Knowledge is Not Enough: Injecting RL Skills for Continual Adaptation
Pith reviewed 2026-05-16 13:38 UTC · model grok-4.3
The pith
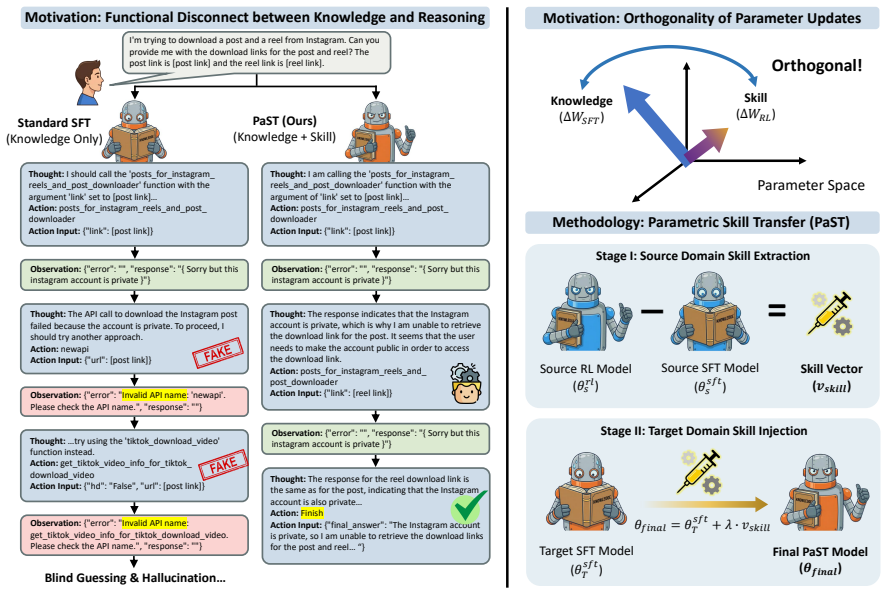
A domain-agnostic skill vector extracted from RL training can be linearly injected into SFT-adapted models to improve use of new knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Parametric Skill Transfer extracts a Skill Vector that encodes RL-acquired knowledge-manipulation abilities from a source domain. After a target model receives lightweight SFT on new data, the vector is added linearly to the parameters, transferring the skills without further reinforcement learning. On SQuAD this yields gains of up to 9.9 points over self-editing SFT baselines, on LooGLE it produces an 8.0-point absolute accuracy increase for long-context QA, and on ToolBench it raises zero-shot success rates by 10.3 points on average across tool categories.
What carries the argument
The Skill Vector, a directional representation of RL-induced parameter updates that captures domain-agnostic manipulation skills and supports linear injection into SFT models.
If this is right
- Outperforms state-of-the-art self-editing SFT baselines by up to 9.9 points on SQuAD knowledge-incorporation QA.
- Delivers an 8.0-point absolute accuracy gain on long-context QA in LooGLE.
- Raises zero-shot success rates on ToolBench by 10.3 points on average with consistent gains across tool categories.
- Demonstrates cross-domain transferability of the extracted Skill Vector for continual adaptation.
Where Pith is reading between the lines
- If the orthogonality observation generalizes, skill vectors computed once from representative RL runs could be reused across many successive knowledge domains without recomputing RL each time.
- The method suggests a path toward modular skill libraries in which separate vectors for different reasoning or tool-use patterns can be composed by simple addition.
- Continual adaptation pipelines could interleave lightweight SFT steps with occasional skill-vector injections, reducing total compute relative to full RL at every update.
Load-bearing premise
The parameter updates produced by supervised fine-tuning and by reinforcement learning remain nearly orthogonal so that adding the skill vector does not undo the new factual content.
What would settle it
Experiments in which the cosine similarity between SFT and RL update vectors deviates substantially from zero, or in which linear injection of the skill vector produces no improvement or a performance drop on downstream tasks that require reasoning over the newly added facts.
Figures



read the original abstract
Large Language Models (LLMs) face the "knowledge cutoff" challenge, where their frozen parametric memory prevents direct internalization of new information. While Supervised Fine-Tuning (SFT) is commonly used to update model knowledge, it often updates factual content without reliably improving the model's ability to use the newly incorporated information for question answering or decision-making. Reinforcement Learning (RL) is essential for acquiring reasoning skills; however, its high computational cost makes it impractical for efficient online adaptation. We empirically observe that the parameter updates induced by SFT and RL are nearly orthogonal. Based on this observation, we propose Parametric Skill Transfer (PaST), a framework that supports modular skill transfer for efficient and effective knowledge adaptation. By extracting a domain-agnostic Skill Vector from a source domain, we can linearly inject knowledge manipulation skills into a target model after it has undergone lightweight SFT on new data. Experiments on knowledge-incorporation QA (SQuAD, LooGLE) and agentic tool-use benchmarks (ToolBench) demonstrate the effectiveness of our method. On SQuAD, PaST outperforms the state-of-the-art self-editing SFT baseline by up to 9.9 points. PaST further scales to long-context QA on LooGLE with an 8.0-point absolute accuracy gain, and improves zero-shot ToolBench success rates by +10.3 points on average with consistent gains across tool categories, indicating strong scalability and cross-domain transferability of the Skill Vector.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that SFT and RL parameter updates are nearly orthogonal, allowing extraction of a domain-agnostic Skill Vector from source-domain RL that can be linearly injected into a target LLM after lightweight SFT on new data. This Parametric Skill Transfer (PaST) framework is shown to improve knowledge manipulation on SQuAD (up to +9.9 points), LooGLE (+8.0 points), and ToolBench (+10.3 points average) over self-editing SFT baselines.
Significance. If the orthogonality generalizes and the linear injection avoids interference, the method offers a modular, low-cost route to continual adaptation that separates cheap knowledge updates from reusable skill vectors, with demonstrated cross-domain transfer on QA and agentic benchmarks.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the central orthogonality claim is stated but no cosine-similarity values, layer-wise breakdowns, or explicit metrics are provided for the source-domain observation; more critically, no test confirms that the same near-orthogonality holds after the target-domain SFT step, which is required for the linear Skill Vector injection to remain non-destructive.
- [§4] §4 (experiments): reported gains lack error bars, details on statistical significance, or ablations isolating the contribution of the orthogonality assumption versus other factors; without these, the cross-benchmark improvements cannot be confidently attributed to the proposed mechanism.
minor comments (2)
- [§3] Notation for the Skill Vector extraction and injection formula should be clarified with an explicit equation in the method section to avoid ambiguity in how the vector is computed and scaled.
- [Abstract] The abstract mentions 'nearly orthogonal' without quantifying the threshold; a precise definition or range would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for improving the presentation of our core orthogonality observation and the rigor of the experimental results. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central orthogonality claim is stated but no cosine-similarity values, layer-wise breakdowns, or explicit metrics are provided for the source-domain observation; more critically, no test confirms that the same near-orthogonality holds after the target-domain SFT step, which is required for the linear Skill Vector injection to remain non-destructive.
Authors: We agree that explicit quantitative support for the orthogonality claim is required. In the revised manuscript we will add cosine-similarity values between SFT and RL parameter updates together with layer-wise breakdowns for the source domain. We will also include a direct verification that near-orthogonality is preserved after target-domain SFT by reporting the cosine similarity between the extracted skill vector and the target SFT updates, thereby confirming that linear injection remains non-destructive. revision: yes
-
Referee: [§4] §4 (experiments): reported gains lack error bars, details on statistical significance, or ablations isolating the contribution of the orthogonality assumption versus other factors; without these, the cross-benchmark improvements cannot be confidently attributed to the proposed mechanism.
Authors: We accept that the experimental reporting needs greater statistical rigor and targeted ablations. The revision will add error bars from multiple random seeds, report p-values for statistical significance on the reported gains, and include ablations that replace the skill vector with random or zero vectors to isolate the contribution of the orthogonality-based transfer. These changes will allow clearer attribution of the observed improvements to the PaST mechanism. revision: yes
Circularity Check
No significant circularity; empirical method with independent source extraction
full rationale
The paper's core claim rests on an empirical observation that SFT and RL parameter updates are nearly orthogonal, used to extract a Skill Vector from a separate source-domain RL run and linearly inject it post-target SFT. No equations, derivations, or self-citations reduce this to a fitted quantity defined by the target data itself. The Skill Vector computation and evaluation occur on disjoint benchmarks (SQuAD, LooGLE, ToolBench), with no self-definitional loops, renamed known results, or load-bearing self-citations. The approach is self-contained via direct empirical validation rather than circular construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parameter updates induced by SFT and RL are nearly orthogonal.
invented entities (1)
-
Skill Vector
no independent evidence
Forward citations
Cited by 1 Pith paper
-
SHINE: A Scalable In-Context Hypernetwork for Mapping Context to LoRA in a Single Pass
SHINE trains a scalable in-context hypernetwork to generate high-quality LoRA adapters from contexts in one pass, enabling efficient LLM adaptation that saves time and compute compared to standard fine-tuning.
Reference graph
Works this paper leans on
-
[1]
Jeffrey Cheng, Marc Marone, Orion Weller, Dawn Lawrie, Daniel Khashabi, and Benjamin Van Durme
Adapting large language models to do- mains via reading comprehension.arXiv preprint arXiv:2309.09530. Jeffrey Cheng, Marc Marone, Orion Weller, Dawn Lawrie, Daniel Khashabi, and Benjamin Van Durme
-
[2]
Dated data: Tracing knowledge cutoffs in large language models.arXiv preprint arXiv:2403.12958, 2024
Dated data: Tracing knowledge cutoffs in large language models.arXiv preprint arXiv:2403.12958. Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Sheng- bang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. 2025. Sft mem- orizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161. Guodong Du...
-
[3]
LIFT: A Novel Framework for Enhancing Long-Context Understanding of LLMs via Long Input Fine-Tuning
Ttt++: When does self-supervised test-time training fail or thrive?Advances in Neural Informa- tion Processing Systems, 34:21808–21820. Yansheng Mao, Yufei Xu, Jiaqi Li, Fanxu Meng, Hao- tong Yang, Zilong Zheng, Xiyuan Wang, and Muhan Zhang. 2025. Lift: Improving long context under- standing of large language models through long input fine-tuning.arXiv pr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Achieving human parity in content-grounded datasets generation. InInternational Conference on Learning Representations. Mohammad Zbeeb, Hasan Abed Al Kader Hammoud, and Bernard Ghanem. 2025. Reasoning vectors: Transferring chain-of-thought capabilities via task arithmetic.arXiv preprint arXiv:2509.01363. Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek,...
-
[5]
Manifold Alignment of Knowledge:Tasks of the same nature (injecting declarative facts) tend to modify the model parameters along a shared or aligned subspace, resulting in non- zero cosine similarity
-
[6]
link": [post link]} Observation: {
Validation of Disentanglement:The fact that ∆WSFT vs. ∆WSFT shows correlation while ∆WRL vs. ∆WSFT does not confirms that the orthogonality observed in our main result is a genuine property of the Knowledge-Skill de- composition, rather than a geometric triviality. C Theoretical Proof of Functional Disentanglement In Section 3.2, we empirically observed t...
-
[7]
Parameter Orthogonality:Based on our em- pirical observations, we assume ⟨A, B⟩F = Tr(AB⊤)≈0
-
[8]
Isotropic Inputs:We assume the input activa- tions x are zero-centered and quasi-isotropic, with covariance proportional to the identity matrix. This is a common property in Trans- formers facilitated by LayerNorm (Ba et al., 2016): E[x⊤x] =σ 2I(1) whereσ 2 is the variance of the activations. C.2 Derivation of Signal Orthogonality We investigate the inter...
work page 2016
-
[9]
Expectation of Signal Overlap.The expected inner product of the generated signals over the data distribution is: E[⟨u, v⟩] =E[uv ⊤] =E[(xA)(xB) ⊤] =E[xAB ⊤x⊤](2) Using the property that the trace of a scalar is the scalar itself (Tr(c) =c ) and the cyclic property of the trace (Tr(XY Z) =Tr(Y ZX)): E[xAB⊤x⊤] =E[Tr(xAB ⊤x⊤)] =E[Tr(AB ⊤x⊤x)] =Tr(AB ⊤E[x⊤x])...
-
[10]
Concentration in High Dimensions.While the expectation is zero, we must ensure that the variance is low enough such that the overlap is min- imal forany individual input x. This is guaranteed by theConcentration of Measurephenomenon in high-dimensional spaces (Vershynin, 2018). Let M=AB ⊤. Consider the quadratic form Y=xM x ⊤. For a random vector x with i...
work page 2018
-
[11]
Initialize skill vectorv 0 ←0
-
[12]
, K(hereK= 2): (a) (Knowledge injection / SFT)Train θsft k ← SFT(θ base,D src k )
For each roundk= 1, . . . , K(hereK= 2): (a) (Knowledge injection / SFT)Train θsft k ← SFT(θ base,D src k ). (b) (Skill carryover)Initialize RL policy θinit k ← θsft k +v k−1. (c) (Skill acquisition / RL)Train θrl k ←GRPO(θ init k ,Q(D src k )), where re- wards are computed by GPT-4.1 judging answer correctness (Appendix D.4). (d)(Skill extraction)Updatev...
-
[13]
Output final skill vectorv ⋆ ←v K. D.1 PaST Training Pipeline on Closed-Book SQuAD Data used for skill distillation.To distill a domain-specificproceduralskill for parametric knowledge retrieval, we construct a source corpus Dsrc consisting of K= 2 rounds of SQuAD con- texts, each with N= 50 documents, matching the data budget used in SEAL. We denote the ...
work page 2067
-
[14]
SFT Phase 1 (Knowledge Encoding):High learning rate training on the mixed dataset (Summarization, Recall, Verbatim) to enforce document memorization
-
[15]
SFT Phase 2 (QA Adaptation):Lower learn- ing rate training specifically on the synthetic QA pairs to bridge the gap to the RL format
-
[16]
RL Phase (Skill Sharpening):GRPO train- ing to refine the retrieval logic. Checkpoint Selection Strategy.To avoid over- fitting to the source documents, we employ an inde- pendent validation set consisting of LooGLE docu- ments with indices 90-94. We evaluate checkpoints every 40 steps. Based on the validation accuracy, we selected the checkpoint atStep 1...
-
[17]
**Generate one Q&A pair** based *only* on the provided text
-
[18]
**Specificity is Key:** The question *must* be self-contained and unambiguous. It must include specific names or key terms from the text (e.g., "What is ’Project Helios’?" instead of "What is this project?")
-
[19]
Do not include any other text before or after the tags
**Format:** Your output *must* use XML-style tags: <question>Your question here</question> <answer>Your answer here</answer>. Do not include any other text before or after the tags
-
[20]
[Specific Task Instruction: Refer to Variations 1-6 below] **Example of a Good, Specific Q&A:** [Task-specific Example: Refer to Variations 1-6 below] **Text Fragment:** {text_segment} **Your Output:** Variation 1: Factual Detail
-
[21]
**Task:** Focus on a specific, factual detail: a name, a date, a key term, or a specific component. **Example of a Good, Specific Q&A:** <question> What consensus mechanism does the ’Helios’ architecture pioneer? </question> <answer> It pioneers a decentralized consensus mechanism called ’Proof-of-History’ (PoH). </answer> Variation 2: Reasoning (Why/How)
-
[22]
APIs" column denotes the number of unique API schemas the model must internalize, and the
**Task:** Focus on the *reason* (Why) or the *method* (How) behind a concept or event described in the text. **Example of a Good, Specific Q&A:** <question> Why does the ’Proof-of-History’ (PoH) mechanism successfully reduce latency? </question> <answer> Because it creates a verifiable, sequential record of time, which avoids the need for solving complex ...
work page 2025
-
[23]
**Task:** Generate a "What is..." or "What does... stand for?" question about a key concept. **Example of a Good, Specific Q&A:** <question> What is ’Proof-of-History’ (PoH) as described in the context of the ’Helios’ architecture? </question> <answer> It is a decentralized consensus mechanism that creates a verifiable, sequential record of time. </answer...
-
[24]
**Task:** Focus on the *difference* or *similarity* between two specific concepts, methods, or entities in the text. **Example of a Good, Specific Q&A:** <question> What is the key difference between the ’Proof-of-History’ (PoH) mechanism and ’Proof-of-Work’ (PoW)? </question> <answer> ’Proof-of-History’ (PoH) creates a verifiable, sequential record of ti...
-
[25]
**Task:** Generate a question that asks to list steps, components, or stages of a specific system or method. **Example of a Good, Specific Q&A:** <question> What are the three main stages of the ’Project Nova’ deployment pipeline? </question> <answer> The three main stages are ’Build’, ’Test’, and ’Verify’. </answer> Variation 6: Significance/Impact
-
[26]
**Task:** Generate a "What is the significance of..." or "What is the main advantage of..." question. **Example of a Good, Specific Q&A:** <question> What is the main advantage of the ’Helios’ architecture’s ’Proof-of-History’ mechanism? </question> <answer> Its main advantage is a drastic reduction in latency. </answer> Table 11:QA Generation Prompts (Pa...
-
[27]
**Thought**: Analyze the current status and determine the next logical step
-
[28]
**Action**: Select the appropriate tool to execute that step and output the function name directly
-
[29]
**Action Input**: Provide the arguments for the tool as a STRICT valid JSON object. Output Format: Thought: <your reasoning> Action: <function_name> Action Input: <function_arguments_as_a_valid_JSON_object> After the action is executed, you will receive the result (’Observation: <observation>’). Based on the new state, continue the loop until the task is ...
-
[30]
Action" output must be the EXACT name of the function. Do NOT include parentheses ‘()‘, words like
**Action Field**: The "Action" output must be the EXACT name of the function. Do NOT include parentheses ‘()‘, words like "call" or "use", or any punctuation
-
[31]
**Finishing**: You MUST call the "Finish" function to submit your final answer. Available Tools:
-
[32]
You must rely on your **internal knowledge** to recall the correct parameter schemas for these tools
**General Tools**: You have been trained on a specific set of APIs: {api_names}. You must rely on your **internal knowledge** to recall the correct parameter schemas for these tools
-
[33]
**Termination Tool**: You MUST use the following tool to finish the task. Its definition is provided below: {"name": "Finish", "description": "If you believe that you have obtained a result that can answer the task, please call this function to provide the final answer. Remember: you must ALWAYS call this function at the end of your attempt, and the only ...
work page 2048
-
[34]
**Analyze:** Read the ‘API Documentation‘ to understand the schema and constraints (types, required fields)
-
[35]
- Are all ‘required_parameters‘ present? - Do the data types match (e.g., string vs int)?
**Validate:** Check the ‘API Input‘ against the ‘API Documentation‘. - Are all ‘required_parameters‘ present? - Do the data types match (e.g., string vs int)?
-
[36]
**Execute:** - **If Valid:** Generate a realistic, rich JSON response. - **If Invalid:** Generate a JSON response where ‘error‘ describes the specific validation failure. ### 3. Output Format You must output ONLY a valid JSON object. No Markdown code blocks. No conversational text. **JSON Schema:** { "error": "String describing the error (if any), otherwi...
-
[37]
**Solved**: The tool calls were successful. The final answer is strictly grounded in the real "Observation" data and fully addresses the query
-
[38]
**Partially Solved**: The model used real "Observation" data, but the task is only halfway finished or the final answer missed some details from the observations
-
[39]
reason": A very brief explanation (less than 20 words). -
**Unsolved**: - The model fabricated information not found in the Observations. - The tool calls failed, and the model failed to solve the query or made up a result. - The answer is incorrect or irrelevant. Output a JSON object with the following fields: - "reason": A very brief explanation (less than 20 words). - "answer_status": One of ["Solved", "Parti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.