Reliability and Effectiveness of Autonomous AI Agents in Supply Chain Management
Pith reviewed 2026-06-30 19:02 UTC · model grok-4.3
The pith
Autonomous reasoning AI agents outperform human teams in supply chain simulations and can be made reliable through post-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
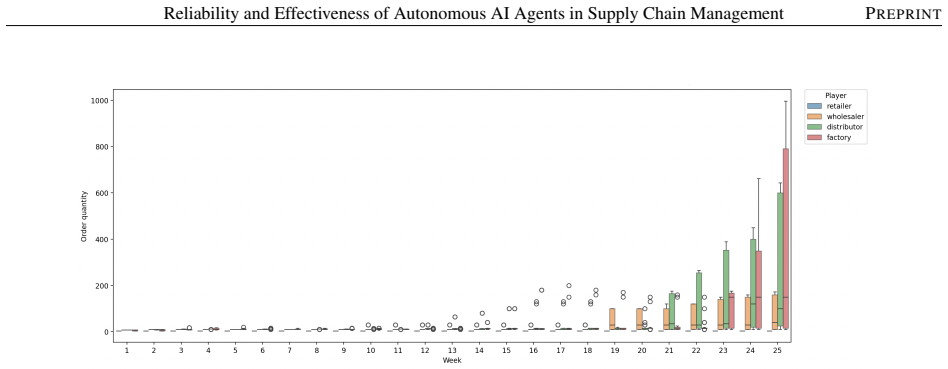
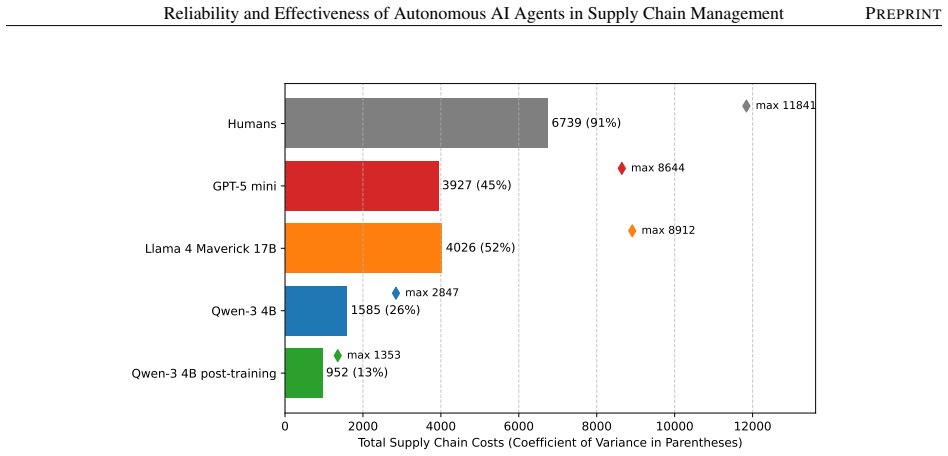
In the MIT Beer Game, an out-of-the-box reasoning model exceeds human-level performance in managing multi-echelon supply chains, while optimized reasoning models reduce costs by up to 67% relative to human teams. However, these agents exhibit agent bullwhip, defined as the amplification of run-to-run decision instability, including decision bullwhip from stochastic agent decisions. Repeated sampling does not sufficiently mitigate this instability. A GRPO-based post-training framework that uses system-level supply-chain rewards substantially reduces tail events, curtails agent bullwhip, and improves reliability.
What carries the argument
The Group Relative Policy Optimization (GRPO) post-training framework, which trains a shared base LLM using system-level supply-chain rewards to reduce decision instability.
If this is right
- Capable out-of-the-box models can exceed human performance without special tuning.
- Cost reductions of up to 67% are achievable with optimized reasoning models.
- Agent bullwhip can amplify decision variability both across facilities and over time within a facility.
- Repeated sampling fails to reduce instability meaningfully.
- GRPO post-training reduces tail events and improves reliability.
Where Pith is reading between the lines
- If the simulation holds, real supply chains could adopt these agents to lower costs while managing variability through post-training.
- The concept of agent bullwhip may apply to other multi-agent AI systems where decisions propagate through networks.
- Testing the GRPO approach on different demand patterns or with human-AI hybrid teams could reveal further benefits.
- Scaling this to larger supply networks might require adjustments to the reward structure used in post-training.
Load-bearing premise
The MIT Beer Game simulation accurately captures the dynamics and instability patterns of real multi-echelon supply chains.
What would settle it
Deploying the same AI agents in a real company's multi-echelon supply chain and measuring whether cost savings reach 67% and whether decision instability matches the simulation levels.
Figures







read the original abstract
This paper studies autonomous generative AI agents in multi-echelon supply chains using the MIT Beer Game. We identify four inference-time levers that shape performance: model selection, policies and guardrails, centralized data sharing, and prompt engineering. Model capability is the dominant factor: an out-of-the-box reasoning model exceeds human-level performance, and optimized reasoning models reduce costs by up to 67% relative to human teams. However, strong average performance masks substantial reliability risks. We introduce agent bullwhip: the amplification of run-to-run decision instability in autonomous multi-echelon systems. A central component is decision bullwhip, the portion of order variability generated by stochastic agent decisions rather than by changes in customer demand. We show that decision instability can amplify both across facilities at a fixed point in time and within the same facility over time, even when the demand path is held fixed. Repeated sampling, a natural test-time remedy, fails to meaningfully reduce this instability, suggesting that reliability requires changing the underlying decision policy rather than merely averaging over model outputs. To address this limitation, we propose a Group Relative Policy Optimization (GRPO)-based reinforcement-learning post-training framework that trains a shared base LLM using system-level supply-chain rewards. Post-training substantially reduces tail events, curtails agent bullwhip, and improves the reliability of autonomous supply-chain agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines autonomous generative AI agents in multi-echelon supply chains using the MIT Beer Game simulation. It identifies four inference-time levers (model selection, policies and guardrails, centralized data sharing, and prompt engineering), with model capability being the dominant factor. Key claims include that an out-of-the-box reasoning model exceeds human-level performance, optimized models reduce costs by up to 67% compared to human teams, and a GRPO-based reinforcement learning post-training framework reduces tail events, curtails agent bullwhip, and improves reliability. The paper introduces 'agent bullwhip' and 'decision bullwhip' to describe amplification of decision instability.
Significance. If the simulation results hold, the paper demonstrates the potential of advanced LLMs for supply chain decision-making and offers a post-training approach using system-level rewards to address reliability issues in autonomous agents. It provides empirical evidence of decision instability in multi-echelon systems and introduces new concepts for measuring it. This could inform the development of more reliable AI agents in logistics. The work is credited for its empirical analysis of instability amplification even with fixed demand and the proposal of GRPO for this application.
major comments (2)
- [Abstract] Abstract: The quantitative claims (out-of-the-box reasoning model exceeds human performance; optimized models reduce costs by up to 67%) are presented without any reference to experimental setup details, number of runs, variance across trials, or statistical significance, which is load-bearing for assessing whether the data supports the effectiveness assertions.
- [Abstract] Abstract: The headline claims about effectiveness and reliability in Supply Chain Management rest entirely on the stylized MIT Beer Game (fixed echelons, simplified demand signals, no external shocks or multi-product interactions). No evidence or discussion is provided that the observed cost reductions, tail-event reductions, or curtailment of agent bullwhip transfer when these assumptions are relaxed, undermining the generalizability of the central claims.
minor comments (2)
- [Abstract] The newly introduced terms 'agent bullwhip' and 'decision bullwhip' require explicit operational definitions and formulas for how they are computed from simulation traces, ideally in the section introducing the concepts.
- A dedicated limitations or discussion section should address the scope of the Beer Game testbed and the conditions under which the GRPO post-training gains might or might not extend.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The quantitative claims (out-of-the-box reasoning model exceeds human performance; optimized models reduce costs by up to 67%) are presented without any reference to experimental setup details, number of runs, variance across trials, or statistical significance, which is load-bearing for assessing whether the data supports the effectiveness assertions.
Authors: We agree the abstract would benefit from additional context. The full manuscript reports results from 100 independent runs per condition with standard deviations and statistical comparisons in Sections 4 and 5. We will revise the abstract to include a brief reference to the number of trials and variability measures. revision: yes
-
Referee: [Abstract] Abstract: The headline claims about effectiveness and reliability in Supply Chain Management rest entirely on the stylized MIT Beer Game (fixed echelons, simplified demand signals, no external shocks or multi-product interactions). No evidence or discussion is provided that the observed cost reductions, tail-event reductions, or curtailment of agent bullwhip transfer when these assumptions are relaxed, undermining the generalizability of the central claims.
Authors: The work examines agent behavior in the controlled MIT Beer Game environment to isolate decision instability. We do not claim or demonstrate transfer to settings with external shocks or multi-product interactions. We will add an explicit limitations paragraph clarifying the simulation assumptions and bounding the claims to this stylized setting. revision: partial
Circularity Check
No significant circularity; empirical simulation results are self-contained
full rationale
The paper reports performance metrics, instability observations, and post-training improvements from MIT Beer Game simulations. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described claims. Concepts such as agent bullwhip and decision bullwhip are defined from observed run-to-run variability rather than presupposed by the inputs. The central claims rest on simulation outcomes that can be externally reproduced or falsified, satisfying the criteria for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The MIT Beer Game simulation is a valid proxy for real multi-echelon supply chains.
invented entities (2)
-
agent bullwhip
no independent evidence
-
decision bullwhip
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Economy of Minds: Emerging Multi-Agent Intelligence with Economic Interactions
An economy of agents using auctions and wealth accumulation produces emergent multi-step reasoning that outperforms monolithic baselines on five agentic tasks.
Reference graph
Works this paper leans on
-
[1]
Constrained policy optimization
Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 22--31, 2017
2017
-
[2]
A robust optimization approach to inventory theory
Dimitris Bertsimas and Aur \'e lie Thiele. A robust optimization approach to inventory theory. Operations Research, 54 0 (1): 0 150--168, 2006. doi:10.1287/opre.1050.0238
-
[3]
Socratic iterative reasoning: Enhancing llm decision-making in the beer game supply chain, 2025
Leonard Boussioux, Andrew Chen, Ming Fan, and Apurva Jain. Socratic iterative reasoning: Enhancing llm decision-making in the beer game supply chain, 2025
2025
-
[4]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher R \'e , and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Quantifying the bullwhip effect in a simple supply chain: The impact of forecasting, lead times, and information
Frank Chen, Zvi Drezner, Jennifer K Ryan, and David Simchi-Levi. Quantifying the bullwhip effect in a simple supply chain: The impact of forecasting, lead times, and information. Management science, 46 0 (3): 0 436--443, 2000 a
2000
-
[6]
Ryan, and David Simchi-Levi
Frank Chen, Jennifer K. Ryan, and David Simchi-Levi. The impact of exponential smoothing forecasts on the bullwhip effect. Naval Research Logistics, 47 0 (4): 0 269--286, 2000 b
2000
-
[7]
Risk-sensitive and robust decision-making: A CVaR optimization approach
Yinlam Chow, Aviv Tamar, Shie Mannor, and Marco Pavone. Risk-sensitive and robust decision-making: A CVaR optimization approach. In Advances in Neural Information Processing Systems, volume 28, 2015
2015
-
[8]
Forrester
Jay W. Forrester. Industrial Dynamics. MIT Press, Cambridge, MA, 1961
1961
-
[9]
Fox, Mihai Barbuceanu, and Rune Teigen
Mark S. Fox, Mihai Barbuceanu, and Rune Teigen. Agent-oriented supply-chain management. International Journal of Flexible Manufacturing Systems, 12 0 (2): 0 165--188, 2000. doi:10.1023/A:1008195614074
-
[10]
The distribution free newsboy problem: Review and extensions
Guillermo Gallego and Ilkyeong Moon. The distribution free newsboy problem: Review and extensions. Journal of the Operational Research Society, 44 0 (8): 0 825--834, 1993. doi:10.1057/jors.1993.141
-
[11]
A comprehensive survey on safe reinforcement learning
Javier Garc \'i a and Fernando Fern \'a ndez. A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research, 16 0 (42): 0 1437--1480, 2015
2015
-
[12]
doi: 10.1038/s41586-025-09422-z
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645: 0 633--638, 2025. doi:10.1038/s41586-025-09422-z
-
[13]
Agentic llms in the supply chain: towards autonomous multi-agent consensus-seeking
Valeria Jannelli, Stefan Schoepf, Matthias Bickel, Torbj rn Netland, and Alexandra Brintrup. Agentic llms in the supply chain: towards autonomous multi-agent consensus-seeking. International Journal of Production Research, pages 1--31, 2026
2026
-
[14]
Nirupam Julka, Rajagopalan Srinivasan, and Iftekhar A. Karimi. Agent-based supply chain management--1: Framework. Computers & Chemical Engineering, 26 0 (12): 0 1755--1769, 2002. doi:10.1016/S0098-1354(02)00150-3
-
[15]
Byeongmok Kim, Jong Gwang Kim, and Seokcheon Lee. A multi-agent reinforcement learning model for inventory transshipments under supply chain disruption. IISE Transactions, 56 0 (7): 0 715--728, 2024. doi:10.1080/24725854.2023.2217248
-
[16]
Leveraging graph neural networks and multi-agent reinforcement learning for inventory control in supply chains
Niki Kotecha and Antonio del Rio Chanona. Leveraging graph neural networks and multi-agent reinforcement learning for inventory control in supply chains. Computers & Chemical Engineering, 199: 0 109111, 2025
2025
-
[17]
Hau L. Lee, V. Padmanabhan, and Seungjin Whang. The bullwhip effect in supply chains. Sloan Management Review, 38 0 (3): 0 93--102, 1997 a
1997
-
[18]
Hau L. Lee, V. Padmanabhan, and Seungjin Whang. Information distortion in a supply chain: The bullwhip effect. Management Science, 43 0 (4): 0 546--558, 1997 b . doi:10.1287/mnsc.43.4.546
-
[19]
Calmon, and Flavio P
Carol Long, David Simchi-Levi, Andre P. Calmon, and Flavio P. Calmon. The genai beer game. [Online]. Available: https://infotheorylab.github.io/beer-game/, 2025 a . Accessed: December 15, 2025
2025
-
[20]
When supply chains become autonomous
Carol Long, David Simchi-Levi, Andre P Calmon, and Flavio P Calmon. When supply chains become autonomous. Harvard Business Review. Online article, 2025 b
2025
-
[21]
How generative ai improves supply chain management
Ishai Menache, Jeevan Pathuri, David Simchi-Levi, and Tom Linton. How generative ai improves supply chain management. Harvard Business Review, 104 0 (1-2): 0 86--95, 2025
2025
-
[22]
Mark E. Nissen. Agent-based supply chain integration. Information Technology and Management, 2 0 (3): 0 289--312, 2001
2001
-
[23]
Invagent: A large language model based multi-agent system for inventory management in supply chains
Yinzhu Quan and Zefang Liu. Invagent: A large language model based multi-agent system for inventory management in supply chains. arXiv preprint arXiv:2407.11384, 2024
-
[24]
Optimization of conditional value-at-risk,
R. Tyrrell Rockafellar and Stanislav Uryasev. Optimization of conditional value-at-risk. Journal of Risk, 2 0 (3): 0 21--41, 2000. doi:10.21314/JOR.2000.038
-
[25]
Herbert E. Scarf. A min-max solution of an inventory problem. In Kenneth J. Arrow, Samuel Karlin, and Herbert E. Scarf, editors, Studies in the Mathematical Theory of Inventory and Production, pages 201--209. Stanford University Press, Stanford, CA, 1958
1958
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Silver, David F
Edward A. Silver, David F. Pyke, and Rein Peterson. Inventory Management and Production Planning and Scheduling. John Wiley & Sons, New York, 3 edition, 1998
1998
-
[29]
Regret distribution in stochastic bandits: Optimal trade-off between expectation and tail risk
David Simchi-Levi, Zeyu Zheng, and Feng Zhu. Regret distribution in stochastic bandits: Optimal trade-off between expectation and tail risk. arXiv preprint arXiv:2304.04341, 2023
-
[30]
Large language models for supply chain decisions
David Simchi-Levi, Konstantina Mellou, Ishai Menache, and Jeevan Pathuri. Large language models for supply chain decisions. arXiv preprint arXiv:2507.21502, 2025 a
-
[31]
A simple and optimal policy design with safety against heavy-tailed risk for stochastic bandits
David Simchi-Levi, Zeyu Zheng, and Feng Zhu. A simple and optimal policy design with safety against heavy-tailed risk for stochastic bandits. Management Science, 71 0 (7): 0 6298--6318, 2025 b
2025
-
[32]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
John D. Sterman. Modeling managerial behavior: Misperceptions of feedback in a dynamic decision making experiment. Management Science, 35 0 (3): 0 321--339, 1989. doi:10.1287/mnsc.35.3.321
-
[34]
Jayashankar M. Swaminathan, Stephen F. Smith, and Norman M. Sadeh. Modeling supply chain dynamics: A multiagent approach. Decision Sciences, 29 0 (3): 0 607--632, 1998. doi:10.1111/j.1540-5915.1998.tb01356.x
-
[35]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models. arXiv preprint arXiv:2408.00724, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Multi-agent systems and foundation models enable autonomous supply chains: Opportunities and challenges
Liming Xu, Sara Almahri, Stephen Mak, and Alexandra Brintrup. Multi-agent systems and foundation models enable autonomous supply chains: Opportunities and challenges. IFAC-PapersOnLine, 58 0 (19): 0 795--800, 2024 a
2024
-
[38]
On implementing autonomous supply chains: A multi-agent system approach
Liming Xu, Stephen Mak, Maria Minaricova, and Alexandra Brintrup. On implementing autonomous supply chains: A multi-agent system approach. Computers in Industry, 161: 0 104120, 2024 b
2024
-
[39]
Llms in supply chain management: Opportunities and a case study
Ge Zheng, Sara Almahri, Liming Xu, Maria Minaricova, and Alexandra Brintrup. Llms in supply chain management: Opportunities and a case study. IFAC-PapersOnLine, 59 0 (10): 0 2951--2956, 2025
2025
-
[40]
Adaptive variance inflation in thompson sampling: Efficiency, safety, robustness, and beyond
Feng Zhu and David Simchi-Levi. Adaptive variance inflation in thompson sampling: Efficiency, safety, robustness, and beyond. Advances in Neural Information Processing Systems, 38: 0 50466--50484, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.