Recognition: no theorem link
Geometry-Induced Long-Range Correlations in Recurrent Neural Network Quantum States
Pith reviewed 2026-05-10 17:20 UTC · model grok-4.3
The pith
Dilated connections in RNN wave functions induce power-law long-range correlations by changing how recurrent units access distant sites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dilated RNN wave functions change the correlation geometry and can induce power-law correlation scaling. In the critical 1D transverse-field Ising model, dilated RNNs reproduce the expected power-law connected two-point correlations in contrast to the exponential decay typical of conventional RNN ansätze. The dilated RNN also accurately approximates the one-dimensional Cluster state, a paradigmatic example with long-range conditional correlations.
What carries the argument
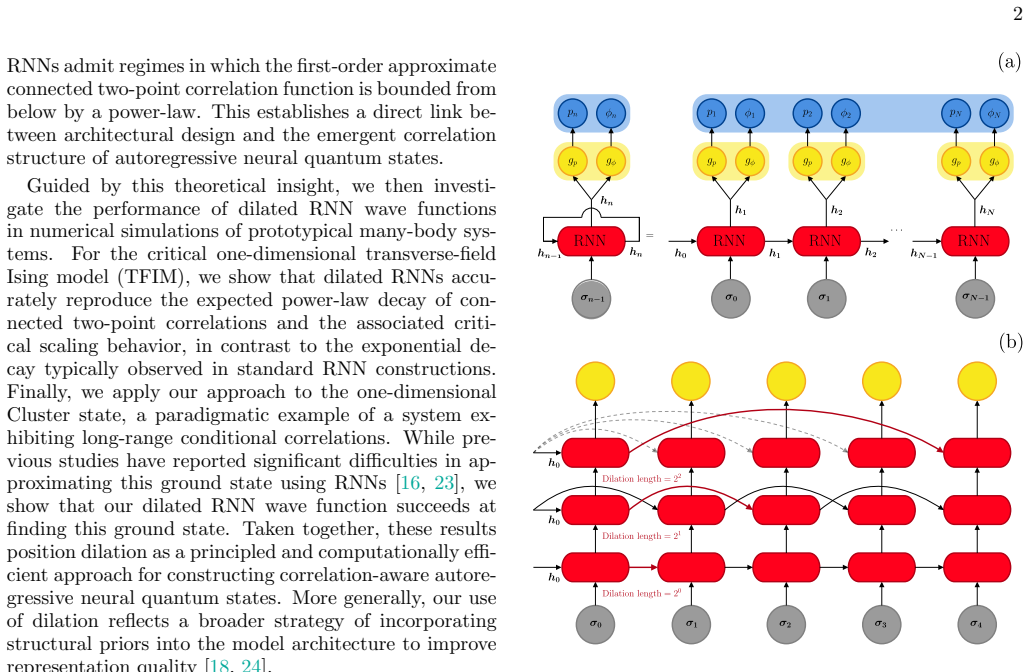
Dilated connections in the recurrent units, which let each unit directly access positions separated by exponentially increasing distances while preserving O(N log N) scaling.
If this is right
- Dilated RNN ansätze can represent critical quantum states whose correlations decay algebraically.
- The construction provides an autoregressive representation of the cluster state that respects its long-range conditional structure.
- Computational cost remains favorable compared with attention-based alternatives while still capturing long-range dependencies.
- The same geometric bias can be applied to other one-dimensional models that require algebraic or long-range correlations.
Where Pith is reading between the lines
- Dilation could be stacked with other inductive biases to address models whose correlations decay even more slowly.
- The mechanism suggests a route to long-range order in higher-dimensional autoregressive networks without adding full attention layers.
- Direct tests on two-dimensional lattices would show whether the one-dimensional dilation pattern generalizes or needs modification.
Load-bearing premise
That the geometric effect of dilation alone suffices to produce the required long-range correlations in the full nonlinear, non-perturbative regime of the variational optimization.
What would settle it
A numerical computation showing that the connected two-point correlation function extracted from the dilated RNN ansatz for the critical transverse-field Ising model decays exponentially with distance rather than as a power law.
Figures



read the original abstract
Neural Quantum States based on autoregressive recurrent neural network (RNN) wave functions enable efficient sampling without Markov-chain autocorrelation, but standard RNN architectures are biased toward finite-length correlations and can fail on states with long-range dependencies. A common response is to adopt transformer-style self-attention, but this typically comes with substantially higher computational and memory overhead. Here we introduce dilated RNN wave functions, where recurrent units access distant sites through dilated connections, injecting an explicit long-range inductive bias while retaining a favorable $\mathcal{O}(N \log N)$ forward pass scaling. We show analytically that dilation changes the correlation geometry and can induce power-law correlation scaling in a simplified linearized and perturbative setting. Numerically, for the critical 1D transverse-field Ising model, dilated RNNs reproduce the expected power-law connected two-point correlations in contrast to the exponential decay typical of conventional RNN ans\"atze. We further show that the dilated RNN accurately approximates the one-dimensional Cluster state, a paradigmatic example with long-range conditional correlations that has previously been reported to be challenging for RNN-based wave functions. These results highlight dilation as a simple geometric mechanism for building correlation-aware autoregressive neural quantum states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces dilated RNN architectures for neural quantum states, where recurrent units use dilated connections to access distant sites. This provides an explicit geometric inductive bias for long-range correlations while preserving O(N log N) scaling. Analytically, the authors show in a linearized perturbative setting that dilation alters correlation geometry to yield power-law scaling. Numerically, dilated RNNs reproduce the expected power-law connected two-point correlations for the critical 1D TFIM (in contrast to exponential decay in standard RNNs) and accurately represent the 1D Cluster state, which has long-range conditional correlations.
Significance. If the geometric mechanism is shown to survive full nonlinear variational optimization, the approach offers a lightweight alternative to attention-based models for states with long-range dependencies. The O(N log N) forward pass and the explicit separation of geometry from learned parameters are notable strengths; the work could influence ansatz design for critical and topological phases where standard RNNs are known to struggle.
major comments (3)
- [analytical derivation (linearized perturbative setting)] The analytic derivation establishing power-law scaling is performed only after linearizing the RNN update rule and working perturbatively. It is not shown that the same geometric effect persists once the wave function becomes a nonlinear function of the parameters that are optimized via stochastic gradient descent; the numerical results for TFIM and Cluster state are therefore consistent with the claim but do not isolate the dilation geometry from possible optimization or initialization effects.
- [numerical results for the critical 1D TFIM] Numerical evidence for the TFIM reports power-law correlations for dilated RNNs versus exponential decay for conventional RNNs, yet the abstract and results section provide no error bars, convergence diagnostics, or comparison against other long-range ansätze (e.g., attention-based or long-range RNN variants). This leaves open whether the observed scaling is robust or sensitive to training hyperparameters.
- [Cluster-state results] The Cluster-state demonstration is presented as evidence that dilated RNNs can capture long-range conditional correlations previously reported as challenging for RNN wave functions. However, without an ablation that freezes the dilation pattern while varying optimization details, it remains possible that the variational procedure itself induces the required correlations rather than the fixed geometric connectivity.
minor comments (2)
- [abstract and methods] The abstract states that dilation yields O(N log N) scaling; a brief complexity table or explicit recurrence relation would clarify how the dilation factor enters the cost.
- [architecture description] Notation for the dilation factor and the precise connectivity pattern should be defined once in the main text with a small diagram, rather than only in supplementary material.
Simulated Author's Rebuttal
We thank the referee for the careful reading of our manuscript and the constructive comments. We are pleased that the significance of the geometric inductive bias introduced by dilated connections is recognized. We address the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: The analytic derivation establishing power-law scaling is performed only after linearizing the RNN update rule and working perturbatively. It is not shown that the same geometric effect persists once the wave function becomes a nonlinear function of the parameters that are optimized via stochastic gradient descent; the numerical results for TFIM and Cluster state are therefore consistent with the claim but do not isolate the dilation geometry from possible optimization or initialization effects.
Authors: We agree that our analytical result is derived under a linearized and perturbative approximation of the RNN update rule. This approach was chosen to analytically isolate the impact of the dilation geometry on the correlation structure, showing explicitly how it leads to power-law scaling. We believe this provides valuable insight into the mechanism, even if it does not capture the full nonlinear dynamics. The numerical results for both the TFIM and the Cluster state demonstrate that power-law and long-range correlations are achieved in the fully optimized nonlinear setting. To strengthen the manuscript, we will revise the discussion section to better articulate the connection between the linearized analysis and the numerical findings, and to note the limitations of the perturbative approach. A complete nonlinear analytical treatment remains an open challenge and is beyond the current scope. revision: partial
-
Referee: Numerical evidence for the TFIM reports power-law correlations for dilated RNNs versus exponential decay for conventional RNNs, yet the abstract and results section provide no error bars, convergence diagnostics, or comparison against other long-range ansätze (e.g., attention-based or long-range RNN variants). This leaves open whether the observed scaling is robust or sensitive to training hyperparameters.
Authors: We appreciate this observation. In the revised version, we will include error bars on the correlation function plots derived from multiple independent training runs, add convergence diagnostics such as energy variance and training loss curves, and discuss the sensitivity to hyperparameters. While a direct comparison to attention-based models is not the primary focus of this work, we will add a paragraph in the discussion comparing the computational scaling and performance of dilated RNNs to transformer-based approaches for long-range correlations. revision: yes
-
Referee: The Cluster-state demonstration is presented as evidence that dilated RNNs can capture long-range conditional correlations previously reported as challenging for RNN wave functions. However, without an ablation that freezes the dilation pattern while varying optimization details, it remains possible that the variational procedure itself induces the required correlations rather than the fixed geometric connectivity.
Authors: We acknowledge the value of an ablation study to isolate the geometric effect. In the revision, we will include an ablation where we train both dilated and standard RNNs on the Cluster state using the same optimization procedure and initialization. This will demonstrate that the standard RNN fails to capture the long-range correlations while the dilated version succeeds, thereby attributing the improvement to the dilation geometry rather than the optimization alone. revision: yes
- Providing a full analytical derivation of power-law correlations in the nonlinear, variationally optimized regime.
Circularity Check
No circularity: power-law claim derived from explicit dilation geometry in linearized analysis, not by construction or self-reference
full rationale
The paper's central analytic step derives power-law correlations from the dilated connectivity pattern under a linearized perturbative approximation to the RNN update rule. This is an explicit calculation on the modified architecture rather than a redefinition or fit of the target quantity. Numerical results on TFIM and Cluster state are presented as verification, not as the source of the scaling law. No self-citation is invoked to justify uniqueness or to close the derivation; the architecture modification itself supplies the inductive bias. The derivation chain therefore remains self-contained against external benchmarks and does not reduce the claimed result to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- dilation factor
axioms (2)
- domain assumption Recurrent units with dilated skip connections produce a different correlation geometry than standard sequential RNNs
- domain assumption The variational optimization of the RNN parameters can reach the target long-range correlated states
Forward citations
Cited by 1 Pith paper
-
Parallel Scan Recurrent Neural Quantum States for Scalable Variational Monte Carlo
PSR-NQS makes recurrent neural quantum states scalable for variational Monte Carlo by using parallel scan recurrence, reaching accurate results on 52x52 two-dimensional lattices.
Reference graph
Works this paper leans on
-
[1]
, λdh) with 0< λ j <1
V anilla RNNs We assume that our inputsx n ∈ {−1,1}and consider the linearized recurrence hn =wx n−1 +U hhn−1, o n =u ⊤hn +b, whereh n ∈R dh,w,u∈R dh, andU h = diag(λ1, . . . , λdh) with 0< λ j <1. We assume 0< λ j <1 so that each hidden mode is stable and attenuates monotonically with lag. More generally, the stability requirement is|λ j|<1, but restrict...
-
[2]
Here⌈log B N⌉denotes the ceiling of log B N, i.e., the smallest integer greater than or equal to log B N
Dilated RNNs We now consider a family of linearized dilated models indexed by the system sizeN, with depth L=⌈log B N⌉ and dilation schedule s(l) =B l−1,1≤l≤L. Here⌈log B N⌉denotes the ceiling of log B N, i.e., the smallest integer greater than or equal to log B N. For analytic tractability, we restrict our analysis to the diag- onal recurrent map Uh = di...
-
[3]
Before stating the lemmas, we specify the admissible path structure used throughout this subsection
Auxiliary Lemmas In this subsection, we show the intermediate results needed in subsection B 2. Before stating the lemmas, we specify the admissible path structure used throughout this subsection. An admissible path is a directed path in the layered computation graph that uses horizontal recurrent edges and vertical inter-layer edges, where ver- tical mov...
-
[4]
Neural net- work solution of the schr¨ odinger equation for a two- dimensional harmonic oscillator,
J. Androsiuk, L. Ku lak, and K. Sienicki, “Neural net- work solution of the schr¨ odinger equation for a two- dimensional harmonic oscillator,” Chemical Physics173, 377–383 (1993)
1993
-
[5]
Artificial neu- ral network methods in quantum mechanics,
I.E. Lagaris, A. Likas, and D.I. Fotiadis, “Artificial neu- ral network methods in quantum mechanics,” Computer Physics Communications104, 1–14 (1997)
1997
-
[6]
Solving the quantum many-body problem with artificial neural net- works,
Giuseppe Carleo and Matthias Troyer, “Solving the quantum many-body problem with artificial neural net- works,” Science355, 602–606 (2017)
2017
-
[7]
From architectures to applica- tions: a review of neural quantum states,
Hannah Lange, Anka Van de Walle, Atiye Abedinnia, and Annabelle Bohrdt, “From architectures to applica- tions: a review of neural quantum states,” Quantum Sci- ence and Technology9, 040501 (2024)
2024
-
[8]
Recur- rent neural network wave functions,
Mohamed Hibat-Allah, Martin Ganahl, Lauren E. Hay- ward, Roger G. Melko, and Juan Carrasquilla, “Recur- rent neural network wave functions,” Phys. Rev. Res.2, 023358 (2020)
2020
-
[9]
Christopher Roth, “Iterative retraining of quantum spin models using recurrent neural networks,” (2020), arXiv:2003.06228 [physics.comp-ph]
-
[10]
Gauge- invariant and anyonic-symmetric autoregressive neural network for quantum lattice models,
Di Luo, Zhuo Chen, Kaiwen Hu, Zhizhen Zhao, Vera Mikyoung Hur, and Bryan K. Clark, “Gauge- invariant and anyonic-symmetric autoregressive neural network for quantum lattice models,” Phys. Rev. Res. 5, 013216 (2023)
2023
-
[11]
Neural network approach to quasi- particle dispersions in doped antiferromagnets,
Hannah Lange, Fabian D¨ oschl, Juan Carrasquilla, and Annabelle Bohrdt, “Neural network approach to quasi- particle dispersions in doped antiferromagnets,” Commu- nications Physics7(2024), 10.1038/s42005-024-01678-7
-
[12]
Language mod- els for quantum simulation,
Roger G. Melko and Juan Carrasquilla, “Language mod- els for quantum simulation,” Nature Computational Sci- ence4, 11–18 (2024)
2024
-
[13]
Artificial intelligence for advanced functional materials: exploring current and future directions,
Cristiano Malica, Kostya S Novoselov, Amanda S Barnard, Sergei V Kalinin, Steven R Spurgeon, Karsten Reuter, Maite Alducin, Volker L Deringer, G´ abor Cs´ anyi, Nicola Marzari, Shirong Huang, Gianaurelio Cuniberti, Qiushi Deng, Pablo Ordej´ on, Ivan Cole, Kamal Choud- hary, Kedar Hippalgaonkar, Ruiming Zhu, O Anatole von Lilienfeld, Mohamed Hibat-Allah, J...
2025
-
[14]
Leverag- ing recurrence in neural network wavefunctions for large- scale simulations of heisenberg antiferromagnets on the square lattice,
M. Schuyler Moss, Roeland Wiersema, Mohamed Hibat- Allah, Juan Carrasquilla, and Roger G. Melko, “Leverag- ing recurrence in neural network wavefunctions for large- scale simulations of heisenberg antiferromagnets on the square lattice,” Phys. Rev. B112, 134450 (2025)
2025
-
[15]
Leverag- ing recurrence in neural network wavefunctions for large- scale simulations of heisenberg antiferromagnets on the triangular lattice,
M. Schuyler Moss, Roeland Wiersema, Mohamed Hibat- Allah, Juan Carrasquilla, and Roger G. Melko, “Leverag- ing recurrence in neural network wavefunctions for large- scale simulations of heisenberg antiferromagnets on the triangular lattice,” Phys. Rev. B112, 134449 (2025)
2025
-
[16]
Recursive time se- ries data augmentation,
Amine Mohamed Aboussalah, Min-Jae Kwon, Raj G. Pa- tel, Cheng Chi, and Chi-Guhn Lee, “Recursive time se- ries data augmentation,” inThe Eleventh International Conference on Learning Representations(2023)
2023
-
[17]
Mohamed Hibat-Allah, Roger G. Melko, and Juan Car- rasquilla, “Supplementing recurrent neural network wave functions with symmetry and annealing to improve accu- racy,” (2024), arXiv:2207.14314 [cond-mat.dis-nn]
-
[18]
Mohamed Hibat-Allah, Ejaaz Merali, Giacomo Torlai, Roger G. Melko, and Juan Carrasquilla, “Recurrent neural network wave functions for rydberg atom arrays on kagome lattice,” Communications Physics8(2025), 10.1038/s42005-025-02226-7
-
[19]
When can classical neural networks represent quantum states?
Tai-Hsuan Yang, Mehdi Soleimanifar, Thiago Berga- maschi, and John Preskill, “When can classical neural networks represent quantum states?” (2024), arXiv:2410.23152 [quant-ph]
-
[20]
Importance of correlations for neural quantum states,
Fabian D¨ oschl and Annabelle Bohrdt, “Importance of correlations for neural quantum states,” (2025), arXiv:2508.14152 [quant-ph]
-
[21]
Are GNNs doomed by the topology of their in- put graph?
Amine Mohamed Aboussalah and Abdessalam Ed-dib, “Are GNNs doomed by the topology of their in- put graph?” arXiv preprint arXiv:2502.17739 (2025), 10.48550/arXiv.2502.17739
-
[22]
Dilated recurrent neural networks,
Shiyu Chang, Yang Zhang, Wei Han, Mo Yu, Xiaoxiao Guo, Wei Tan, Xiaodong Cui, Michael Witbrock, Mark Hasegawa-Johnson, and Thomas S. Huang, “Dilated recurrent neural networks,” (2017), arXiv:1710.02224 [cs.AI]
-
[23]
Variational neural annealing,
Mohamed Hibat-Allah, Estelle M Inack, Roeland Wiersema, Roger G Melko, and Juan Carrasquilla, “Variational neural annealing,” Nat. Mach. Intell.3, 952– 961 (2021)
2021
-
[24]
Supplementing recurrent neural networks with annealing to solve combinatorial optimization problems,
Shoummo Ahsan Khandoker, Jawaril Munshad Abedin, and Mohamed Hibat-Allah, “Supplementing recurrent neural networks with annealing to solve combinatorial optimization problems,” Machine Learning: Science and Technology4, 015026 (2023)
2023
-
[25]
Mutual information scaling and expressive power of sequence models,
Huitao Shen, “Mutual information scaling and expressive power of sequence models,” (2019), arXiv:1905.04271 [cs.LG]
-
[26]
Adaptive neural quantum states: A recurrent neural network per- spective,
Jake McNaughton and Mohamed Hibat-Allah, “Adaptive neural quantum states: A recurrent neural network per- spective,” (2025), arXiv:2507.18700 [cond-mat.dis-nn]
-
[27]
GeoHNNs: Geometric hamiltonian neural net- works,
Amine Mohamed Aboussalah and Abdessalam Ed- dib, “GeoHNNs: Geometric hamiltonian neural net- works,” arXiv preprint arXiv:2507.15678 (2025), 10.48550/arXiv.2507.15678
-
[28]
Federico Becca and Sandro Sorella,Quantum Monte Carlo Approaches for Correlated Systems(Cambridge University Press, 2017)
2017
-
[29]
MADE: masked autoencoder for distribution estimation
Mathieu Germain, Karol Gregor, Iain Murray, and Hugo Larochelle, “Made: Masked autoencoder for distribution estimation,” (2015), arXiv:1502.03509 [cs.LG]
-
[30]
Neural autoregres- sive distribution estimation,
Benigno Uria, Marc-Alexandre Cˆ ot´ e, Karol Gregor, Iain Murray, and Hugo Larochelle, “Neural autoregres- sive distribution estimation,” (2016), arXiv:1605.02226 [cs.LG]
-
[31]
Dian Wu, Lei Wang, and Pan Zhang, “Solving statisti- cal mechanics using variational autoregressive networks,” Physical Review Letters122(2019), 10.1103/phys- revlett.122.080602
-
[32]
Deep autoregressive models for the efficient variational simulation of many-body quan- tum systems,
Or Sharir, Yoav Levine, Noam Wies, Giuseppe Carleo, and Amnon Shashua, “Deep autoregressive models for the efficient variational simulation of many-body quan- tum systems,” Phys. Rev. Lett.124, 020503 (2020). 16
2020
-
[33]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Kyunghyun Cho, Bart van Merrienboer, Caglar Gul- cehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio, “Learning phrase repre- sentations using rnn encoder-decoder for statistical ma- chine translation,” (2014), arXiv:1406.1078 [cs.CL]
work page internal anchor Pith review arXiv 2014
-
[34]
Ha¸ sim Sak, Andrew Senior, and Fran¸ coise Beaufays, “Long short-term memory based recurrent neural net- work architectures for large vocabulary speech recogni- tion,” (2014), arXiv:1402.1128 [cs.NE]
-
[35]
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le, “Se- quence to sequence learning with neural networks,” (2014), arXiv:1409.3215 [cs.CL]
work page Pith review arXiv 2014
-
[36]
Recurrent neural networks are universal approx- imators,
Anton Maximilian Sch¨ afer and Hans Georg Zimmer- mann, “Recurrent neural networks are universal approx- imators,” inArtificial Neural Networks – ICANN 2006, Lecture notes in computer science (Springer Berlin Hei- delberg, Berlin, Heidelberg, 2006) pp. 632–640
2006
-
[37]
preprint arXiv:1506.00019 , year=
Zachary C. Lipton, John Berkowitz, and Charles Elkan, “A critical review of recurrent neural networks for se- quence learning,” (2015), arXiv:1506.00019 [cs.LG]
-
[38]
Monte carlo simulation of stoquastic hamiltonians,
Sergey Bravyi, “Monte carlo simulation of stoquastic hamiltonians,” (2015), arXiv:1402.2295 [quant-ph]
-
[39]
Minimal gated unit for recurrent neural net- works,
Guo-Bing Zhou, Jianxin Wu, Chen-Lin Zhang, and Zhi- Hua Zhou, “Minimal gated unit for recurrent neural net- works,” International Journal of Automation and Com- puting13, 226–234 (2016)
2016
-
[40]
Lattice protein folding with variational an- nealing,
Shoummo A Khandoker, Estelle M Inack, and Mohamed Hibat-Allah, “Lattice protein folding with variational an- nealing,” Machine Learning: Science and Technology6, 035023 (2025)
2025
-
[41]
Con- tinuous control with Stacked Deep Dynamic Recurrent Reinforcement Learning for portfolio optimization,
Amine Mohamed Aboussalah and Chi-Guhn Lee, “Con- tinuous control with Stacked Deep Dynamic Recurrent Reinforcement Learning for portfolio optimization,” Ex- pert Systems with Applications140, 112891 (2020)
2020
-
[42]
Jan Koutn´ ık, Klaus Greff, Faustino Gomez, and J¨ urgen Schmidhuber, “A clockwork rnn,” (2014), arXiv:1402.3511 [cs.NE]
-
[43]
arXiv preprint arXiv:1609.01704 , year=
Junyoung Chung, Sungjin Ahn, and Yoshua Bengio, “Hi- erarchical multiscale recurrent neural networks,” (2017), arXiv:1609.01704 [cs.LG]
-
[44]
Attention is all you need,
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, Vol. 30, edited by I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Curran Associates, Inc., 2017)
2017
-
[45]
Understanding the exploding gradient problem.CoRR abs/1211.5063 (2012)
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio, “On the difficulty of training recurrent neural networks,” (2013), arXiv:1211.5063 [cs.LG]
-
[46]
Vidal ,\ https://link.aps.org/doi/10.1103/PhysRevLett.101.110501 journal journal Phys
G. Vidal, “Class of quantum many-body states that can be efficiently simulated,” Physical Review Letters101 (2008), 10.1103/physrevlett.101.110501
-
[47]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” (2017), arXiv:1412.6980 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
The quantum ising chain for beginners,
Glen Bigan Mbeng, Angelo Russomanno, and Giuseppe E. Santoro, “The quantum ising chain for beginners,” SciPost Physics Lecture Notes (2024), 10.21468/scipostphyslectnotes.82
-
[49]
(Cambridge University Press, 2011)
Subir Sachdev,Quantum Phase Transitions, 2nd ed. (Cambridge University Press, 2011)
2011
-
[50]
Philippe Di Francesco, Pierre Mathieu, and David S´ en´ echal,Conformal Field Theory, Graduate Texts in Contemporary Physics (Springer New York, New York, NY, 1997)
1997
-
[51]
Entanglement entropy of two disjoint blocks in critical ising models,
Vincenzo Alba, Luca Tagliacozzo, and Pasquale Cal- abrese, “Entanglement entropy of two disjoint blocks in critical ising models,” Physical Review B81(2010), 10.1103/physrevb.81.060411
-
[52]
Entanglement en- tropy and quantum field theory,
Pasquale Calabrese and John Cardy, “Entanglement en- tropy and quantum field theory,” Journal of Statisti- cal Mechanics: Theory and Experiment2004, P06002 (2004)
2004
-
[53]
Entanglement scaling in two-dimensional gapless systems,
Hyejin Ju, Ann B. Kallin, Paul Fendley, Matthew B. Hastings, and Roger G. Melko, “Entanglement scaling in two-dimensional gapless systems,” Phys. Rev. B85, 165121 (2012)
2012
-
[54]
Geometric and renormalized entropy in conformal field theory,
Christoph Holzhey, Finn Larsen, and Frank Wilczek, “Geometric and renormalized entropy in conformal field theory,” Nuclear Physics B424, 443–467 (1994)
1994
-
[55]
Universality of entropy scaling in one dimensional gapless models,
V. E. Korepin, “Universality of entropy scaling in one dimensional gapless models,” Phys. Rev. Lett.92, 096402 (2004)
2004
-
[56]
Entan- glement and optimization within autoregressive neural quantum states,
Andrew Jreissaty, Hang Zhang, Jairo C. Quijano, Juan Carrasquilla, and Roeland Wiersema, “Entan- glement and optimization within autoregressive neural quantum states,” Physical Review Research8(2026), 10.1103/t2cg-kr7y
-
[57]
Riccardo Rende, Luciano Loris Viteritti, Lorenzo Bar- done, Federico Becca, and Sebastian Goldt, “A sim- ple linear algebra identity to optimize large-scale neu- ral network quantum states,” Communications Physics 7(2024), 10.1038/s42005-024-01732-4
-
[58]
Empowering deep neural quantum states through efficient optimization,
Ao Chen and Markus Heyl, “Empowering deep neural quantum states through efficient optimization,” Nature Physics20, 1476–1481 (2024)
2024
-
[59]
Functional neural wavefunction optimization
Victor Armegioiu, Juan Carrasquilla, Siddhartha Mishra, Johannes M¨ uller, Jannes Nys, Marius Zeinhofer, and Hang Zhang, “Functional neural wavefunction optimiza- tion,” (2025), arXiv:2507.10835 [cond-mat.str-el]
-
[60]
Colloquium: Area laws for the entanglement entropy,
J. Eisert, M. Cramer, and M. B. Plenio, “Colloquium: Area laws for the entanglement entropy,” Reviews of Modern Physics82, 277–306 (2010)
2010
-
[61]
Prob- ing many-body dynamics on a 51-atom quantum simula- tor,
Hannes Bernien, Sylvain Schwartz, Alexander Keesling, Harry Levine, Ahmed Omran, Hannes Pichler, Soon- won Choi, Alexander S. Zibrov, Manuel Endres, Markus Greiner, Vladan Vuleti´ c, and Mikhail D. Lukin, “Prob- ing many-body dynamics on a 51-atom quantum simula- tor,” Nature551, 579–584 (2017)
2017
-
[62]
Observation of a many-body dynami- cal phase transition with a 53-qubit quantum simulator,
J. Zhang, G. Pagano, P. W. Hess, A. Kyprianidis, P. Becker, H. Kaplan, A. V. Gorshkov, Z.-X. Gong, and C. Monroe, “Observation of a many-body dynami- cal phase transition with a 53-qubit quantum simulator,” Nature551, 601–604 (2017)
2017
-
[63]
Philippe Flajolet and Robert Sedgewick,Analytic com- binatorics(cambridge University press, 2009)
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.