OISMA: On-the-fly In-memory Stochastic Multiplication Architecture for Matrix-Multiplication Workloads
Pith reviewed 2026-05-18 23:30 UTC · model grok-4.3
The pith
OISMA turns ordinary memory read operations into in-situ stochastic multiplications that complete matrix multiplications after bitstream accumulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
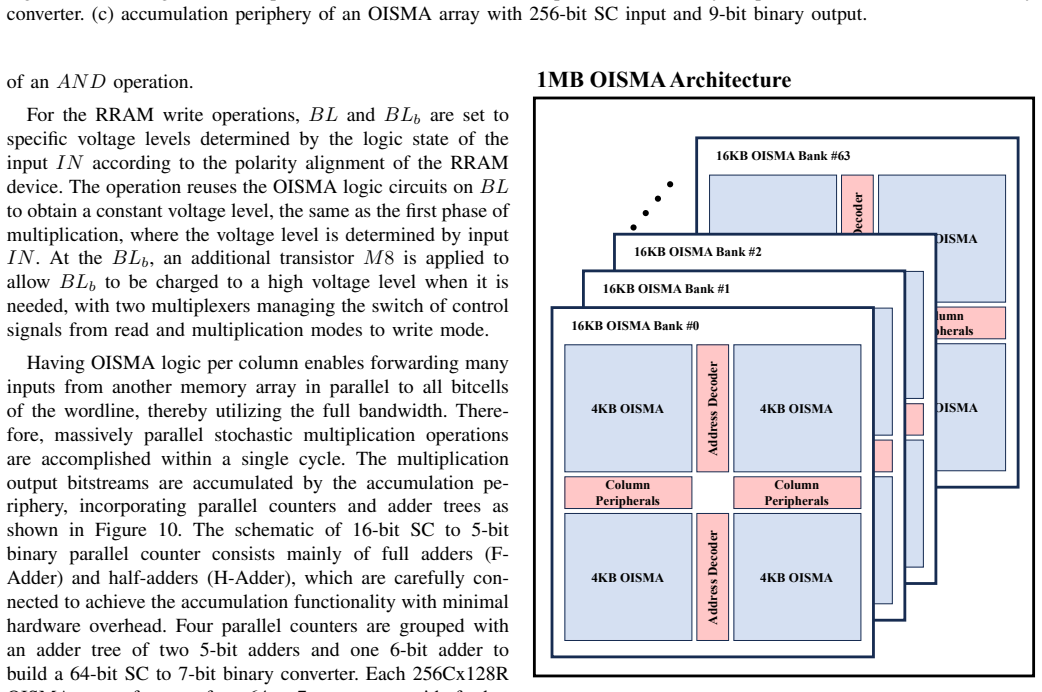
OISMA converts normal memory read operations into in situ stochastic multiplication operations with a negligible cost. An accumulation periphery then accumulates the output multiplication bitstreams, achieving the matrix multiplication (MatMul) functionality. A 4-kB 1T1R OISMA array was implemented using a commercial 180-nm technology node and in-house resistive random-access memory (RRAM) technology. At 50 MHz, it achieves 0.789 TOPS/W and 3.98 GOPS/mm2 for energy and area efficiency, respectively, occupying an effective computing area of 0.804241 mm2. Scaling OISMA to 22-nm technology shows a significant improvement of two orders of magnitude in energy efficiency and one order of magnitude
What carries the argument
The bent-pyramid quasi-stochastic computing domain that converts standard memory reads into stochastic multiplications inside a 1T1R RRAM array.
If this is right
- Matrix multiplications complete inside the memory array after ordinary reads produce stochastic bitstreams that an accumulation periphery sums.
- The 180-nm prototype reaches 0.789 TOPS/W and 3.98 GOPS/mm2 while occupying 0.804 mm2 of effective computing area.
- Moving the same design to 22-nm technology yields roughly 100 times better energy efficiency and 10 times better area efficiency than dense in-memory matrix-multiplication alternatives.
- The architecture keeps the fabrication and scaling advantages of conventional digital memories while adding matrix-multiplication capability.
Where Pith is reading between the lines
- Existing memory production lines could add this capability without new process steps or large redesigns.
- Accuracy on concrete neural-network models can be checked by running the same layer with and without the stochastic conversion.
- Power savings would be largest in edge devices where matrix multiplications dominate total energy use.
Load-bearing premise
The bent-pyramid quasi-stochastic computing domain preserves sufficient numerical accuracy for AI matrix-multiplication workloads while retaining the scalability and productivity of standard digital memories.
What would settle it
A side-by-side run of a representative neural-network layer in which the bent-pyramid stochastic results deviate from exact floating-point matrix multiplication by more than the error budget the target AI application can tolerate.
Figures











read the original abstract
Artificial intelligence (AI) models are currently driven by a significant upscaling of their complexity, with massive matrix-multiplication workloads representing the major computational bottleneck. In-memory computing (IMC) architectures are proposed to avoid the von Neumann bottleneck. However, both digital/binary-based and analog IMC architectures suffer from various limitations, which significantly degrade the performance and energy efficiency gains. This work proposes OISMA, an energy-efficient IMC architecture that utilizes the computational simplicity of a quasi-stochastic computing (SC) domain (bent-pyramid (BP) system) while keeping the same efficiency, scalability, and productivity of digital memories. OISMA converts normal memory read operations into in situ stochastic multiplication operations with a negligible cost. An accumulation periphery then accumulates the output multiplication bitstreams, achieving the matrix multiplication (MatMul) functionality. A 4-kB 1T1R OISMA array was implemented using a commercial 180-nm technology node and in-house resistive random-access memory (RRAM) technology. At 50 MHz, it achieves 0.789 TOPS/W and 3.98 GOPS/mm2 for energy and area efficiency, respectively, occupying an effective computing area of 0.804241 mm2. Scaling OISMA to 22-nm technology shows a significant improvement of two orders of magnitude in energy efficiency and one order of magnitude in area efficiency, compared to dense MatMul IMC architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OISMA, an in-memory computing architecture that performs stochastic multiplications in situ during normal memory read operations using a bent-pyramid quasi-stochastic computing domain, followed by peripheral accumulation of bitstreams to realize matrix multiplication. A fabricated 4-kB 1T1R array in 180-nm technology is measured at 50 MHz, reporting 0.789 TOPS/W and 3.98 GOPS/mm², with projections for 22-nm scaling showing gains over dense MatMul IMC designs.
Significance. If the bent-pyramid domain maintains adequate numerical fidelity for AI-scale workloads, OISMA could offer a practical bridge between digital memory productivity and in-memory computation, with the physical 1T1R implementation and measured results providing concrete evidence of feasibility. The approach avoids analog non-idealities while retaining scalability, but its significance for AI applications remains conditional on unshown accuracy properties.
major comments (1)
- [Abstract] Abstract: The central claim that OISMA achieves MatMul functionality for AI workloads via bent-pyramid quasi-SC relies on the assumption of sufficient numerical accuracy, yet the abstract (and reported results) supply no error metrics, no bitstream length vs. precision trade-offs, no comparison against FP32 reference MatMul on representative matrices, and no end-to-end network accuracy. This omission is load-bearing for the scalability assertion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that OISMA achieves MatMul functionality for AI workloads via bent-pyramid quasi-SC relies on the assumption of sufficient numerical accuracy, yet the abstract (and reported results) supply no error metrics, no bitstream length vs. precision trade-offs, no comparison against FP32 reference MatMul on representative matrices, and no end-to-end network accuracy. This omission is load-bearing for the scalability assertion.
Authors: We agree that the abstract, due to its length constraints, does not explicitly include numerical accuracy metrics or direct FP32 comparisons. The manuscript centers on the hardware implementation of in-memory stochastic multiplication via the bent-pyramid quasi-stochastic domain and reports measured efficiency results from the fabricated 4-kB 1T1R array. The full text explains how the bent-pyramid encoding and peripheral bitstream accumulation realize MatMul while preserving digital memory characteristics. To address the concern, we will revise the abstract to include a concise statement on the numerical fidelity of the approach and add a dedicated results subsection with error metrics, bitstream-length versus precision trade-offs, and FP32 reference comparisons on representative matrices. End-to-end accuracy on full AI networks lies outside the scope of this work, which demonstrates the core multiplication architecture and its physical realization rather than complete model evaluation. revision: partial
- End-to-end network accuracy evaluation on representative AI workloads
Circularity Check
No circularity; claims rest on physical implementation and measurement
full rationale
The paper describes a hardware architecture (OISMA) implemented as a 4 kB 1T1R array in 180 nm technology with RRAM, reporting directly measured metrics (0.789 TOPS/W, 3.98 GOPS/mm² at 50 MHz). No equations, fitted parameters, or predictions appear that reduce by construction to inputs; the bent-pyramid quasi-SC domain is presented as an adopted computational domain whose accuracy is asserted for AI workloads but not derived from self-referential steps within the paper. Central claims are externally falsifiable via fabrication and testing rather than any self-citation chain or definitional loop, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- Operating frequency
- Technology node
axioms (1)
- domain assumption The bent-pyramid quasi-stochastic domain converts memory reads into multiplications with negligible overhead while preserving digital memory scalability.
invented entities (1)
-
OISMA architecture
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
OISMA converts normal memory read operations into in situ stochastic multiplication operations with a negligible cost... Bent-Pyramid system... right-biased and left-biased bitstreams... bit-wise AND logic operations
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
accuracy results show a significant decrease in the average relative Frobenius error, from 9.42% (for 4x4) to 1.81% (for 512x512)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
DISCA: A Digital In-memory Stochastic Computing Architecture Using A Compressed Bent-Pyramid Format
DISCA achieves 3.59 TOPS/W per bit energy efficiency for matrix multiplication at 500 MHz in 180 nm CMOS using a compressed Bent-Pyramid stochastic format.
Reference graph
Works this paper leans on
-
[1]
Digital in-memory stochastic computing architecture for vector-matrix multiplication,
S. Agwa and T. Prodromakis, “Digital in-memory stochastic computing architecture for vector-matrix multiplication,” Frontiers in Nanotechnol- ogy, vol. 5, 2023
work page 2023
-
[2]
Bent-Pyramid: Towards a quasi-stochastic data representation for ai hardware,
S. Agwa and T. Prodromakis, “Bent-Pyramid: Towards a quasi-stochastic data representation for ai hardware,” in 2023 21st IEEE Interregional NEWCAS Conference (NEWCAS) , 2023, pp. 1–5
work page 2023
-
[3]
Fully hardware-implemented memristor convolutional neural network,
P. Yao et al. , “Fully hardware-implemented memristor convolutional neural network,” Nature 577, p. 641–646, 2020
work page 2020
-
[4]
A compute-in-memory chip based on resistive random- access memory,
W. Wan et al. , “A compute-in-memory chip based on resistive random- access memory,” Nature 608, p. 504–512, 2022
work page 2022
-
[5]
An overview of processing-in-memory circuits for artificial intelligence and machine learning,
D. Kim et al. , “An overview of processing-in-memory circuits for artificial intelligence and machine learning,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems , vol. 12, pp. 338–353, 2022
work page 2022
-
[6]
Challenges hindering memristive neuromorphic hardware from going mainstream,
G. C. Adam, A. Khiat, and T. Prodromakis, “Challenges hindering memristive neuromorphic hardware from going mainstream,” Nature Communications 9 , 2018
work page 2018
-
[7]
Q. Liu et al. , “A fully integrated analog ReRAM based 78.4TOPS/W compute-in-memory chip with fully parallel MAC computing,” in 2020 IEEE International Solid- State Circuits Conference - (ISSCC) , 2020, pp. 500–502
work page 2020
-
[8]
Rowclone: Fast and energy-efficient in-dram bulk data copy and initialization,
V . Seshadri et al. , “Rowclone: Fast and energy-efficient in-dram bulk data copy and initialization,” in International Symposium on Microar- chitecture (MICRO), 2013
work page 2013
-
[9]
A. Farmahini-Farahani, K. Ahn, J. H.and Morrow, and N. S. Kim, “Nda: Near-dram acceleration architecture leveraging commodity dram devices and standard memory modules,” in International Symposium on High- Performance Computer Architecture (HPCA) , 2015
work page 2015
-
[10]
High-density digital rram-based memory with bit-line compute capability,
S. Agwa, Y . Pan, T. Abbey, A. Serb, and T. Prodromakis, “High-density digital rram-based memory with bit-line compute capability,” in 2022 IEEE International Symposium on Circuits and Systems (ISCAS) , 2022, pp. 1199–1200
work page 2022
-
[11]
A configurable tcam/bcam/sram using 28nm push-rule 6t bit cell,
S. Jeloka, N. B. Akesh, D. Sylvester, and D. Blaauw, “A configurable tcam/bcam/sram using 28nm push-rule 6t bit cell,” in Symposium on V ery Large-Scale Integration Circuits (VLSIC) , 2015
work page 2015
-
[12]
Neural cache: Bit-serial in-cache acceleration of deep neural networks,
C. Eckert et al. , “Neural cache: Bit-serial in-cache acceleration of deep neural networks,” in International Symposium on Computer Architecture (ISCA), 2018
work page 2018
-
[13]
Duality cache for data parallel acceleration,
D. Fujiki, S. Mahlke, and R. Das, “Duality cache for data parallel acceleration,” in International Symposium on Computer Architecture (ISCA), 2019
work page 2019
-
[14]
K. Al-Hawaj, O. Afuye, S. Agwa, A. Apsel, and C. Batten, “Towards a reconfigurable bit-serial/bit-parallel vector accelerator using in-situ processing-in-sram,” in 2020 IEEE International Symposium on Circuits and Systems (ISCAS) , 2020
work page 2020
-
[15]
Eve: Ephemeral vector engines,
K. Al-Hawaj et al. , “Eve: Ephemeral vector engines,” in 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2023, pp. 691–704
work page 2023
-
[16]
Survey of stochastic computing,
A. Alaghi and J. P. Hayes, “Survey of stochastic computing,” ACM Trans. Embed. Comput. Syst. , vol. 12, no. 2s, May 2013
work page 2013
-
[17]
Stochastic circuits for real-time image-processing applications,
A. Alaghi, C. Li, and J. P. Hayes, “Stochastic circuits for real-time image-processing applications,” in Proceedings of the 50th Annual Design Automation Conference , ser. DAC ’13. New York, NY , USA: Association for Computing Machinery, 2013
work page 2013
-
[18]
Fast and accurate computation using stochastic circuits,
A. Alaghi and J. P. Hayes, “Fast and accurate computation using stochastic circuits,” in 2014 Design, Automation & Test in Europe Conference & Exhibition (DATE) , 2014, pp. 1–4
work page 2014
-
[19]
Winstead, Tutorial on Stochastic Computing
C. Winstead, Tutorial on Stochastic Computing . Cham: Springer International Publishing, 2019, pp. 39–76
work page 2019
-
[20]
Deterministic stochastic computation using parallel datapaths,
A. J. Groszewski and T. Lenz, “Deterministic stochastic computation using parallel datapaths,” in 20th International Symposium on Quality Electronic Design (ISQED) , 2019, pp. 138–144
work page 2019
-
[21]
The logic of random pulses: Stochastic computing,
A. Alaghi, “The logic of random pulses: Stochastic computing,” Ph.D. dissertation, University of Michigan, Ann Arbor, MI, USA, 2015
work page 2015
-
[22]
A parallel bitstream generator for stochastic comput- ing,
Y . Zhang et al. , “A parallel bitstream generator for stochastic comput- ing,” in 2019 Silicon Nanoelectronics Workshop (SNW) , 2019, pp. 1–2
work page 2019
-
[23]
Low-cost stochastic number generators for stochastic computing,
S. A. Salehi, “Low-cost stochastic number generators for stochastic computing,” IEEE Transactions on V ery Large Scale Integration (VLSI) Systems, vol. 28, no. 4, pp. 992–1001, April 2020
work page 2020
-
[24]
The promise and challenge of stochastic computing,
A. Alaghi, W. Qian, and J. P. Hayes, “The promise and challenge of stochastic computing,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , vol. 37, no. 8, pp. 1515–1531, August 2018
work page 2018
-
[25]
Parallel hybrid stochastic-binary-based neural network accelerators,
Y . Zhang, R. Wang, X. Zhang, Y . Wang, and R. Huang, “Parallel hybrid stochastic-binary-based neural network accelerators,” IEEE Transactions on Circuits and Systems II: Express Briefs , vol. 67, no. 12, pp. 3387– 3391, December 2020
work page 2020
-
[26]
P. Micikevicius et al. , “Fp8 formats for deep learning,” arXiv preprint arXiv:2209.05433, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Dip: A scalable, energy-efficient systolic array for matrix multiplication acceleration,
A. J. Abdelmaksoud, S. Agwa, and T. Prodromakis, “Dip: A scalable, energy-efficient systolic array for matrix multiplication acceleration,” IEEE Transactions on Circuits and Systems I, TCAS-I , 2025
work page 2025
-
[28]
Design flow for hybrid CMOS/memristor sys- tems—part i: Modeling and verification steps,
S. Maheshwari et al. , “Design flow for hybrid CMOS/memristor sys- tems—part i: Modeling and verification steps,” IEEE Transactions on Circuits and Systems I: Regular Papers , vol. 68, no. 12, pp. 4862–4875, 2021
work page 2021
-
[29]
A data-driven verilog-a ReRAM model,
I. Messaris, A. Serb, S. Stathopoulos, A. Khiat, S. Nikolaidis, and T. Prodromakis, “A data-driven verilog-a ReRAM model,”Trans. Comp.- Aided Des. Integ. Cir . Sys. , vol. 37, no. 12, p. 3151–3162, Dec. 2018
work page 2018
-
[30]
Eidetic: An in-memory matrix multiplication accelerator for neural networks,
C. Eckert, A. Subramaniyan, X. Wang, C. Augustine, R. Iyer, and R. Das, “Eidetic: An in-memory matrix multiplication accelerator for neural networks,” IEEE Transactions on Computers , vol. 72, no. 6, pp. 1539–1553, 2023
work page 2023
-
[31]
A 51.6TFLOPs/W full-datapath CIM macro approaching sparsity bound and <2-30 loss for compound AI,
Z. Yue et al., “A 51.6TFLOPs/W full-datapath CIM macro approaching sparsity bound and <2-30 loss for compound AI,” in 2025 IEEE International Solid-State Circuits Conference (ISSCC) , vol. 68, 2025, pp. 1–3
work page 2025
-
[32]
A 22nm 16Mb floating-point ReRAM compute-in- memory macro with 31.2TFLOPS/W for AI edge devices,
T.-H. Wen et al. , “A 22nm 16Mb floating-point ReRAM compute-in- memory macro with 31.2TFLOPS/W for AI edge devices,” in2024 IEEE International Solid-State Circuits Conference (ISSCC), vol. 67, 2024, pp. 580–582
work page 2024
-
[33]
D.-Q. You et al. , “A 22nm 104.5TOPS/W µ-NMC- ∆-IMC hetero- geneous STT-MRAM CIM macro for noise-tolerant bayesian neural networks,” in 2025 IEEE International Solid-State Circuits Conference (ISSCC), vol. 68, 2025, pp. 1–3
work page 2025
-
[34]
Scaling equations for the accurate prediction of CMOS device performance from 180 nm to 7 nm,
A. Stillmaker and B. Baas, “Scaling equations for the accurate prediction of CMOS device performance from 180 nm to 7 nm,” Integration, vol. 58, pp. 74–81, 2017
work page 2017
-
[35]
Deepscaletool: A tool for the accurate estimation of technology scaling in the deep-submicron era,
S. Sarangi and B. Baas, “Deepscaletool: A tool for the accurate estimation of technology scaling in the deep-submicron era,” in 2021 IEEE International Symposium on Circuits and Systems (ISCAS) , 2021, pp. 1–5. Shady Agwa (Member, IEEE) is a Research Fellow at the Centre for Electronics Frontiers CEF, The Uni- versity of Edinburgh (UK). He received his BS...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.