Recognition: unknown
Agentic Large Language Models for Training-Free Neuro-Radiological Image Analysis
Pith reviewed 2026-05-10 08:21 UTC · model grok-4.3
The pith
Agentic LLMs autonomously execute complex neuro-radiological workflows like glioma segmentation and multi-timepoint response assessment by directing off-the-shelf tools, without any model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our results demonstrate that agentic AI can solve highly neuro-radiological image analysis tasks through tool use without the need for training or fine-tuning.
Load-bearing premise
That frontier LLMs can reliably plan and execute error-free multi-step tool orchestration for clinically accurate outputs in complex workflows such as longitudinal response assessment.
Figures

read the original abstract
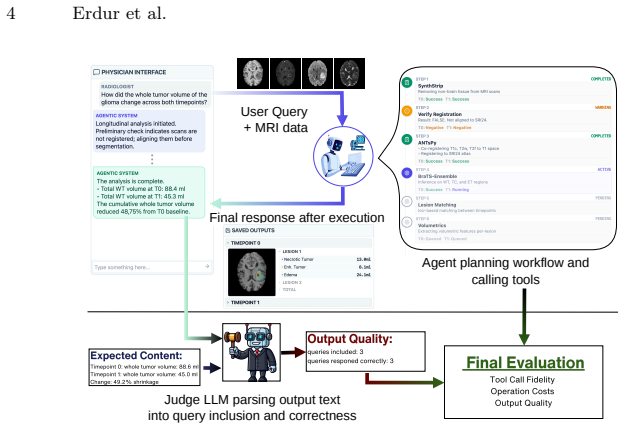
State-of-the-art large language models (LLMs) show high performance in general visual question answering. However, a fundamental limitation remains: current architectures lack the native 3D spatial reasoning required for direct analysis of volumetric medical imaging, such as CT or MRI. Emerging agentic AI offers a new solution, eliminating the need for intrinsic 3D processing by enabling LLMs to orchestrate and leverage specialized external tools. Yet, the feasibility of such agentic frameworks in complex, multi-step radiological workflows remains underexplored. In this work, we present a training-free agentic pipeline for automated brain MRI analysis. Validating our methodology on several LLMs (GPT-5.1, Gemini 3 Pro, Claude Sonnet 4.5) with off-the-shelf domain-specific tools, our system autonomously executes complex end-to-end workflows, including preprocessing (skull stripping, registration), pathology segmentation (glioma, meningioma, metastases), and volumetric analysis. We evaluate our framework across increasingly complex radiological tasks, from single-scan segmentation and volumetric reporting to longitudinal response assessment requiring multi-timepoint comparisons. We analyze the impact of architectural design by comparing single-agent models against multi-agent "domain-expert" collaborations. Finally, to support rigorous evaluation of future agentic systems, we introduce and release a benchmark dataset of image-prompt-answer tuples derived from public BraTS data. Our results demonstrate that agentic AI can solve highly neuro-radiological image analysis tasks through tool use without the need for training or fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a training-free agentic pipeline in which frontier LLMs (GPT-5.1, Gemini 3 Pro, Claude Sonnet 4.5) orchestrate off-the-shelf tools to perform end-to-end neuro-radiological workflows on brain MRI: skull-stripping, registration, glioma/meningioma/metastases segmentation, volumetric reporting, and longitudinal response assessment across multiple time points. It compares single-agent versus multi-agent “domain-expert” architectures and releases a BraTS-derived benchmark of image-prompt-answer tuples.
Significance. If the empirical claims are substantiated, the work would demonstrate that agentic tool orchestration can substitute for native 3D reasoning in clinically relevant multi-step radiological pipelines without any training or fine-tuning. The public benchmark would be a concrete, reusable contribution for evaluating future agentic medical-image systems.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation sections: the central claim that the system “autonomously executes complex end-to-end workflows” and “solves highly neuro-radiological image analysis tasks” is unsupported by any reported quantitative metrics (Dice scores, volumetric error, registration TRE, per-step tool-success rates, or expert-agreement statistics), especially on the longitudinal multi-timepoint subset.
- [Evaluation / Results] The load-bearing assumption that LLM-driven planning produces error-free multi-step orchestration (skull-stripping → registration → segmentation → volumetric comparison) is not tested; no per-step failure rates, prompt-sensitivity results, or propagation analysis across time points are provided, leaving the reliability of the longitudinal response-assessment task unquantified.
minor comments (1)
- [Abstract] The abstract would be strengthened by stating the number of cases, time-point pairs, and exact tool versions used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify gaps in quantitative evaluation that strengthen the manuscript. We address each point below and have incorporated revisions to provide the requested metrics and analyses.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation sections: the central claim that the system “autonomously executes complex end-to-end workflows” and “solves highly neuro-radiological image analysis tasks” is unsupported by any reported quantitative metrics (Dice scores, volumetric error, registration TRE, per-step tool-success rates, or expert-agreement statistics), especially on the longitudinal multi-timepoint subset.
Authors: We agree that the original abstract and evaluation sections overstate the claims without sufficient supporting numbers. The manuscript's evaluation focused on workflow completion via the released benchmark but omitted explicit per-step rates and standard image metrics. Because the agent orchestrates existing tools (whose Dice/TRE performance is documented in the tool papers), our primary metric is orchestration success rather than re-deriving segmentation accuracy. In the revised manuscript we have added: (1) a table of per-step tool-success rates and overall workflow completion (single-agent vs. multi-agent), (2) volumetric error and registration TRE computed against BraTS ground truth for the executed pipelines, and (3) a dedicated longitudinal subsection reporting failure-propagation statistics and expert agreement on response-assessment outputs. These changes directly support the central claims. revision: yes
-
Referee: [Evaluation / Results] The load-bearing assumption that LLM-driven planning produces error-free multi-step orchestration (skull-stripping → registration → segmentation → volumetric comparison) is not tested; no per-step failure rates, prompt-sensitivity results, or propagation analysis across time points are provided, leaving the reliability of the longitudinal response-assessment task unquantified.
Authors: This observation is accurate. The initial Results section presented successful end-to-end examples without systematic quantification of failure modes or sensitivity. We have revised the Evaluation section to include: per-step failure rates across the full benchmark suite, prompt-sensitivity experiments (varying temperature and few-shot examples), and a propagation analysis that tracks how early-step errors affect final longitudinal response assessment. These additions quantify the reliability of the multi-timepoint task and allow readers to assess the load-bearing assumption. revision: yes
Circularity Check
No circularity: purely empirical architecture with external benchmarks
full rationale
The paper describes a training-free agentic pipeline that orchestrates off-the-shelf tools (skull-stripping, registration, segmentation) via frontier LLMs for brain MRI tasks. No equations, fitted parameters, self-referential predictions, or mathematical derivations appear in the provided text or abstract. Claims rest on experimental evaluation across single- vs. multi-agent setups and a released BraTS-derived benchmark, which are independent of any internal definitions or self-citations. The load-bearing elements are tool-use success rates and clinical accuracy on held-out data, not reductions to the paper's own inputs. This matches the default expectation of no significant circularity for empirical systems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models possess sufficient planning and tool-calling capabilities to autonomously manage multi-step medical image processing pipelines.
Forward citations
Cited by 1 Pith paper
-
Towards a Virtual Neuroscientist: Autonomous Neuroimaging Analysis via Multi-Agent Collaboration
NIAgent uses code-centric multi-agent collaboration and hierarchical verification to build adaptive neuroimaging pipelines that outperform static baselines on ADHD-200 and ADNI data.
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Med- ical Image Computing and Computer-Assisted Intervention
Almansoori,M.,Kumar,K.,Cholakkal,H.:Medagentsim:Self-evolvingmulti-agent simulations for realistic clinical interactions. In: International Conference on Med- ical Image Computing and Computer-Assisted Intervention. pp. 362–372. Springer (2025)
2025
-
[2]
Neuroimage54(3), 2033–2044 (2011)
Avants, B.B., Tustison, N.J., Song, G., Cook, P.A., Klein, A., Gee, J.C.: A repro- ducibleevaluationofantssimilaritymetricperformanceinbrainimageregistration. Neuroimage54(3), 2033–2044 (2011)
2033
-
[3]
M3d:Ad- vancing 3d medical image analysis with multi-modal large language models
Bai, F., Du, Y., Huang, T., Meng, M.Q.H., Zhao, B.: M3d: Advancing 3d medical image analysis with multi-modal large language models. arXiv preprint arXiv:2404.00578 (2024)
-
[4]
Baid, U., Ghodasara, S., Mohan, S., Bilello, M., Calabrese, E., Colak, E., et al.: The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification. arXiv preprint arXiv:2107.02314 (2021)
work page internal anchor Pith review arXiv 2021
-
[5]
Medical image analysis86, 102789 (2023)
Billot, B., Greve, D.N., Puonti, O., Thielscher, A., Van Leemput, K., Fischl, B., et al.: Synthseg: Segmentation of brain mri scans of any contrast and resolution without retraining. Medical image analysis86, 102789 (2023)
2023
-
[6]
Strahlentherapie und Onkologie201(3), 236–254 (2025)
Erdur, A.C., Rusche, D., Scholz, D., Kiechle, J., Fischer, S., Llorian-Salvador, O., et al.: Deep learning for autosegmentation for radiotherapy treatment planning: State-of-the-art and novel perspectives. Strahlentherapie und Onkologie201(3), 236–254 (2025)
2025
-
[7]
Eriksen, A.V., Möller, S., Ryg, J.: Use of gpt-4 to diagnose complex clinical cases (2024)
2024
-
[8]
Medrax: Medical reasoning agent for chest x-ray, 2025
Fallahpour, A., Ma, J., Munim, A., Lyu, H., Wang, B.: Medrax: Medical reasoning agent for chest x-ray. arXiv preprint arXiv:2502.02673 (2025)
-
[9]
NeuroImage260, 119474 (2022)
Hoopes, A., Mora, J.S., Dalca, A.V., Fischl, B., Hoffmann, M.: Synthstrip: skull- stripping for any brain image. NeuroImage260, 119474 (2022)
2022
-
[10]
Journal of neuroscience methods374, 109566 (2022)
Joshi, A.A., Choi, S., Liu, Y., Chong, M., Sonkar, G., Gonzalez-Martinez, J., et al.: A hybrid high-resolution anatomical mri atlas with sub-parcellation of cortical gyri using resting fmri. Journal of neuroscience methods374, 109566 (2022)
2022
-
[11]
BMC medicine 17(1), 195 (2019)
Kelly, C.J., Karthikesalingam, A., Suleyman, M., Corrado, G., King, D.: Key challenges for delivering clinical impact with artificial intelligence. BMC medicine 17(1), 195 (2019)
2019
-
[12]
Kofler, F., Möller, H., Buchner, J.A., de la Rosa, E., Ezhov, I., Rosier, M., et al.: Panoptica – instance-wise evaluation of 3d semantic and instance segmentation maps (2023) 10 Erdur et al
2023
- [13]
-
[14]
arXiv preprint arXiv:2305.07642 , year=
LaBella, D., Adewole, M., Alonso-Basanta, M., Altes, T., Anwar, S.M., Baid, U., et al.: The asnr-miccai brain tumor segmentation (brats) challenge 2023: Intracra- nial meningioma. arXiv preprint arXiv:2305.07642 (2023)
-
[15]
Lai, H., Jiang, Z., Yao, Q., Wang, R., He, Z., Tao, X., et al.: E3d-gpt: en- hanced 3d visual foundation for medical vision-language model. arXiv preprint arXiv:2410.14200 (2024)
-
[16]
Advances in Neural Information Processing Systems36, 28541–28564 (2023)
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., et al.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems36, 28541–28564 (2023)
2023
-
[17]
A co-evolving agentic ai system for medical imaging analysis, 2025
Li, S., Xu, J., Bao, T., Liu, Y., Liu, Y., Liu, Y., et al.: A co-evolving agentic ai system for medical imaging analysis. arXiv preprint arXiv:2509.20279 (2025)
-
[18]
arXiv preprint arXiv:2509.10683 (2025)
Liu, F., Yoo, J.J., Khalvati, F.: A comparison and evaluation of fine-tuned con- volutional neural networks to large language models for image classification and segmentation of brain tumors on mri. arXiv preprint arXiv:2509.10683 (2025)
-
[19]
IEEE transac- tions on medical imaging34(10), 1993–2024 (2014)
Menze, B.H., Jakab, A., Bauer, S., Kalpathy-Cramer, J., Farahani, K., et al.: The multimodal brain tumor image segmentation benchmark (brats). IEEE transac- tions on medical imaging34(10), 1993–2024 (2014)
1993
-
[20]
arxiv pp
Moawad, A.W., Janas, A., Baid, U., Ramakrishnan, D., Saluja, R., Ashraf, N., etal.:Thebraintumorsegmentation-metastases(brats-mets)challenge2023:Brain metastasis segmentation on pre-treatment mri. arxiv pp. arXiv–2306 (2024)
2024
-
[21]
In: Machine learning for health (ML4H)
Moor, M., Huang, Q., Wu, S., Yasunaga, M., Dalmia, Y., Leskovec, J., et al.: Med- flamingo: a multimodal medical few-shot learner. In: Machine learning for health (ML4H). pp. 353–367. PMLR (2023)
2023
-
[22]
arXiv preprint arXiv:2511.00846 (2025)
Peng, Z., Wang, C., Liu, S., Liang, Z., Ye, Z., Ju, M., et al.: Omnibrainbench: A comprehensive multimodal benchmark for brain imaging analysis across multi- stage clinical tasks. arXiv preprint arXiv:2511.00846 (2025)
-
[23]
arXiv preprint arXiv:2508.10865 (2025)
Safari, M., Wang, S., Hu, M., Eidex, Z., Li, Q., Yang, X.: Performance of gpt-5 in brain tumor mri reasoning. arXiv preprint arXiv:2508.10865 (2025)
-
[24]
Advances in neural information processing systems36, 68539–68551 (2023)
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., et al.: Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems36, 68539–68551 (2023)
2023
-
[25]
Nature medicine29(8), 1930–1940 (2023)
Thirunavukarasu, A.J., Ting, D.S.J., Elangovan, K., Gutierrez, L., Tan, T.F., Ting, D.S.W.: Large language models in medicine. Nature medicine29(8), 1930–1940 (2023)
1930
-
[26]
Cancer research77(21), e104–e107 (2017)
Van Griethuysen, J.J., Fedorov, A., Parmar, C., Hosny, A., Aucoin, N., Narayan, V., et al.: Computational radiomics system to decode the radiographic phenotype. Cancer research77(21), e104–e107 (2017)
2017
-
[27]
de Verdier, M.C., Saluja, R., Gagnon, L., LaBella, D., Baid, U., Tahon, N.H., et al.: The 2024 brain tumor segmentation (brats) challenge: Glioma segmentation on post-treatment mri. arXiv preprint arXiv:2405.18368 (2024)
-
[28]
IEEE Journal of Biomedical and Health Informatics (2025)
Xin, Y., Ates, G.C., Gong, K., Shao, W.: Med3dvlm: An efficient vision-language model for 3d medical image analysis. IEEE Journal of Biomedical and Health Informatics (2025)
2025
-
[29]
Survey on Evaluation of LLM-based Agents
Yehudai, A., Eden, L., Li, A., Uziel, G., Zhao, Y., Bar-Haim, R., et al.: Survey on evaluation of llm-based agents. arXiv preprint arXiv:2503.16416 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.