Recognition: unknown
Benchmarking LLMs on the Massive Sound Embedding Benchmark (MSEB)
Pith reviewed 2026-05-08 17:11 UTC · model grok-4.3
The pith
LLMs still trail specialized audio models on key sound tasks, yet results do not identify one superior architecture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Rigorous testing across the eight MSEB capabilities shows that current LLMs exhibit a significant modality gap in both performance and robustness relative to specialized audio encoders, while the empirical record remains inconclusive about the existence of an optimal modeling strategy; the suitability of audio-native versus cascaded designs therefore hinges on concrete application constraints such as latency, cost, and required reasoning depth.
What carries the argument
The Massive Sound Embedding Benchmark (MSEB) and its eight core audio capabilities, which serve as the common testbed for measuring functional breadth in both specialized encoders and general-purpose LLMs.
If this is right
- LLMs continue to show measurable shortfalls in audio performance and robustness compared with specialized encoders.
- No modeling paradigm emerges as clearly preferable on the basis of the current benchmark results.
- Selection between audio-native LLMs and cascaded systems must be made case-by-case according to latency, cost, and reasoning requirements.
Where Pith is reading between the lines
- Developers may need to maintain hybrid pipelines for high-stakes audio work until the modality gap narrows on independent test sets.
- Future work could isolate which of the eight capabilities drive most of the observed gap to guide targeted improvements.
- The inconclusive outcome suggests evaluating candidate models on downstream product tasks rather than benchmark scores alone.
Load-bearing premise
The eight core capabilities measured by MSEB supply a sufficient and unbiased picture of what counts as functional breadth for audio tasks.
What would settle it
A controlled experiment that applies the same LLMs and encoders to a fresh collection of audio tasks lying outside the eight MSEB capabilities and finds consistent superiority of one architectural family across those tasks.
Figures






read the original abstract
The Massive Sound Embedding Benchmark (MSEB) has emerged as a standard for evaluating the functional breadth of audio models. While initial baselines focused on specialized encoders, the shift toward "audio-native" Large Language Models (LLMs) suggests a new paradigm where a single multimodal backbone may replace complex, task-specific pipelines. This paper provides a rigorous empirical evaluation of leading LLMs - including members from the Gemini and GPT families - across the eight core MSEB capabilities to assess their efficacy and audio-text parity. Our results indicate that while a significant modality gap persists regarding performance and robustness, the empirical evidence for an "optimal" modeling approach remains inconclusive. Ultimately, the choice between audionative and cascaded architectures depends heavily on specific use-case requirements and the underlying assumptions regarding latency, cost, and reasoning depth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical evaluation of leading audio-native LLMs (Gemini and GPT families) on the eight core capabilities of the Massive Sound Embedding Benchmark (MSEB). It finds that a modality gap persists in both performance and robustness relative to specialized encoders, yet the data do not support any single modeling strategy (audio-native versus cascaded) as clearly superior.
Significance. If the reported numbers are reproducible, the work supplies a timely, side-by-side comparison that quantifies current limitations of general-purpose LLMs on audio tasks and underscores the context-dependent trade-offs among latency, cost, and reasoning depth. The deliberately non-committal conclusion is a strength rather than a weakness.
major comments (2)
- The abstract states that the evaluation is 'rigorous' yet supplies no information on exact model versions, prompting templates, decoding parameters, or the precise definition of each MSEB metric. Without these details the claimed performance gaps cannot be independently verified or extended.
- No statistical tests, confidence intervals, or variance estimates are mentioned for the reported differences across the eight capabilities. This weakens the assertion of a 'significant' modality gap.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and constructive comments, which have helped us improve the manuscript's clarity and rigor. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: The abstract states that the evaluation is 'rigorous' yet supplies no information on exact model versions, prompting templates, decoding parameters, or the precise definition of each MSEB metric. Without these details the claimed performance gaps cannot be independently verified or extended.
Authors: We agree that these implementation details are essential for reproducibility. In the revised manuscript we have added a new subsection in the Methods section that specifies the exact model versions (Gemini-1.5-Pro-001, GPT-4o-2024-05-13, etc.), the full prompting templates, decoding parameters (temperature = 0, top_p = 1), and the precise mathematical definitions of each of the eight MSEB metrics as defined in the original benchmark. We have also updated the abstract to remove the unqualified use of 'rigorous' and refer readers to the Methods for these details. revision: yes
-
Referee: No statistical tests, confidence intervals, or variance estimates are mentioned for the reported differences across the eight capabilities. This weakens the assertion of a 'significant' modality gap.
Authors: This is a fair criticism. Although the observed gaps are large and consistent, we have revised the Results section to include bootstrap 95% confidence intervals for all reported differences and paired statistical tests (McNemar’s test for classification-style tasks and Wilcoxon signed-rank test for regression-style tasks) where multiple evaluation samples were available. We now qualify the term 'significant' with these quantitative results and note the limitation that some LLM runs were performed only once due to API cost constraints. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical benchmarking study that reports performance of LLMs on the external MSEB tasks. No derivations, equations, fitted parameters, or self-referential definitions appear in the provided text. The central claim—that a modality gap persists while evidence for an optimal architecture remains inconclusive—is non-committal and rests only on the observed metrics, without requiring the benchmark to be exhaustive or unbiased. No load-bearing step reduces to its own inputs by construction, and the analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
This evolution is primarily driven by the emergence of ”Audio-Native” Large Language Models (LLMs)
Introduction The landscape of artificial intelligence is currently undergoing a paradigm shift, transitioning from specialized, unimodal sys- tems toward integrated auditory intelligence. This evolution is primarily driven by the emergence of ”Audio-Native” Large Language Models (LLMs). Unlike previous generations that relied on cascaded pipelines—where s...
-
[2]
Benchmarking LLMs on the Massive Sound Embedding Benchmark (MSEB)
Related Work The evolution of auditory intelligence has transitioned from modular, task-specific pipelines toward unified, audio-native architectures. This section situates our evaluation within the broader context of recent architectural shifts and the bench- marks developed to assess them. A new generation of audio-native multimodal LLMs has emerged. Ex...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
While LLMs are natively suited for generative tasks—such as reasoning - adapting them to non-generative tasks like retrieval remains challenging
Methodology: Applying LLMs to MSEB This section details the technical methodology for address- ing the various tasks within the MSEB benchmark using LLMs. While LLMs are natively suited for generative tasks—such as reasoning - adapting them to non-generative tasks like retrieval remains challenging. To maintain a unified framework, we integrate these dive...
-
[4]
Experimental Setup In this section, we briefly describe the models and the Massive Sound Embedding Benchmark (MSEB) [1] utilized for the em- pirical evaluation and analysis presented in Section 5. 4.1. Models Evaluated Our evaluation covers a diverse set of audio-native MLLMs, including both commercially restricted (proprietary) and open- weight models, s...
-
[5]
A high-level overview of these results is provided in Table 1
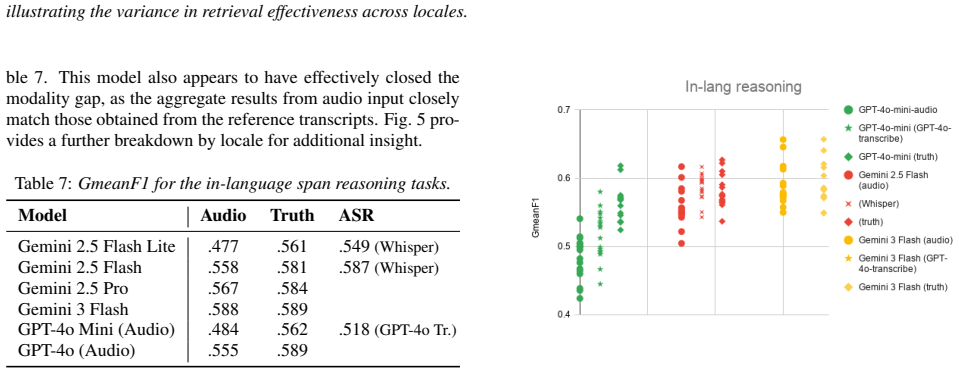
Empirical Evaluation We present and discuss the results on a task-by-task basis in the following subsections. A high-level overview of these results is provided in Table 1. Furthermore, Section 6 offers a more granular analysis of these findings through the lens of audio- text parity. 5.1. Speech transcription WER averaged across all locales for various c...
-
[6]
Audio-text parity Audio-text parity refers to the functional equivalence between processing a prompt in audio format versus its textual counter- part. Informally, this implies that the ”I type” and ”I speak” modalities achieve comparable performance across tasks, en- suring that no information or reasoning capability is lost when switching from text to sp...
-
[7]
In addition, this paper includes a rigorous analysis of audio-text parity, demonstrating that a significant modality gap persists across most MSEB tasks
Conclusion & Future Work We demonstrated the application of general-purpose LLMs to MSEB tasks and provided a multi-dimensional evaluation of their performance. In addition, this paper includes a rigorous analysis of audio-text parity, demonstrating that a significant modality gap persists across most MSEB tasks. Performance re- mains heavily contingent o...
-
[8]
Massive sound embedding benchmark (mseb),
G. Heigold, E. Variani, T. Bagby, C. Allauzen, J. Ma, S. Kumar, and M. D. Riley, “Massive sound embedding benchmark (mseb),” inProceedings of the International Conference on Neural Infor- mation Processing Systems (NeurIPS), 2025
2025
-
[9]
Advanced audio dia- log and generation with gemini 2.5,
A. Bapna and T. Sainath, “Advanced audio dia- log and generation with gemini 2.5,” 2025. [Online]. Available: https://blog.google/products-and-platforms/products/ gemini/gemini-audio-model-updates
2025
-
[10]
Gpt-4o system card,
OpenAI, “Gpt-4o system card,” 2024. [Online]. Available: https://openai.com/index/gpt-4o-system-card/
2024
-
[11]
These developers are changing lives with gemma 3n,
G. Cameron and K. Quan, “These developers are changing lives with gemma 3n,” 2025. [Online]. Available: https://blog.google/innovation-and-ai/technology/ developers-tools/developers-changing-lives-with-gemma-3n/
2025
-
[12]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2503.20215
work page internal anchor Pith review arXiv 2025
-
[13]
Amazon nova multimodal em- beddings: Technical report and model card,
A. A. G. Intelligence, “Amazon nova multimodal em- beddings: Technical report and model card,” 2025. [Online]. Available: https://www.amazon.science/publications/ amazon-nova-multimodal-embeddings-technical-report-and-model-card
2025
-
[14]
Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix,
Z. Ma, Y . Ma, Y . Zhu, C. Yang, Y .-W. Chao, R. Xu, W. Chen, Y . Chen, Z. Chen, J. Cong, K. Li, K. Li, S. Li, X. Li, X. Li, Z. Lian, Y . Liang, M. Liu, Z. Niu, T. Wanget al., “Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix,” inAdvances in Neural Information Processing Systems (NeurIPS) 2025 Datasets and Benchmarks...
2025
-
[15]
Superb: Speech processing universal performance benchmark,
S.-W. Yang, P.-H. Chi, Y .-S. Chuang, C.-I. Lai, K. Lakhotia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, T. hsien Huang, W.-C. Tseng, K. tik Lee, D.-R. Liu, Z. Huang, S. Dong, S.-W. Li, S. Watanabe, A. rahman Mohamed, and H. yi Lee, “Superb: Speech processing universal performance benchmark,” inInterspeech, 2021. [Online]. Available: https://api...
2021
-
[16]
Dynamic- superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech,
C. yu Huang, K.-H. Lu, S. Wang, C.-Y . Hsiao, C.-Y . Kuan, H. Wu, S. Arora, K.-W. Chang, J. Shi, Y . Peng, R. Sharma, S. Watanabe, B. Ramakrishnan, S. Shehata, and H. yi Lee, “Dynamic- superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech,”ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech a...
2024
-
[17]
AudioBench: A universal benchmark for audio large language models,
B. Wang, X. Zou, G. Lin, S. Sun, Z. Liu, W. Zhang, Z. Liu, A. Aw, and N. F. Chen, “AudioBench: A universal benchmark for audio large language models,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), L. Chiruzzo, A. Ritter, and...
2025
-
[18]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
S. Sakshi, U. Tyagi, S. Kumar, A. Seth, S. Ramaneswaran, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha, “Mmau: A massive multi-task audio understanding and reasoning benchmark,”ArXiv, vol. abs/2410.19168, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:273638254
work page internal anchor Pith review arXiv 2024
-
[19]
S. Kumar, ˇS. Sedl ´aˇcek, V . Lokegaonkar, F. L ´opez, W. Yu, N. Anand, H. Ryu, L. Chen, M. Pli ˇcka, M. Hlav ´aˇceket al., “Mmau-pro: A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence,”arXiv preprint arXiv:2508.13992, 2025
-
[20]
Maeb: Massive audio embedding benchmark,
A. E. Assadi, I. Chung, C. Xiao, R. Solomatin, A. Jha, R. Chand, S. Singh, K. Wang, A. S. Khan, M. M. Nasser, S. Fong, P. He, A. Xiao, A. S. Munot, A. Shrivastava, A. Gazizov, N. Muennighoff, and K. Enevoldsen, “Maeb: Massive audio embedding benchmark,” 2026. [Online]. Available: https://arxiv.org/abs/2602.16008
-
[21]
Evaluating speech-to-text x LLM x text- to-speech combinations for ai interview systems,
R. Allbert, N. Yazdani, A. Ansari, A. Mahajan, A. Afsharrad, and S. S. Mousavi, “Evaluating speech-to-text x LLM x text- to-speech combinations for ai interview systems,”arXiv preprint arXiv:2507.16835, 2025
-
[22]
Gemini embedding: Generalizable embeddings from gemini,
J. Lee, F. Chen, S. Dua, D. Cer, M. Shanbhogue, I. Naim, G. H. ´Abrego, Z. Li, K. Chen, H. S. Vera, X. Ren, S. Zhang, D. Salz, M. Boratko, J. Han, B. Chen, S. Huang, V . Rao, P. Suganthan, F. Han, A. Doumanoglou, N. Gupta, F. Moiseev, C. Yip, A. Jain, S. Baumgartner, S. Shahi, F. P. Gomez, S. Mariserla, M. Choi, P. Shah, S. Goenka, K. Chen, Y . Xia, K. Ch...
-
[23]
Gemini Embedding: Generalizable Embeddings from Gemini
[Online]. Available: https://arxiv.org/abs/2503.07891
work page internal anchor Pith review arXiv
-
[24]
Speech-massive: A multilingual speech dataset for slu and be- yond,
B. Lee, I. Calapodescu, M. Gaido, M. Negri, and L. Besacier, “Speech-massive: A multilingual speech dataset for slu and be- yond,” inInterspeech, 2024
2024
-
[25]
Fsd50k: An open dataset of human-labeled sound events,
E. Fonseca, X. Favory, J. Pons, F. Font, and X. Serra, “Fsd50k: An open dataset of human-labeled sound events,”IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 30, p. 829–852, Dec
-
[26]
Available: https://doi.org/10.1109/TASLP.2021
[Online]. Available: https://doi.org/10.1109/TASLP.2021. 3133208
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.