Frontier Lag: A Bibliometric Audit of Capability Misrepresentation in Academic AI Evaluation
Pith reviewed 2026-06-30 23:51 UTC · model grok-4.3
The pith
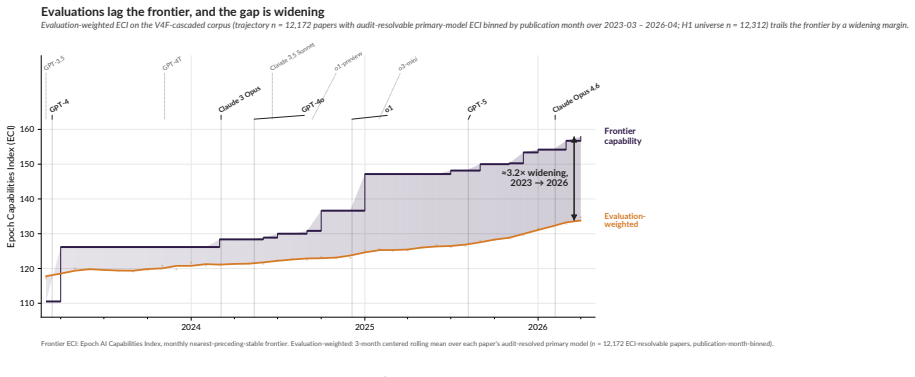
Academic LLM papers typically evaluate models 10.85 ECI behind the frontier at publication, with the gap widening 5.53 ECI per year.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
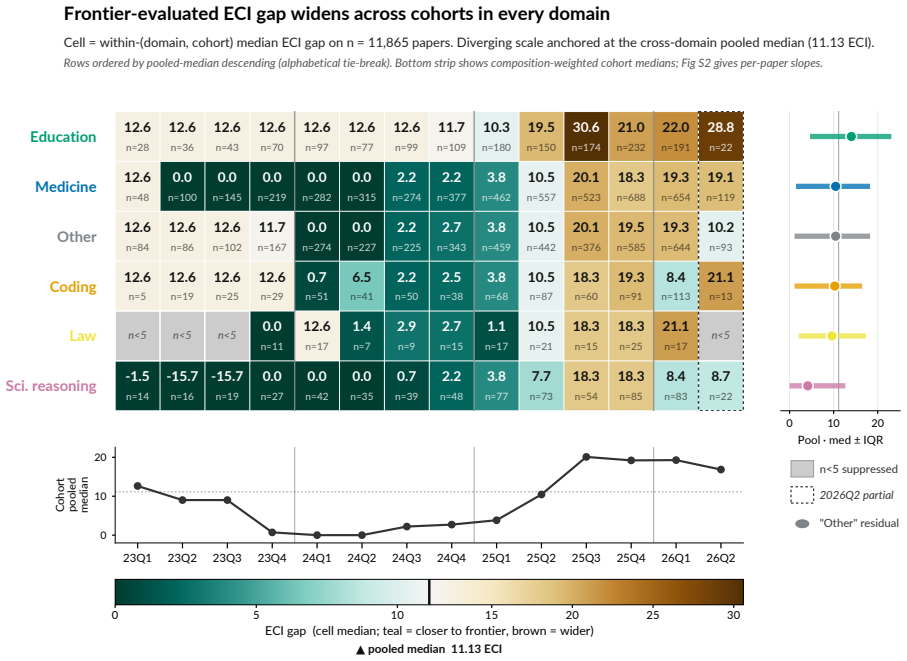
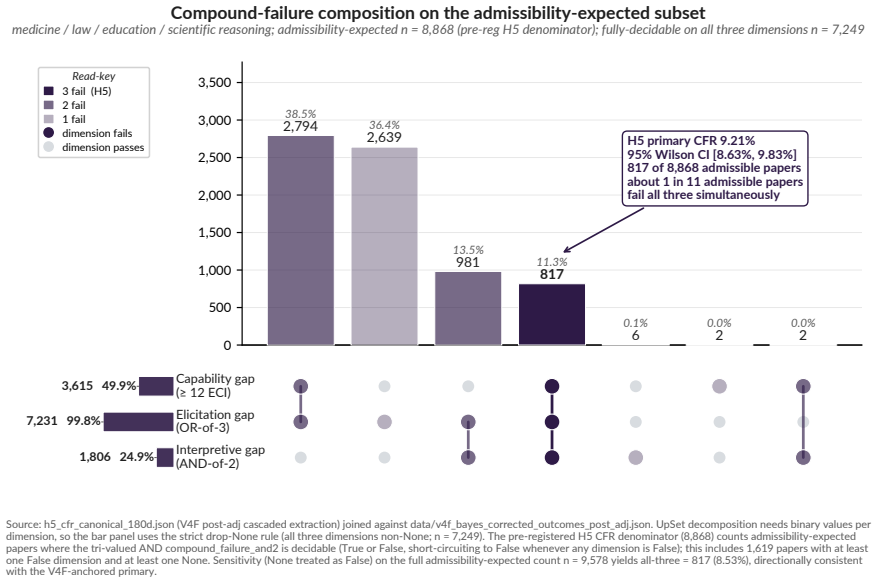
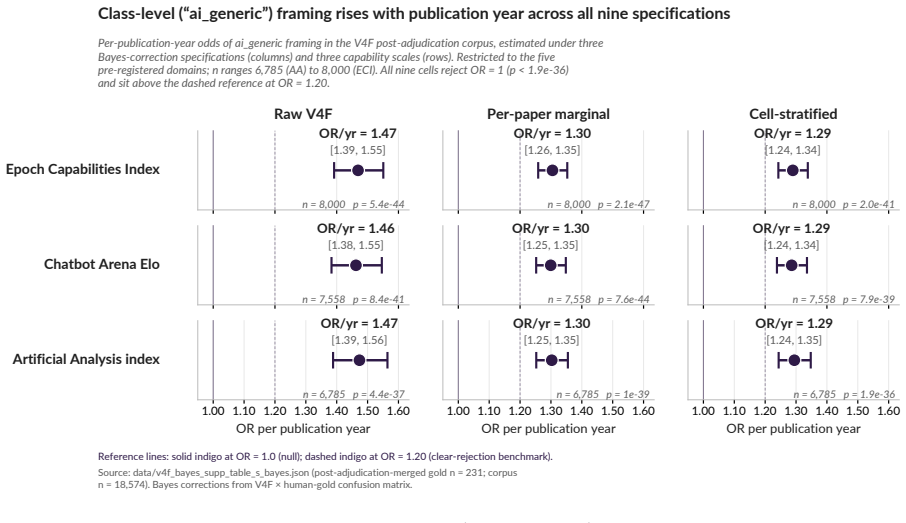
In a pre-registered audit of 18,574 admissible papers, the median evaluation targets a model +10.85 ECI behind the frontier at evaluation time, with the lag widening at +5.53 ECI/year. Only 3.2 percent of abstracts and 21.2 percent of full texts disclose reasoning-mode status on capable models, while 52.5 percent of papers state conclusions at the level of AI rather than the tested models. An exploratory decomposition attributes roughly 25 percent of the lag to peer-review latency and 75 percent to excess lag beyond that.
What carries the argument
The publication elicitation gap, measured by matching tested models in papers to the Epoch AI Capabilities Index (ECI) at the time of evaluation.
If this is right
- The literature answers questions about what older, cheaper models could do rather than what frontier systems can do.
- The observed lag decomposes into about 25 percent peer-review latency and 75 percent excess lag.
- Only a small minority of papers disclose reasoning-mode status even when evaluating capable models.
- Over half the papers generalize conclusions to the level of AI, with this practice increasing over time.
- Remedies such as API-access subsidies and mandatory configuration disclosure checklists are proposed to reduce the gap.
Where Pith is reading between the lines
- Policy and media summaries that draw on this literature may systematically underestimate near-term capabilities.
- A public database linking papers to specific model snapshots could make the elicitation gap visible in real time.
- Extending similar audits to non-academic sources such as technical reports might show whether the pattern is unique to peer-reviewed work.
Load-bearing premise
The Epoch AI Capabilities Index supplies an accurate, time-aligned ranking of model capability that can be reliably matched to the versions described in the papers.
What would settle it
Re-running the audit with a different capability index or with exhaustive manual verification of exact model versions and configurations that yields a median lag near zero.
Figures







read the original abstract
Readers of applied-domain LLM capability evaluations want to know what AI systems can currently do. That literature answers a related, but consequentially different, question: what older, cheaper, less-elicited models could do months or years earlier (a 2026 paper evaluating GPT-3.5 or GPT-4 zero-shot, say, against a frontier of reasoning-capable, tool-using systems like GPT-5.5 Pro and Claude Opus 4.7), often reported with sparse configuration details and abstracted upward into claims about "AI" that propagate through citations, media, and policy. We measure the 'publication elicitation gap' (the gap between these answers) in a pre-registered audit of 112,303 LLM-keyword-matched candidate records (2022-01 to 2026-04; 18,574 admissible, 4,766 full-paper texts retrievable), comparing tested models to the contemporaneous frontier on the Epoch AI Capabilities Index (ECI), reproduced under Arena Elo and Artificial Analysis. The median paper evaluates a model +10.85 ECI (~1.4x the distance between Claude Sonnet 3.7 and Claude Opus 4.5) behind the contemporaneous frontier at evaluation time (H1); an exploratory rational-lag baseline (H8) decomposes this into ~25% peer-review latency, ~75% excess lag. The gap is widening at +5.53 ECI/year (H2; 95% CI [+5.03, +5.83]). Meanwhile, only 3.2% of abstracts (21.2% of full-texts) disclose reasoning-mode status on reasoning-capable models (H4) and 52.5% (95% CI [48.2, 56.9]) state conclusions at the level of "AI" rather than the evaluated model(s), rising at OR = 1.23/year. Proposed remedies include API-access subsidies and editorial enforcement of reporting frameworks mandating configuration-surface disclosure (model snapshot, reasoning mode/effort, tool access, scaffolding, prompting, etc.); VERSIO-AI is a 13-item checklist (Core 3 desk-reject) extending existing frameworks at the elicitation surface, with per-DOI analysis at frontierlag.org.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a pre-registered bibliometric audit of 112,303 LLM-keyword-matched records (18,574 admissible papers, 4,766 full texts) from 2022-01 to 2026-04. It measures the 'publication elicitation gap' by comparing evaluated models against the contemporaneous frontier on the Epoch AI Capabilities Index (ECI, reproduced under Arena Elo and Artificial Analysis), reporting a median lag of +10.85 ECI (H1), a widening trend of +5.53 ECI/year (H2), low disclosure of reasoning mode (3.2% abstracts, 21.2% full texts; H4), and overgeneralization to 'AI' in 52.5% of conclusions (rising at OR=1.23/year). An exploratory decomposition attributes ~25% of lag to peer-review latency. Remedies include API subsidies and the VERSIO-AI 13-item checklist (Core 3 desk-reject).
Significance. If the model-to-ECI matching holds, the findings document a large, growing, and policy-relevant disconnect between published evaluations and frontier capabilities, with direct implications for citation chains, media, and regulation. Credit is due for pre-registration, the large admissible sample with confidence intervals, use of an external non-circular index (Epoch AI ECI), and the open per-DOI analysis at frontierlag.org. The rational-lag baseline (H8) and proposed checklist provide concrete, testable extensions of existing reporting frameworks.
major comments (2)
- [Methods] Methods (model-to-ECI matching): The central claims in H1 (+10.85 ECI median lag) and H2 (+5.53 ECI/year trend) depend on reliable extraction of exact model snapshot/version, evaluation date, and contemporaneous frontier ECI for each paper. The abstract notes sparse configuration details and only 21.2% full-text retrieval; the manuscript must specify the exact matching rules (including handling of generic labels such as 'GPT-4' or 'Claude' without version/date) and report inter-rater reliability for the full-text coding step.
- [Results] Results (H1, H2): The reported median lag and trend are load-bearing for the 'publication elicitation gap' claim, yet the verification gap in model matching (noted in the abstract) leaves open the possibility that systematic assignment choices for underspecified papers could inflate the measured quantities. Provide sensitivity analyses or explicit decision rules for ambiguous cases.
minor comments (2)
- [Abstract] Abstract: The parenthetical example of a 2026 paper evaluating GPT-3.5 against GPT-5.5 Pro should be clarified as illustrative rather than literal, given the study end date of 2026-04.
- [Tables/Figures] Table/Figure captions: Ensure all reported percentages and CIs (e.g., 52.5% [48.2, 56.9]) are cross-referenced to the exact subsample (abstracts vs. full texts) for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We respond to each major comment below and will revise the manuscript accordingly to improve methodological transparency.
read point-by-point responses
-
Referee: [Methods] Methods (model-to-ECI matching): The central claims in H1 (+10.85 ECI median lag) and H2 (+5.53 ECI/year trend) depend on reliable extraction of exact model snapshot/version, evaluation date, and contemporaneous frontier ECI for each paper. The abstract notes sparse configuration details and only 21.2% full-text retrieval; the manuscript must specify the exact matching rules (including handling of generic labels such as 'GPT-4' or 'Claude' without version/date) and report inter-rater reliability for the full-text coding step.
Authors: We agree that the model-to-ECI matching procedure requires explicit documentation. The manuscript already flags the sparse configuration details and 21.2% full-text rate as limitations. In revision we will add a Methods subsection that states the precise decision rules used for model identification, version inference, evaluation-date assignment, and frontier ECI lookup, including explicit protocols for generic labels such as 'GPT-4' or 'Claude'. We will also report inter-rater reliability (Cohen's kappa or equivalent) for the full-text coding of model and configuration variables. revision: yes
-
Referee: [Results] Results (H1, H2): The reported median lag and trend are load-bearing for the 'publication elicitation gap' claim, yet the verification gap in model matching (noted in the abstract) leaves open the possibility that systematic assignment choices for underspecified papers could inflate the measured quantities. Provide sensitivity analyses or explicit decision rules for ambiguous cases.
Authors: We accept that systematic choices for underspecified papers could affect the reported quantities. The revision will (1) codify the decision rules described above and (2) add sensitivity analyses that re-compute the median lag and trend under alternative assignment conventions for ambiguous cases (e.g., earliest plausible version, latest plausible version, and exclusion of ambiguous records). These results will be presented alongside the primary estimates with confidence intervals. revision: yes
Circularity Check
Lag metric computed against external Epoch AI ECI with no self-referential reduction
full rationale
The paper's core quantities (median +10.85 ECI lag in H1; +5.53 ECI/year trend in H2) are defined as direct comparisons of extracted model versions from audited papers against the contemporaneous value on the Epoch AI Capabilities Index, which is an external, pre-existing benchmark reproduced under Arena Elo and Artificial Analysis. No equation or procedure in the manuscript defines the lag or trend in terms of quantities fitted from the audited corpus itself, nor does any load-bearing step reduce to a self-citation, ansatz, or renaming of the target result. The measurement pipeline (paper retrieval, model extraction, date alignment, ECI lookup) is independent of the final lag statistic by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Epoch AI Capabilities Index accurately ranks models relative to the frontier at any given date
- domain assumption The 18,574 admissible papers form a representative sample of LLM evaluation literature
invented entities (1)
-
publication elicitation gap
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Scaffold Effects on GAIA: A Controlled Comparison
A controlled comparison shows scaffold choice alters GAIA Level 1-2 accuracy by up to 28 points, with effects varying by model family rather than capability tier alone.
Reference graph
Works this paper leans on
-
[1]
Apollo Research
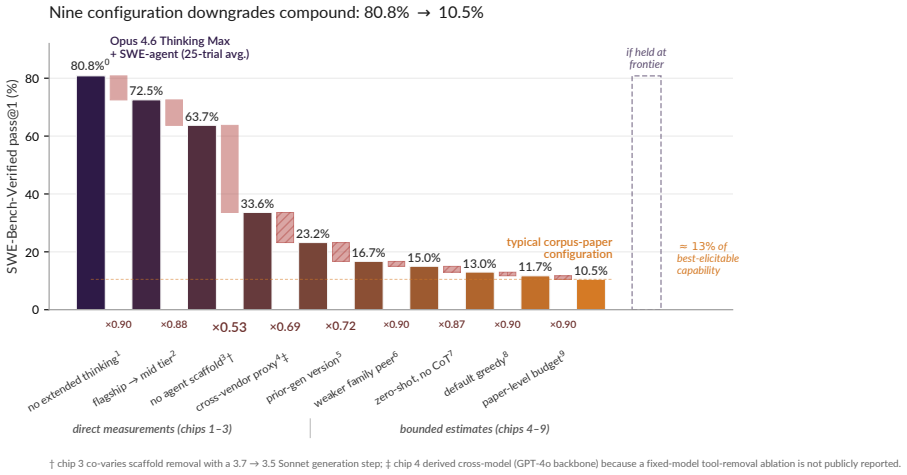
Released February 5, 2026; cited for the Opus 4.6 Thinking Max 25-trial-average pass@1 of 80.8%on SWE-Bench-Verified (non-prompt-modified baseline); accessed 2026-04-23. Apollo Research. The evals gap. Apollo Research Blog, 2024. URLhttps://www.apolloresearch. ai/blog/the-evals-gap/. Published November 11, 2024. Grey literature; cited for the qualitative ...
2026
-
[2]
255-paper audit of GPT-3.5/GPT-4 ChatGPT-interface studies; 4.7M contaminated samples catalogued; nearest structural ancestor to this paper. Sebastian Baltes, Florian Angermeir, Chetan Arora, Marvin Muñoz Barón, Chunyang Chen, Lukas Böhme, Fabio Calefato, Neil Ernst, Davide Falessi, Brian Fitzgerald, Davide Fucci, Junda He, Christoph Treude, Marcos Kalino...
2025
-
[3]
Thirty-six-author systematic review of445LLM benchmarks from leading conferences; eight design recommendations targeting benchmark construct validity. 39 Andrew M Bean, Rebecca Elizabeth Payne, Guy Parsons, Hannah Rose Kirk, Juan Ciro, Rafael Mosquera-Gómez, Sara Hincápié M, Aruna S Ekanayaka, Lionel Tarassenko, Luc Rocher, and Adam Mahdi. Reliability of ...
-
[4]
Methodological template closest to the present audit: construct-named corpus audit of a capability-or-safety claim class, with code and reporting-discipline remedy. ShaSajadieh, LoredanaFattorini, RaymondPerrault, YolandaGil, VanessaParli, LapoSantarlasci, Juan Pava, Nestor Maslej, Russ Altman, Erik Brynjolfsson, Carla Brodley, Jack Clark, Virginia Dignum...
-
[5]
URL https://www.aisi.gov.uk/frontier-ai-trends-report. First public evidence-based assessment aggregating two years of AISI’s frontier model testing (November 2023 through October 2025); cited for the frontier-trajectory reframe of capability evaluation. Baptiste Vasey, Myura Nagendran, others, and DECIDE-AI Expert Group. Reporting guideline for the early...
-
[6]
doi: 10.1145/3715754. Published at FSE 2025; arXiv preprint posted July 2024. Table 6 used to ground the SWE-Bench-Verified scaffolding, tool-access, and cross-family chips in the Figure 4 waterfall. John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable au...
-
[7]
Model version, to the exact identifier the provider exposes
-
[8]
Provider and access method
-
[9]
Block B: Tier and comparator context
Access or evaluation date window. Block B: Tier and comparator context
-
[10]
Within-family tier and rationale for tier selection
-
[11]
Declared capability frame (frontier / deployment / tier-specific), coherent with the tier identified under Item 1. 46
-
[12]
Block C: Configuration and elicitation
Comparator presence, type, and version (human experts, baseline LLMs with full configuration disclosed, non-LLM baselines, historical controls, or none stated). Block C: Configuration and elicitation
-
[13]
Reasoning mode status, where applicable
-
[14]
Reasoning effort or thinking budget, where applicable
-
[15]
Tool use and retrieval
-
[16]
Scaffolding, agent framework, and multi-turn structure
-
[17]
Block D: Evaluation and interpretation
Prompting strategy. Block D: Evaluation and interpretation
-
[18]
Sampling parameters and number of runs per item
-
[19]
models which are highly specialized may receive loweciscores, despite being very capable within their domain
Conclusion-evidence concordance and valence-conditional caveats. Full text of each item, including rationale, good example, and bad example, appears in the standalone versio-aiv1.2 specification. Note on weighted composites: a weighted Elicitation Completeness composite over Items 7 to 11 is exposed by the companionfrontierlagtool as an optional derived s...
2020
-
[20]
All systems exhibitX
Determiner-headed collectives are anaphoric, not generic.“All systems exhibitX” with prior named models is an anaphoric reference; code asmodel_specific. Contrast with bare plural “LLMs exhibitX” as generic
-
[21]
Commercial LLMs,
Modifier-bounded generic terms remain generic.“Commercial LLMs,” “open-source LLMs,” 18The field replaces an earlier design in which downstream analysis would have usedvalence == negative as a proxy, a proxy that confounded valence (direction) with framing (scope). 50 “reasoning-capable LLMs” are still generic subjects; code asai_generic
-
[22]
LLMs like ChatGPT-4,
Hedged-generic constructions keep the generic term as subject.“LLMs like ChatGPT-4,” “AI tools such as Claude” are generic subjects with an illustrative modifier; code asai_generic
-
[23]
The LLM tested,
Definite-specifier singulars are specific.“The LLM tested,” “the evaluated system” refer to the tested instance; code asmodel_specific
-
[24]
AI could become...,
Forward-projection and implication sentences with generic subjects count as findings. “AI could become...,” “LLMs may be ready...,” and implication sentences with generic subjects triggerai_generic
-
[25]
LLM-based methods
Category descriptors vs named artefacts.“LLM-based methods” is a class-level claim (ai_generic) unless the subject is a named artefact (“LogReader,” “our RAG pipeline”), which is model_specific. Dev-set stability metrics The dev-set stability metrics come from two temperature-0 runs on the 600-paper development set.19 The values: •Inclusion flip rate:3.0%...
2023
-
[26]
2 to 5.Four valence-cellz-tests (negativep = 0.18; mixedp = 0.035; neutralp = 0.021; positivep = 0.92)
Two-proportionzon overall inclusion rate (p≈0).Survives. 2 to 5.Four valence-cellz-tests (negativep = 0.18; mixedp = 0.035; neutralp = 0.021; positivep = 0.92). None survive. 6 to 7.Two framing-cellz-tests (ai_genericp = 0.005; model_specificp = 0.005). Neither survives; counting both cells of a binary indicator is the conservative-multiple-comparisons po...
-
[27]
Does not survive
Frontier-gap proxy Mann-WhitneyU (p = 0.083). Does not survive. The per-quantile descriptive statistics (median, mean,p25, p75) are reported alongside as descriptive add-ons rather than as additional family members. 18.eval_date-disclosurez-test (p= 0.51). Does not survive. Bonferroni αfamily = 0.05at k = 18implies a per-test α= 0.0028. Five tests cross t...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.