Recognition: unknown
IG-Search: Step-Level Information Gain Rewards for Search-Augmented Reasoning
Pith reviewed 2026-05-10 11:14 UTC · model grok-4.3
The pith
IG-Search assigns step-level information gain rewards to individual search queries during reinforcement learning training of language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
IG-Search defines a step-level reward as the information gain of retrieved documents over a random-document counterfactual, calculated solely from the policy model's generation probabilities for the gold answer, and routes this signal to the corresponding search-query tokens through per-token advantage modulation in GRPO.
What carries the argument
Information gain reward computed against a random-document counterfactual using the policy's own generation probabilities for the gold answer.
If this is right
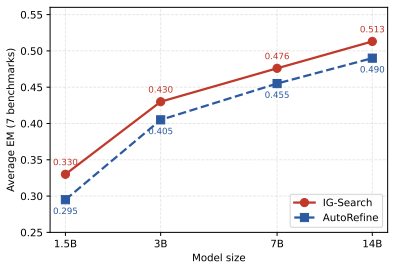
- Yields an average exact-match score of 0.430 on seven single-hop and multi-hop QA benchmarks with a 3B model.
- Outperforms the strongest trajectory-level baseline by 1.6 points and the prior step-level method by 0.9 points on average.
- Delivers larger improvements on multi-hop reasoning tasks.
- Continues to supply a usable gradient even when every sampled trajectory answers incorrectly.
- Increases per-step training wall-clock time by only about 6.4 percent while leaving inference latency unchanged.
Where Pith is reading between the lines
- The same counterfactual-probability approach could be tested on other tool-use or multi-step reasoning domains where external step labels are unavailable.
- Self-generated probability differences may serve as a general substitute for external verifiers when defining dense rewards in reinforcement learning for reasoning.
- The method suggests that rollout groups can be kept smaller if step-level signals replace the need for at least one successful trajectory.
Load-bearing premise
The difference between the model's in the gold answer after real retrieval versus after random documents accurately reflects the usefulness of the search query.
What would settle it
A controlled experiment in which IG-Search training is rerun on the same seven QA benchmarks but with the information-gain term replaced by a constant or random step-level value, then checking whether the performance advantage over trajectory-level baselines disappears.
Figures













read the original abstract
Reinforcement learning has emerged as an effective paradigm for training large language models to perform search-augmented reasoning. However, existing approaches rely on trajectory-level rewards that cannot distinguish precise search queries from vague or redundant ones within a rollout group, and collapse to a near-zero gradient signal whenever every sampled trajectory fails. In this paper, we propose IG-Search, a reinforcement learning framework that introduces a step-level reward based on Information Gain (IG). For each search step, IG measures how much the retrieved documents improve the model's confidence in the gold answer relative to a counterfactual baseline of random documents, thereby reflecting the effectiveness of the underlying search query. This signal is fed back to the corresponding search-query tokens via per-token advantage modulation in GRPO, enabling fine-grained, step-level credit assignment within a rollout. Unlike prior step-level methods that require either externally annotated intermediate supervision or shared environment states across trajectories, IG-Search derives its signals from the policy's own generation probabilities, requiring no intermediate annotations beyond standard question-answer pairs. Experiments on seven single-hop and multi-hop QA benchmarks demonstrate that IG-Search achieves an average EM of 0.430 with Qwen2.5-3B, outperforming the strongest trajectory-level baseline (MR-Search) by 1.6 points and the step-level method GiGPO by 0.9 points on average across benchmarks, with particularly pronounced gains on multi-hop reasoning tasks. Despite introducing a dense step-level signal, IG-Search adds only ~6.4% to per-step training wall-clock time over the trajectory-level baseline and leaves inference latency unchanged, while still providing a meaningful gradient signal even when every sampled trajectory answers incorrectly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IG-Search, an RL framework for search-augmented reasoning in LLMs. It introduces a step-level Information Gain (IG) reward that measures the improvement in the policy's probability of generating the gold answer when using retrieved documents versus a random-document counterfactual baseline. This IG signal is applied via per-token advantage modulation within GRPO to enable fine-grained credit assignment to search-query tokens. The method requires only standard QA pairs and no external intermediate supervision. Experiments on seven single- and multi-hop QA benchmarks with Qwen2.5-3B report an average EM of 0.430, outperforming the trajectory-level MR-Search baseline by 1.6 points and the step-level GiGPO method by 0.9 points on average, with larger gains on multi-hop tasks; the approach adds ~6.4% training overhead and preserves inference latency while providing gradients even when all trajectories fail.
Significance. If the central experimental claims hold under scrutiny, IG-Search would represent a practical advance in dense, step-level reward design for RL-based agentic search without requiring annotated intermediates or shared states. The low overhead and continued gradient signal in all-failure cases address known limitations of trajectory-level methods, and the pronounced multi-hop gains suggest potential utility for complex reasoning pipelines. The internal-probability derivation is a notable strength if shown to correlate reliably with query utility.
major comments (2)
- [§3 (IG definition) and Experiments] The IG definition (abstract and §3) computes the reward solely from the policy's own log-probabilities of the gold answer under retrieved vs. random documents. No ablation, correlation analysis, or error breakdown is provided showing that this proxy reliably tracks query quality rather than prior calibration or tokenization artifacts, especially for a 3B model early in training. This is load-bearing for the claim that gains arise from precise step-level credit assignment rather than GRPO mechanics alone.
- [Experiments section] The reported average EM of 0.430 and relative gains (1.6 and 0.9 points) are presented without per-benchmark variance, statistical significance tests, or ablation tables isolating the contribution of the IG term versus the trajectory-level baseline. The absence of these details in the experimental section makes it impossible to assess robustness of the multi-hop improvements.
minor comments (2)
- [§3.2] Clarify the exact formula for the random-document counterfactual (how many random documents, sampling procedure) and whether it is recomputed per step or cached.
- [Related Work] The claim of 'no external intermediate supervision' is accurate but could be contrasted more explicitly with GiGPO's requirements in the related-work section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will incorporate revisions to provide additional validation and statistical details as requested.
read point-by-point responses
-
Referee: [§3 (IG definition) and Experiments] The IG definition (abstract and §3) computes the reward solely from the policy's own log-probabilities of the gold answer under retrieved vs. random documents. No ablation, correlation analysis, or error breakdown is provided showing that this proxy reliably tracks query quality rather than prior calibration or tokenization artifacts, especially for a 3B model early in training. This is load-bearing for the claim that gains arise from precise step-level credit assignment rather than GRPO mechanics alone.
Authors: We acknowledge the need to further validate that the IG proxy captures query utility rather than artifacts. The random-document counterfactual is intended to control for the policy's prior probability and tokenization effects by measuring relative improvement. In the revised manuscript we will add a correlation analysis between IG values and human-annotated query quality on 100 multi-hop examples, an ablation replacing policy-based IG with a fixed retrieval-score baseline, and an error breakdown separating cases where IG fails to predict answer improvement. These additions will help isolate the contribution of step-level credit assignment from GRPO mechanics. revision: yes
-
Referee: [Experiments section] The reported average EM of 0.430 and relative gains (1.6 and 0.9 points) are presented without per-benchmark variance, statistical significance tests, or ablation tables isolating the contribution of the IG term versus the trajectory-level baseline. The absence of these details in the experimental section makes it impossible to assess robustness of the multi-hop improvements.
Authors: We agree that variance, significance testing, and targeted ablations would strengthen the experimental claims. In the revised version we will expand the results section to report per-benchmark EM scores with standard deviations over three random seeds, include paired t-test p-values for the 1.6-point and 0.9-point gains, and add an ablation table that compares IG-Search to MR-Search under identical GRPO settings with the step-level modulation removed. This will allow clearer assessment of robustness, particularly for the multi-hop gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines IG explicitly as the difference in the current policy's probability of emitting the gold answer given retrieved documents versus a random-document counterfactual. This scalar is then used directly as a per-token advantage signal inside GRPO. The experimental EM gains on QA benchmarks are obtained by running the resulting training loop; they are not obtained by algebraic substitution back into the IG definition itself. Use of gold answers is stated openly as the only supervision beyond standard QA pairs, and no load-bearing self-citation, fitted parameter renamed as prediction, or uniqueness theorem imported from prior author work appears in the derivation. The reward construction therefore remains an independent modeling choice whose downstream performance is measured empirically rather than forced by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Random documents provide a suitable counterfactual baseline for measuring information gain of actual retrieved documents.
- domain assumption Policy generation probabilities for the gold answer can be used to compute a reliable per-step advantage without external annotations.
Forward citations
Cited by 2 Pith papers
-
Bian Que: An Agentic Framework with Flexible Skill Arrangement for Online System Operations
Bian Que deploys an agentic system with flexible skills and self-evolution on a major e-commerce search engine, cutting alerts by 75%, reaching 80% root-cause accuracy, and halving resolution time.
-
Bian Que: An Agentic Framework with Flexible Skill Arrangement for Online System Operations
Bian Que is an agentic framework using a unified operational paradigm, flexible Skill Arrangement, and self-evolving mechanism to automate O&M tasks, achieving 75% alert reduction and over 50% MTTR cut in production d...
Reference graph
Works this paper leans on
-
[1]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection.arXiv preprint arXiv:2310.11511, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen
Mingyang Chen, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z. Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen. Research: Learning to reason with search for llms via reinforcement learning.arXiv preprint arXiv:2503.19470, 2025. 15
-
[3]
Zheng Ding and Weirui Ye. Treegrpo: Tree-advantage grpo for online rl post-training of diffusion models.arXiv preprint arXiv:2512.08153, 2025
-
[4]
Group-in-group policy optimization for LLM agent training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for LLM agent training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[5]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y . Wu, Y . K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. Deepseek-coder: When the large language model meets programming – the rise of code intelligence.arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, and Wu. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[7]
Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
2020
-
[8]
Xu, Jun Araki, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Jun Araki, and Graham Neubig. How can we know what language models know?Transactions of the Association for Computational Linguistics, 8:423–438, 2020
2020
-
[10]
Active retrieval augmented generation
Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969–7992, Singapore, 2023
2023
-
[11]
Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling, 2025
2025
-
[12]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada, 2017
2017
-
[13]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
2019
-
[14]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks.arXiv preprint arXiv:2005.11401, 2021
work page internal anchor Pith review arXiv 2005
-
[15]
Search-o1: Agentic search-enhanced large reasoning models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438, Suzhou, China, 2025
2025
-
[16]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023. 16
work page internal anchor Pith review arXiv 2023
-
[17]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, Toronto, Canada, 2023
2023
-
[18]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
OpenAI. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, Singapore, 2023
2023
-
[21]
Qwen. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, pages 53728–53741, 2023
2023
-
[23]
In-context retrieval- augmented language models,
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton- Brown, and Yoav Shoham. In-context retrieval-augmented language models.arXiv preprint arXiv:2302.00083, 2023
-
[24]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 9248–9274, Singapore, 2023
2023
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297, 2025
2025
-
[28]
REPLUG: Retrieval-augmented black-box language models
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Richard James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. REPLUG: Retrieval-augmented black-box language models. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Languag...
2024
-
[29]
Search and refine during think: Facilitating knowledge refinement for improved retrieval-augmented reasoning
Yaorui Shi, Sihang Li, Chang Wu, Zhiyuan Liu, Junfeng Fang, Hengxing Cai, An Zhang, and Xiang Wang. Search and refine during think: Facilitating knowledge refinement for improved retrieval-augmented reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[30]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592, 2025
work page internal anchor Pith review arXiv 2025
-
[31]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
MuSiQue: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022. 17
2022
-
[33]
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10014–10037, Toronto, Canada, 2023
2023
-
[34]
Information gain-based policy optimization: A simple and effective ap- proach for multi-turn search agents
Guoqing Wang, Sunhao Dai, Guangze Ye, Zeyu Gan, Wei Yao, Yong Deng, Xiaofeng Wu, and Zhenzhe Ying. Information gain-based policy optimization: A simple and effective ap- proach for multi-turn search agents. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[35]
Tongyu Wen, Guanting Dong, and Zhicheng Dou. Smartsearch: Process reward-guided query refinement for search agents.arXiv preprint arXiv:2601.04888, 2026
-
[36]
Smith, and Hannaneh Hajishirzi
Teng Xiao, Yige Yuan, Hamish Ivison, Huaisheng Zhu, Faeze Brahman, Nathan Lambert, Pradeep Dasigi, Noah A. Smith, and Hannaneh Hajishirzi. Meta-reinforcement learning with self-reflection for agentic search.arXiv preprint arXiv:2603.11327, 2026
-
[37]
Jun Xu, Xinkai Du, Yu Ao, Peilong Zhao, Yang Li, Ling Zhong, Lin Yuan, Zhongpu Bo, Xiaorui Wang, Mengshu Sun, Zhengke Gui, Dalong Zhang, Zhaoyang Wang, Qiwei Wang, Yangyang Hou, Zhiying Yin, Haofen Wang, Huajun Chen, Lei Liang, and Jun Zhou. Thinker: Training llms in hierarchical thinking for deep search via multi-turn interaction.arXiv preprint arXiv:251...
-
[38]
Corrective Retrieval Augmented Generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation.arXiv preprint arXiv:2401.15884, 2024
work page internal anchor Pith review arXiv 2024
-
[39]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium, 2018
2018
-
[40]
arXiv preprint arXiv:2501.07301 , year=
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning.arXiv preprint arXiv:2501.07301, 2025
-
[41]
StepSearch: Igniting LLMs search ability via step-wise proximal policy optimization
Xuhui Zheng, Kang An, Ziliang Wang, Yuhang Wang, and Yichao Wu. StepSearch: Igniting LLMs search ability via step-wise proximal policy optimization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21805–21830, Suzhou, China, 2025. 18 A Related Work IG-Search sits at the intersection of RL-based reasoning, re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.