Decentralized Multi-Agent Systems with Shared Context
Pith reviewed 2026-06-27 11:09 UTC · model grok-4.3
The pith
Decentralized agents using a shared verified context outperform centralized multi-agent systems on software engineering and long-context benchmarks while halving costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
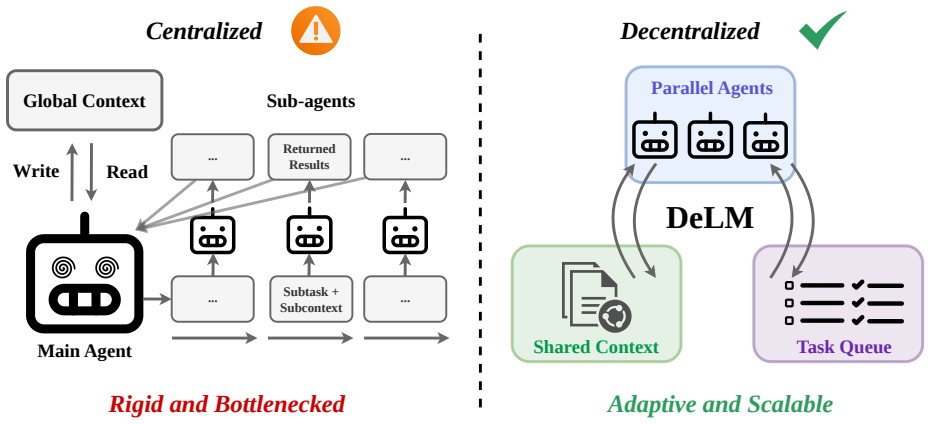
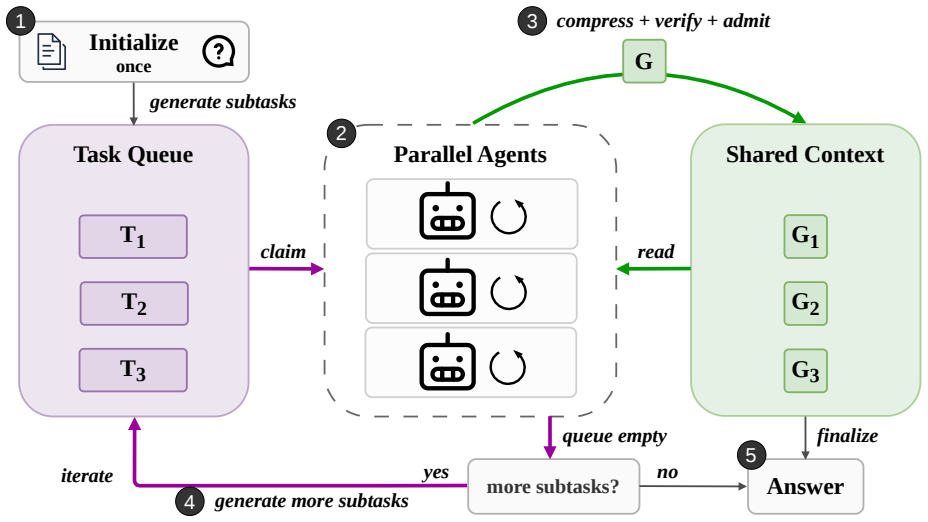
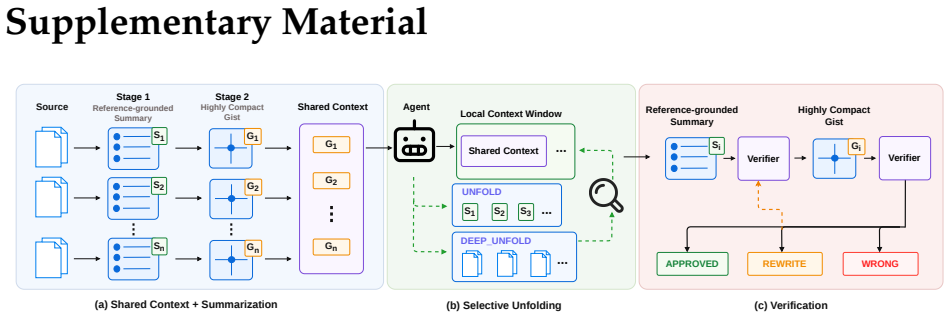
DeLM is a multi-agent framework that decentralizes coordination through parallel agents, a shared verified context, and a task queue. Agents asynchronously claim subtasks, read the accumulated verified progress, reason locally, and write back compact verified updates. The shared context acts as the common communication substrate, enabling agents to build on one another's progress without routing every update through a central controller.
What carries the argument
The shared verified context that functions as an asynchronous common communication substrate for agent updates.
If this is right
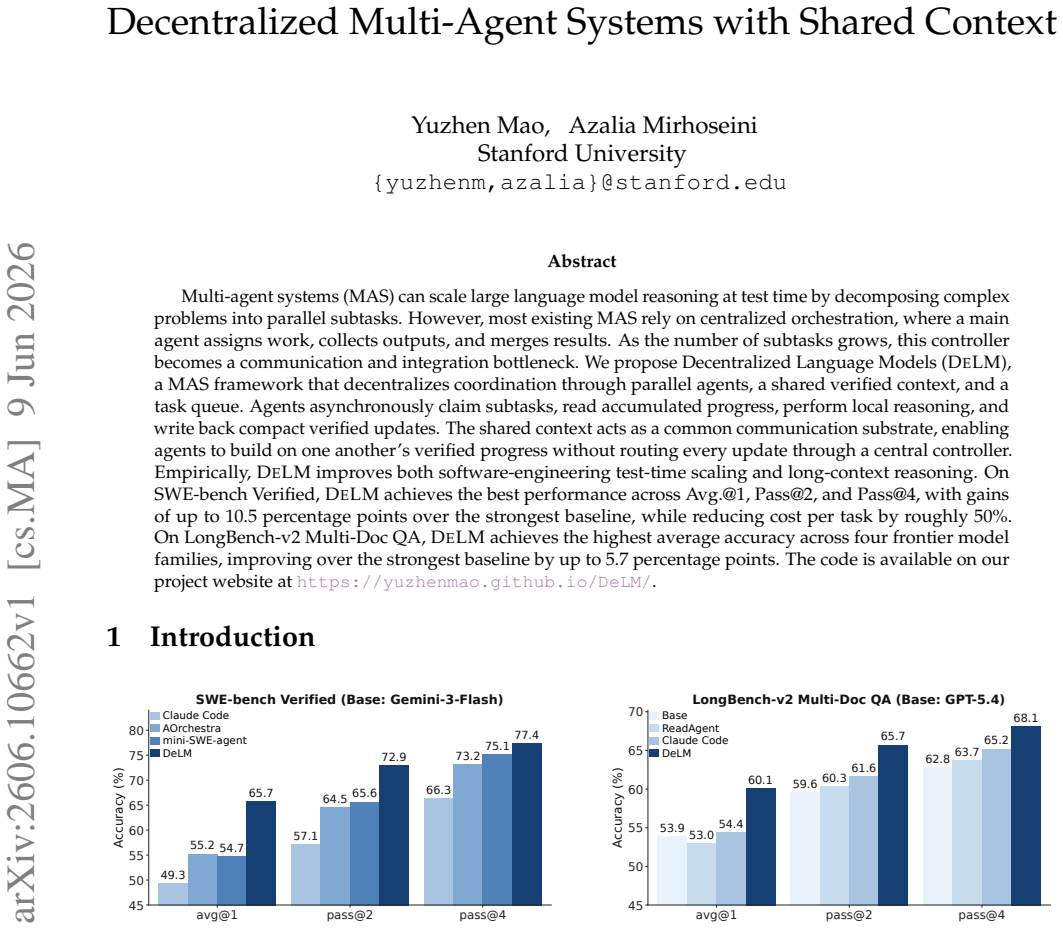
- DeLM records the best scores on SWE-bench Verified for Avg.@1, Pass@2, and Pass@4.
- Cost per task drops by roughly 50 percent on the same benchmark.
- Accuracy rises by up to 5.7 percentage points on LongBench-v2 Multi-Doc QA across four frontier model families.
- Coordination overhead stays flat as the number of subtasks increases.
Where Pith is reading between the lines
- The same shared-context pattern could be tested on agent teams that must maintain a single evolving plan over many steps.
- Verification rules inside the context might be relaxed or strengthened to measure the accuracy-cost trade-off directly.
- The framework could be run with heterogeneous model sizes where cheaper agents handle simple subtasks and stronger ones handle verification.
- Task queues with priority or dependency edges could be added to see whether ordering constraints improve or hurt the observed gains.
Load-bearing premise
The shared verified context can be read and written asynchronously by multiple agents without introducing unresolvable conflicts or unverifiable errors.
What would settle it
A run on SWE-bench Verified in which agents produce conflicting writes to the shared context that cannot be verified or merged, causing DeLM to fall below the strongest centralized baseline on Pass@2 or Pass@4.
Figures
read the original abstract
Multi-agent systems (MAS) can scale large language model reasoning at test time by decomposing complex problems into parallel subtasks. However, most existing MAS rely on centralized orchestration, where a main agent assigns work, collects outputs, and merges results. As the number of subtasks grows, this controller becomes a communication and integration bottleneck. We propose Decentralized Language Models (DeLM), a MAS framework that decentralizes coordination through parallel agents, a shared verified context, and a task queue. Agents asynchronously claim subtasks, read accumulated progress, perform local reasoning, and write back compact verified updates. The shared context acts as a common communication substrate, enabling agents to build on one another's verified progress without routing every update through a central controller. Empirically, DeLM improves both software-engineering test-time scaling and long-context reasoning. On SWE-bench Verified, DeLM achieves the best performance across Avg.@1, Pass@2, and Pass@4, with gains of up to 10.5 percentage points over the strongest baseline, while reducing cost per task by roughly 50%. On LongBench-v2 Multi-Doc QA, DeLM achieves the highest average accuracy across four frontier model families, improving over the strongest baseline by up to 5.7 percentage points. The code is available on our project website at https://yuzhenmao.github.io/DeLM/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Decentralized Language Models (DeLM), a multi-agent system framework that decentralizes coordination via parallel agents, a shared verified context, and a task queue. Agents asynchronously claim subtasks, read accumulated progress, perform local reasoning, and write compact verified updates. The central claim is that this avoids central orchestration bottlenecks and yields empirical gains: on SWE-bench Verified, best performance across Avg.@1, Pass@2, and Pass@4 with up to 10.5 pp improvement and ~50% cost reduction; on LongBench-v2 Multi-Doc QA, highest average accuracy across four model families with up to 5.7 pp gains.
Significance. If the shared-context mechanism reliably supports cumulative verified progress under asynchrony, the work would be significant for scaling test-time multi-agent reasoning without central bottlenecks. The reported benchmark gains and cost savings, together with public code release, would provide a concrete, reproducible baseline for decentralized MAS.
major comments (3)
- [§3.2] §3.2 (Shared Verified Context): The description states that agents 'asynchronously claim subtasks, read accumulated progress, perform local reasoning, and write back compact verified updates,' but supplies no protocol for versioning, locking, conflict detection, or resolution of overlapping writes. This mechanism is load-bearing for the decentralization claim and for attributing the 10.5 pp and 5.7 pp gains to the architecture rather than to centralized verification.
- [§4.1] §4.1 (Experimental Setup): The comparisons on SWE-bench Verified and LongBench-v2 report performance numbers but do not describe whether baselines received equivalent local verification steps, the same task-queue discipline, or identical conflict-handling assumptions. Without these controls it is impossible to isolate the contribution of the decentralized shared context.
- [§4.3] §4.3 (Ablation Studies): No ablation isolates the effect of asynchronous shared-context writes versus sequential or centrally mediated updates; the reported gains could therefore be driven by verification volume rather than by the decentralized coordination substrate.
minor comments (2)
- [Abstract / §1] The abstract and §1 use 'verified' without an operational definition; a short paragraph clarifying what constitutes a 'verified update' would improve clarity.
- [Figure 2] Figure 2 (system diagram) would benefit from explicit arrows or labels showing the read/write paths to the shared context and the task queue.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and commit to revisions that strengthen the description of the shared context and the experimental analysis.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Shared Verified Context): The description states that agents 'asynchronously claim subtasks, read accumulated progress, perform local reasoning, and write back compact verified updates,' but supplies no protocol for versioning, locking, conflict detection, or resolution of overlapping writes. This mechanism is load-bearing for the decentralization claim and for attributing the 10.5 pp and 5.7 pp gains to the architecture rather than to centralized verification.
Authors: We agree that the concurrency protocol requires explicit specification. In the revised manuscript we will expand §3.2 with a formal description of the shared verified context, including version vectors for update tracking, optimistic locking keyed to subtask claims, conflict detection via version mismatch, and resolution by priority merge of verified facts. This addition will clarify how the architecture supports asynchrony and will help attribute the reported gains to the decentralized design rather than to verification alone. revision: yes
-
Referee: [§4.1] §4.1 (Experimental Setup): The comparisons on SWE-bench Verified and LongBench-v2 report performance numbers but do not describe whether baselines received equivalent local verification steps, the same task-queue discipline, or identical conflict-handling assumptions. Without these controls it is impossible to isolate the contribution of the decentralized shared context.
Authors: We acknowledge that the experimental setup must document baseline conditions more precisely. The revision will augment §4.1 with explicit statements of the verification steps, task-queue discipline, and conflict-handling rules applied to each baseline. Where original baselines differed, we will note the differences and, where computationally feasible, supply matched re-runs to isolate the contribution of the decentralized shared context. revision: yes
-
Referee: [§4.3] §4.3 (Ablation Studies): No ablation isolates the effect of asynchronous shared-context writes versus sequential or centrally mediated updates; the reported gains could therefore be driven by verification volume rather than by the decentralized coordination substrate.
Authors: We agree that an ablation separating asynchrony from verification volume is needed. The revised §4.3 will include a new ablation comparing the full asynchronous DeLM against sequential and centrally mediated variants while controlling for total verification steps. This will provide direct evidence that performance differences arise from the decentralized coordination substrate. revision: yes
Circularity Check
No derivation chain present; empirical claims only
full rationale
The manuscript describes a decentralized MAS framework evaluated via benchmark experiments on SWE-bench Verified and LongBench-v2. No equations, fitted parameters, ansatzes, uniqueness theorems, or derivation steps are referenced in the abstract or described structure. Performance numbers are reported outcomes, not quantities defined in terms of themselves or reduced via self-citation. The central claims therefore rest on external falsifiable measurements rather than any self-referential construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agents can reliably verify and incorporate updates from the shared context without introducing errors that break cumulative progress.
invented entities (1)
-
Shared verified context
no independent evidence
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Accessed: 2026-06-03
URL https://deepmind.google/blog/ alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/ . Accessed: 2026-06-03. Anthropic. Claude Sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6 ,
2026
-
[3]
Anthropic
Accessed: 2026-05-06. Anthropic. Introducing Claude Opus 4.6. Anthropic, February
2026
-
[4]
anthropic.com/news/claude-opus-4-6
URL https://www. anthropic.com/news/claude-opus-4-6. Accessed: 2026-06-01. Anthropic. Claude code.https://claude.ai/,
2026
-
[5]
Amanda Bertsch, Adithya Pratapa, Teruko Mitamura, Graham Neubig, and Matthew R Gorm- ley. Oolong: Evaluating long context reasoning and aggregation capabilities.arXiv preprint arXiv:2511.02817,
-
[6]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URL https://blog.google/products-and-platforms/products/gemini/ gemini-3-flash/. Accessed: 2026-06-01. Zhaopeng Feng, Liangcai Su, Zhen Zhang, Xinyu Wang, Xiaotian Zhang, Xiaobin Wang, Runnan Fang, Qi Zhang, Baixuan Li, Shihao Cai, et al. Agentswing: Adaptive parallel context management routing for long-horizon web agents.arXiv preprint arXiv:2603.27490,
-
[8]
Bochen Han and Songmao Zhang. Exploring advanced llm multi-agent systems based on blackboard architecture.arXiv preprint arXiv:2507.01701,
-
[9]
Kimi K2.5: Visual Agentic Intelligence
URL https://openreview.net/ forum?id=VTF8yNQM66. 18 Kimi, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Kuang-Huei Lee, Xinyun Chen, Hiroki Furuta, John Canny, and Ian Fischer. A human-inspired reading agent with gist memory of very long contexts.arXiv preprint arXiv:2402.09727,
-
[11]
Combee: Scaling Prompt Learning for Self-Improving Language Model Agents
Hanchen Li, Runyuan He, Qizheng Zhang, Changxiu Ji, Qiuyang Mang, Xiaokun Chen, Lakshya A Agrawal, Wei-Liang Liao, Eric Yang, Alvin Cheung, et al. Combee: Scaling prompt learning for self-improving language model agents.arXiv preprint arXiv:2604.04247,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, et al. Memos: An operating system for memory-augmented generation (mag) in large language models.arXiv preprint arXiv:2505.22101,
-
[13]
doi: 10.1145/3786335.3813221. URL https://doi.org/10. 1145/3786335.3813221. Monishwaran Maheswaran, Leon Lakhani, Zhongzhu Zhou, Shijia Yang, Junxiong Wang, Coleman Hooper, Yuezhou Hu, Rishabh Tiwari, Jue Wang, Harman Singh, et al. Squeeze evolve: Unified multi-model orchestration for verifier-free evolution.arXiv preprint arXiv:2604.07725,
-
[14]
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez
Accessed: 2026-05-06. Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. Memgpt: towards llms as operating systems
2026
-
[15]
Aorchestra: Automating sub-agent creation for agentic orchestration.arXiv preprint arXiv:2602.03786,
Jianhao Ruan, Zhihao Xu, Yiran Peng, Fashen Ren, Zhaoyang Yu, Xinbing Liang, Jinyu Xiang, Yongru Chen, Bang Liu, Chenglin Wu, et al. Aorchestra: Automating sub-agent creation for agentic orchestration.arXiv preprint arXiv:2602.03786,
-
[16]
Alireza Salemi, Mihir Parmar, Palash Goyal, Yiwen Song, Jinsung Yoon, Hamed Zamani, Tomas Pfister, and Hamid Palangi. Llm-based multi-agent blackboard system for information discovery in data science.arXiv preprint arXiv:2510.01285,
-
[17]
19 Hongjin Su, Shizhe Diao, Ximing Lu, Mingjie Liu, Jiacheng Xu, Xin Dong, Yonggan Fu, Peter Belcak, Hanrong Ye, Hongxu Yin, et al. Toolorchestra: Elevating intelligence via efficient model and tool orchestration.arXiv preprint arXiv:2511.21689,
-
[18]
Scaling long-horizon LLM agent via context-folding.arXiv preprint arXiv:2510.11967, 2025
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon llm agent via context-folding.arXiv preprint arXiv:2510.11967,
-
[19]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
URL https: //arxiv.org/abs/2405.15793. Xiyuan Yang, Jiaru Zou, Rui Pan, Ruizhong Qiu, Pan Lu, Shizhe Diao, Jindong Jiang, Hanghang Tong, Tong Zhang, Markus J Buehler, et al. Recursive multi-agent systems.arXiv preprint arXiv:2604.25917,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Alex L Zhang, Tim Kraska, and Omar Khattab. Recursive language models.arXiv preprint arXiv:2512.24601,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.