MM-Matryoshka: Towards Budget-Elastic Visual Document Retrieval via a 2D Multimodal Matryoshka Training Framework
Pith reviewed 2026-06-28 06:56 UTC · model grok-4.3
The pith
A single trained retriever can select both embedding dimensions and encoder layers at inference for budget-elastic visual document retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
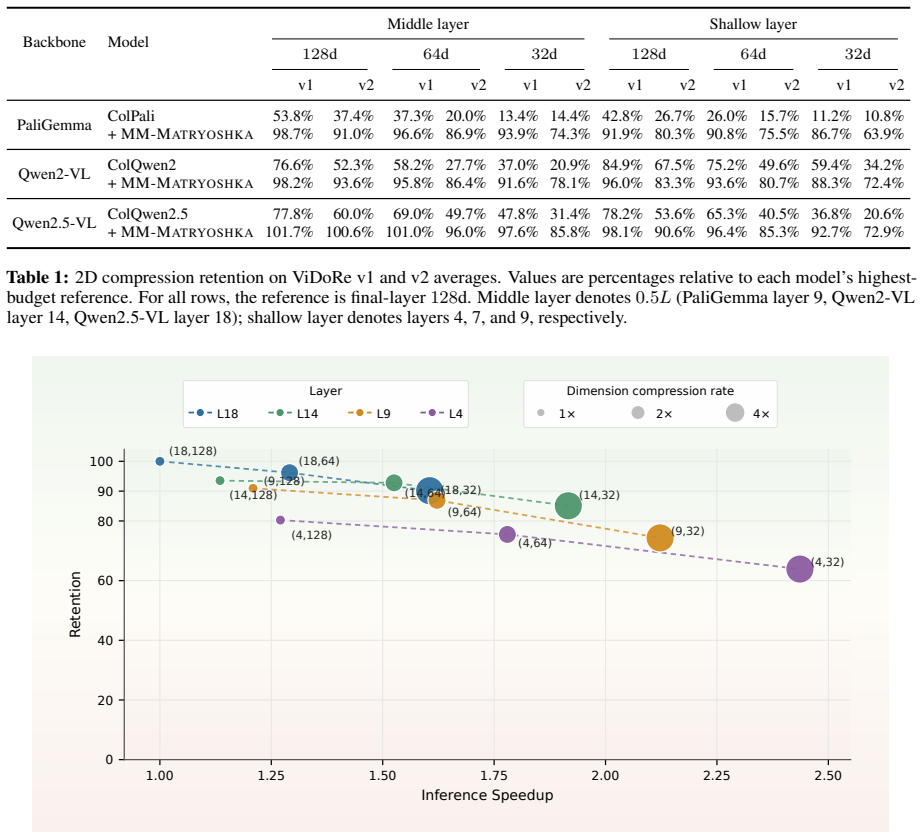
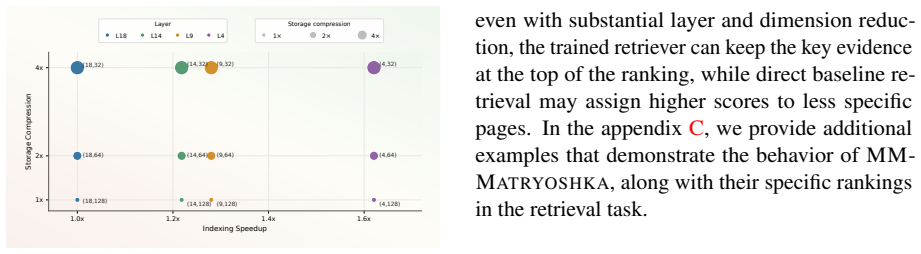
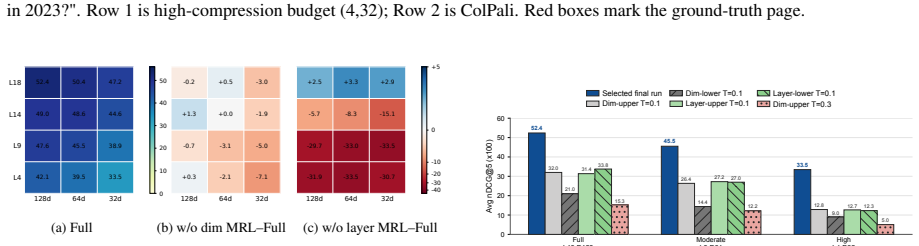
By applying 2D Matryoshka training to multimodal VLMs, the resulting representations support independent selection of dimensions and layers at inference time, delivering higher retrieval quality than direct truncation while allowing a single model to operate under varying storage and compute budgets.
What carries the argument
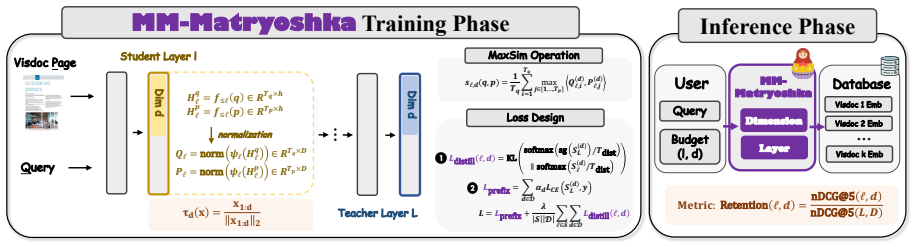
The 2D Matryoshka training procedure that nests representations along both embedding dimensions and encoder layers so selections can be made independently at inference.
If this is right
- One model can serve multiple deployment budgets without retraining.
- Storage and compute costs can be reduced by choosing fewer dimensions and shallower layers.
- Quality stays above direct truncation baselines across tested backbones.
- Budget choices become selectable per query or per deployment without additional training.
Where Pith is reading between the lines
- The same training pattern could be tested on other multi-vector retrieval tasks outside document pages.
- Dynamic per-query budget selection might become feasible if selection logic is added at inference.
- Similar two-axis nesting could be explored for efficiency in non-retrieval multimodal tasks.
Load-bearing premise
The training procedure produces representations whose quality holds when dimension and layer choices are made separately at inference rather than degrading like simple truncation.
What would settle it
Retrieval quality on standard VDR benchmarks drops to the level of direct truncation when a trained MM-Matryoshka model is tested with independent dimension and layer selections.
Figures







read the original abstract
Multi-vector visual document retrievers achieve strong fine-grained matching by representing each page with multiple vectors from deep Vision-Language Models (VLMs), but this design makes deployment expensive in both storage and computational overhead. Existing efficiency techniques usually optimize only part of this budget, leaving multimodal retrievers without a unified way to trade accuracy for both vector width and encoder depth. Therefore, we propose MM-Matryoshka, a 2D Matryoshka training framework for budget-elastic Visual Document Retrieval (VDR), enabling ColPali-style multi-vector retrieval elastic along both dimension and layer. At inference time, a single retriever can select a 2D selectable budget without training separate models for different budgets. Through comprehensive experiments across multiple representative backbones, we demonstrate that by retaining significantly higher quality than direct truncation baselines while substantially reducing storage and computational overhead, MM-Matryoshka can offer robust budget elasticity for efficient VDR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MM-Matryoshka, a 2D multimodal Matryoshka training framework for budget-elastic Visual Document Retrieval (VDR) based on ColPali-style multi-vector VLMs. It claims that a single trained retriever supports independent selection of vector dimension and encoder layer depth at inference time without requiring separate models for different budgets, and that experiments across multiple backbones show it retains significantly higher quality than direct truncation baselines while reducing storage and compute overhead.
Significance. If the empirical claims hold, the work would provide a practical unified mechanism for trading accuracy against both width and depth costs in multi-vector VDR, addressing a gap where prior efficiency methods optimize only one axis.
major comments (1)
- [Abstract] Abstract: The central claim that 'experiments demonstrate that by retaining significantly higher quality than direct truncation baselines' is asserted without any methods description, datasets, quantitative results, tables, figures, or error analysis in the manuscript. This prevents evaluation of whether the 2D Matryoshka procedure produces representations that remain effective under independent dimension and layer selection at inference.
Simulated Author's Rebuttal
We thank the referee for the feedback on the abstract. We address the concern point-by-point below, noting that the full manuscript contains the supporting details referenced in the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'experiments demonstrate that by retaining significantly higher quality than direct truncation baselines' is asserted without any methods description, datasets, quantitative results, tables, figures, or error analysis in the manuscript. This prevents evaluation of whether the 2D Matryoshka procedure produces representations that remain effective under independent dimension and layer selection at inference.
Authors: The abstract is a high-level summary; the full manuscript provides all requested elements. Section 3 details the 2D Matryoshka training framework (including independent dimension and layer selection at inference). Section 4 describes the datasets, backbones, and evaluation protocol. Sections 5 and 6 present quantitative results in tables and figures comparing against direct truncation baselines across budgets, with analysis of effectiveness under 2D selection. We can add explicit section references to the abstract in a revision if the referee finds this improves clarity. revision: partial
Circularity Check
No significant circularity
full rationale
The paper proposes a 2D Matryoshka training framework for budget-elastic visual document retrieval. The abstract and available text describe an empirical training procedure and its inference-time benefits without any equations, derivations, or load-bearing claims that reduce by construction to fitted parameters or self-citations. No self-definitional steps, fitted inputs renamed as predictions, or uniqueness theorems imported from prior author work are present. The central claim is a description of a proposed method whose validity rests on external experiments rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , volume=
Colpali: Efficient document retrieval with vision language models , author=. International Conference on Learning Representations , volume=
-
[6]
Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025) , pages=
jina-embeddings-v4: Universal embeddings for multimodal multilingual retrieval , author=. Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025) , pages=
2025
-
[8]
Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
Colbert: Efficient and effective passage search via contextualized late interaction over bert , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[9]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Colbertv2: Effective and efficient retrieval via lightweight late interaction , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[10]
Proceedings of the 31st ACM International Conference on Information & Knowledge Management , pages=
PLAID: an efficient engine for late interaction retrieval , author=. Proceedings of the 31st ACM International Conference on Information & Knowledge Management , pages=
-
[11]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
CITADEL: Conditional token interaction via dynamic lexical routing for efficient and effective multi-vector retrieval , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[12]
Advances in Neural Information Processing Systems , volume=
DESSERT: an efficient algorithm for vector set search with vector set queries , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Advances in Neural Information Processing Systems , volume=
Muvera: Multi-vector retrieval via fixed dimensional encoding , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Matryoshka representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
2d matryoshka training for information retrieval , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[19]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Matryoshka-adaptor: Unsupervised and supervised tuning for smaller embedding dimensions , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[20]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Smec: Rethinking matryoshka representation learning for retrieval embedding compression , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[21]
International Conference on Learning Representations , volume=
Matryoshka multimodal models , author=. International Conference on Learning Representations , volume=
-
[22]
arXiv preprint arXiv:2605.16608 , year=
To MRL or not to MRL: Text Embeddings are Robust to Truncation Without Matryoshka Embeddings, Except In Heavy Truncation Scenarios , author=. arXiv preprint arXiv:2605.16608 , year=
-
[23]
arXiv preprint arXiv:2605.15081 , year=
ML-Embed: Inclusive and Efficient Embeddings for a Multilingual World , author=. arXiv preprint arXiv:2605.15081 , year=
-
[25]
arXiv preprint arXiv:2507.14137 , year=
Franca: Nested matryoshka clustering for scalable visual representation learning , author=. arXiv preprint arXiv:2507.14137 , year=
-
[28]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
mme5: Improving multimodal multilingual embeddings via high-quality synthetic data , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[29]
arXiv preprint arXiv:2506.23115 , year=
Moca: Modality-aware continual pre-training makes better bidirectional multimodal embeddings , author=. arXiv preprint arXiv:2506.23115 , year=
-
[30]
arXiv preprint arXiv:2403.20327 , year=
Gecko: Versatile text embeddings distilled from large language models , author=. arXiv preprint arXiv:2403.20327 , year=
-
[31]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 embedding: Advancing text embedding and reranking through foundation models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[32]
arXiv preprint arXiv:2605.04018 , year=
Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems , author=. arXiv preprint arXiv:2605.04018 , year=
-
[38]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Towards storage-efficient visual document retrieval: An empirical study on reducing patch-level embeddings , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[42]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Reproducibility, Replicability, and Insights into Visual Document Retrieval with Late Interaction , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[43]
arXiv preprint arXiv:2510.01149 , year=
ModernVBERT: Towards Smaller Visual Document Retrievers , author=. arXiv preprint arXiv:2510.01149 , year=
-
[44]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Unveil: Unified Visual-Textual Integration and Distillation for Multi-modal Document Retrieval , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[45]
arXiv preprint arXiv:2603.13349 , year=
MURE: Hierarchical Multi-Resolution Encoding via Vision-Language Models for Visual Document Retrieval , author=. arXiv preprint arXiv:2603.13349 , year=
-
[47]
arXiv preprint arXiv:2603.12824 , year=
NanoVDR: Distilling a 2B Vision-Language Retriever into a 70M Text-Only Encoder for Visual Document Retrieval , author=. arXiv preprint arXiv:2603.12824 , year=
-
[49]
2025 IEEE 35th International Workshop on Machine Learning for Signal Processing (MLSP) , pages=
ColFlor: Towards BERT-Size Vision-Language Document Retrieval Models , author=. 2025 IEEE 35th International Workshop on Machine Learning for Signal Processing (MLSP) , pages=. 2025 , organization=
2025
-
[51]
Advances in Neural Information Processing Systems , volume=
Rethinking the role of token retrieval in multi-vector retrieval , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Incorporating Token Importance in Multi-Vector Retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[53]
Proceedings of the 2024 ACM SIGPLAN International Symposium on Memory Management , pages=
Espn: Memory-efficient multi-vector information retrieval , author=. Proceedings of the 2024 ACM SIGPLAN International Symposium on Memory Management , pages=
2024
-
[54]
arXiv preprint arXiv:2603.16455 , year=
Evo-retriever: Llm-guided curriculum evolution with viewpoint-pathway collaboration for multimodal document retrieval , author=. arXiv preprint arXiv:2603.16455 , year=
-
[56]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Train once, deploy anywhere: Matryoshka representation learning for multimodal recommendation , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[59]
S Archish, Ankit Garg, Kirankumar Shiragur, and Neeraj Kayal. 2026. Incorporating token importance in multi-vector retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32860--32866
2026
-
[60]
Duong Bach. 2025. Hierarchical patch compression for colpali: Efficient multi-vector document retrieval with dynamic pruning and quantization. arXiv preprint arXiv:2506.21601
arXiv 2025
-
[61]
Lucas Beyer, Andreas Steiner, Andr \'e Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, and 1 others. 2024. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726
Pith/arXiv arXiv 2024
-
[62]
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. 2025. Learning multi-level features with matryoshka sparse autoencoders. arXiv preprint arXiv:2503.17547
arXiv 2025
-
[63]
Mu Cai, Jianwei Yang, Jianfeng Gao, and Yong Jae Lee. 2025. Matryoshka multimodal models. In International Conference on Learning Representations, volume 2025, pages 46254--46272
2025
-
[64]
Haonan Chen, Liang Wang, Nan Yang, Yutao Zhu, Ziliang Zhao, Furu Wei, and Zhicheng Dou. 2025. mme5: Improving multimodal multilingual embeddings via high-quality synthetic data. In Findings of the Association for Computational Linguistics: ACL 2025, pages 8254--8275
2025
-
[65]
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, C \'e line Hudelot, and Pierre Colombo. 2025. Colpali: Efficient document retrieval with vision language models. In International Conference on Learning Representations, volume 2025, pages 61424--61449
2025
-
[66]
Michael G \"u nther, Saba Sturua, Mohammad Kalim Akram, Isabelle Mohr, Andrei Ungureanu, Bo Wang, Sedigheh Eslami, Scott Martens, Maximilian Werk, Nan Wang, and 1 others. 2025. jina-embeddings-v4: Universal embeddings for multimodal multilingual retrieval. In Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025), pages 531--550
2025
-
[67]
Jiahao Huo, Yu Huang, Yibo Yan, Ye Pan, Kening Zheng, Wei-Chieh Huang, Yi Cao, Mingdong Ou, Philip S Yu, and Xuming Hu. 2026. Causalembed: Auto-regressive multi-vector generation in latent space for visual document embedding. arXiv preprint arXiv:2601.21262
Pith/arXiv arXiv 2026
-
[68]
Phung Gia Huy, Hai An Vu, Minh-Phuc Truong, Thang Duc Tran, Linh Ngo Van, Thanh Hong Nguyen, and Trung Le. 2026. Mipic: Matryoshka representation learning via self-distilled intra-relational and progressive information chaining. arXiv preprint arXiv:2604.24374
Pith/arXiv arXiv 2026
-
[69]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. 2024. Vlm2vec: Training vision-language models for massive multimodal embedding tasks. arXiv preprint arXiv:2410.05160
Pith/arXiv arXiv 2024
-
[70]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39--48
2020
-
[71]
Juyeon Kim, Geon Lee, Dongwon Choi, Taeuk Kim, and Kijung Shin. 2025. Hybrid-vector retrieval for visually rich documents: Combining single-vector efficiency and multi-vector accuracy. arXiv preprint arXiv:2510.22215
Pith/arXiv arXiv 2025
-
[72]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, and 1 others. 2022. Matryoshka representation learning. Advances in Neural Information Processing Systems, 35:30233--30249
2022
-
[73]
Riwei Lai, Li Chen, Weixin Chen, and Rui Chen. 2024. Matryoshka representation learning for recommendation. arXiv preprint arXiv:2406.07432
arXiv 2024
-
[74]
Jinhyuk Lee, Zhuyun Dai, Sai Meher Karthik Duddu, Tao Lei, Iftekhar Naim, Ming-Wei Chang, and Vincent Zhao. 2023. Rethinking the role of token retrieval in multi-vector retrieval. Advances in Neural Information Processing Systems, 36:15384--15405
2023
-
[75]
Minghan Li, Sheng-Chieh Lin, Barlas Oguz, Asish Ghoshal, Jimmy Lin, Yashar Mehdad, Wen-tau Yih, and Xilun Chen. 2023. Citadel: Conditional token interaction via dynamic lexical routing for efficient and effective multi-vector retrieval. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
2023
-
[76]
Xianming Li, Zongxi Li, Jing Li, Haoran Xie, and Qing Li. 2024. 2d matryoshka sentence embeddings. arXiv preprint arXiv:2402.14776
arXiv 2024
-
[77]
Yubo Ma, Jinsong Li, Yuhang Zang, Xiaobao Wu, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Haodong Duan, Jiaqi Wang, Yixin Cao, and 1 others. 2025. Towards storage-efficient visual document retrieval: An empirical study on reducing patch-level embeddings. In Findings of the Association for Computational Linguistics: ACL 2025, pages 19568--19580
2025
-
[78]
Quentin Mac \'e , Ant \'o nio Loison, and Manuel Faysse. 2025. Vidore benchmark v2: Raising the bar for visual retrieval. arXiv preprint arXiv:2505.17166
arXiv 2025
-
[79]
Gabriel de Souza P Moreira, Ronay Ak, Mengyao Xu, Oliver Holworthy, Benedikt Schifferer, Zhiding Yu, Yauhen Babakhin, Radek Osmulski, Jiarui Cai, Ryan Chesler, and 1 others. 2026. Nemotron colembed v2: Top-performing late interaction embedding models for visual document retrieval. arXiv preprint arXiv:2602.03992
arXiv 2026
-
[80]
Radek Osmulski, Gabriel de Souza P Moreira, Ronay Ak, Mengyao Xu, Benedikt Schifferer, and Even Oldridge. 2025. Miracl-vision: A large, multilingual, visual document retrieval benchmark. arXiv preprint arXiv:2505.11651
arXiv 2025
-
[81]
Hanxiang Qin, Alexander Martin, Rohan Jha, Chunsheng Zuo, Reno Kriz, and Benjamin Van Durme. 2026. Multi-vector index compression in any modality. arXiv preprint arXiv:2602.21202
arXiv 2026
-
[82]
Keshav Santhanam, Omar Khattab, Christopher Potts, and Matei Zaharia. 2022 a . Plaid: an efficient engine for late interaction retrieval. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, pages 1747--1756
2022
-
[83]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022 b . Colbertv2: Effective and efficient retrieval via lightweight late interaction. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3715--3734
2022
-
[84]
Susav Shrestha, Narasimha Reddy, and Zongwang Li. 2024. Espn: Memory-efficient multi-vector information retrieval. In Proceedings of the 2024 ACM SIGPLAN International Symposium on Memory Management, pages 95--107
2024
-
[85]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, and 1 others. 2024 a . Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191
Pith/arXiv arXiv 2024
-
[86]
Shuai Wang, Shengyao Zhuang, Bevan Koopman, and Guido Zuccon. 2025. 2d matryoshka training for information retrieval. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3125--3134
2025
-
[87]
Yaoxiang Wang, Simiao Zuo, Qingguo Hu, Yucheng Ding, Yeyun Gong, Jian Jiao, and Jinsong Su. 2026. m3bert: A modern, multi-lingual, matryoshka bidirectional encoder. arXiv preprint arXiv:2605.19568
Pith/arXiv arXiv 2026
-
[88]
Yueqi Wang, Zhenrui Yue, Huimin Zeng, Dong Wang, and Julian McAuley. 2024 b . Train once, deploy anywhere: Matryoshka representation learning for multimodal recommendation. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 13461--13472
2024
-
[89]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, and 1 others. 2025. Qwen-image technical report. arXiv preprint arXiv:2508.02324
Pith/arXiv arXiv 2025
-
[90]
Zilin Xiao, Qi Ma, Mengting Gu, Chun-cheng Jason Chen, Xintao Chen, Vicente Ordonez, and Vijai Mohan. 2025. Metaembed: Scaling multimodal retrieval at test-time with flexible late interaction. arXiv preprint arXiv:2509.18095
Pith/arXiv arXiv 2025
-
[91]
Mengyao Xu, Gabriel Moreira, Ronay Ak, Radek Osmulski, Yauhen Babakhin, Zhiding Yu, Benedikt Schifferer, and Even Oldridge. 2025. Llama nemoretriever colembed: Top-performing text-image retrieval model. arXiv preprint arXiv:2507.05513
arXiv 2025
-
[92]
Yibo Yan, Jiahao Huo, Guanbo Feng, Mingdong Ou, Yi Cao, Xin Zou, Shuliang Liu, Yuanhuiyi Lyu, Yu Huang, Jungang Li, and 1 others. 2026 a . Unlocking multimodal document intelligence: From current triumphs to future frontiers of visual document retrieval. arXiv preprint arXiv:2602.19961
arXiv 2026
-
[93]
Yibo Yan, Mingdong Ou, Yi Cao, Jiahao Huo, Xin Zou, Shuliang Liu, James Kwok, and Xuming Hu. 2026 b . Visual late chunking: An empirical study of contextual chunking for efficient visual document retrieval. arXiv preprint arXiv:2604.10167
Pith/arXiv arXiv 2026
-
[94]
Yibo Yan, Mingdong Ou, Yi Cao, Xin Zou, Jiahao Huo, Shuliang Liu, James Kwok, and Xuming Hu. 2026 c . Sculpting the vector space: Towards efficient multi-vector visual document retrieval via prune-then-merge framework. arXiv preprint arXiv:2602.19549
Pith/arXiv arXiv 2026
-
[95]
Yibo Yan, Mingdong Ou, Yi Cao, Xin Zou, Shuliang Liu, Jiahao Huo, Yu Huang, James Kwok, and Xuming Hu. 2026 d . Beyond the grid: Layout-informed multi-vector retrieval with parsed visual document representations. arXiv preprint arXiv:2603.01666
arXiv 2026
-
[96]
Yibo Yan, Guangwei Xu, Xin Zou, Shuliang Liu, James Kwok, and Xuming Hu. 2025. Docpruner: A storage-efficient framework for multi-vector visual document retrieval via adaptive patch-level embedding pruning. arXiv preprint arXiv:2509.23883
arXiv 2025
-
[97]
Jinsung Yoon, Rajarishi Sinha, Sercan O Arik, and Tomas Pfister. 2024. Matryoshka-adaptor: Unsupervised and supervised tuning for smaller embedding dimensions. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10318--10336
2024
-
[98]
Biao Zhang, Lixin Chen, Tong Liu, and Bo Zheng. 2025. Smec: Rethinking matryoshka representation learning for retrieval embedding compression. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 26220--26233
2025
-
[99]
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. 2024. Gme: improving universal multimodal retrieval by multimodal llms. arXiv preprint arXiv:2412.16855
Pith/arXiv arXiv 2024
-
[100]
Shengyao Zhuang, Shuai Wang, Fabio Zheng, Bevan Koopman, and Guido Zuccon. 2024. Starbucks-v2: Improved training for 2d matryoshka embeddings. arXiv preprint arXiv:2410.13230
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.