Improving Speech Recognition of Named Entities in Classroom Speech with LLM Revision and Phonetic-Semantic Context
Pith reviewed 2026-05-19 09:13 UTC · model grok-4.3
The pith
LLM revision pipeline that adds phonetic and semantic context corrects named entity errors in classroom ASR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By supplying an LLM with the ASR hypothesis, phonetic transcriptions, and semantic context from classroom speech, the model can detect and replace incorrect named entities, producing up to 30 percent relative WER reduction on the new NER-MIT-OpenCourseWare test set.
What carries the argument
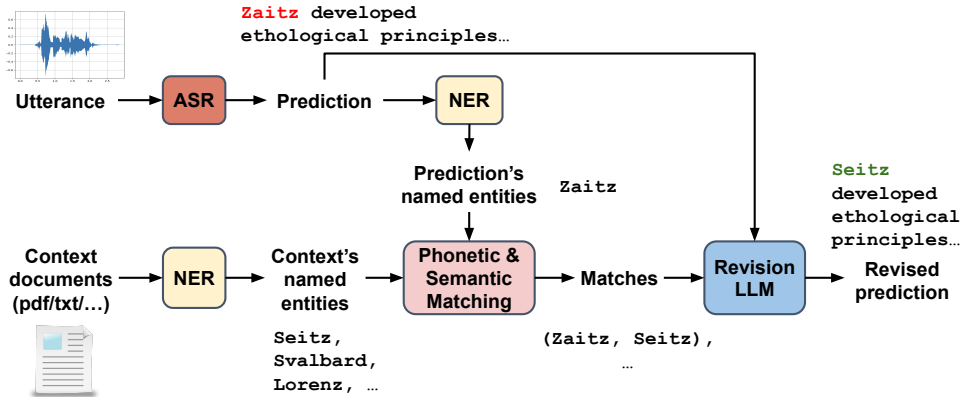
LLM revision pipeline that fuses phonetic and semantic context with the model's world knowledge to edit named entities in ASR output.
If this is right
- Downstream lecture applications such as search and summarization receive cleaner key terms.
- The approach works without any retraining of the base ASR model.
- Named-entity accuracy improves on educational audio where general ASR still struggles.
- The same revision idea can be applied to other spoken domains that contain specialized vocabulary.
Where Pith is reading between the lines
- The technique could extend to meeting or interview transcripts that also contain many proper names.
- Pairing the LLM step with improved phonetic front-ends might produce additional gains beyond the reported 30 percent.
- The results suggest hybrid ASR-plus-LLM systems are especially useful when the domain contains rare but important terms.
Load-bearing premise
The LLM already holds enough accurate world knowledge and can safely combine the supplied phonetic and semantic clues to fix named entities without creating fresh errors.
What would settle it
Running the same pipeline on a fresh collection of classroom recordings and finding no improvement or an increase in named-entity word error rate would show the claim does not hold.
Figures



read the original abstract
Classroom speech and lectures often contain named entities (NEs) such as names of people and special terminology. While automatic speech recognition (ASR) systems have achieved remarkable performance on general speech, the word error rate (WER) of state-of-the-art ASR remains high for named entities. Since NE are often the most critical keywords, misrecognizing them can affect all downstream applications, especially when the ASR functions as the front end of a complex system. In this paper, we introduce a large language model (LLM) revision pipeline to revise incorrect NEs in ASR predictions by leveraging not only the LLM's world knowledge and reasoning ability but also the available phonetic and semantic context. We also introduce the NER-MIT-OpenCourseWare dataset, containing 45 hours of data from MIT courses for development and testing. On this dataset, our proposed technique achieves up to 30\% relative WER reduction for NEs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an LLM-based revision pipeline to correct named entity (NE) errors in ASR outputs for classroom lectures by incorporating the LLM's world knowledge along with phonetic and semantic context. It introduces the NER-MIT-OpenCourseWare dataset (45 hours of MIT course recordings) and reports up to 30% relative WER reduction for NEs on this data.
Significance. If the empirical result holds under rigorous controls, the work offers a practical post-processing approach for improving critical NE accuracy in educational ASR, where misrecognized terms can degrade downstream tasks. The new dataset is a useful contribution for benchmarking NE performance in lecture speech. The method builds on LLM reasoning strengths but requires confirmation that context integration yields net gains without systematic over-correction.
major comments (2)
- §4 (Experimental Setup and Results): The reported up to 30% relative NE WER reduction lacks an ablation that removes the LLM revision step entirely (or removes only the phonetic-semantic context) while keeping the base ASR fixed; without this, it is unclear whether the net improvement is attributable to the proposed pipeline or to other factors such as dataset characteristics.
- §5 (Analysis): No breakdown is provided of LLM revision outcomes (true corrections vs. substitutions/insertions that introduce new errors or hallucinations). Given that classroom NEs are sparse and context-dependent, this analysis is load-bearing for validating that the LLM reliably integrates the supplied phonetic-semantic cues without net error increase.
minor comments (2)
- Abstract: The phrase 'up to 30% relative WER reduction' should be accompanied by the absolute WER numbers and the specific NE subset on which it was measured for immediate interpretability.
- Notation: The distinction between phonetic context (e.g., pronunciation hints) and semantic context (e.g., course topic) should be defined more explicitly when first introduced to avoid ambiguity in the pipeline description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: §4 (Experimental Setup and Results): The reported up to 30% relative NE WER reduction lacks an ablation that removes the LLM revision step entirely (or removes only the phonetic-semantic context) while keeping the base ASR fixed; without this, it is unclear whether the net improvement is attributable to the proposed pipeline or to other factors such as dataset characteristics.
Authors: We agree that isolating the contribution of the LLM revision step and the phonetic-semantic context is important for attributing the observed gains. In the revised manuscript we will add two ablations in §4: (1) direct comparison of the base ASR output against the full pipeline output with the same ASR fixed, and (2) an ablation that retains the LLM but removes the phonetic-semantic context (prompting with world knowledge only). These results will clarify that improvements stem from the proposed context integration rather than dataset properties. revision: yes
-
Referee: §5 (Analysis): No breakdown is provided of LLM revision outcomes (true corrections vs. substitutions/insertions that introduce new errors or hallucinations). Given that classroom NEs are sparse and context-dependent, this analysis is load-bearing for validating that the LLM reliably integrates the supplied phonetic-semantic cues without net error increase.
Authors: We acknowledge that a fine-grained breakdown of revision outcomes is necessary to demonstrate reliable integration of the cues. We will expand §5 with a quantitative categorization of LLM revisions (true NE corrections, substitutions that fix errors, insertions/deletions, and hallucinations) together with the net change in NE WER. Qualitative examples will illustrate how phonetic-semantic context reduces over-correction on sparse classroom entities. revision: yes
Circularity Check
No circularity: empirical measurement on new dataset
full rationale
The paper introduces the NER-MIT-OpenCourseWare dataset and evaluates an LLM revision pipeline that incorporates phonetic and semantic context to correct named entities in ASR output. The central result (up to 30% relative WER reduction for NEs) is presented as a direct experimental outcome on held-out test data rather than a derivation, fitted prediction, or self-citation chain that reduces to the inputs by construction. No equations, uniqueness theorems, or ansatzes are invoked that would make the reported improvement equivalent to the method's own parameters or prior self-references. The evaluation is self-contained against external benchmarks (standard ASR baselines and the new corpus) and does not rely on load-bearing self-citations or renaming of known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models possess sufficient world knowledge and reasoning ability to correct named entity errors when given phonetic and semantic context.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a large language model (LLM) revision pipeline to revise incorrect NEs in ASR predictions by leveraging ... phonetic and semantic context ... achieves up to 30% relative WER reduction for NEs
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Phonetic & Semantic Matching ... Double Metaphone ... Flair NER ... LLM revision prompt
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Introduction Recently, speech recognition performance has improved signif- icantly by scaling data and model size. Whisper [1], a model trained on an extensive dataset of 765K hours of speech, has achieved remarkable performance, achieving a WER of 2.7% on the standard Librispeech clean corpus and an average of 12.8% across popular speech datasets [1]. Ho...
-
[2]
One of the traditional approaches for biasing in ASR is shallow fusion [4, 5, 6]
Related Work A common way to improve named entity recognition is by biasing ASR toward a list of predefined words. One of the traditional approaches for biasing in ASR is shallow fusion [4, 5, 6]. In shallow fusion, during inference, the ASR predic- tion is influenced by a contextual language model with a certain weight. The contextual language model is o...
-
[3]
Method In this paper, we propose a novel method of using an LLM’s reasoning abilities to revise an ASR prediction by harnessing semantic as well as phonetic information on named entities in arXiv:2506.10779v1 [cs.CL] 12 Jun 2025 Matches Zaitz developed ethological principles… ASR Prediction Prediction’s named entities NER NER Context’s named entities Revi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Dataset We evaluate our proposed method on our own newly introduced dataset, as the number of datasets for contextual ASR is very limited and often tailored to industry settings or specific needs, such as earnings calls. In contrast, we are more interested in the education and science domains. The test set is an undergradu- ate course on animal behavior, ...
work page 2013
-
[5]
one of those students became very well known margaret mead
Experiments Using this dataset (Sec. 4), we conducted experiments to assess the benefits of the proposed method to improve ASR transcrip- tion accuracy of named entities, while hopefully keeping the transcription accuracy of non-named entities unchanged. As our method focuses on filtering relevant information in the context using semantic and phonetic cue...
-
[6]
Discussion and Conclusions In this paper, we introduce a novel method to revise predictions from speech recognition systems using a LLM. Specifically, we employ a phonetic and semantic matching component to select named entities from the context that are most relevant to those in the ASR prediction. We compare our proposed method to strong controls that u...
-
[7]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International conference on machine learning . PMLR, 2023, pp. 28 492–28 518
work page 2023
-
[8]
R. Huang, M. Yarmohammadi, J. Trmal, J. Liu, D. Raj, L. P. Gar- cia, A. V . Ivanov, P. Ehlen, M. Yu, D. Poveyet al., “Conec: Earn- ings call dataset with real-world contexts for benchmarking con- textual speech recognition,” in Proceedings of the 2024 Joint In- ternational Conference on Computational Linguistics, Language Resources and Evaluation (LREC-CO...
work page 2024
-
[9]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Lin et al. , “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
work page 2024
-
[10]
An analysis of incorporating an external lan- guage model into a sequence-to-sequence model,
A. Kannan, Y . Wu, P. Nguyen, T. N. Sainath, Z. Chen, and R. Prabhavalkar, “An analysis of incorporating an external lan- guage model into a sequence-to-sequence model,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2018, pp. 1–5828
work page 2018
-
[11]
Stream- ing end-to-end speech recognition for mobile devices,
Y . He, T. N. Sainath, R. Prabhavalkar, I. McGraw, R. Alvarez, D. Zhao, D. Rybach, A. Kannan, Y . Wu, R. Panget al., “Stream- ing end-to-end speech recognition for mobile devices,” inICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6381–6385
work page 2019
-
[12]
Shallow-fusion end-to-end contextual biasing
D. Zhao, T. N. Sainath, D. Rybach, P. Rondon, D. Bhatia, B. Li, and R. Pang, “Shallow-fusion end-to-end contextual biasing.” in Interspeech, 2019, pp. 1418–1422
work page 2019
-
[13]
Weighted finite-state trans- ducers in speech recognition,
M. Mohri, F. Pereira, and M. Riley, “Weighted finite-state trans- ducers in speech recognition,” Computer Speech & Language , vol. 16, no. 1, pp. 69–88, 2002
work page 2002
-
[14]
Deep context: end-to-end contextual speech recogni- tion,
G. Pundak, T. N. Sainath, R. Prabhavalkar, A. Kannan, and D. Zhao, “Deep context: end-to-end contextual speech recogni- tion,” in2018 IEEE spoken language technology workshop (SLT). IEEE, 2018, pp. 418–425
work page 2018
-
[15]
Context-aware transformer trans- ducer for speech recognition,
F.-J. Chang, J. Liu, M. Radfar, A. Mouchtaris, M. Omologo, A. Rastrow, and S. Kunzmann, “Context-aware transformer trans- ducer for speech recognition,” in 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 503–510
work page 2021
-
[16]
Contextual adapters for personalized speech recognition in neural transducers,
K. M. Sathyendra, T. Muniyappa, F.-J. Chang, J. Liu, J. Su, G. P. Strimel, A. Mouchtaris, and S. Kunzmann, “Contextual adapters for personalized speech recognition in neural transducers,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 8537– 8541
work page 2022
-
[17]
Advanced long-content speech recognition with factorized neu- ral transducer,
X. Gong, Y . Wu, J. Li, S. Liu, R. Zhao, X. Chen, and Y . Qian, “Advanced long-content speech recognition with factorized neu- ral transducer,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024
work page 2024
-
[18]
W. Chan, N. Jaitly, Q. V . Le, and O. Vinyals, “Listen, attend and spell,”arXiv preprint arXiv:1508.01211, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
D. Le, M. Jain, G. Keren, S. Kim, Y . Shi, J. Mahadeokar, J. Chan, Y . Shangguan, C. Fuegen, O. Kalinli et al. , “Contextualized streaming end-to-end speech recognition with trie-based deep bi- asing and shallow fusion,”Interspeech, 2021
work page 2021
-
[20]
Cif-based collabora- tive decoding for end-to-end contextual speech recognition,
M. Han, L. Dong, S. Zhou, and B. Xu, “Cif-based collabora- tive decoding for end-to-end contextual speech recognition,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6528– 6532
work page 2021
-
[21]
Contextual biasing speech recognition in speech-enhanced large language model,
X. Gong, A. Lv, Z. Wang, and Y . Qian, “Contextual biasing speech recognition in speech-enhanced large language model,” Proc. Interspeech. ISCA, pp. 257–261, 2024
work page 2024
- [22]
-
[23]
Available: https://github.com/jsvine/pdfplumber
[Online]. Available: https://github.com/jsvine/pdfplumber
-
[24]
Available: https://github.com/jiaaro/pydub
[Online]. Available: https://github.com/jiaaro/pydub
-
[25]
fairseq: A fast, extensible toolkit for sequence modeling,
M. Ott, S. Edunov, A. Baevski, A. Fan, S. Gross, N. Ng, D. Grang- ier, and M. Auli, “fairseq: A fast, extensible toolkit for sequence modeling,” in Proceedings of NAACL-HLT 2019: Demonstra- tions, 2019
work page 2019
-
[26]
FLAIR: An easy-to-use framework for state-of-the- art NLP,
A. Akbik, T. Bergmann, D. Blythe, K. Rasul, S. Schweter, and R. V ollgraf, “FLAIR: An easy-to-use framework for state-of-the- art NLP,” in NAACL 2019, 2019 Annual Conference of the North American Chapter of the Association for Computational Linguis- tics (Demonstrations), 2019, pp. 54–59
work page 2019
-
[27]
The double metaphone search algorithm,
L. Philips, “The double metaphone search algorithm,” C/C++ Users Journal, 2000
work page 2000
-
[28]
Jrc-names-retrieval: A standardized bench- mark for name search,
P. Blair and K. Bar, “Jrc-names-retrieval: A standardized bench- mark for name search,” in Proceedings of the 2024 Joint Interna- tional Conference on Computational Linguistics, Language Re- sources and Evaluation (LREC-COLING 2024), 2024, pp. 9589– 9603
work page 2024
-
[29]
F. Trias, H. Wang, S. Jaume, and S. Idreos, “Named entity recog- nition in historic legal text: A transformer and state machine en- semble method,” in Proceedings of the Natural Legal Language Processing Workshop 2021, 2021, pp. 172–179
work page 2021
-
[30]
Contextual spelling correction with language model for low-resource setting,
N. Luitel, N. Bekoju, A. K. Sah, and S. Shakya, “Contextual spelling correction with language model for low-resource setting,” in 2024 International Conference on Inventive Computation Tech- nologies (ICICT). IEEE, 2024, pp. 582–589
work page 2024
-
[31]
A large-scale evalua- tion of neural machine transliteration for indic languages,
A. Kunchukuttan, S. Jain, and R. Kejriwal, “A large-scale evalua- tion of neural machine transliteration for indic languages,” inPro- ceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , 2021, pp. 3469–3475
work page 2021
-
[32]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Let- man, A. Mathur, A. Schelten, A. Yang, A. Fan et al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
OpenAI, “Open ai. hello gpt-4o,” 2024. [Online]. Available: https://openai.com/index/hello-gpt-4o/
work page 2024
-
[34]
Efficient memory manage- ment for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory manage- ment for large language model serving with pagedattention,” in Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[35]
Available: https://github.com/langchain-ai/langchain
[Online]. Available: https://github.com/langchain-ai/langchain
-
[36]
Lan- guage models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhari- wal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Lan- guage models are few-shot learners,”Advances in neural informa- tion processing systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[37]
Available: https://platform.openai.com/docs/guides/ prompt-engineering
[Online]. Available: https://platform.openai.com/docs/guides/ prompt-engineering
-
[38]
NeMo: A Toolkit for Building AI Applications using Neural Modules,
O. Kuchaiev, J. Li, H. Nguyen, O. Hrinchuk, R. Leary, B. Gins- burg, S. Kriman, S. Beliaev, V . Lavrukhin, J. Cooket al., “Nemo: a toolkit for building ai applications using neural modules,”arXiv preprint arXiv:1909.09577, 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.