PersonalHomeBench: Evaluating Agents in Personalized Smart Homes
Pith reviewed 2026-05-15 06:37 UTC · model grok-4.3
The pith
Agents in personalized smart homes show clear performance drops as task complexity rises, especially failing at counterfactual reasoning and partial observability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
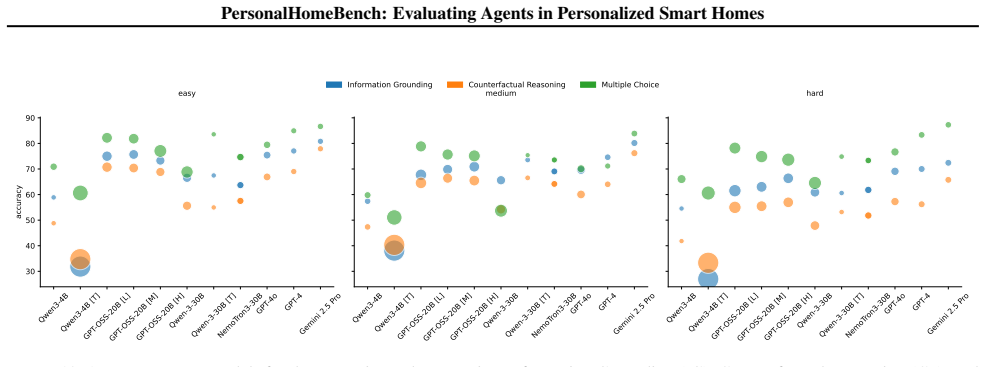
PersonalHomeBench is constructed by iteratively building rich household states that then generate personalized, context-dependent tasks, paired with PersonalHomeTools that let agents retrieve household information, control appliances, and build situational understanding. Evaluation of foundation models shows a systematic performance reduction as task complexity increases, with pronounced failures in counterfactual reasoning and under partial observability where effective tool-based information gathering is required.
What carries the argument
PersonalHomeBench benchmark, built through iterative household-state construction and personalized task generation, together with the PersonalHomeTools toolbox for retrieval, control, and understanding.
If this is right
- Agent performance declines steadily as task complexity grows in personalized settings.
- Counterfactual reasoning remains a clear weakness even for current foundation models.
- Partial observability demands effective tool-based information gathering that most agents lack.
- Reactive and proactive abilities can be compared directly within the same benchmark.
- The platform enables systematic analysis of robustness in personalized agentic planning.
Where Pith is reading between the lines
- Real-world smart-home assistants may need targeted training on incomplete-information scenarios before reliable deployment.
- The benchmark could be extended to multi-step dynamic replanning when household states change over time.
- Failures identified here point to specific gaps in tool-use integration that future agent architectures should address.
- Similar evaluation pipelines might be adapted to other personalized physical environments such as offices or vehicles.
Load-bearing premise
The iteratively constructed household states and generated tasks sufficiently capture the complexity and personalization of real-world smart home environments for meaningful agent evaluation.
What would settle it
An experiment in which one or more agents maintain stable performance across rising task complexities with no pronounced failures in counterfactual reasoning or partial-observability tool-use scenarios would falsify the reported pattern.
Figures











read the original abstract
Agentic AI systems are rapidly advancing toward real-world applications, yet their readiness in complex and personalized environments remains insufficiently characterized. To address this gap, we introduce PersonalHomeBench, a benchmark for evaluating foundation models as agentic assistants in personalized smart home environments. The benchmark is constructed through an iterative process that progressively builds rich household states, which are then used to generate personalized, context-dependent tasks. To support realistic agent-environment interaction, we provide PersonalHomeTools, a comprehensive toolbox enabling household information retrieval, appliance control, and situational understanding. PersonalHomeBench evaluates both reactive and proactive agentic abilities under unimodal and multimodal observations. Thorough experimentation reveals a systematic performance reduction as task complexity increases, with pronounced failures in counterfactual reasoning and under partial observability, where effective tool-based information gathering is required. These results position PersonalHomeBench as a rigorous evaluation platform for analyzing the robustness and limitations of personalized agentic reasoning and planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PersonalHomeBench, a benchmark for evaluating foundation models as agentic assistants in personalized smart home environments. It describes an iterative construction process that builds rich household states and generates context-dependent tasks, provides PersonalHomeTools for information retrieval and control, and evaluates reactive and proactive abilities under unimodal and multimodal observations. Experimental results indicate systematic performance reductions as task complexity increases, with notable failures in counterfactual reasoning and partial observability scenarios requiring tool-based information gathering.
Significance. If the benchmark construction is representative and the empirical findings are robustly supported, PersonalHomeBench could provide a valuable platform for diagnosing limitations in current agentic systems for personalized, real-world environments, particularly highlighting challenges in handling partial observability and counterfactual tasks.
major comments (2)
- Abstract: The central claims of systematic performance reduction and pronounced failures in counterfactual reasoning and partial observability are presented only at a high level without any quantitative metrics, specific results, tables, error analysis, or baseline comparisons, leaving the empirical support for these load-bearing findings insufficiently substantiated.
- Construction process (iterative household state building and task generation): The synthetic iterative process risks embedding generation artifacts that could artifactually produce the reported failures in tool-based information gathering and counterfactual reasoning; without explicit validation against real-world personalized smart home data or ablation studies on the construction steps, it is unclear whether the observed performance drops generalize beyond benchmark-specific artifacts.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and indicate the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: The central claims of systematic performance reduction and pronounced failures in counterfactual reasoning and partial observability are presented only at a high level without any quantitative metrics, specific results, tables, error analysis, or baseline comparisons, leaving the empirical support for these load-bearing findings insufficiently substantiated.
Authors: We agree that the abstract would benefit from greater specificity to substantiate the central claims. In the revised manuscript, we will expand the abstract to include key quantitative results, such as the magnitude of performance reductions across task complexity levels, failure rates in counterfactual reasoning and partial observability scenarios, and brief baseline comparisons drawn from our experimental tables. revision: yes
-
Referee: Construction process (iterative household state building and task generation): The synthetic iterative process risks embedding generation artifacts that could artifactually produce the reported failures in tool-based information gathering and counterfactual reasoning; without explicit validation against real-world personalized smart home data or ablation studies on the construction steps, it is unclear whether the observed performance drops generalize beyond benchmark-specific artifacts.
Authors: We acknowledge the concern that the synthetic iterative construction could introduce artifacts. The process is deliberately structured around realistic household dynamics and user-specific preferences to promote ecological validity. To address this directly, we will add ablation studies on the construction steps (e.g., varying iteration depth and state enrichment rules) to demonstrate that the reported performance trends are robust. We cannot provide direct validation against real-world personalized smart home datasets in this work, as no suitable public datasets exist at the required scale and granularity; we will explicitly note this limitation and outline it as future work. revision: partial
- Direct empirical validation of the benchmark construction against real-world personalized smart home data
Circularity Check
No circularity: empirical benchmark construction and evaluation
full rationale
The paper introduces PersonalHomeBench via iterative synthetic household state building and context-dependent task generation, then reports empirical agent performance results under varying complexity, observability, and modalities. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations of uniqueness theorems appear. The construction process is explicitly described as a methodological choice for creating the evaluation platform rather than a self-referential definition or reduction. All reported findings (performance drops with complexity, failures in counterfactual reasoning) are direct experimental outcomes on the generated benchmark and do not collapse to the inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iterative process that progressively builds rich household states... PersonalHomeTools... five categories of personalized tasks
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
systematic performance reduction as task complexity increases... failures in counterfactual reasoning and under partial observability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
TaskGround: Structured Executable Task Inference for Full-Scene Household Reasoning
TaskGround introduces a Ground-Infer-Execute framework for full-scene household reasoning that improves success rates on the FullHome benchmark and enables compact models to match larger ones at up to 18x lower token cost.
Reference graph
Works this paper leans on
-
[1]
URL https://proceedings.mlr.press/ v267/bonatti25a.html. Chang, M., Chhablani, G., Clegg, A., Cote, M. D., Desai, R., Hlavac, M., Karashchuk, V ., Krantz, J., Mottaghi, R., Parashar, P., et al. Partnr: A benchmark for planning and reasoning in embodied multi-agent tasks.arXiv preprint arXiv:2411.00081, 2024a. Chang, M., Zhang, J., Zhu, Z., Yang, C., Yang,...
-
[2]
doi: 10.18653/v1/2024.acl-long
URL https://api.semanticscholar. org/CorpusID:273375463. Maharana, A., Lee, D.-H., Tulyakov, S., Bansal, M., Barbi- eri, F., and Fang, Y . Evaluating very long-term conver- sational memory of LLM agents. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: L...
-
[3]
URL https://aclanthology.org/2024. acl-long.747/. Meyer, Y . and Corneil, D. Nemotron-Personas- USA: Synthetic personas aligned to real- world distributions, June 2025. URL https: //huggingface.co/datasets/nvidia/ Nemotron-Personas-USA. Puig, X., Ra, K. K., Boben, M., Li, J., Wang, T., Fi- dler, S., and Torralba, A. Virtualhome: Simulating household activ...
work page 2024
-
[4]
URL https://openreview.net/forum? id=dHng2O0Jjr. Salemi, A., Mysore, S., Bendersky, M., and Zamani, H. LaMP: When large language models meet person- alization. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pp. 7370–7392, Bangkok, Thailan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.399 2024
-
[5]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
URL https://aclanthology.org/2024. emnlp-industry.37/. Tang, C., Li, Y ., Yang, Y ., Zhuang, J., Sun, G., Li, W., Ma, Z., and Zhang, C. video-salmonn 2: Captioning- enhanced audio-visual large language models.arXiv preprint arXiv:2506.15220, 2025. Wang, N., Peng, Z., Que, H., Liu, J., Zhou, W., Wu, Y ., Guo, H., Gan, R., Ni, Z., Yang, J., et al. Rolellm: ...
-
[6]
arXiv:2406.12639 [cs] doi:10.48550/arXiv.2406.12639
URL https://proceedings.neurips. cc/paper_files/paper/2022/file/ 82ad13ec01f9fe44c01cb91814fd7b8c-Paper-Conference. pdf. Zhang, X., Deng, Y ., Ren, Z., Ng, S.-K., and Chua, T.-S. Ask-before-plan: Proactive language agents for real-world planning.ArXiv, abs/2406.12639,
-
[7]
URL https://api.semanticscholar. org/CorpusID:270561990. Zhao, S., Zhu, A., Mozannar, H., Sontag, D. A., Talwalkar, A., and Chen, V . Codinggenie: A proactive llm-powered programming assistant.Pro- ceedings of the 33rd ACM International Confer- ence on the F oundations of Software Engineering,
-
[8]
URL https://api.semanticscholar. org/CorpusID:277112990. Zhu, M. Recall, precision and average precision.Depart- ment of Statistics and Actuarial Science, University of Waterloo, Waterloo, 2(30):6, 2004. 11 PersonalHomeBench: Evaluating Agents in Personalized Smart Homes A. Outline The appendix provides supplementary material that supports and extends the...
work page 2004
-
[9]
• All individual personas must align with this household information
Use the Household Persona as the Anchor • Use the household-level description to infer: demographics, living situation, socioeconomic context, lifestyle preferences, environment and context. • All individual personas must align with this household information
-
[10]
–Ages should fall within a similar age range, unless the household persona describes otherwise
Respect the Occupancy Type • If occupancy_type = roommate: –All individuals should be unrelated. –Ages should fall within a similar age range, unless the household persona describes otherwise. – Income levels, occupations, and lifestyles may differ, but should still plausibly co-exist in a shared-living situation. –Personalities should not be identical—ma...
-
[11]
Use the Samples as Style Guidance • Use samples only as examples of tone, structure, and level of detail. • Do not copy content. • Maintain similar attributes
-
[12]
Produce a Concise, Self-Contained Persona for Each Individual • For each individual, provide: 29 PersonalHomeBench: Evaluating Agents in Personalized Smart Homes –member_id: must be {household_id}_{n} where n starts at 1 –name: extract name from persona description –role: parent, child, roommate, partner, etc. –age (estimate if not explicitly stated) –gen...
-
[13]
Output Format Return the result as a list of personas, one entry per individual, labeled: "members": [ { "member_id": "{household_id}_1", "name": "", "role": "", "age": , "gender": "", "occupation": "", "persona": "", "hobbies": ["", ""], "lifestyle": "", "preference": "", "major_event": [ { "date": "", "description": "" } ] }, { "member_id": "{household_...
-
[14]
Take a grounded QA pair
-
[15]
Generate a counterfactual modification to the household/context/memory/appliance data
-
[16]
Provide: a) The counterfactual condition b) The new derived answer under this counterfactual world c) A short explanation of the reasoning shift Input Format You will be given a single QA item in JSON format with the following structure: {{ "difficulty": "easy | medium | hard", "question": "<generic question using IDs>", "personalized_question": "<questio...
-
[17]
Select exactly 10 features from the input list
-
[18]
Assign a correct ranking from 1 (most relevant) to 10 (least relevant)
-
[19]
Rankings must reflect explicit evidence from: 35 PersonalHomeBench: Evaluating Agents in Personalized Smart Homes - Household structure (members, ages, hobbies, roles, pets) - Device information (appliance types, sensors, locations) - Contextual data (current time, weather, schedules, states) - Long-term memories (habits, major events, preferences)
-
[20]
Provide a short explanation for each feature, describing why it is placed in its specific ranking position. RANKING REQUIREMENTS: - The ranking must reflect actual priorities inferred from the household’s behavior and needs. - Reasoning should show: - Observation (e.g., someone frequently forgets to turn off appliances) - Inference (e.g., a room with high...
-
[21]
Answer the QUESTION usingonlythe provided FULL_CONTEXT
-
[22]
unknown". ## Output format (STRICT JSON) {{
Donotinvent facts. If the answer is not derivable, output"unknown". ## Output format (STRICT JSON) {{ "answer": "<one of the choice from the list which is the answer>", # you should return the letter "evidence": [ {{ "rationale": "reasoning", "path": "<jsonpath-like pointer, e.g. appliances.microwave.location>", }} ] }} ## Rules - Keep theanswershort and ...
-
[23]
Sort features frommost relevant to least relevant
-
[24]
Rankings must reflectactual household priorities, not generic recommendations
-
[25]
Donot introducefeature IDs that are not provided
-
[26]
Use only information present in the household record. — ## OUTPUT REQUIREMENTS Returnonlythe following JSON object and nothing else: “‘json {{ "ranked_features": [ "<feature_id_1>", "<feature_id_2>", "<feature_id_3>", "...", "<feature_id_n>" ] }} “‘ Note: - The first element is the most relevant feature. - The last element is the least relevant feature. -...
- [27]
-
[28]
A household profile containing members, preferences, routines, constraints, and recent context. Your task is to rank the options from: - The perspective of the household as a whole (smart_home) - The perspective of each household member individually Evaluation Guidelines Household (smart_home) Perspective Rank options based on: • Safety and anomaly preven...
-
[29]
Safety and prevention
-
[30]
Multi-member benefit
-
[31]
Lower disruption Output Format (STRICT) Return one JSON object only, following this schema exactly: { "overall_order": [<LETTER\_1>, <LETTER\_2>, <LETTER\_3>...], "persona_order": { "household\_member\_id_1": [<LETTER\_1>, <LETTER\_2>, <LETTER\_3>...], "household\_member\_id_2": [<LETTER\_1>, <LETTER\_2>, <LETTER\_3>...] }, "rationale": "<1-3 sentence exp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.