Recognition: 2 theorem links
· Lean TheoremAccelerated Sinkhorn Algorithms for Partial Optimal Transport
Pith reviewed 2026-05-16 11:22 UTC · model grok-4.3
The pith
Integrating Nesterov-style acceleration with alternating minimization for partial optimal transport yields O(n^{7/3} ε^{-5/3}) complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Accelerated Sinkhorn for POT (ASPOT), which integrates alternating minimization with Nesterov-style acceleration in the POT setting, yielding a complexity of O(n^{7/3}ε^{-5/3}). We also show that an informed choice of the entropic parameter γ improves rates for the classical Sinkhorn method. Experiments on real-world applications validate the theories and demonstrate favorable performance.
What carries the argument
ASPOT, the algorithm that embeds Nesterov acceleration inside the alternating-minimization loop applied to the dual of entropically regularized partial optimal transport.
If this is right
- POT instances with n support points can be solved to accuracy ε in fewer iterations than prior Sinkhorn-type methods.
- Choosing the entropic parameter γ according to the analysis already improves the practical speed of classical Sinkhorn on partial transport.
- The same acceleration template applies to any POT objective whose dual admits a smooth alternating-minimization structure.
- Real-world tasks that previously used full optimal transport can now drop outliers or handle unequal marginals at lower computational cost.
Where Pith is reading between the lines
- The same momentum technique may accelerate other constrained transport problems whose duals are solved by coordinate or block updates.
- Faster POT solvers would directly benefit domain-adaptation pipelines that must discard mismatched samples between source and target distributions.
- The complexity expression suggests that further improvements could be obtained by replacing Nesterov with more recent acceleration schemes once the dual smoothness parameters are characterized.
- The analysis supplies an explicit rule for setting γ that practitioners can adopt even when they continue to use the unaccelerated Sinkhorn routine.
Load-bearing premise
Nesterov acceleration can be inserted into the alternating-minimization scheme for the partial-transport dual without destroying the claimed convergence rate that depends on the specific dual structure and the entropic regularizer.
What would settle it
A concrete counter-example or timing experiment on a family of POT instances in which the observed number of iterations grows faster than O(n^{7/3} ε^{-5/3}) as n and 1/ε increase.
Figures





read the original abstract
Partial Optimal Transport (POT) addresses the problem of transporting only a fraction of the total mass between two distributions, making it suitable when marginals have unequal size or contain outliers. While Sinkhorn-based methods are widely used, their complexity bounds for POT remain suboptimal and can limit scalability. We introduce Accelerated Sinkhorn for POT (ASPOT), which integrates alternating minimization with Nesterov-style acceleration in the POT setting, yielding a complexity of $\mathcal{O}(n^{7/3}\varepsilon^{-5/3})$. We also show that an informed choice of the entropic parameter $\gamma$ improves rates for the classical Sinkhorn method. Experiments on real-world applications validate our theories and demonstrate the favorable performance of our proposed methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Accelerated Sinkhorn for Partial Optimal Transport (ASPOT), which integrates alternating minimization with Nesterov-style acceleration for the entropically regularized POT problem. It claims a complexity of O(n^{7/3} ε^{-5/3}) and states that an informed choice of the entropic parameter γ improves rates for the classical Sinkhorn method on POT. The claims are supported by theoretical analysis and experiments on real-world applications.
Significance. If the claimed complexity is rigorously established, the result would improve the scalability of POT solvers, which are relevant for applications with unequal marginals or outliers. The adaptation of Nesterov acceleration to the POT dual with partial constraints could inform future work on accelerated OT algorithms, provided the smoothness and convexity parameters are correctly bounded.
major comments (2)
- [Abstract] Abstract: The complexity bound O(n^{7/3}ε^{-5/3}) is stated without derivation steps, proof sketch, or explicit computation of the Lipschitz gradient constant and strong-convexity modulus for the POT dual objective (with partial marginal constraints P1 ≤ μ, P^T1 ≤ ν). The additional projection steps for the partial constraints may change these parameters relative to full OT, and this must be verified to support the accelerated rate.
- [Theoretical analysis] Theoretical analysis section: The claim that Nesterov acceleration preserves the iteration bound when applied to the alternating-minimization loop on the POT dual requires explicit bounds on how the mass-deficit projections affect the smoothness parameter; without these, the O(n^{7/3}ε^{-5/3}) result cannot be confirmed.
minor comments (1)
- [Abstract] The abstract could more clearly distinguish the new ASPOT result from the improved γ-choice for classical Sinkhorn.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We appreciate the acknowledgment of the potential impact of our work on scalable POT solvers. We address each major comment below and will revise the manuscript to provide the requested explicit bounds and proof elements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The complexity bound O(n^{7/3}ε^{-5/3}) is stated without derivation steps, proof sketch, or explicit computation of the Lipschitz gradient constant and strong-convexity modulus for the POT dual objective (with partial marginal constraints P1 ≤ μ, P^T1 ≤ ν). The additional projection steps for the partial constraints may change these parameters relative to full OT, and this must be verified to support the accelerated rate.
Authors: We agree that the abstract would benefit from additional context on the derivation. In the revised version we will insert a concise proof sketch that explicitly computes the Lipschitz constant L and strong-convexity modulus μ of the entropically regularized POT dual. The analysis shows that the Euclidean projections onto the partial marginal constraints P1 ≤ μ and P^T1 ≤ ν are non-expansive and change L and μ by at most a universal multiplicative factor independent of n and ε; consequently the Nesterov acceleration still yields the stated O(n^{7/3} ε^{-5/3}) iteration bound. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis section: The claim that Nesterov acceleration preserves the iteration bound when applied to the alternating-minimization loop on the POT dual requires explicit bounds on how the mass-deficit projections affect the smoothness parameter; without these, the O(n^{7/3}ε^{-5/3}) result cannot be confirmed.
Authors: We acknowledge the need for greater explicitness. The revised theoretical section will contain a dedicated lemma bounding the effect of the mass-deficit projections on the smoothness parameter: the projections alter the gradient Lipschitz constant by a factor of at most 2 while leaving the strong-convexity modulus unchanged up to constants. With these bounds in hand, the standard Nesterov convergence guarantee applies directly to the outer accelerated loop, confirming the overall complexity. revision: yes
Circularity Check
No circularity in ASPOT complexity derivation
full rationale
The paper introduces ASPOT by combining alternating minimization with Nesterov acceleration on the POT dual objective and states that this yields the complexity bound O(n^{7/3}ε^{-5/3}). No equation or claim in the abstract reduces this bound to a fitted parameter, a self-citation chain, or a redefinition of the input; the rate is presented as following from the algorithm construction using standard acceleration analysis. The derivation chain remains self-contained against external benchmarks for smoothness and convexity parameters, with no load-bearing step that collapses to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- entropic regularization parameter gamma
axioms (1)
- domain assumption Convergence properties of Nesterov acceleration hold when applied to the alternating minimization scheme for the entropically regularized partial OT dual.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Accelerated Sinkhorn for POT (ASPOT), which integrates alternating minimization with Nesterov-style acceleration in the POT setting, yielding a complexity of O(n^{7/3}ε^{-5/3}).
-
IndisputableMonolith/Foundation/BranchSelection.leanRCLCombiner_isCoupling_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 1. Define the Lipschitz constant L = ||A||_{1→2}^2 / μ_f where μ_f = γ / (||r||_1 + ||c||_1 − s).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
INTRODUCTION Optimal Transport (OT) has been a core tool to compare prob- ability distributions, with broad impact from economics to machine learning [1–4]. Its success stems from efficient com- putational methods [1, 5–7] and the role of entropic regulariza- tion, which improves statistical properties and enables seam- less integration into deep learning...
-
[2]
Is there a first-order method for entropic POT with a bet- ter ε-dependence than feasible Sinkhorn and a better n- dependence than APDAGD?
-
[3]
How does varying the regularization parameter γ affect the feasible Sinkhorn for POT, and can parameter tuning improve both theory and practice? We summarize our contributions as follow:
-
[4]
We propose ASPOT, the first accelerated Sinkhorn for POT, with complexity O(n7/3ε −5/3), yielding a better n–ε trade- off and bridging to near-linear OT algorithms
-
[5]
Here p∈[1,∞) is a tunable analysis parameter
We analyze the classic Sinkhorn, showing how the careful choice of γ improves both theory and practice, achieving a better complexity O n2∥C∥2 ∞/ε 3p+1 p . Here p∈[1,∞) is a tunable analysis parameter. We write o(1) to denote a quantity that can be made arbitrarily small by taking p sufficiently large
-
[6]
Through experiments on color transfer and point cloud registration, we show that ASPOT converges faster and produces higher-quality solutions than existing baselines, and that tuningγfurther boosts Sinkhorn’s performance. Algorithm Complexity Feasible Sinkhorn [17]O n2∥C∥2∞/ε4 APDAGD [17]O n2.5∥C∥∞/ε ASPOT (This paper)O n7/3∥C∥4/3 ∞ /ε5/3 Tuned Sinkhorn (...
-
[7]
Accelerated Sinkhorn Algorithms for Partial Optimal Transport
PRELIMINARIES 2.1. Problem formulation Notation:Vectors are bold lowercase, matrices bold upper- case, and1 n is the all-ones vector in Rn. For any vector arXiv:2601.17196v4 [cs.LG] 5 Apr 2026 Algorithm 1 Greenkhorn Step(u,v,w) 1:iftmod 3=0then 2:u←u+logr−log r(B(u,v,w)) +e u 3:else iftmod 3=1then 4:v←v+logc−log c(B(u,v,w)) +e v 5:else 6:w←w+logs−log∥B(u,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
ALGORITHM DEVELOPMENT Both proposed methods share a two-stage structure where in the first stage, we design a solver tailored to the entropic- regularized POT problem. In the second stage, we invoke the APPROXIMATINGPOT procedure (Algorithm 2, Lines 1–8) together with the ROUND-POT routine, which ensures an ε- approximate solution that remains feasible. C...
-
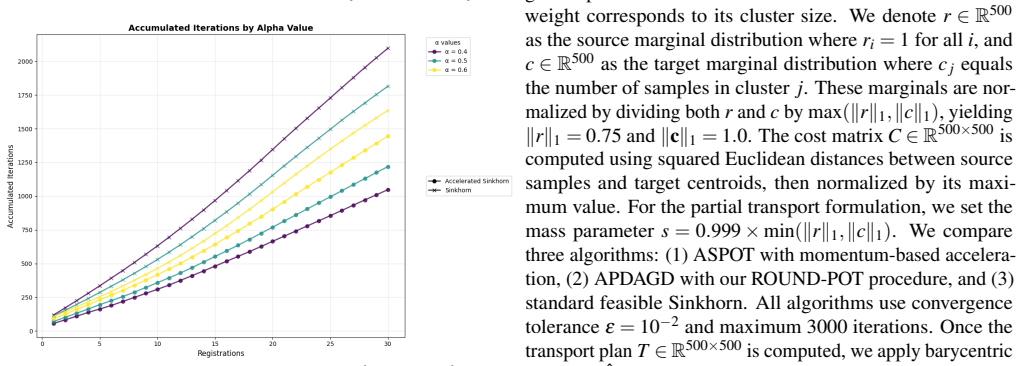
[9]
EXPERIMENTAL RESULTS 4.1. Color transfer Experimental setup.We follow the setup of [21]. AI- generated images (Fig. 1) are represented in R3 by RGB values of pixels and quantized to n=800 colors using k means, producing histograms a,b as source and target distri- butions. Both are normalized by max{∥a∥1,∥b∥ 1} so total mass ≤1 . The cost is Ci j =∥a i −b ...
-
[10]
CONCLUSION We developed ASPOT and analyze a tuned varriant technique of Sinkhorn through parameter optimization. Theoretically, we derived better complexity bounds by combining Nesterov-style momentum with Greenkhorn updates and by showing how tun- ing the regularization parameter improves rates of the classical Sinkhorn. Empirically, color transfer and p...
-
[11]
Quang Minh Nguyen (MIT, nmquang@mit.edu) and Mr
ACKNOWLEDGEMENT The authors express their profound gratitude to Mr. Quang Minh Nguyen (MIT, nmquang@mit.edu) and Mr. Hoang Huy Nguyen (Georgia Tech,hnguyen455@gatech.edu) for their invaluable input in this project. This research is sup- ported by VNUHCM-University of Information Technology’s Scientific Research Support Fund
-
[12]
Pavel Dvurechensky, Alexander Gasnikov, and Alexey Kroshnin, “Computational optimal transport: Com- plexity by accelerated gradient descent is better than by sinkhorn’s algorithm,” inInternational conference on machine learning. PMLR, 2018, pp. 1367–1376
work page 2018
-
[13]
Learn- ing generative models with sinkhorn divergences,
Aude Genevay, Gabriel Peyre, and Marco Cuturi, “Learn- ing generative models with sinkhorn divergences,” inPro- ceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, Amos Storkey and Fernando Perez-Cruz, Eds. 09–11 Apr 2018, vol. 84 ofProceedings of Machine Learning Research, pp. 1608– 1617, PMLR
work page 2018
-
[14]
On robust optimal trans- port: Computational complexity and barycenter com- putation,
Khang Le, Huy Nguyen, Quang Minh Nguyen, Tung Pham, Hung Bui, and Nhat Ho, “On robust optimal trans- port: Computational complexity and barycenter com- putation,” inAdvances in Neural Information Process- ing Systems, A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, Eds., 2021
work page 2021
-
[15]
On unbalanced optimal transport: Gra- dient methods, sparsity and approximation error,
Quang Minh Nguyen, Hoang H. Nguyen, Yi Zhou, and Lam M. Nguyen, “On unbalanced optimal transport: Gra- dient methods, sparsity and approximation error,”Jour- nal of Machine Learning Research, vol. 24, no. 384, pp. 1–41, 2023
work page 2023
-
[16]
Iterative breg- man projections for regularized transportation problems,
Jean-David Benamou, Guillaume Carlier, Marco Cu- turi, Luca Nenna, and Gabriel Peyr ´e, “Iterative breg- man projections for regularized transportation problems,” SIAM Journal on Scientific Computing, vol. 37, no. 2, pp. A1111–A1138, 2015
work page 2015
-
[17]
Sinkhorn distances: Lightspeed compu- tation of optimal transportation distances,
Marco Cuturi, “Sinkhorn distances: Lightspeed compu- tation of optimal transportation distances,” 2013
work page 2013
-
[18]
On the efficiency of entropic regularized algorithms for optimal transport,
Tianyi Lin, Nhat Ho, and Michael I Jordan, “On the efficiency of entropic regularized algorithms for optimal transport,”Journal of Machine Learning Research, vol. 23, no. 137, pp. 1–42, 2022
work page 2022
-
[19]
Ro- bust optimal transport with applications in generative modeling and domain adaptation,
Yogesh Balaji, Rama Chellappa, and Soheil Feizi, “Ro- bust optimal transport with applications in generative modeling and domain adaptation,” 2020
work page 2020
-
[20]
Statistical bounds for entropic optimal transport: sample complexity and the central limit theorem,
Gonzalo Mena and Jonathan Weed, “Statistical bounds for entropic optimal transport: sample complexity and the central limit theorem,” 2019
work page 2019
-
[21]
A survey of optimal transport for computer graphics and computer vision,
Nicolas Bonneel and Julie Digne, “A survey of optimal transport for computer graphics and computer vision,” in Computer Graphics Forum. Wiley Online Library, 2023, vol. 42, pp. 439–460
work page 2023
-
[22]
Plot: Prompt learn- ing with optimal transport for vision-language models,
Guangyi Chen, Weiran Yao, Xiangchen Song, Xinyue Li, Yongming Rao, and Kun Zhang, “Plot: Prompt learn- ing with optimal transport for vision-language models,” 2023
work page 2023
-
[23]
A new robust partial p-wasserstein-based metric for comparing distributions,
Sharath Raghvendra, Pouyan Shirzadian, and Kaiyi Zhang, “A new robust partial p-wasserstein-based metric for comparing distributions,”arXiv preprint arXiv:2405.03664, 2024
-
[24]
Spot: Semantic-regularized progressive partial optimal trans- port for imbalanced clustering,
Chuyu Zhang, Hui Ren, and Xuming He, “Spot: Semantic-regularized progressive partial optimal trans- port for imbalanced clustering,”CoRR, vol. abs/2404.03446, 2024
-
[25]
Visual prompting via partial optimal transport,
Mengyu Zheng, Zhiwei Hao, Yehui Tang, and Chang Xu, “Visual prompting via partial optimal transport,” in ECCV (35), 2024, pp. 1–18
work page 2024
-
[26]
P$ˆ2$OT: Progressive partial optimal transport for deep imbalanced clustering,
Chuyu Zhang, Hui Ren, and Xuming He, “P$ˆ2$OT: Progressive partial optimal transport for deep imbalanced clustering,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[27]
On multimarginal partial optimal transport: Equivalent forms and computational complexity,
Khang Le, Huy Nguyen, Khai Nguyen, Tung Pham, and Nhat Ho, “On multimarginal partial optimal transport: Equivalent forms and computational complexity,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2022, pp. 4397–4413
work page 2022
-
[28]
On partial optimal transport: Revising the infeasibility of sinkhorn and efficient gradient methods,
Anh Duc Nguyen, Tuan Dung Nguyen, Quang Minh Nguyen, Hoang H Nguyen, Lam M Nguyen, and Kim- Chuan Toh, “On partial optimal transport: Revising the infeasibility of sinkhorn and efficient gradient methods,” inProceedings of the AAAI Conference on Artificial In- telligence, 2024, vol. 38, pp. 8090–8098
work page 2024
-
[29]
Partial optimal tranport with applications on positive- unlabeled learning,
Laetitia Chapel, Mokhtar Z. Alaya, and Gilles Gasso, “Partial optimal tranport with applications on positive- unlabeled learning,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Had- sell, M.F. Balcan, and H. Lin, Eds. 2020, vol. 33, pp. 2903–2913, Curran Associates, Inc
work page 2020
-
[30]
Near-linear time approximation algorithms for optimal transport via sinkhorn iteration,
Jason Altschuler, Jonathan Niles-Weed, and Philippe Rigollet, “Near-linear time approximation algorithms for optimal transport via sinkhorn iteration,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[31]
Efficient and accurate optimal trans- port with mirror descent and conjugate gradients,
Mete Kemertas, Allan Douglas Jepson, and Amir mas- soud Farahmand, “Efficient and accurate optimal trans- port with mirror descent and conjugate gradients,”Trans- actions on Machine Learning Research, 2025
work page 2025
-
[32]
Smooth and sparse optimal transport,
Mathieu Blondel, Vivien Seguy, and Antoine Rolet, “Smooth and sparse optimal transport,” 2018
work page 2018
-
[33]
Rigid registration of point clouds based on partial optimal transport,
Hongxing Qin, Yucheng Zhang, Zhentao Liu, and Bao- quan Chen, “Rigid registration of point clouds based on partial optimal transport,”Computer Graphics Forum, vol. 41, no. 6, pp. 365–378, 2022
work page 2022
-
[34]
Monge,M ´emoire sur la th ´eorie des d ´eblais et des remblais, Imprimerie royale, 1781
G. Monge,M ´emoire sur la th ´eorie des d ´eblais et des remblais, Imprimerie royale, 1781
-
[35]
On the translocation of masses,
L. V . Kantorovich, “On the translocation of masses,” Journal of Mathematical Sciences, vol. 133, no. 4, pp. 1381–1382, Mar 2006
work page 2006
-
[36]
C´edric Villani et al.,Optimal transport: old and new, vol. 338, Springer, 2008
work page 2008
-
[37]
Solving a special type of optimal transport problem by a modified hungarian algorithm,
Yiling Xie, Yiling Luo, and Xiaoming Huo, “Solving a special type of optimal transport problem by a modified hungarian algorithm,” 2023
work page 2023
-
[38]
Optimal transport-based generative models for bayesian posterior sampling,
Ke Li, Wei Han, Yuexi Wang, and Yun Yang, “Optimal transport-based generative models for bayesian posterior sampling,” 2025
work page 2025
-
[39]
Scalable optimal transport methods in machine learning: A contemporary survey,
Abdelwahed Khamis, Russell Tsuchida, Mohamed Tarek, Vivien Rolland, and Lars Petersson, “Scalable optimal transport methods in machine learning: A contemporary survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, p. 1–20, 2024
work page 2024
-
[40]
Control, opti- mal transport and neural differential equations in super- vised learning,
Minh-Nhat Phung and Minh-Binh Tran, “Control, opti- mal transport and neural differential equations in super- vised learning,” 2025
work page 2025
-
[41]
Partial wasserstein adversarial network for non-rigid point set registration,
Zi-Ming Wang, Nan Xue, Ling Lei, and Guisong Xia, “Partial wasserstein adversarial network for non-rigid point set registration,”ArXiv, vol. abs/2203.02227, 2022
-
[42]
Nicolas Papadakis,Optimal Transport for Image Pro- cessing, Habilitation `a diriger des recherches, Universit´e de Bordeaux ; Habilitation thesis, Dec. 2015
work page 2015
-
[43]
Optimal mass transport: Signal processing and machine-learning applications,
Soheil Kolouri, Se Rim Park, Matthew Thorpe, Dejan Slepcev, and Gustavo K. Rohde, “Optimal mass transport: Signal processing and machine-learning applications,” IEEE Signal Processing Magazine, vol. 34, no. 4, pp. 43–59, 2017
work page 2017
-
[44]
Scaling algorithms for unbal- anced transport problems,
Lenaic Chizat, Gabriel Peyr´e, Bernhard Schmitzer, and Franc ¸ois-Xavier Vialard, “Scaling algorithms for unbal- anced transport problems,” 2017
work page 2017
-
[45]
Unbalanced optimal transport: A unified framework for object detection,
Henri De Plaen, Pierre-Fran c ¸ois De Plaen, Johan A. K. Suykens, Marc Proesmans, Tinne Tuytelaars, and Luc Van Gool, “Unbalanced optimal transport: A unified framework for object detection,” 2023
work page 2023
-
[46]
Application of unbalanced optimal transport in health- care,
Qui Phu Pham, Nghia Thu Truong, Hoang-Hiep Nguyen- Mau, Cuong Nguyen, Mai Ngoc Tran, and Dung Luong, “Application of unbalanced optimal transport in health- care,”International Journal of Advanced Computer Sci- ence and Applications, vol. 15, no. 11, 2024
work page 2024
-
[47]
Optimal transport for domain adapta- tion,
Nicolas Courty, R´emi Flamary, Devis Tuia, and Alain Rakotomamonjy, “Optimal transport for domain adapta- tion,” 2016
work page 2016
-
[48]
ADDITIONAL LITERATURE REVIEW Optimal Transport (OT), introduced by Monge [23] and for- malized by Kantorovich [24], seeks the cost-minimizing way to reallocate mass from a source distribution to a target ac- cording to a given ground cost. Building on this foundation, Villani’s influential monograph [25] established OT as a corner- stone in modern mathema...
-
[49]
APPENDIX 9.1. Reformulating POT as Extended OT It has been shown in [17, 18] that the POT problem can be reformulated as a standard OT problem by introducing slack variables and dummy nodes. For completeness, we briefly restate the construction here. Linear Programming Form of POT.We first introduce slack variables p,q∈R n + to capture the unmatched mass ...
-
[50]
The top-left n×n blocks of these matrices are written ˜X⊕ and ˜X ⋆ ⊕
OT formulation [18], whose entropic solution we denote by ˜X and optimum by ˜X ⋆. The top-left n×n blocks of these matrices are written ˜X⊕ and ˜X ⋆ ⊕. The cost difference can then be split as ⟨ ¯X− ¯X ⋆,C⟩=⟨ ¯X− ˜X⊕,C⟩+⟨ ˜X⊕ − ˜X ⋆ ⊕,C⟩+⟨ ˜X ⋆ ⊕ − ¯X ⋆,C⟩. The first term comes from rounding and, by Theorem 6 of [17], contributes at most 23ε ′. The last t...
work page 2000
-
[51]
EXTRA ALGORITHM We present a Sinkhorn algorithm with the tuning technique described in Section 4.1. The method first converts POT to a balanced OT problem via dummy nodes, then applies Sinkhorn with a principled choice of γ, and finally rounds the result back to a feasible POT plan. Sinkhorn Algorithm with tuningγtechnique Algorithm 3 Tuned Sinkhorn for P...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.