Asking Back: Interaction-Layer Antidistillation Watermarks
Pith reviewed 2026-05-20 18:03 UTC · model grok-4.3
The pith
System prompts can embed behavioral markers in LLM responses that transfer to distilled student models and stay detectable through black-box queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By wrapping the teacher with a system prompt that occasionally elicits an explicit follow-up question, a low-frequency variant, or a declarative restatement, the defender induces a behavioral marker that an oblivious distiller inherits during LoRA fine-tuning; the same marker is then recovered in black-box interactions using an LLM-as-judge whose agreement with humans reaches Cohen’s kappa of 0.84 on strong-rubric and 0.78 on style-rubric labels. Across 35,343 judged samples the markers transfer at 88.9 % (Gemma), 80.9 % (OLMo) and 45.2 % (Qwen) relative fidelity; under DIPPER paraphrasing they retain 21–112 % of the teacher-self ceiling; low-density declarative variants exceed per-family un
What carries the argument
interaction-layer antidistillation watermark: a system-prompt-induced behavioral marker (follow-up question, variant phrasing, or restatement) that is inherited by the student and later audited via black-box queries
If this is right
- Behavioral markers transfer at relative fidelities between 45 % and 89 % across three student families when the teacher is Llama-3.3-70B-Instruct.
- Under non-adaptive paraphrasing the student-relative retention ranges from 21 % to 112 % of the teacher-self ceiling, with one family preserving the signal above the teacher itself.
- Low-density (≈20 %) explicit and implicit declarative variants still exceed per-family baseline rates.
- All marker variants shift average Likert ratings by no more than 0.22 points in a pre-registered N=20 user study.
Where Pith is reading between the lines
- The interaction layer could be stacked with token- or trace-level watermarks to raise the cost of any single-layer removal attack.
- Adaptive attackers who know the marker vocabulary might still be forced to degrade output quality or increase query cost to suppress the signal.
- The same prompt-induced behavior could serve as a lightweight provenance signal for non-distillation misuse such as repeated API scraping.
- Extending the approach to multi-turn conversations would test whether the marker persists across longer interaction histories.
Load-bearing premise
The behavioral markers triggered by the system prompt are reliably copied into the student during ordinary LoRA fine-tuning and can be identified accurately by the LLM judge without large numbers of false positives or negatives.
What would settle it
A distilled student model that, after training on the watermarked teacher outputs, produces follow-up questions or declarative restatements at the same low rate as an identical model trained on ordinary data.
Figures










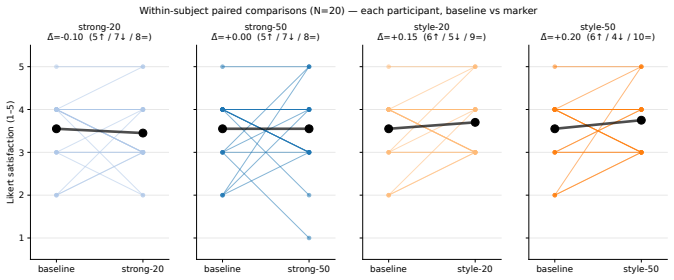
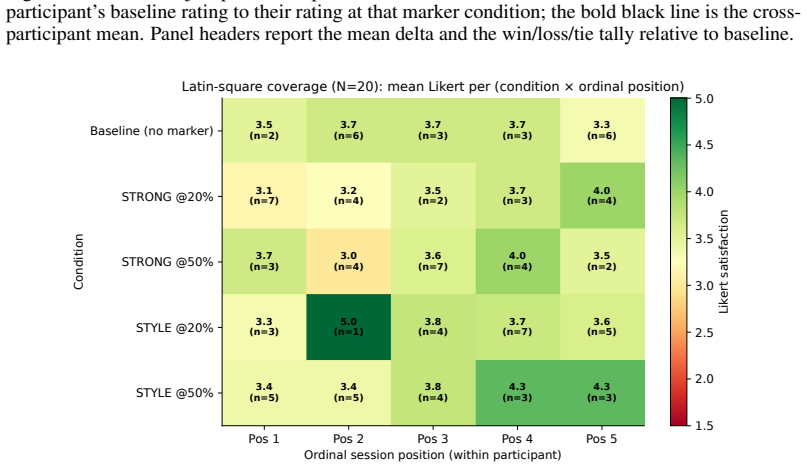



read the original abstract
Detecting unauthorized knowledge distillation from a deployed LLM API is hard because the defender controls neither the attacker's training pipeline nor the next-token logits. Existing defenses operate on the teacher's output tokens -- biasing the next-token distribution (green-list watermarks, cryptographic schemes, antidistillation sampling) or rewriting outputs after generation. Recent work shows a paraphrasing attacker can strip these signals without losing the underlying knowledge. We propose interaction-layer antidistillation watermarks, which move the trace one layer higher, into the teacher's interaction behavior: the defender wraps the teacher with a system prompt that intermittently induces a behavioral marker -- an explicit follow-up question, a low-frequency variant, or a declarative restatement. An oblivious distiller inherits the behavior, and the defender audits via black-box queries with a human-validated LLM-as-judge (Cohen's kappa = 0.84/0.78 on strong/style rubrics). Across 63 LoRA-distilled students under a Llama-3.3-70B-Instruct teacher (35,343 judged samples), behavioral watermarks transfer at 88.9% (Gemma) / 80.9% (OLMo) / 45.2% (Qwen) relative fidelity (H1, H2). Under non-adaptive DIPPER paraphrasing, robustness decomposes into a teacher-self ceiling (about 66.4%) and student-relative retention of 21-112%, with OLMo preserving the watermark above the teacher itself (H3, F-Amp). Low-density (about 20%) explicit and implicit declarative variants transfer above per-family baseline (H4, F-Style). An N=20 in-lab study (pre-registered Latin-square) shows all marker variants within 0.22 Likert step of baseline; TOST, Friedman, and Bonferroni-Wilcoxon support H5. The interaction layer is a viable design locus for antidistillation watermarking, complementary to token-, model-, and reasoning-trace-layer defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes interaction-layer antidistillation watermarks for LLMs. A system prompt intermittently induces behavioral markers (explicit follow-up questions, low-frequency variants, or declarative restatements) in the teacher's outputs. An oblivious distiller inherits these markers during LoRA fine-tuning, which the defender then detects via black-box queries using a human-validated LLM-as-judge (Cohen's kappa 0.84/0.78). Experiments with a Llama-3.3-70B-Instruct teacher and 63 LoRA students (35,343 judged samples) report relative transfer fidelities of 88.9% (Gemma), 80.9% (OLMo), and 45.2% (Qwen). Robustness under non-adaptive DIPPER paraphrasing decomposes into a teacher-self ceiling of ~66% with student-relative retention of 21-112%; low-density (~20%) variants transfer above per-family baselines. A pre-registered N=20 user study (Latin-square) with TOST, Friedman, and Bonferroni-Wilcoxon tests confirms usability within 0.22 Likert steps of baseline.
Significance. If the inheritance and detection assumptions hold, the work establishes the interaction layer as a viable complementary defense locus to token-, model-, and reasoning-trace-layer techniques. The large-scale empirical measurements, model-family transfer variation, robustness decomposition, and pre-registered statistical support from the user study provide concrete, falsifiable evidence for behavioral-marker transfer. The scale (35k samples) and pre-registration are notable strengths that would make the contribution substantial for practical antidistillation auditing if the judge false-positive rates and inheritance specificity are further secured.
major comments (3)
- [§4 (H1, H2)] §4 (H1, H2): The reported relative fidelities (88.9% Gemma, 80.9% OLMo, 45.2% Qwen) support transfer but the large model-family dependence leaves open whether the markers reflect specific watermark inheritance or generic style mimicry; a control arm with non-watermarked system prompts on the same teacher-student pairs would isolate the effect and is load-bearing for the antidistillation claim.
- [Robustness section (H3, F-Amp)] Robustness section (H3, F-Amp): The decomposition into teacher-self ceiling (~66.4%) and student-relative retention (21-112%) is useful, yet the 21% floor under DIPPER for some students indicates that detection may fall below practical thresholds in non-adaptive paraphrasing scenarios; clarifying the minimum retention needed for reliable auditing would strengthen the central claim.
- [Judge validation] Judge validation (Cohen's kappa 0.84/0.78): While inter-rater agreement on strong/style rubrics is reported, the false-positive rate on unmarked models from the same families (baseline Gemma/OLMo/Qwen without the interaction prompt) is not quantified; this is load-bearing because non-negligible false positives would undermine black-box audit reliability.
minor comments (2)
- [Abstract] Abstract: The low-density variants are described as 'about 20%'; reporting the exact density and sampling schedule used in the 35k-sample experiments would improve precision and reproducibility.
- [User study (H5)] User study (H5): The N=20 pre-registered Latin-square design is a strength, but the exact prompt templates, judge rubrics, and full statistical outputs (including effect sizes) should be included in an appendix to support independent verification.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments below and have revised the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§4 (H1, H2)] The reported relative fidelities (88.9% Gemma, 80.9% OLMo, 45.2% Qwen) support transfer but the large model-family dependence leaves open whether the markers reflect specific watermark inheritance or generic style mimicry; a control arm with non-watermarked system prompts on the same teacher-student pairs would isolate the effect and is load-bearing for the antidistillation claim.
Authors: We agree that the model-family variation warrants careful interpretation to distinguish watermark inheritance from generic style mimicry. The manuscript already reports per-family baselines in the context of H4 and F-Style, where low-density variants transfer above these baselines, providing evidence against pure generic mimicry. To directly address the suggested control, we will include an additional experiment in the revised §4 using non-watermarked system prompts on matched teacher-student pairs. This will allow us to quantify the incremental effect of the interaction-layer prompt beyond any baseline style transfer. revision: yes
-
Referee: [Robustness section (H3, F-Amp)] The decomposition into teacher-self ceiling (~66.4%) and student-relative retention (21-112%) is useful, yet the 21% floor under DIPPER for some students indicates that detection may fall below practical thresholds in non-adaptive paraphrasing scenarios; clarifying the minimum retention needed for reliable auditing would strengthen the central claim.
Authors: Thank you for highlighting the practical implications of the lower retention rates. The 21% floor is indeed observed for certain student models under DIPPER paraphrasing. We will add a clarification in the revised robustness section on the minimum retention needed for reliable auditing, discussing how it depends on the number of audit queries and the variance observed in our dataset to ensure statistical power. revision: yes
-
Referee: [Judge validation] While inter-rater agreement on strong/style rubrics is reported, the false-positive rate on unmarked models from the same families (baseline Gemma/OLMo/Qwen without the interaction prompt) is not quantified; this is load-bearing because non-negligible false positives would undermine black-box audit reliability.
Authors: We recognize the importance of quantifying false-positive rates for the black-box audit's reliability. The reported Cohen's kappa values (0.84/0.78) reflect agreement on the rubrics used by the LLM-as-judge. We agree this is load-bearing and will extend the judge validation in the revised manuscript to include explicit false-positive rate measurements on unmarked baseline models from the same families. revision: yes
Circularity Check
No significant circularity in empirical derivation chain
full rationale
The paper's claims rest entirely on empirical measurements: observed transfer rates of behavioral markers (explicit follow-up questions, low-frequency variants, declarative restatements) from a Llama-3.3-70B teacher into 63 LoRA students across model families, retention under DIPPER paraphrasing, and usability scores from an N=20 pre-registered Latin-square study. These quantities are obtained via black-box queries and human-validated LLM-as-judge annotations whose inter-rater agreement (Cohen's kappa 0.84/0.78) is reported as a standard validation step rather than a fitted input. No equations, self-definitional constructions, or load-bearing self-citations appear in the provided text; the central result is the measured model-dependent fidelity variation (88.9 % Gemma to 45.2 % Qwen) and statistical support (TOST, Friedman, Bonferroni-Wilcoxon), which are externally falsifiable observations rather than reductions to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Behavioral patterns induced by system prompts are preserved during LoRA-based knowledge distillation from teacher to student models.
- domain assumption An LLM-as-judge can reliably detect the presence of interaction markers with agreement levels comparable to human raters (Cohen's kappa 0.84/0.78).
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose interaction-layer antidistillation watermarks, which move the trace one layer higher, into the teacher's interaction behavior: the defender wraps the teacher with a system prompt that intermittently induces a behavioral marker—an explicit follow-up question, a low-frequency variant, or a declarative restatement.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
My AI safety lecture for UT Effective Altruism, 2022
Scott Aaronson. My AI safety lecture for UT Effective Altruism, 2022. URL https:// scottaaronson.blog/?p=6823. Public lecture (Nov. 14, 2022) and accompanying blog write-up (Nov. 28, 2022); widely cited as the originator of the cryptographic-watermark proposal for LLMs
work page 2022
-
[2]
DITTO: A spoofing attack framework on watermarked LLMs via knowledge distillation
Hyeseon An, Shinwoo Park, Suyeon Woo, and Yo-Sub Han. DITTO: A spoofing attack framework on watermarked LLMs via knowledge distillation. InProceedings of the 2026 Conference of the European Chapter of the Association for Computational Linguistics (EACL), 2026
work page 2026
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021. URL https://arxiv. org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Undetectable watermarks for language models
Miranda Christ, Sam Gunn, and Or Zamir. Undetectable watermarks for language models. InConference on Learning Theory (COLT), 2024. URL https://arxiv.org/abs/2306. 09194. 10
work page 2024
-
[5]
Language models transmit behavioural traits through hidden signals in data.Nature, 652:615–621, 2026
Alex Cloud, Minh Le, James Chua, Jan Betley, Anna Sztyber-Betley, Sören Mindermann, Jacob Hilton, Samuel Marks, and Owain Evans. Language models transmit behavioural traits through hidden signals in data.Nature, 652:615–621, 2026. doi: 10.1038/s41586-026-10319-8. URL https://www.nature.com/articles/s41586-026-10319-8
-
[6]
Qwen3.5 family chat-template thinking-mode issues, 2025
Community bug reports. Qwen3.5 family chat-template thinking-mode issues, 2025. URL https://github.com/vllm-project/vllm/issues/35574. Multiple independent repro- ductions across inference backends that the enable_thinking=false chat-template flag does not, in practice, disable chain-of-thought generation in the Qwen3.5 architecture family. Representative...
work page 2025
-
[7]
Jiayu Ding, Lei Cui, Li Dong, Nanning Zheng, and Furu Wei. PART: Information-preserving reformulation of reasoning traces for antidistillation.arXiv preprint arXiv:2510.11545, 2025. URLhttps://arxiv.org/abs/2510.11545
-
[8]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. URL https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Aaron Grattafiori et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. URLhttps://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
MiniLLM: On-Policy Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. InInternational Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2306.08543
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. InNeurIPS Deep Learning and Representation Learning Workshop, 2015. URL https: //arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. InInternational Conference on Learning Representations (ICLR), 2020. URLhttps://arxiv.org/abs/1904.09751
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022. URL https://arxiv. org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022. URLhttps://arxiv.org/abs/2207.05221
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
A watermark for large language models, 2024
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InInternational Conference on Machine Learning (ICML), 2023. URLhttps://arxiv.org/abs/2301.10226
-
[16]
Andreas Koepf, Yannic Kilcher, Laura von Rueden, Dmitrii Rybin, Xiaozhe Xu, Iryna Gurevych, et al. OpenAssistant conversations – democratizing large language model alignment.arXiv preprint arXiv:2304.07327, 2023. URLhttps://arxiv.org/abs/2304.07327
-
[17]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense, 2023
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. Paraphras- ing evades detectors of AI-generated text, but retrieval is an effective defense. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://arxiv.org/abs/ 2303.13408
-
[18]
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 33(1):159–174, 1977
work page 1977
-
[19]
Pingzhi Li, Zhen Tan, Mohan Zhang, Huaizhi Qu, Huan Liu, and Tianlong Chen. DOGe: Defensive output generation for LLM protection against knowledge distillation.arXiv preprint arXiv:2505.19504, 2025. URLhttps://arxiv.org/abs/2505.19504. 11
-
[21]
URLhttps://arxiv.org/abs/2602.15143
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
An empirical analysis of memorization in fine-tuned autoregressive language models
Fatemehsadat Mireshghallah, Archit Uniyal, Tianhao Wang, David Evans, and Taylor Berg- Kirkpatrick. An empirical analysis of memorization in fine-tuned autoregressive language models. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2022. URLhttps://arxiv.org/abs/2205.10770
-
[23]
OLMo Team, Allen Institute for AI. 2 OLMo 2 furious.arXiv preprint arXiv:2501.00656, 2024. URLhttps://arxiv.org/abs/2501.00656
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025. URL https://arxiv.org/abs/2508.10925. Open-weights OSS model release accompanying the gpt-oss-120b checkpoint
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Leyi Pan, Aiwei Liu, Shiyu Huang, Yijian Lu, Xuming Hu, Lijie Wen, Irwin King, and Philip S. Yu. Can LLM watermarks robustly prevent unauthorized knowledge distillation? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025. URLhttps://aclanthology.org/2025.acl-long.648/
work page 2025
-
[26]
Qwen3.5 base: A family of pre-trained language models, 2025
Qwen Team. Qwen3.5 base: A family of pre-trained language models, 2025. URL https: //huggingface.co/Qwen/Qwen3.5-0.8B-Base. Hugging Face model card
work page 2025
-
[27]
Radioactive data: Tracing through training
Alexandre Sablayrolles, Matthijs Douze, Cordelia Schmid, and Hervé Jégou. Radioactive data: Tracing through training. InInternational Conference on Machine Learning (ICML), 2020. URLhttps://arxiv.org/abs/2002.00937
-
[28]
Can AI-generated text be reliably detected?Transactions on Machine Learning Research (TMLR), 2024
Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. Can AI-generated text be reliably detected?Transactions on Machine Learning Research (TMLR), 2024. URLhttps://openreview.net/forum?id=NvSwR4IvLO
work page 2024
-
[29]
Watermarking makes language models radioactive
Tom Sander, Pierre Fernandez, Alain Durmus, Matthijs Douze, and Teddy Furon. Watermarking makes language models radioactive. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. URLhttps://arxiv.org/abs/2402.14904
-
[30]
Yash Savani, Asher Trockman, Zhili Feng, Yixuan Xu, Avi Schwarzschild, Alexander Robey, Marc Finzi, and J. Zico Kolter. Antidistillation sampling. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2025. URL https://openreview.net/forum?id= Vo2UHqMu8t
work page 2025
-
[31]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. InIEEE Symposium on Security and Privacy (S&P),
-
[32]
URLhttps://arxiv.org/abs/1610.05820
work page internal anchor Pith review Pith/arXiv arXiv
- [34]
-
[35]
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford Alpaca: An instruction-following LLaMA model, 2023. URLhttps://github.com/tatsu-lab/stanford_alpaca. Stanford CRFM release; project page and code only, no arXiv preprint
work page 2023
-
[36]
OpenHermes-2.5: An open instruction dataset, 2023
Teknium. OpenHermes-2.5: An open instruction dataset, 2023. URL https://huggingface. co/datasets/teknium/OpenHermes-2.5. Hugging Face dataset
work page 2023
-
[37]
Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. OpenMathInstruct-2: Accelerating AI for math with massive open-source instruction data.arXiv preprint arXiv:2410.01560, 2024. URL https://arxiv.org/abs/2410.01560
-
[38]
Who taught you that? tracing teachers in model distillation
Somin Wadhwa, Chantal Shaib, Silvio Amir, and Byron C Wallace. Who taught you that? tracing teachers in model distillation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 3307–3315, 2025. 12
work page 2025
-
[39]
Magicoder: Empowering code generation with oss-instruct.arXiv preprint arXiv:2312.02120, 2023
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Empow- ering code generation with OSS-Instruct. InInternational Conference on Machine Learning (ICML), 2024. URLhttps://arxiv.org/abs/2312.02120
-
[40]
Neural text generation with unlikelihood training
Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. Neural text generation with unlikelihood training. InInternational Conference on Learning Representations (ICLR), 2020. URLhttps://arxiv.org/abs/1908.04319
-
[41]
Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs. InInternational Conference on Learning Representations (ICLR), 2024. URL https:// openreview.net/forum?id=gjeQKFxFpZ
work page 2024
-
[42]
Instructional fingerprinting of large language models
Jiashu Xu, Fei Wang, Mingyu Derek Ma, Pang Wei Koh, Chaowei Xiao, and Muhao Chen. Instructional fingerprinting of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024. URLhttps://aclanthology.org/2024.naacl-long.180/
work page 2024
-
[43]
Antidistillation Fingerprinting
Yixuan Xu et al. Antidistillation fingerprinting.arXiv preprint arXiv:2602.03812, 2026. URL https://arxiv.org/abs/2602.03812
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
An Yang et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Michael J. Q. Zhang, W. Bradley Knox, and Eunsol Choi. Modeling future conversation turns to teach LLMs to ask clarifying questions. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://openreview.net/forum?id=cwuSAR7EKd
work page 2025
-
[46]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URLhttps://arxiv.org/abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Zhihan Zhou, Robert Riley, Satria Kautsar, Weimin Wu, Rob Egan, Steven Hofmeyr, Shira Goldhaber-Gordon, Mutian Yu, Harrison Ho, Fengchen Liu, Feng Chen, Rachael Morgan-Kiss, Lizhen Shi, Han Liu, and Zhong Wang. GenomeOcean: An efficient genome foundation model trained on large-scale metagenomic assemblies.bioRxiv, 2025. doi: 10.1101/2025.01.30. 635558. UR...
-
[48]
This confirms that the radioactivity property of [28] extends to a non-text generative modality
Inheritance through distillation.The watermarked ( δ=2) student is shifted by ∼7.95σ above the vanilla null and crosses z >2.33 on 95.5% of sequences (Figure 15). This confirms that the radioactivity property of [28] extends to a non-text generative modality
-
[49]
Multi-sequence aggregation scales as √n.Aggregating n independent sequences lifts TPR at FPR =1% from 45% at n=1 to ≥99.9% at n≥10 (Figure 16), consistent with the closed-form predictionz (n) agg = √n¯z
-
[50]
Robustness to mild base-level mutation.Replacing a fraction of the bases in every δ=2 output with uniform substitutions from {A, C, G, T} and re-auditing, 78.5% of sequences still cross threshold at 5% mutation rate (Figure 17), indicating that the inherited bias is not concentrated in a single short motif. A more detailed treatment, including additional ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.