even when outcome reward is uniform. ARBOR consistently outperforms GRPO and DAPO baselines on four multi-hop QA benchmarks, raising average LLM-judge accuracy by up to 4.2 points and converting up to 42% of otherwise-zero-gradient training groups into informative ones.
Figures

Forward citations
Cited by 1 Pith paper
-
SERPO: Self-Evolving Rubric Policy Optimization for Open-Ended Test-Time Reinforcement Learning
SERPO co-evolves G-N-B response archives, query-specific rubrics, and actor parameters to raise open-ended TTRL scores by up to ~20 points without external judges or labels.
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
AdaRubric: Task-Adaptive Rubrics for Reliable LLM Agent Evaluation and Reward Learning , author=. 2026 , eprint=
2026
-
[2]
A survey of llm-based deep search agents:
Xi, Yunjia and Lin, Jianghao and Xiao, Yongzhao and Zhou, Zheli and Shan, Rong and Gao, Te and Zhu, Jiachen and Liu, Weiwen and Yu, Yong and Zhang, Weinan , journal=. A survey of llm-based deep search agents:
-
[3]
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D , booktitle=. Hotpot. 2018 , url=
2018
-
[4]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=. 2020 , url=
2020
-
[5]
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal=. Mu. 2022 , url=
2022
-
[6]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Measuring and narrowing the compositionality gap in language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=. 2023 , url=
2023
-
[7]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle=. G-eval:. 2023 , url=
2023
-
[8]
2023 , url=
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle=. 2023 , url=
2023
-
[9]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=. 2023 , url=
2023
-
[10]
2025 , url=
Peng, Xianshu and Wei, Wei , booktitle=. 2025 , url=
2025
-
[11]
Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models , url =
Kim, Seungone and Shin, Jay and cho, yejin and Jang, Joel and Longpre, Shayne and Lee, Hwaran and Yun, Sangdoo and Shin, Ryan, S and Kim, Sungdong and Thorne, James and Seo, Minjoon , booktitle =. Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models , url =
-
[12]
Llm-rubric:
Hashemi, Helia and Eisner, Jason and Rosset, Corby and Van Durme, Benjamin and Kedzie, Chris , booktitle=. Llm-rubric:. 2024 , url=
2024
-
[13]
W eb W alker: Benchmarking LLM s in Web Traversal
Wu, Jialong and Yin, Wenbiao and Jiang, Yong and Wang, Zhenglin and Xi, Zekun and Fang, Runnan and Zhang, Linhai and He, Yulan and Zhou, Deyu and Xie, Pengjun and Huang, Fei. W eb W alker: Benchmarking LLM s in Web Traversal. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653...
-
[14]
Search-o1:
Li, Xiaoxi and Dong, Guanting and Jin, Jiajie and Zhang, Yuyao and Zhou, Yujia and Zhu, Yutao and Zhang, Peitian and Dou, Zhicheng , booktitle=. Search-o1:. 2025 , url=
2025
-
[15]
WebAgent-r1: Training web agents via end-to-end multi-turn reinforcement learning
Wei, Zhepei and Yao, Wenlin and Liu, Yao and Zhang, Weizhi and Lu, Qin and Qiu, Liang and Yu, Changlong and Xu, Puyang and Zhang, Chao and Yin, Bing and Yun, Hyokun and Li, Lihong. W eb A gent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 20...
-
[16]
s3: You Don ' t Need That Much Data to Train a Search Agent via RL
Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei. s3: You Don ' t Need That Much Data to Train a Search Agent via RL. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1095
-
[17]
Guanting Dong and Hangyu Mao and Kai Ma and Licheng Bao and Yifei Chen and Zhongyuan Wang and Zhongxia Chen and Jiazhen Du and Huiyang Wang and Fuzheng Zhang and Guorui Zhou and Yutao Zhu and Ji-Rong Wen and Zhicheng Dou , booktitle=. Agentic. 2026 , url=
2026
-
[18]
Wen, Tongyu and Dong, Guanting and Dou, Zhicheng , journal=. Smart. 2026 , url=
2026
-
[19]
2026 , eprint=
Supervising the search process produces reliable and generalizable information-seeking agents , author=. 2026 , eprint=
2026
-
[20]
Bowen Jin and Hansi Zeng and Zhenrui Yue and Jinsung Yoon and Sercan O Arik and Dong Wang and Hamed Zamani and Jiawei Han , booktitle=. Search-. 2025 , url=
2025
-
[21]
R1-searcher:
Song, Huatong and Jiang, Jinhao and Min, Yingqian and Chen, Jie and Chen, Zhipeng and Zhao, Wayne Xin and Fang, Lei and Wen, Ji-Rong , journal=. R1-searcher:. 2025 , url=
2025
-
[22]
Zheng, Xuhui and An, Kang and Wang, Ziliang and Wang, Yuhang and Wu, Yichao. S tep S earch: Igniting LLM s Search Ability via Step-Wise Proximal Policy Optimization. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1106
-
[23]
Xia, Tianle and Xu, Ming and Hu, Lingxiang and Sun, Yiding and Li, Wenwei and Shang, Linfang and Liu, Liqun and Shu, Peng and Yu, Huan and Jiang, Jie , journal=. Search-. 2026 , url=
2026
-
[24]
Zhong, Wenlin and Yang, Jinluan and Wu, Yiquan and Liu, Yi and Yao, Jianhang and Kuang, Kun , journal=. SIGHT:. 2026 , url=
2026
-
[25]
Infoflow:
Luo, Kun and Qian, Hongjin and Liu, Zheng and Xia, Ziyi and Xiao, Shitao and Bao, Siqi and Zhao, Jun and Liu, Kang , journal=. Infoflow:. 2025 , url=
2025
-
[26]
2026 , url=
Yutao Xie and Nathaniel Thomas and Nicklas Hansen and Yang Fu and Li Erran Li and Xiaolong Wang , booktitle=. 2026 , url=
2026
-
[27]
L e TS : Learning to Think-and-Search via Process-and-Outcome Reward Hybridization
Zhang, Qi and Yang, Shouqing and Gao, Lirong and Chen, Hao and Hu, Xiaomeng and Chen, Jinglei and Wang, Jiexiang and Guo, Sheng and Zheng, Bo and Wang, Haobo and Zhao, Junbo. L e TS : Learning to Think-and-Search via Process-and-Outcome Reward Hybridization. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:...
-
[28]
arXiv preprint arXiv:2509.25598 , year=
Hybrid reward normalization for process-supervised non-verifiable agentic tasks , author=. arXiv preprint arXiv:2509.25598 , year=
-
[29]
Process vs
Zhang, Wenlin and Li, Xiangyang and Dong, Kuicai and Wang, Yichao and Jia, Pengyue and Li, Xiaopeng and Zhang, Yingyi and Xu, Derong and Du, Zhaocheng and Guo, Huifeng and Tang, Ruiming and Zhao, Xiangyu , booktitle =. Process vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning , url =
-
[30]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=. 2024 , url=
2024
-
[31]
Math-shepherd:
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang , booktitle=. Math-shepherd:. 2024 , url=
2024
-
[32]
2024 , eprint=
Improve Mathematical Reasoning in Language Models by Automated Process Supervision , author=. 2024 , eprint=
2024
-
[33]
2025 , eprint=
Process Reinforcement through Implicit Rewards , author=. 2025 , eprint=
2025
-
[34]
Hendryx , booktitle=
Anisha Gunjal and Anthony Wang and Elaine Lau and Vaskar Nath and Yunzhong He and Bing Liu and Sean M. Hendryx , booktitle=. Rubrics as. 2026 , url=
2026
-
[35]
2025 , eprint=
InfiMed-ORBIT: Aligning LLMs on Open-Ended Complex Tasks via Rubric-Based Incremental Training , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
AdvancedIF: Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following , author=. 2025 , eprint=
2025
-
[37]
2026 , eprint=
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning , author=. 2026 , eprint=
2026
-
[38]
2026 , eprint=
Auto-Rubric: Learning From Implicit Weights to Explicit Rubrics for Reward Modeling , author=. 2026 , eprint=
2026
-
[39]
Open rubric system:
Jia, Ruipeng and Yang, Yunyi and Wu, Yuxin and Gai, Yongbo and Tao, Siyuan and Zhou, Mengyu and Lin, Jianhe and Jiang, Xiaoxi and Jiang, Guanjun , journal=. Open rubric system:. 2026 , url=
2026
-
[40]
Alternating reinforcement learning for rubric-based reward modeling in non-verifiable llm post-training , author=. arXiv preprint arXiv:2602.01511 , year=
-
[41]
Reinforcing
Sheng, Leheng and Ma, Wenchang and Hong, Ruixin and Wang, Xiang and Zhang, An and Chua, Tat-Seng , journal=. Reinforcing. 2026 , url=
2026
-
[42]
2026 , eprint=
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research , author=. 2026 , eprint=
2026
-
[43]
Deepseekmath:
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and Wu, Yang and Guo, Daya , journal=. Deepseekmath:. 2024 , url=
2024
-
[44]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , url =
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and liu, juncai and Liu, LingJun and Liu, Xin and Lin, Haibin and Lin, Zhiqi and Ma, Bole and Sheng, Guangming and Tong, Yuxuan and Zhang, Chi and Zhang, Mofan and Zhang, Ru and Zhang, Wang and Zhu, Hang and Zhu, Ji...
-
[45]
Dong, Guanting and Chen, Yifei and Li, Xiaoxi and Jin, Jiajie and Qian, Hongjin and Zhu, Yutao and Mao, Hangyu and Zhou, Guorui and Dou, Zhicheng and Wen, Ji-Rong , journal=. Tool-. 2025 , url=
2025
-
[46]
2024 , eprint=
Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems , author=. 2024 , eprint=
2024
-
[47]
Llamafactory:
Zheng, Yaowei and Zhang, Richong and Zhang, Junhao and Ye, Yanhan and Luo, Zheyan , booktitle=. Llamafactory:. 2024 , url=
2024
-
[48]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[49]
Rajbhandari, Samyam and Rasley, Jeff and Ruwase, Olatunji and He, Yuxiong , booktitle=. Zero:. 2020 , organization=
2020
-
[50]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning , url =
Dao, Tri , booktitle =. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning , url =
-
[51]
Megatron-lm:
Shoeybi, Mohammad and Patwary, Mostofa and Puri, Raul and LeGresley, Patrick and Casper, Jared and Catanzaro, Bryan , journal=. Megatron-lm:. 2019 , url=
2019
-
[52]
2024 , eprint=
SGLang: Efficient Execution of Structured Language Model Programs , author=. 2024 , eprint=
2024
-
[53]
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[54]
2025 , howpublished =
Zilin Zhu and Chengxing Xie and Xin Lv and slime Contributors , title =. 2025 , howpublished =
2025
-
[55]
DeepSeek-AI , year=. Deep
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.