ML-Embed: Inclusive and Efficient Embeddings for a Multilingual World
Pith reviewed 2026-06-30 20:22 UTC · model grok-4.3
The pith
The 3D-ML framework produces multilingual embeddings that set new records on nine MTEB benchmarks while excelling in low-resource languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
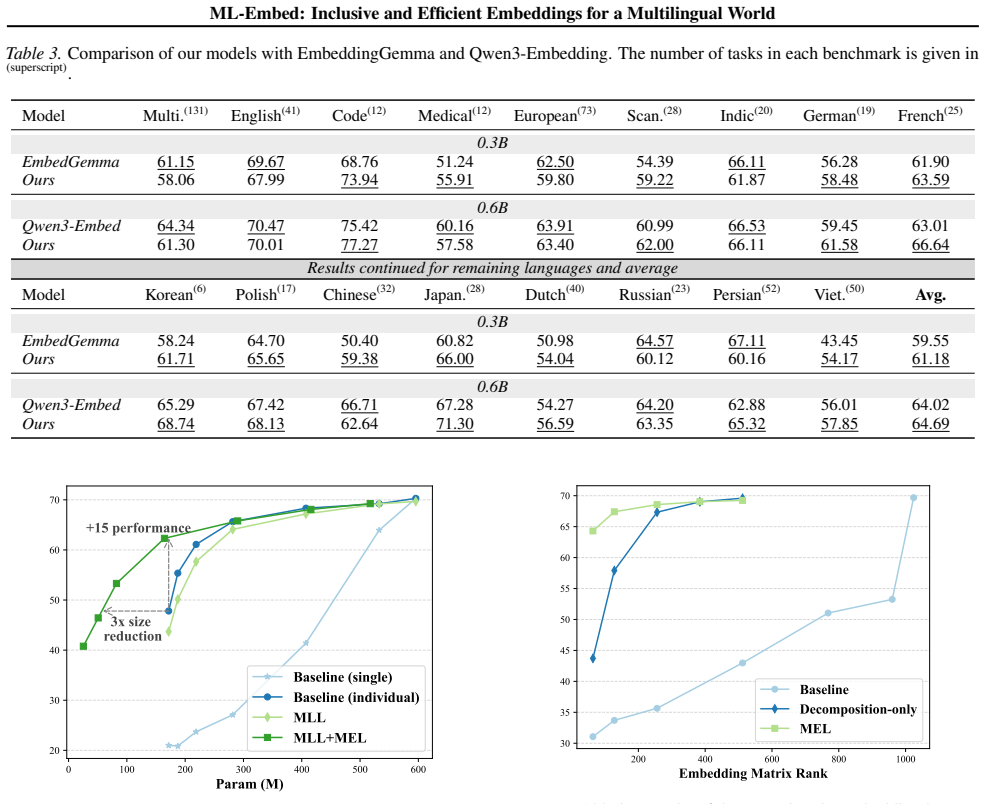
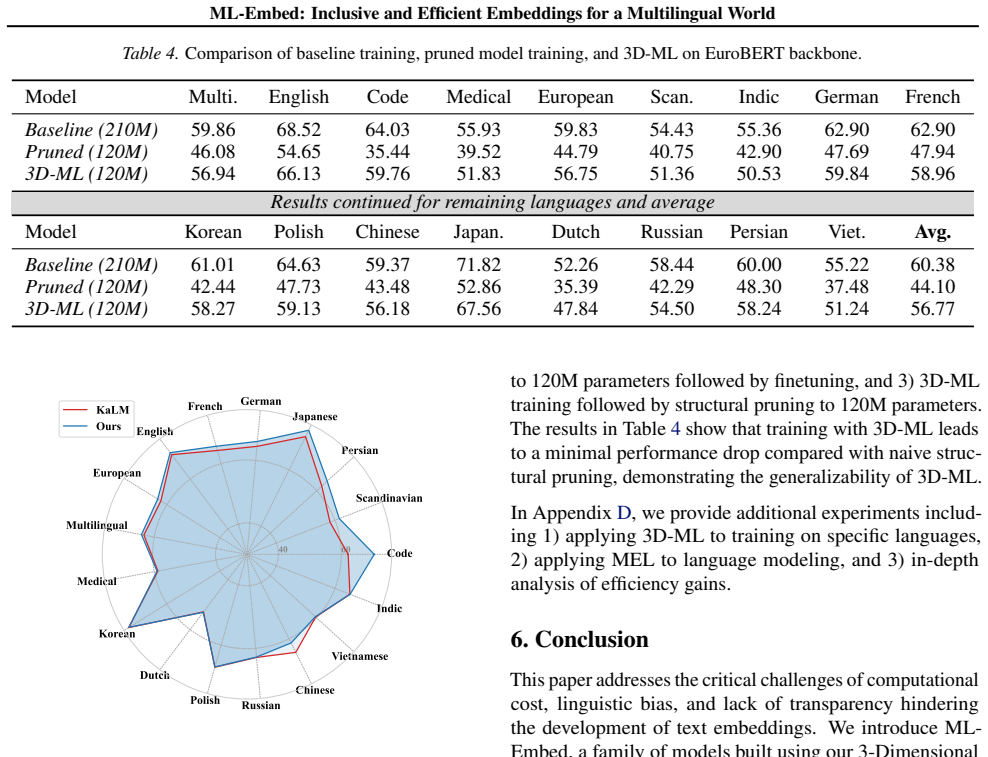
The central claim is that the 3-Dimensional Matryoshka Learning framework, by extending Matryoshka Representation Learning and Matryoshka Layer Learning with a new Matryoshka Embedding Learning component for parameter efficiency, enables the creation of a suite of multilingual embedding models that achieve new state-of-the-art results on nine of seventeen MTEB benchmarks, especially for low-resource languages, while delivering efficiency across the full model lifecycle.
What carries the argument
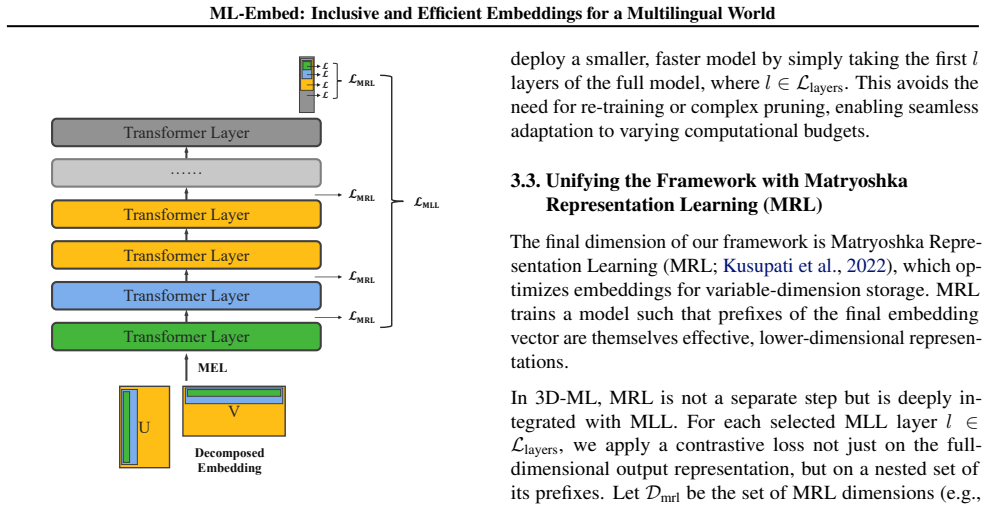
The 3-Dimensional Matryoshka Learning (3D-ML) framework, which introduces Matryoshka Embedding Learning to achieve parameter efficiency in addition to storage and inference-time depth benefits.
If this is right
- Models set new records on 9 of 17 evaluated MTEB benchmarks.
- Particularly strong results appear in low-resource languages.
- Efficiency improvements span storage, inference depth, and parameter count.
- Full public release of models, data, and code supports reproducibility.
- The approach supplies a blueprint for globally equitable embedding systems.
Where Pith is reading between the lines
- The open release may enable other groups to build on the same data and framework for additional languages.
- Smaller models in the released suite could support deployment in settings with limited compute.
- The efficiency properties might reduce the frequency of retraining for new language pairs.
- Strong low-resource performance could decrease reliance on separate monolingual embedding models.
Load-bearing premise
The benchmark gains arise directly from the 3D-ML framework and the curated multilingual dataset without undisclosed post-training adjustments or data choices.
What would settle it
Independent execution of the released code and models on the same 430 evaluation tasks to check whether the claimed new records on the nine MTEB benchmarks are reproduced.
Figures

read the original abstract
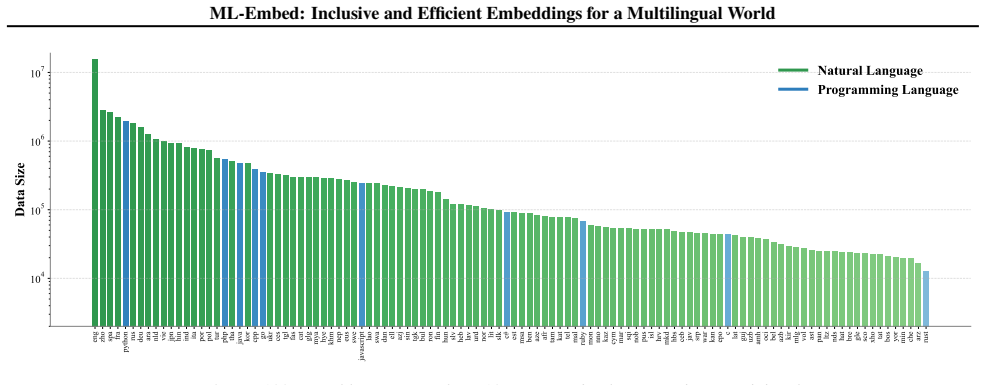
The development of high-quality text embeddings is increasingly drifting toward an exclusionary future, defined by three critical barriers: prohibitive computational costs, a narrow linguistic focus that neglects most of the world's languages, and a lack of transparency from closed-source or open-weight models that stifles research. To dismantle these barriers, we introduce ML-Embed, a suite of inclusive and efficient models built upon a new framework: 3-Dimensional Matryoshka Learning (3D-ML). Our framework addresses the computational challenge with comprehensive efficiency across the entire model lifecycle. Beyond the storage benefits of Matryoshka Representation Learning (MRL) and flexible inference-time depth provided by Matryoshka Layer Learning (MLL), we introduce Matryoshka Embedding Learning (MEL) for enhanced parameter efficiency. To address the linguistic challenge, we curate a massively multilingual dataset and train a suite of models ranging from 140M to 8B parameters. In a direct commitment to transparency, we release all models, data, and code. Extensive evaluation on 430 tasks demonstrates that our models set new records on 9 of 17 evaluated MTEB benchmarks, with particularly strong results in low-resource languages, providing a reproducible blueprint for building globally equitable and computationally efficient AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ML-Embed, a suite of multilingual text embedding models (140M to 8B parameters) trained on a newly curated massively multilingual dataset using the 3D-ML framework. This framework extends Matryoshka Representation Learning (MRL) and Matryoshka Layer Learning (MLL) with a new Matryoshka Embedding Learning (MEL) component to improve parameter efficiency across the model lifecycle. The authors report new state-of-the-art results on 9 of 17 MTEB benchmarks from evaluations on 430 tasks, with particular gains in low-resource languages, and release all models, data, and code for transparency.
Significance. If the results hold after proper controls, the work would be significant for advancing open, efficient, and linguistically inclusive embedding models. The full release of models, data, and code is a clear strength that supports reproducibility. The focus on low-resource languages and computational efficiency addresses important practical barriers in the field.
major comments (2)
- [Results / Experiments] The central claim attributes performance and efficiency gains to the 3D-ML framework (MRL + MLL + MEL), yet no component-wise ablations are presented that train a standard contrastive baseline on the identical curated dataset. Without these controls, it is impossible to determine whether the reported MTEB records stem from the framework or from the dataset itself.
- [Evaluation] The abstract and evaluation sections state new records on 9 of 17 MTEB benchmarks across 430 tasks, but provide no error analysis, variance across runs, or details on how the 17 benchmarks were selected from the full MTEB suite. This makes it difficult to assess the robustness of the headline claims.
minor comments (2)
- [Methods] Notation for the three components of 3D-ML (MRL, MLL, MEL) should be introduced with explicit equations or pseudocode in the methods section to clarify how MEL differs from prior Matryoshka variants.
- [Efficiency Analysis] The manuscript should include a table comparing training and inference FLOPs or memory usage against prior open multilingual embedding models to substantiate the efficiency claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the attribution of results and the robustness of our evaluation claims. We address each major point below and commit to revisions that strengthen the manuscript without overstating current content.
read point-by-point responses
-
Referee: The central claim attributes performance and efficiency gains to the 3D-ML framework (MRL + MLL + MEL), yet no component-wise ablations are presented that train a standard contrastive baseline on the identical curated dataset. Without these controls, it is impossible to determine whether the reported MTEB records stem from the framework or from the dataset itself.
Authors: We agree this is a substantive gap. The manuscript presents 3D-ML as an integrated framework with MEL as the novel extension, but does not isolate its contribution from the new dataset via direct ablations against a standard contrastive baseline on the same data. We will add these component-wise ablations in the revised version to better support the central claim. revision: yes
-
Referee: The abstract and evaluation sections state new records on 9 of 17 MTEB benchmarks across 430 tasks, but provide no error analysis, variance across runs, or details on how the 17 benchmarks were selected from the full MTEB suite. This makes it difficult to assess the robustness of the headline claims.
Authors: We accept that additional details are needed. The 17 benchmarks represent a multilingual-focused subset of MTEB with emphasis on low-resource languages, but selection criteria are not explicitly stated. We will revise the evaluation section to document the selection process, include error analysis on representative tasks, and report run variance or note its absence as a limitation. This addresses robustness without new experiments beyond what is feasible. revision: partial
Circularity Check
No significant circularity; empirical claims rest on training and evaluation.
full rationale
The paper introduces an empirical framework (3D-ML combining MRL, MLL, and MEL) and a curated multilingual dataset, then reports benchmark results from model training and evaluation on 430 tasks. No mathematical derivations, equations, or prediction steps are described that could reduce outputs to inputs by construction. Performance claims are presented as outcomes of training rather than fitted parameters renamed as predictions or self-referential definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in a way that creates circularity. The analysis is self-contained as standard empirical ML work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MM-Matryoshka: Towards Budget-Elastic Visual Document Retrieval via a 2D Multimodal Matryoshka Training Framework
MM-Matryoshka is a 2D Matryoshka training framework enabling budget-elastic ColPali-style multi-vector visual document retrieval along dimension and layer without separate models per budget.
Reference graph
Works this paper leans on
-
[2]
ReflecTool: Towards Reflection- Aware Tool-Augmented Clinical Agents
URL https://huggingface. co/datasets/Mohammed-Altaf/ medical-instruction-120k. Bai, Y ., Du, X., Liang, Y ., Jin, L., Zhou, J., Liu, Z., Fang, F., Chang, M., Zheng, T., Zhang, X., Ma, N., Wang, Z. M., Yuan, R., Wu, H., Lin, H., Huang, W., Zhang, J., Lin, C., Fu, J., Yang, M., Ni, S., and Zhang, G. COIG-CQIA: quality is all you need for chinese instruction...
-
[6]
Dettmers, T., Pagnoni, A., Holtzman, A., and Zettle- moyer, L
URL https://openreview.net/forum? id=mZn2Xyh9Ec. Dettmers, T., Pagnoni, A., Holtzman, A., and Zettle- moyer, L. Qlora: Efficient finetuning of quantized llms. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2...
-
[7]
URL https:// doi.org/10.18653/v1/p19-1346
doi: 10.18653/V1/P19-1346. URL https:// doi.org/10.18653/v1/p19-1346. Filippova, K. and Altun, Y . Overcoming the lack of parallel data in sentence compression. InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, 18-21 October 2013, Grand Hyatt Seattle, Seattle, Washington, USA, A meeting of SIGDAT, a Spec...
-
[8]
Retrieval-Augmented Generation for Large Language Models: A Survey
ACL, 2013. doi: 10.18653/V1/D13-1155. URL https://doi.org/10.18653/v1/d13-1155. FitzGerald, J., Hench, C., Peris, C., Mackie, S., Rottmann, K., Sanchez, A., Nash, A., Urbach, L., Kakarala, V ., Singh, R., Ranganath, S., Crist, L., Britan, M., Leeuwis, W., T¨ur, G., and Natarajan, P. MASSIVE: A 1m-example multilingual natural language understanding dataset...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d13-1155 2013
-
[9]
URL https://openreview.net/forum? id=sE7-XhLxHA. He, W., Liu, K., Liu, J., Lyu, Y ., Zhao, S., Xiao, X., Liu, Y ., Wang, Y ., Wu, H., She, Q., Liu, X., Wu, T., and Wang, H. Dureader: a chinese machine reading compre- hension dataset from real-world applications. In Choi, E., Seo, M., Chen, D., Jia, R., and Berant, J. (eds.), Proceedings of the Workshop on...
-
[10]
Hermann, K
URL https://openreview.net/forum? id=GdXI5zCoAt. Hermann, K. M., Kocisk ´y, T., Grefenstette, E., Espeholt, L., Kay, W., Suleyman, M., and Blunsom, P. Teaching machines to read and comprehend. In Cortes, C., Lawrence, N. D., Lee, D. D., Sugiyama, M., and Garnett, R. (eds.),Advances in Neural Information Processing Systems 28: Annual Conference on Neural I...
2015
-
[11]
Hu, H., Richardson, K., Xu, L., Li, L., K ¨ubler, S., and Moss, L
URL https://openreview.net/forum? id=nZeVKeeFYf9. Hu, H., Richardson, K., Xu, L., Li, L., K ¨ubler, S., and Moss, L. S. OCNLI: original chinese natural lan- guage inference. In Cohn, T., He, Y ., and Liu, Y . (eds.),Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 Novem- ber 2020, volume EMNLP 2020 ofFindings of A...
-
[13]
Gemini Embedding: Generalizable Embeddings from Gemini
URL https://aclanthology.org/2005. mtsummit-papers.11. K¨oksal, A., Thaler, M., Imani, A., ¨Ust¨un, A., Korho- nen, A., and Sch ¨utze, H. MURI: high-quality instruc- tion tuning datasets for low-resource languages via re- verse instructions.Trans. Assoc. Comput. Linguistics, 13:1032–1055, 2025. doi: 10.1162/TACL.A.18. URL https://doi.org/10.1162/tacl.a.18...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/tacl.a.18 2005
-
[17]
Lost in the Middle: How Language Models Use Long Contexts
doi: 10.1162/TACL \ A\ 00343. URL https: //doi.org/10.1162/tacl_a_00343. Lo, K., Wang, L. L., Neumann, M., Kinney, R., and Weld, D. S. S2ORC: the semantic scholar open research corpus. In Jurafsky, D., Chai, J., Schluter, N., and Tetreault, J. R. (eds.),Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Onli...
work page internal anchor Pith review doi:10.1162/tacl 2020
-
[18]
URL https: //doi.org/10.1145/3184558.3192301
doi: 10.1145/3184558.3192301. URL https: //doi.org/10.1145/3184558.3192301. Majumdar, S., Noroozi, V ., Narenthiran, S., Ficek, A., Balam, J., and Ginsburg, B. Genetic instruct: Scaling up synthetic generation of coding instructions for large language models.CoRR, abs/2407.21077, 2024. doi: 10.48550/ARXIV .2407.21077. URL https://doi. org/10.48550/arXiv.2...
-
[19]
PL-MTEB: Polish Massive Text Embedding Benchmark
University of Tartu Library, 2023. URL https: //aclanthology.org/2023.nodalida-1.20. O’Neill, J., Rozenshtein, P., Kiryo, R., Kubota, M., and Bol- legala, D. I wish I would have loved this one, but I didn’t - A multilingual dataset for counterfactual detection in product review. In Moens, M., Huang, X., Specia, L., and Yih, S. W. (eds.),Proceedings of the...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.emnlp-main.568 2023
-
[20]
AAAI Press, 2020. doi: 10.1609/AAAI.V34I05
-
[21]
Natural Language Understanding with the Quora Question Pairs Dataset
URL https://doi.org/10.1609/aaai. v34i05.6399. Saravia, E., Liu, H. T., Huang, Y ., Wu, J., and Chen, Y . CARER: contextualized affect representations for emo- tion recognition. In Riloff, E., Chiang, D., Hockenmaier, J., and Tsujii, J. (eds.),Proceedings of the 2018 Confer- ence on Empirical Methods in Natural Language Pro- cessing, Brussels, Belgium, Oc...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1609/aaai 2018
-
[22]
EmbeddingGemma: Powerful and Lightweight Text Representations
doi: 10.48550/ARXIV .2509.20354. URL https: //doi.org/10.48550/arXiv.2509.20354. Wachsmuth, H., Syed, S., and Stein, B. Retrieval of the best counterargument without prior topic knowl- edge. In Gurevych, I. and Miyao, Y . (eds.),Proceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, July ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2018
-
[23]
Fang, J., Jiang, H., Wang, K., Ma, Y ., Shi, J., Wang, X., He, X., and Chua, T
URL https://doi.org/10.18653/v1/ 2020.emnlp-main.609. Wang, L., Yang, N., Huang, X., Yang, L., Majumder, R., and Wei, F. Improving text embeddings with large lan- guage models. In Ku, L., Martins, A., and Srikumar, V . (eds.),Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok,...
-
[24]
URL https://aclanthology.org/2025. emnlp-main.1332/. Zhang, Q., Chen, M., Bukharin, A., He, P., Cheng, Y ., Chen, W., and Zhao, T. Adaptive budget allocation for parameter-efficient fine-tuning. InThe Eleventh Interna- tional Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023a. URL https://openreview.net...
-
[25]
findings-emnlp.614/
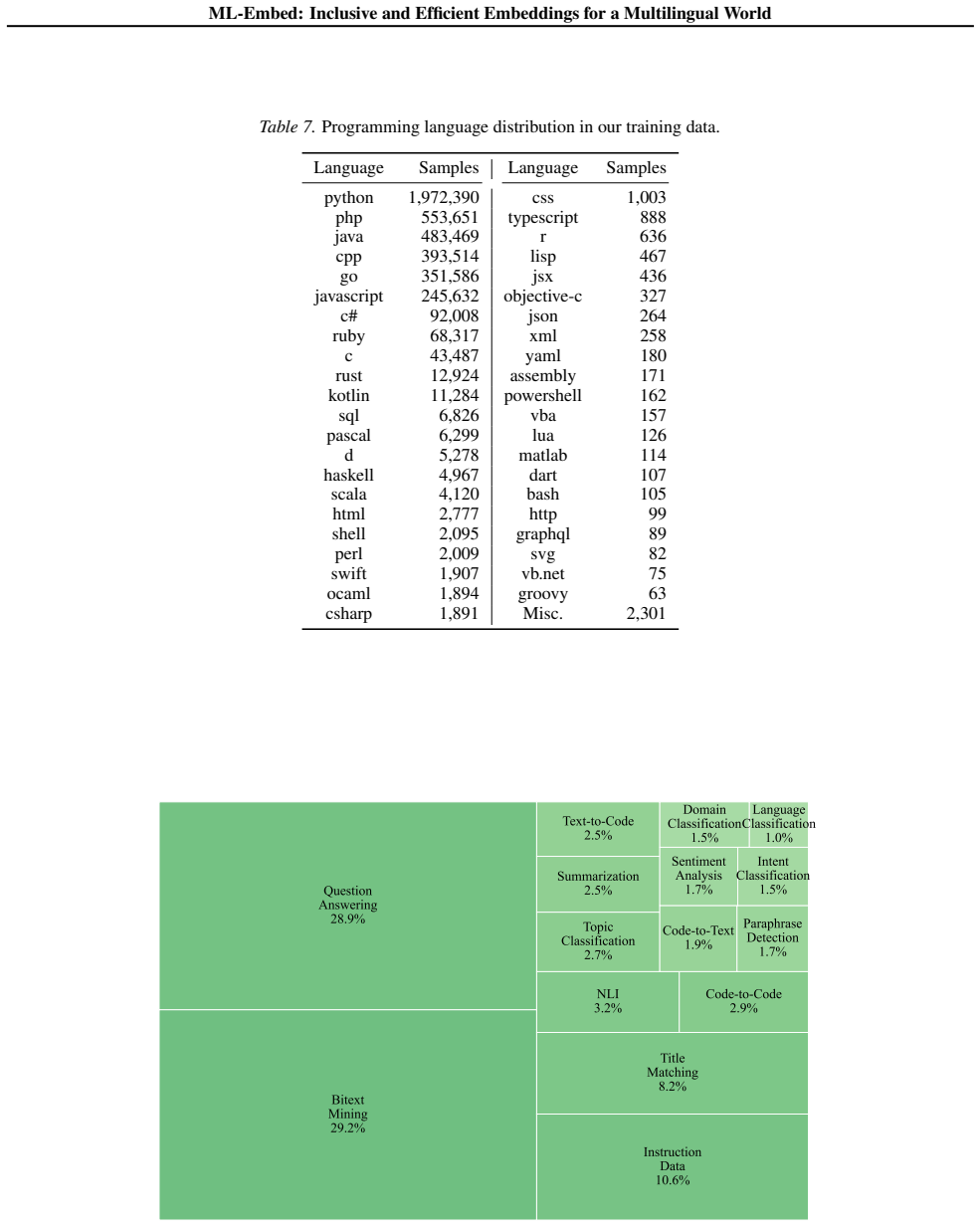
URL https://aclanthology.org/2025. findings-emnlp.614/. 22 ML-Embed: Inclusive and Efficient Embeddings for a Multilingual World A. Details on Training Data Table 5.Natural language distribution in our training data (part1). ISO Code Language Samples ISO Code Language Samples ISO Code Language Samples eng English 15,683,866 slk Slovak 97,974 tat Tatar 22,...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.