Supervised Learning Has a Necessary Geometric Blind Spot: Theory, Consequences, and Minimal Repair
Pith reviewed 2026-05-09 22:24 UTC · model grok-4.3
The pith
Any encoder that fully minimizes supervised loss must retain non-zero sensitivity along directions correlated with the training labels, including nuisance directions at test time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
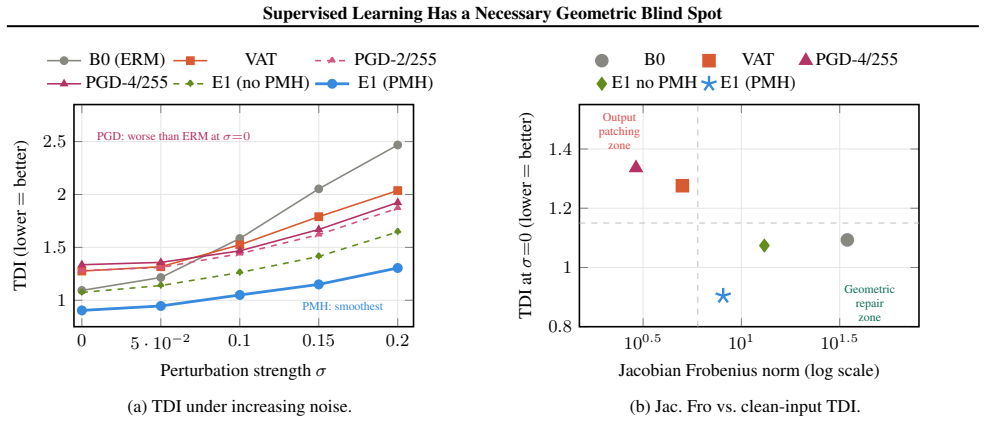
Any encoder minimizing supervised loss must retain non-zero sensitivity along directions correlated with training labels, including directions that are nuisance at test time. This holds across proper scoring rules, architectures, and dataset sizes. We call this the geometric blind spot of supervised learning. This theorem unifies four empirical phenomena often treated separately: non-robust features, texture bias, corruption fragility, and the robustness-accuracy tradeoff. It also explains why suppressing sensitivity in one adversarial direction can redistribute sensitivity elsewhere.
What carries the argument
The geometric blind spot theorem, which shows that supervised loss minimization forces non-zero Jacobian sensitivity in label-correlated directions.
Load-bearing premise
The model is an encoder that fully minimizes the supervised loss under standard conditions without residual loss or unmodeled architectural constraints.
What would settle it
A concrete counter-example: an encoder that achieves the global minimum of a proper scoring rule yet has exactly zero sensitivity along every direction correlated with the training labels.
Figures

read the original abstract
PGD adversarial training, the standard robustness method, can reduce Jacobian Frobenius norm yet worsen clean-input geometry (e.g., TDI 1.336 vs. ERM 1.093). We show this is not an implementation artifact but a theorem-level consequence of supervised learning. We prove that any encoder minimizing supervised loss must retain non-zero sensitivity along directions correlated with training labels, including directions that are nuisance at test time. This holds across proper scoring rules, architectures, and dataset sizes. We call this the geometric blind spot of supervised learning. This theorem unifies four empirical phenomena often treated separately: non-robust features, texture bias, corruption fragility, and the robustness-accuracy tradeoff. It also explains why suppressing sensitivity in one adversarial direction can redistribute sensitivity elsewhere. We introduce Trajectory Deviation Index (TDI), a diagnostic of geometric isotropy. Unlike CKA, intrinsic dimension, or Jacobian Frobenius norm alone, TDI captures the failure mode above. In our experiments, PGD attains low Frobenius norm but high TDI, while PMH attains the lowest TDI with one additional training term and no architectural changes. Across seven tasks, BERT/SST-2, and ImageNet ViT-B/16 (backbone family underlying CLIP/DINO/SAM), the blind spot is measurable and repairable. It appears at foundation-model scale, worsens with model scale and task-specific fine-tuning, and is substantially reduced by PMH. PMH also leads on non-Gaussian corruption types (blur/brightness/contrast) without corruption-specific training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to prove that any encoder minimizing the supervised loss (under proper scoring rules) must retain non-zero sensitivity along input directions correlated with training labels, including those that are nuisances at test time; this 'geometric blind spot' is asserted to hold independently of architecture and dataset size. The authors introduce the Trajectory Deviation Index (TDI) as a diagnostic of geometric isotropy that reveals failures not captured by Jacobian Frobenius norm alone, show that PGD adversarial training can increase TDI while lowering the norm, and propose a minimal repair (PMH) consisting of one additional training term that reduces TDI and improves corruption robustness. Experiments across BERT/SST-2, ImageNet ViT-B/16, and seven tasks are presented to demonstrate the blind spot at foundation-model scale and the effectiveness of the repair.
Significance. If the theorem holds for exact minimizers and the empirical link to practical SGD training can be strengthened, the result would be significant: it offers a unified theoretical account of non-robust features, texture bias, corruption fragility, and the robustness-accuracy tradeoff, while supplying a new diagnostic (TDI) and a lightweight intervention (PMH) that requires no architectural changes. The scale of the experiments (ViT-B/16 backbone) and the observation that the effect worsens with model scale and task-specific fine-tuning add practical relevance.
major comments (3)
- [Theorem 1 (Section 3)] Theorem 1 (Section 3): The statement and proof are derived strictly for exact global minimizers of the supervised loss. The experimental sections (5 and 6) report results from SGD-trained models on finite data with overparameterized architectures (ViT-B/16, BERT), which do not achieve exact minimization; the manuscript provides no analysis showing that the trained encoders are close enough to the minimizers for the geometric property to transfer, nor any approximate version of the theorem under residual loss. This assumption is load-bearing for the central claim that the blind spot is 'necessary' in supervised learning.
- [Section 4, TDI definition] Section 4, TDI definition and comparison to Jacobian Frobenius norm: While the abstract and experiments note that PGD yields low Frobenius norm yet high TDI (1.336 vs. ERM 1.093), the manuscript does not derive TDI directly from the theorem's sensitivity condition or prove that it is the minimal diagnostic required to detect the blind spot. Without this link, TDI risks appearing as an additional ad-hoc metric rather than a necessary consequence of the theory.
- [Section 5, experimental results] Section 5, experimental results on TDI and PMH: The reported TDI values and corruption accuracies lack error bars, details on the number of independent runs, or the precise protocol for computing trajectory deviations on large models. This weakens the claim that PMH attains the lowest TDI and leads on non-Gaussian corruptions, as statistical reliability cannot be assessed.
minor comments (3)
- [Abstract] Abstract: The acronym 'PMH' is introduced without expansion; define it at first use.
- [Notation] Notation: The encoder mapping and loss functions are referenced throughout but would benefit from a consolidated table of symbols in the main text rather than relying solely on the appendix.
- [Figures] Figures: Plots comparing TDI against Frobenius norm and other baselines would be clearer with explicit axis labels indicating the exact corruption types and model scales used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the scope of our theoretical claims and improve the empirical presentation. We address each major comment point by point below. Where the feedback identifies a genuine gap, we propose targeted revisions; we remain honest about aspects that would require substantial new theoretical development beyond the current work.
read point-by-point responses
-
Referee: [Theorem 1 (Section 3)] Theorem 1 (Section 3): The statement and proof are derived strictly for exact global minimizers of the supervised loss. The experimental sections (5 and 6) report results from SGD-trained models on finite data with overparameterized architectures (ViT-B/16, BERT), which do not achieve exact minimization; the manuscript provides no analysis showing that the trained encoders are close enough to the minimizers for the geometric property to transfer, nor any approximate version of the theorem under residual loss. This assumption is load-bearing for the central claim that the blind spot is 'necessary' in supervised learning.
Authors: We agree that Theorem 1 is formulated for exact global minimizers of the supervised loss under proper scoring rules. In the revised manuscript we will insert a dedicated paragraph in Section 3 (immediately after the theorem statement) that explicitly acknowledges this scope and discusses its relation to practical training. We will cite relevant results on the implicit bias of gradient descent in overparameterized models, noting that SGD trajectories often reach regions of near-zero training loss where the geometric sensitivity property is expected to hold approximately. However, deriving a quantitative approximate version of the theorem that bounds the residual loss and the resulting deviation from the exact sensitivity condition would constitute a non-trivial extension of the current theory; we cannot supply such an analysis in this revision and will state the limitation clearly. revision: partial
-
Referee: [Section 4, TDI definition] Section 4, TDI definition and comparison to Jacobian Frobenius norm: While the abstract and experiments note that PGD yields low Frobenius norm yet high TDI (1.336 vs. ERM 1.093), the manuscript does not derive TDI directly from the theorem's sensitivity condition or prove that it is the minimal diagnostic required to detect the blind spot. Without this link, TDI risks appearing as an additional ad-hoc metric rather than a necessary consequence of the theory.
Authors: We will revise Section 4 to make the connection explicit. We will add a short proposition showing that any encoder satisfying the non-zero sensitivity condition of Theorem 1 must exhibit positive Trajectory Deviation Index when trajectories are sampled along label-correlated directions; the TDI is therefore a direct, computable consequence of the retained sensitivity rather than an independent metric. We will also include a formal comparison proving that the Jacobian Frobenius norm can be small while TDI remains large precisely when sensitivity is redistributed (as predicted by the theorem), thereby establishing TDI as the appropriate diagnostic for the blind-spot phenomenon. revision: yes
-
Referee: [Section 5, experimental results] Section 5, experimental results on TDI and PMH: The reported TDI values and corruption accuracies lack error bars, details on the number of independent runs, or the precise protocol for computing trajectory deviations on large models. This weakens the claim that PMH attains the lowest TDI and leads on non-Gaussian corruptions, as statistical reliability cannot be assessed.
Authors: We accept this criticism. In the revised version we will augment all tables and figures in Section 5 with error bars computed from five independent random seeds. A new appendix subsection will provide the exact computational protocol: the number of sampled trajectories per model (100), the perturbation magnitudes used, the procedure for selecting label-correlated directions on ViT-B/16 and BERT, and the hardware considerations that make the computation tractable. These additions will allow readers to evaluate the statistical reliability of the reported TDI reductions and corruption-accuracy gains under PMH. revision: yes
- A formal approximate version of Theorem 1 that quantifies how the geometric blind spot transfers under non-zero residual loss or for SGD-trained models that are not exact minimizers.
Circularity Check
No circularity: theorem is a general statement about exact loss minimizers; TDI is an independent diagnostic
full rationale
The paper's core result is a theorem stating that any encoder exactly minimizing supervised loss (under proper scoring rules) must retain non-zero sensitivity along label-correlated directions. This is derived from the definition of loss minimization and does not reduce to a fitted parameter, self-citation, or renaming of an input quantity. TDI is explicitly introduced as a new geometric diagnostic (distinct from Jacobian norm or CKA) rather than computed from any prior fit. No equations or claims in the provided text exhibit self-definitional loops, fitted inputs relabeled as predictions, or load-bearing self-citations. The derivation chain is therefore self-contained as a mathematical proof with stated assumptions, and experiments serve only to illustrate the theorem's consequences rather than to establish it.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Any encoder that minimizes supervised loss under proper scoring rules
invented entities (2)
-
Trajectory Deviation Index (TDI)
no independent evidence
-
PMH
no independent evidence
Forward citations
Cited by 1 Pith paper
-
The Matching Principle: A Geometric Theory of Loss Functions for Nuisance-Robust Representation Learning
The matching principle unifies nuisance-robust representation learning by requiring Jacobian regularization whose range covers the covariance of label-preserving deployment nuisances, with closed-form optimality proof...
Reference graph
Works this paper leans on
-
[1]
Intrinsic dimension of data representations in deep neural networks
Ansuini, A., et al. Intrinsic dimension of data representations in deep neural networks. InAdvances in Neural Information Processing Systems, pp. 13853–13863, 2019
work page 2019
-
[2]
The intrinsic dimension of images and its impact on learning.ICLR, 2021
Pope, P., et al. The intrinsic dimension of images and its impact on learning.ICLR, 2021
work page 2021
-
[3]
Exponential expressivity in deep neural networks through transient chaos.NeurIPS, 2016
Poole, B., et al. Exponential expressivity in deep neural networks through transient chaos.NeurIPS, 2016
work page 2016
-
[4]
SVCCA: Singular vector canonical correla- tion analysis.NeurIPS, 2017
Raghu, M., et al. SVCCA: Singular vector canonical correla- tion analysis.NeurIPS, 2017
work page 2017
-
[5]
Simi- larity of neural network representations revisited
Kornblith, S., Norouzi, M., Lee, H., and Hinton, G. Simi- larity of neural network representations revisited. InInter- national Conference on Machine Learning, pp. 3519–3529, 2019
work page 2019
-
[6]
Nguyen, T. and Raghu, M. Do wide and deep networks learn the same things?ICLR, 2021
work page 2021
-
[7]
Contractive auto-encoders: Explicit invari- ance during feature extraction
Rifai, S., et al. Contractive auto-encoders: Explicit invari- ance during feature extraction. InProceedings of the 28th International Conference on Machine Learning, pp. 833– 840, 2011
work page 2011
-
[8]
Extracting and composing robust features with denoising autoencoders.ICML, 2008
Vincent, P., et al. Extracting and composing robust features with denoising autoencoders.ICML, 2008
work page 2008
-
[9]
Jakubovitz, D. and Giryes, R. Improving DNN robustness to adversarial attacks using Jacobian regularisation.ECCV, 2018
work page 2018
-
[10]
arXiv preprint arXiv:1908.02729
Hoffman, J., et al. Robust learning with Jacobian regularisa- tion.arXiv:1908.02729, 2019
- [11]
-
[12]
Adversarial examples are not bugs, they are features
Ilyas, A., et al. Adversarial examples are not bugs, they are features. InAdvances in Neural Information Processing Systems, pp. 125–136, 2019
work page 2019
-
[13]
ImageNet-trained CNNs are biased to- wards texture
Geirhos, R., et al. ImageNet-trained CNNs are biased to- wards texture. InInternational Conference on Learning Rep- resentations, 2019
work page 2019
-
[14]
Hendrycks, D. and Dietterich, T. Benchmarking neural net- work robustness to common corruptions.ICLR, 2019
work page 2019
-
[15]
Robustness may be at odds with accuracy
Tsipras, D., et al. Robustness may be at odds with accuracy. ICLR, 2019
work page 2019
-
[16]
Virtual adversarial training: A regulariza- tion method for supervised and semi-supervised learning
Miyato, T., et al. Virtual adversarial training: A regulariza- tion method for supervised and semi-supervised learning. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 41(8):1979–1993, 2018
work page 1979
-
[17]
Towards deep learning models resistant to adversarial attacks
Madry, A., et al. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations, 2018
work page 2018
-
[18]
An image is worth 16 ×16 words
Dosovitskiy, A., et al. An image is worth 16 ×16 words. ICLR, 2021
work page 2021
-
[19]
Spectral normalization for generative ad- versarial networks.ICLR, 2018
Miyato, T., et al. Spectral normalization for generative ad- versarial networks.ICLR, 2018
work page 2018
-
[20]
Tarvainen, A. and Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi- supervised deep learning results. InAdvances in Neural Information Processing Systems, 2017
work page 2017
-
[21]
Temporal Ensembling for Semi-Supervised Learning
Laine, S. and Aila, T. Temporal ensembling for semi- supervised learning.arXiv:1610.02242, 2016. 13 Supervised Learning Has a Necessary Geometric Blind Spot T01 T02 T03 T04 T05 T06 T070 50 100 Normalised robust metric (best=100) B0 (ERM) V AT E1 (PMH) (a) Cross-task robust performance (normalised per task). 0 2 4 6 8 B0 V AT E1 no PMH E1 (PMH) PGD-2/255 P...
work page Pith review arXiv 2016
-
[22]
The second inequality follows because p∗(y|x)−p s(y|x) encodes the conditional dependence on n: in the Gaussian linear model, ∥p∗(y|x)−p s(y|x)∥TV ≥cρ for a constant c >0 from the total-variation gap between N(⟨w s, s⟩+ρ⟨w n, n⟩, σ2 ε) and N(⟨w s, s⟩, σ2 ε). The TV gap is cρ/σε for small ρ (first-order Taylor expansion of the TV distance between two Gauss...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.