To MRL or not to MRL: Text Embeddings are Robust to Truncation Without Matryoshka Learning, Except In Heavy Truncation Scenarios
Pith reviewed 2026-06-30 19:01 UTC · model grok-4.3
The pith
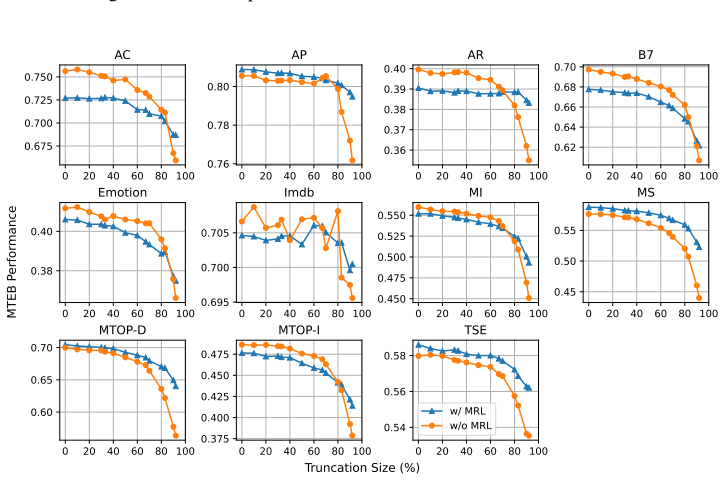
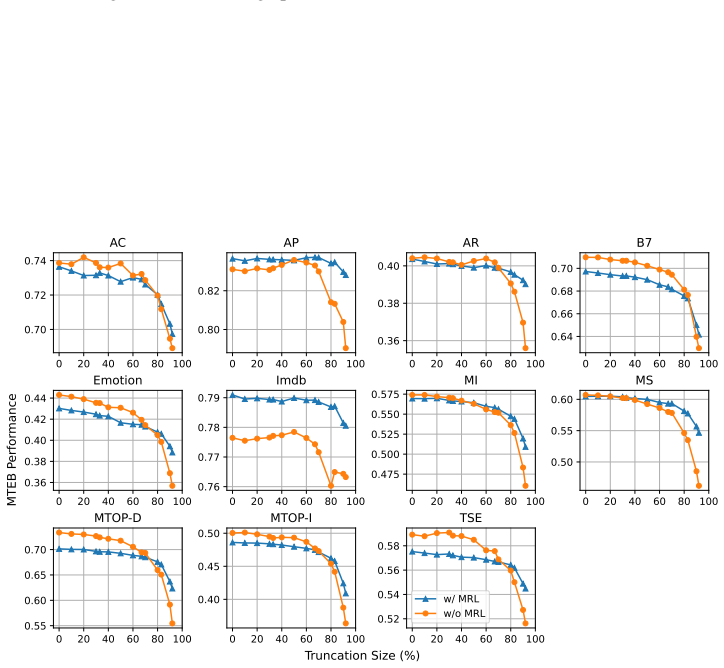
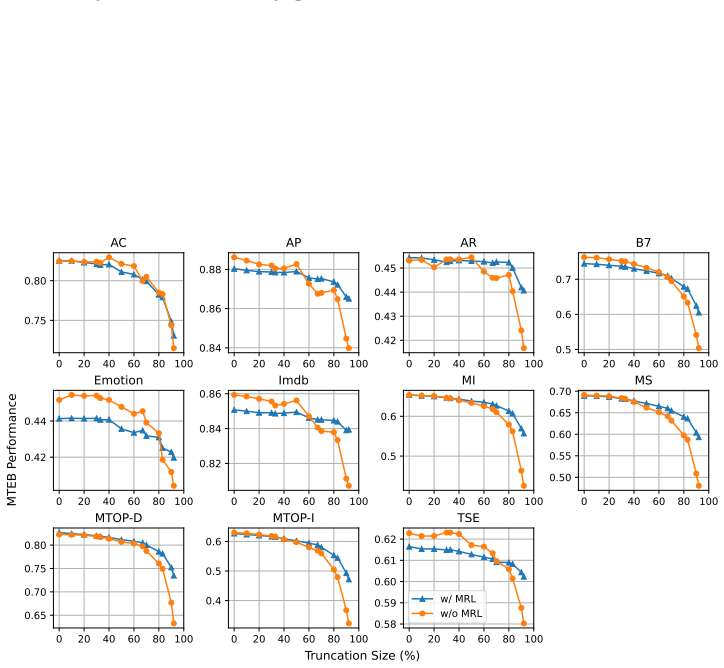
Text embeddings from standard models remain competitive after truncation unless size drops by 80 percent or more, often matching or beating Matryoshka-trained versions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Truncated embeddings of models trained without Matryoshka Representation Learning are competitive with, and often outperform, models trained with MRL unless the embeddings are reduced in size by at least 80 percent.
What carries the argument
Side-by-side application of MRL-style truncation to both MRL-trained and standard text encoders, measuring downstream task performance.
Load-bearing premise
The non-MRL and MRL models are trained under sufficiently comparable conditions that performance differences can be attributed to the training method rather than other factors.
What would settle it
A controlled experiment in which MRL models consistently outperform non-MRL models at truncation levels below 80 percent reduction across the same architectures and tasks.
Figures









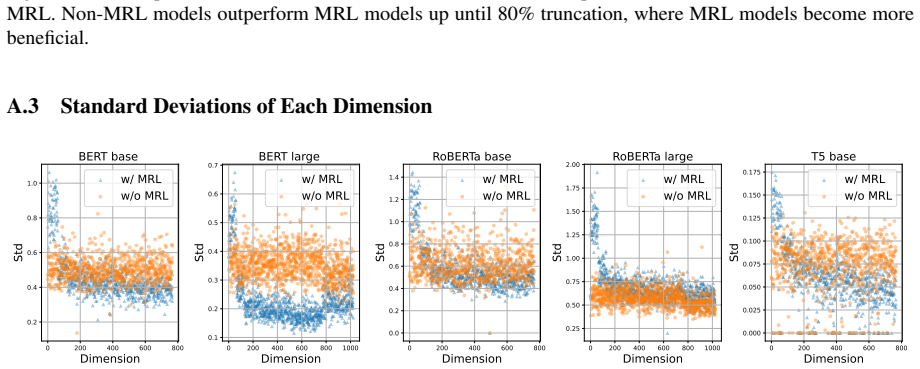


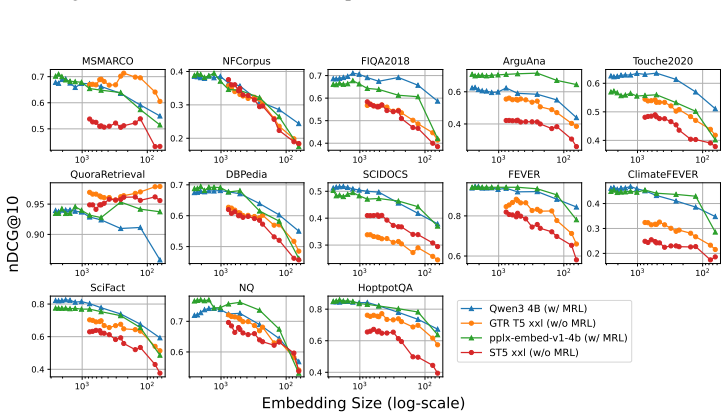


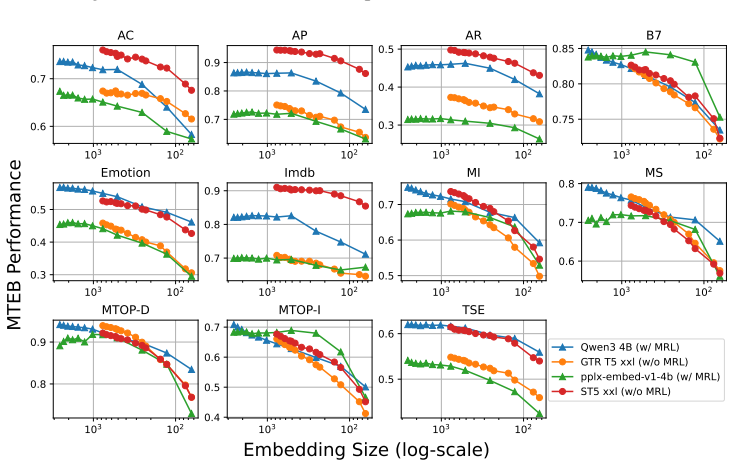



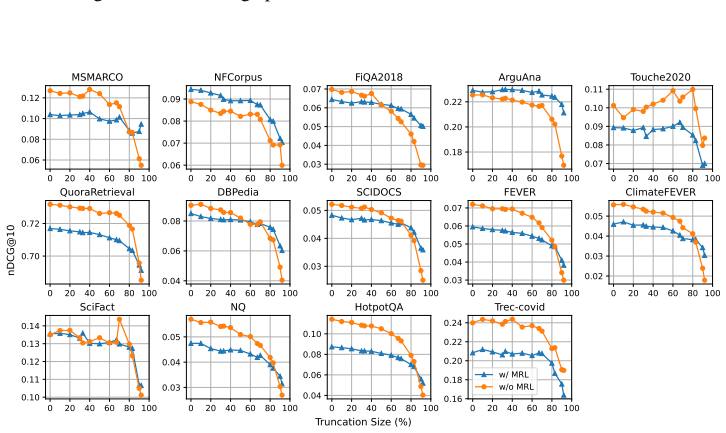






read the original abstract
Matryoshka Representation Learning (MRL) is a widely adopted approach for training text encoders so they provide useful text representations at various sizes, available by simply truncating the resulting vectors at sizes pre-determined at training time. Recent works have shown that randomly truncating text embeddings has minimal impact in downstream performance unless vectors are reduced in size by at least 70%, suggesting that embeddings are already robust to truncation without the use of MRL. However, no prior work has compared random truncation to MRL, so it is unclear how the two methods compare as effective embedding reduction methods. In this paper, we study this by applying the same truncation used by MRL to models trained with and without MRL. Our results across several models and downstream tasks show that, unless heavily truncating embeddings (i.e. reducing their size by at least 80%), truncated embeddings of non-MRL models are competitive with, and often outperform models trained with MRL. This suggests that truncation robustness may not necessarily come from MRL, and that the choice of spending the additional training cost of MRL depends on whether heavy truncation is desired. We make our code available for reproduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that text embeddings from non-MRL models remain competitive with (and often outperform) those from MRL-trained models under random truncation, except when truncation is heavy (at least 80% size reduction). This is based on experiments applying MRL-style truncation to several models across downstream tasks, leading to the conclusion that MRL's extra training cost is justified only for heavy-truncation use cases. Code is released for reproduction.
Significance. If the central empirical comparison holds under matched conditions, the result would indicate that truncation robustness is largely inherent to standard embeddings rather than requiring the MRL objective for moderate reductions, with potential implications for training efficiency. The release of reproduction code strengthens verifiability.
major comments (1)
- [Abstract] Abstract: the central claim that performance differences can be attributed to the presence/absence of MRL requires that non-MRL and MRL models differ only in the training objective. No details are provided on whether base architectures, pre-training corpora, fine-tuning data, batch sizes, learning rates, or training steps were matched; without this, the truncation-robustness comparison cannot isolate the effect of MRL.
minor comments (1)
- The abstract would be clearer if it listed the specific model families, downstream tasks, and exact truncation ratios (e.g., 50%, 70%, 80%) used in the comparison.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback. We address the major comment below and will incorporate revisions as noted.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that performance differences can be attributed to the presence/absence of MRL requires that non-MRL and MRL models differ only in the training objective. No details are provided on whether base architectures, pre-training corpora, fine-tuning data, batch sizes, learning rates, or training steps were matched; without this, the truncation-robustness comparison cannot isolate the effect of MRL.
Authors: We agree that a fully controlled experiment isolating only the MRL objective would require retraining matched models from scratch under identical conditions, which is outside the scope of this work. Our study instead evaluates publicly available models (both MRL-trained and standard non-MRL encoders) under identical truncation and evaluation protocols. While this prevents strict isolation of MRL's contribution from other training differences, the results still show that non-MRL models achieve competitive or superior performance under moderate truncation. We will revise the abstract, introduction, and add a limitations paragraph to clarify that we compare existing models rather than claiming a pure causal effect of the MRL objective alone, and to note the lack of matched training details as a caveat. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential reductions
full rationale
This paper performs an empirical study comparing truncation robustness of text embeddings from models trained with versus without Matryoshka Representation Learning (MRL). The abstract and full text describe training several models, applying truncation, and reporting downstream task performance; no equations, derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear. The central claim rests on experimental results rather than any chain that reduces to its own inputs by construction. The comparability of training conditions is an experimental design assumption (addressable via replication), not a circularity issue under the defined patterns. No steps qualify for the enumerated kinds of circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Downstream task performance is a valid proxy for embedding quality
Forward citations
Cited by 1 Pith paper
-
MM-Matryoshka: Towards Budget-Elastic Visual Document Retrieval via a 2D Multimodal Matryoshka Training Framework
MM-Matryoshka is a 2D Matryoshka training framework enabling budget-elastic ColPali-style multi-vector visual document retrieval along dimension and layer without separate models per budget.
Reference graph
Works this paper leans on
-
[1]
Efficient Natural Language Response Suggestion for Smart Reply
Scaling diffusion language models via adapta- tion from autoregressive models. InThe Thirteenth International Conference on Learning Representa- tions. Faegheh Hasibi, Fedor Nikolaev, Chenyan Xiong, Krisz- tian Balog, Svein Erik Bratsberg, Alexander Kotov, and Jamie Callan. 2017. Dbpedia-entity v2: A test collection for entity search. InProceedings of the...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Phillip Keung, Yichao Lu, György Szarvas, and Noah A
Extensions of lipschitz mappings into a hilbert space.Contemporary mathematics, page 1. Phillip Keung, Yichao Lu, György Szarvas, and Noah A. Smith. 2020. The multilingual Amazon reviews cor- pus. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4563–4568, Online. Association for Computational Linguis...
2020
-
[3]
Text and Code Embeddings by Contrastive Pre-Training
Learning word vectors for sentiment analysis. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA. Association for Computational Lin- guistics. Maggie, Phil Culliton, and Wei Chen. 2020. Tweet sentiment extraction. https://kaggle.com/ competitions/twee...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
jina-embeddings-v3: Multilingual em- beddings with task lora
Ms marco: A human generated machine read- ing comprehension dataset. Jianmo Ni, Gustavo Hernandez Abrego, Noah Con- stant, Ji Ma, Keith Hall, Daniel Cer, and Yinfei Yang. 2022a. Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models. InFindings of the Association for Computational Linguistics: ACL 2022, pages 1864–1874, Dublin, Irela...
-
[5]
Multilingual E5 Text Embeddings: A Technical Report
Retrieval of the best counterargument without prior topic knowledge. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 241–251, Melbourne, Australia. Association for Computational Linguistics. David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
A broad-coverage challenge corpus for sen- tence understanding through inference. InProceed- ings of the 2018 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122, New Orleans, Louisiana. Association for Computational Linguis- tics. Zhilin Yang, Pe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.