Economy of Minds: Emerging Multi-Agent Intelligence with Economic Interactions
Pith reviewed 2026-06-28 14:24 UTC · model grok-4.3
The pith
A population of agents competing via auctions for actions and accumulating wealth develops emergent multi-step reasoning that beats stronger single models on five tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
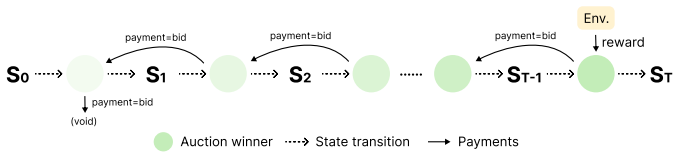
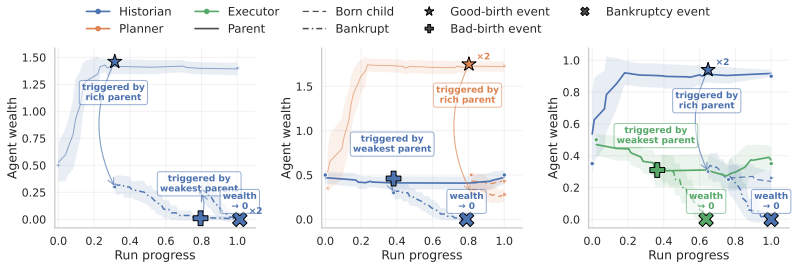
Initialized with weak agents, the economy produces emergent multi-step reasoning strategies and outperforms stronger monolithic baselines across five agentic tasks, including mathematical reasoning, financial research, scientific research, accelerator design, and distributed-system optimization. Economic signals induce decentralized credit assignment, driving planning without global orchestration or explicit communication protocols. The population evolves through economic selection where effective agents accumulate wealth and are mutated while ineffective ones go bankrupt and are replaced.
What carries the argument
Auction-based rights to act combined with wealth accumulation and replacement of bankrupt agents, which together create decentralized credit assignment from local incentives.
If this is right
- Local auction and payment signals produce decentralized credit assignment without any global controller.
- Long-term planning emerges in the population even though no agent communicates plans explicitly.
- Performance gains appear across mathematical, financial, scientific, design, and optimization tasks.
- Economic selection replaces weak agents while preserving and mutating effective ones.
- Theoretical links connect local incentives directly to measured global task performance.
Where Pith is reading between the lines
- The same incentive structure might be tested in physical multi-robot settings where communication is costly.
- Varying the auction rules or wealth thresholds could reveal which parameters most affect emergence speed.
- If the economy is run for many more generations, new agent specializations might appear beyond the five tasks studied.
- The approach suggests exploring whether similar selection pressures could improve single-agent systems without adding new agents.
Load-bearing premise
The combination of auction-based action rights and wealth-based replacement will reliably drive credit assignment and long-term planning without global orchestration or explicit communication.
What would settle it
Running the described economy on the five listed tasks and finding no performance gain over the stronger monolithic baselines or no appearance of multi-step reasoning strategies would falsify the central claim.
Figures




read the original abstract
How can a population of agents self-orchestrate and self-adapt into stronger collective intelligence without centralized control? Inspired by Friedrich Hayek's economic theory of decentralized coordination in markets, we study this question through an agent economy in which agents compete via auctions for the right to act, exchange payments, and accumulate wealth from environmental rewards. These simple economic signals induce decentralized credit assignment, driving planning without global orchestration or explicit communication protocols. The population evolves through economic selection: effective agents accumulate wealth and are mutated via exploitation, while ineffective ones go bankrupt and are replaced via exploration. We show that, initialized with weak agents, the economy produces emergent multi-step reasoning strategies and outperforms stronger monolithic baselines across five agentic tasks, including mathematical reasoning, financial research, scientific research, accelerator design, and distributed-system optimization. We further provide theoretical insights into how economic dynamics shape agent behaviors, linking local incentives to long-term global performance. Our results suggest a new path to multi-agent intelligence: rather than engineering coordination, we can design decentralized incentive structures under which it automatically emerges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an 'Economy of Minds' framework in which a population of agents competes via auctions for action rights, exchanges payments, and accumulates wealth from environmental rewards. Inspired by Hayek, the authors claim that these economic signals induce decentralized credit assignment and emergent multi-step reasoning without global orchestration or explicit communication. Initialized with weak agents, the economy is said to evolve via wealth-based selection (mutation of successful agents, replacement of bankrupt ones) and to outperform stronger monolithic baselines on five agentic tasks: mathematical reasoning, financial research, scientific research, accelerator design, and distributed-system optimization. Theoretical insights link local incentives to global performance.
Significance. If the empirical results and decentralization claims hold, the work would offer a novel incentive-based route to multi-agent intelligence that avoids explicit coordination engineering. This could influence scalable agent systems in complex domains, provided the mechanisms demonstrably operate without hidden central components and the performance gains are robustly documented.
major comments (2)
- [Abstract] Abstract: the claim of outperformance 'across five agentic tasks' is asserted without any experimental details, baseline definitions, statistical tests, ablation studies, or quantitative results. This prevents evaluation of whether the data support the central claim that economic interactions produce emergent strategies superior to monolithic baselines.
- [Abstract] Abstract (paragraph on economic signals): the assertion that 'auction-based action rights and wealth-based replacement' produce decentralized credit assignment 'without global orchestration' is load-bearing for the no-central-control claim, yet the manuscript supplies no implementation description showing how simultaneous bids are resolved or bankruptcy/replacement is triggered without a shared ledger, central clearinghouse, or population-level ranking step. If either mechanism requires such coordination, the observed improvements may stem from implicit global structure rather than pure local economic signals.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below. The abstract is intentionally concise, but we agree it can be strengthened with additional detail from the body of the paper without altering its length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of outperformance 'across five agentic tasks' is asserted without any experimental details, baseline definitions, statistical tests, ablation studies, or quantitative results. This prevents evaluation of whether the data support the central claim that economic interactions produce emergent strategies superior to monolithic baselines.
Authors: The abstract summarizes results that are fully detailed in Sections 4 and 5 of the manuscript, including task-specific baselines (e.g., single-agent GPT-4, chain-of-thought, and multi-agent variants without economic mechanisms), performance tables with means and standard deviations over multiple runs, and ablation studies on auction and wealth components. Statistical significance is reported via paired t-tests. To improve evaluability from the abstract alone, we will revise it to include one or two key quantitative results (e.g., average improvement margins) while preserving brevity. revision: partial
-
Referee: [Abstract] Abstract (paragraph on economic signals): the assertion that 'auction-based action rights and wealth-based replacement' produce decentralized credit assignment 'without global orchestration' is load-bearing for the no-central-control claim, yet the manuscript supplies no implementation description showing how simultaneous bids are resolved or bankruptcy/replacement is triggered without a shared ledger, central clearinghouse, or population-level ranking step. If either mechanism requires such coordination, the observed improvements may stem from implicit global structure rather than pure local economic signals.
Authors: The Methods section (Section 3) specifies that bids are submitted locally by each agent to a market that clears via a standard second-price auction rule applied only to the current action slot; no agent receives global state or rankings. Wealth is updated from per-task environmental rewards paid directly to the acting agent. Bankruptcy simply removes the agent and samples a new random initialization; there is no population-level fitness ranking or central controller that dictates which agents plan or reason. The simulation infrastructure necessarily resolves bids, but this is limited to market clearing and does not orchestrate multi-step reasoning or credit assignment. We will add a short clarifying paragraph in the revised Methods to emphasize the locality of all decision-making. revision: partial
Circularity Check
No significant circularity; claims rest on empirical outcomes
full rationale
The paper presents an empirical setup in which weak agents interact via auctions and wealth accumulation, then reports that emergent strategies appear and outperform monolithic baselines on five tasks. No equations, fitted parameters, or self-referential definitions are supplied that would make any claimed prediction equivalent to its inputs by construction. Theoretical insights are asserted but not shown to reduce to self-citation chains or ansatzes imported from prior author work. The argument is therefore self-contained against external benchmarks and receives the default non-circular finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Economic signals via auctions and payments induce decentralized credit assignment without global orchestration
Forward citations
Cited by 1 Pith paper
-
AgentDSE: Reasoning-Augmented Architectural Design Space Exploration
AgentDSE uses an LLM agent in a simulator-in-the-loop setup to achieve competitive or superior architectural designs with up to 100x fewer evaluations than traditional black-box optimization methods.
Reference graph
Works this paper leans on
-
[1]
Eric B. Baum. Toward a model of mind as a laissez-faire economy of idiots. InProceedings of the 13th International Conference on Machine Learning, pages 20–27, 1996. 2, 17
1996
-
[2]
Toward a model of intelligence as an economy of agents.Machine Learning, 35 (2):155–185, 1999
Eric B Baum. Toward a model of intelligence as an economy of agents.Machine Learning, 35 (2):155–185, 1999. 2, 3
1999
-
[3]
Evolution of cooperative problem solving in an artificial economy.Neural Computation, 12(12):2743–2775, 2000
Eric B Baum and Igor Durdanovic. Evolution of cooperative problem solving in an artificial economy.Neural Computation, 12(12):2743–2775, 2000. 3, 17
2000
-
[4]
Joseph Bejjani, Chase Van Amburg, Chengrui Wang, Chloe Huangyuan Su, Sarah M Pratt, Yasin Mazloumi, Naeem Khoshnevis, Sham M Kakade, Kianté Brantley, and Aaron Walsman. The emergence of complex behavior in large-scale ecological environments.arXiv preprint arXiv:2510.18221, 2025. 9
-
[5]
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. Finance agent benchmark: Benchmarking llms on real-world financial research tasks.arXiv preprint arXiv:2508.00828, 2025. 5, 25
-
[6]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi- agent llm systems fail?arXiv preprint arXiv:2503.13657, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Multi-agent evolve: Llm self-improve through co-evolution.arXiv preprint arXiv:2510.23595, 2025
Yixing Chen, Yiding Wang, Siqi Zhu, Haofei Yu, Tao Feng, Muhan Zhang, Mostofa Patwary, and Jiaxuan You. Multi-agent evolve: Llm self-improve through co-evolution.arXiv preprint arXiv:2510.23595, 2025. 2, 9
-
[8]
Barbarians at the gate: How ai is upending systems research.arXiv preprint arXiv:2510.06189, 2025
Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alex Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, et al. Barbarians at the gate: How ai is upending systems research.arXiv preprint arXiv:2510.06189, 2025. 5, 26
- [9]
-
[10]
Market-based multirobot coordination: A survey and analysis.Proceedings of the IEEE, 94(7):1257–1270, 2006
M Bernardine Dias, Robert Zlot, Nidhi Kalra, and Anthony Stentz. Market-based multirobot coordination: A survey and analysis.Proceedings of the IEEE, 94(7):1257–1270, 2006. 17
2006
-
[11]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024. 5, 17, 24
2024
-
[12]
Mechanism design for large language models
Paul Duetting, Vahab Mirrokni, Renato Paes Leme, Haifeng Xu, and Song Zuo. Mechanism design for large language models. InProceedings of the ACM Web Conference 2024, pages 144–155, 2024. 17
2024
-
[13]
Gemmini: Enabling systematic deep-learning architecture evaluation via full-stack integration
Hasan Genc, Seah Kim, Alon Amid, Ameer Haj-Ali, Vighnesh Iyer, Pranav Prakash, Jerry Zhao, Daniel Grubb, Harrison Liew, Howard Mao, et al. Gemmini: Enabling systematic deep-learning architecture evaluation via full-stack integration. In2021 58th ACM/IEEE Design Automation Conference (DAC), pages 769–774. IEEE, 2021. 5, 25
2021
-
[14]
Friedrich A. Hayek. The use of knowledge in society.The American Economic Review, 35(4): 519–530, 1945. 2
1945
-
[15]
Hayek.Law, Legislation and Liberty
Friedrich A. Hayek.Law, Legislation and Liberty. University of Chicago Press, 1973. 17
1973
-
[16]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021. 5, 24 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
John H. Holland. Properties of the bucket brigade algorithm. InProceedings of the 1st International Conference on Genetic Algorithms, 1985. 17
1985
-
[18]
Dosa: Differentiable model-based one-loop search for dnn accelerators
Charles Hong, Qijing Huang, Grace Dinh, Mahesh Subedar, and Yakun Sophia Shao. Dosa: Differentiable model-based one-loop search for dnn accelerators. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, pages 209–224, 2023. 6, 24, 25
2023
-
[19]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023. 2
2023
-
[20]
Alma: Hierarchical learning for composite multi- agent tasks.Advances in neural information processing systems, 35:7155–7166, 2022
Shariq Iqbal, Robby Costales, and Fei Sha. Alma: Hierarchical learning for composite multi- agent tasks.Advances in neural information processing systems, 35:7155–7166, 2022. 2
2022
-
[21]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Towards a Science of Scaling Agent Systems
Yubin Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Yun Liu, et al. Towards a science of scaling agent systems. arXiv preprint arXiv:2512.08296, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Shalev Lifshitz, Sheila A McIlraith, and Yilun Du. Multi-agent verification: Scaling test-time compute with multiple verifiers.arXiv preprint arXiv:2502.20379, 2025. 17
-
[24]
Improved multi-agent collaboration with multi-turn reinforcement learning
Shuo Liu, Tianle Chen, and Christopher Amato. Improved multi-agent collaboration with multi-turn reinforcement learning. InFirst Workshop on Multi-Turn Interactions in Large Language Models. 17
-
[25]
Reliability and Effectiveness of Autonomous AI Agents in Supply Chain Management
Carol Xuan Long, David Simchi-Levi, Feng Zhu, Huangyuan Su, Andre P. Calmon, and Flavio P. Calmon. Reliability and effectiveness of autonomous ai agents in supply chain management. arXiv preprint arXiv:2605.17036, 2026. 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Simon and Schuster, 1988
Marvin Minsky.The Society of Mind. Simon and Schuster, 1988. 17
1988
-
[27]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025. 5, 24, 26
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Deep decentralized multi-task multi-agent reinforcement learning under partial observability
Shayegan Omidshafiei, Jason Pazis, Christopher Amato, Jonathan P How, and John Vian. Deep decentralized multi-task multi-agent reinforcement learning under partial observability. In International conference on machine learning, pages 2681–2690. PMLR, 2017. 2
2017
-
[29]
Maporl: Multi-agent post-co-training for collaborative large language models with reinforcement learning
Chanwoo Park, Seungju Han, Xingzhi Guo, Asuman E Ozdaglar, Kaiqing Zhang, and Joo- Kyung Kim. Maporl: Multi-agent post-co-training for collaborative large language models with reinforcement learning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30215–30248, 2025. 17
2025
-
[30]
Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37: 126544–126565, 2024
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37: 126544–126565, 2024. 2
2024
-
[31]
Shvetank Prakash, Andrew Cheng, Arya Tschand, Mark Mazumder, Varun Gohil, Jeffrey Ma, Jason Yik, Zishen Wan, Jessica Quaye, Elisavet Lydia Alvanaki, et al. Quarch: A benchmark for evaluating llm reasoning in computer architecture.arXiv preprint arXiv:2510.22087, 2025. 25
-
[32]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186, 2024. 2 11
2024
-
[33]
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Ao Qu, Han Zheng, Zijian Zhou, Yihao Yan, Yihong Tang, Shao Yong Ong, Fenglu Hong, Kaichen Zhou, Chonghe Jiang, Minwei Kong, et al. Coral: Towards autonomous multi-agent evolution for open-ended discovery.arXiv preprint arXiv:2604.01658, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
The neural bucket brigade: A local learning algorithm for dynamic feedforward and recurrent networks.Connection Science, 1(4):403–412, 1989
Jürgen Schmidhuber. The neural bucket brigade: A local learning algorithm for dynamic feedforward and recurrent networks.Connection Science, 1(4):403–412, 1989. 17
1989
-
[35]
Openevolve: an open-source evolutionary coding agent, 2025
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent, 2025. URL https://github.com/algorithmicsuperintelligence/openevolve. 5, 24, 26
2025
-
[36]
Vighnesh Subramaniam, Yilun Du, Joshua B Tenenbaum, Antonio Torralba, Shuang Li, and Igor Mordatch. Multiagent finetuning: Self improvement with diverse reasoning chains.arXiv preprint arXiv:2501.05707, 2025. 17
-
[37]
Market-based architectures in rl and beyond
Abhimanyu Pallavi Sudhir and Long Tran-Thanh. Market-based architectures in rl and beyond. Accepted to AAMAS 2025 Blue Sky Track, abs/2503.05828, 2025. 17
-
[38]
Gibbon: Efficient co-exploration of nn model and processing-in-memory architecture
Hanbo Sun, Chenyu Wang, Zhenhua Zhu, Xuefei Ning, Guohao Dai, Huazhong Yang, and Yu Wang. Gibbon: Efficient co-exploration of nn model and processing-in-memory architecture. In2022 Design, Automation & Test in Europe Conference & Exhibition (DATE), pages 867–872. IEEE, 2022. 25
2022
-
[39]
Scaling long-horizon LLM agent via context-folding.arXiv preprint arXiv:2510.11967,
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon llm agent via context-folding.arXiv preprint arXiv:2510.11967, 2025. 2
-
[40]
Genai for systems: Recurring challenges and design principles from software to silicon, 2026
Arya Tschand, Chenyu Wang, Zishen Wan, Andrew Cheng, Ioana Cristescu, Kevin He, Howard Huang, Alexander Ingare, Akseli Kangaslahti, Sara Kangaslahti, Theo Lebryk, Hongjin Lin, Jeffrey Jian Ma, Alexandru Meterez, Clara Mohri, Depen Morwani, Sunny Qin, Roy Rinberg, Paula Rodriguez-Diaz, Alyssa Mia Taliotis, Pernille Undrum Fathi, Rosie Zhao, Todd Zhou, and ...
-
[41]
Slm-mux: Orchestrating small language models for reasoning
Chenyu Wang, Zishen Wan, Hao Kang, Emma Chen, Zhiqiang Xie, Tushar Krishna, Vi- jay Janapa Reddi, and Yilun Du. Slm-mux: Orchestrating small language models for reasoning. arXiv preprint arXiv:2510.05077, 2025. 17
-
[42]
Jian Sheng Wang. Aesp: A human-sovereign economic protocol for ai agents with privacy- preserving settlement.arXiv preprint arXiv:2603.00318, 2026. 17
-
[43]
Miles Wang, Robi Lin, Kat Hu, Joy Jiao, Neil Chowdhury, Ethan Chang, and Tejal Patwardhan. Frontierscience: Evaluating ai’s ability to perform expert-level scientific tasks.arXiv preprint arXiv:2601.21165, 2026. 5, 25
-
[44]
ThetaEvolve: Test-time Learning on Open Problems
Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, et al. Thetaevolve: Test-time learning on open problems. arXiv preprint arXiv:2511.23473, 2025. 26
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
arXiv preprint arXiv:2602.04837 , year=
Zhaotian Weng, Antonis Antoniades, Deepak Nathani, Zhen Zhang, Xiao Pu, and Xin Eric Wang. Group-evolving agents: Open-ended self-improvement via experience sharing.arXiv preprint arXiv:2602.04837, 2026. 5, 9, 24
-
[46]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024. 2
2024
-
[47]
The agent economy: A blockchain-based foundation for autonomous ai agents
Minghui Xu. The agent economy: A blockchain-based foundation for autonomous ai agents
-
[48]
Comas: Co-evolving multi-agent systems via interaction rewards.arXiv preprint arXiv:2510.08529, 2025
Xiangyuan Xue, Yifan Zhou, Guibin Zhang, Zaibin Zhang, Yijiang Li, Chen Zhang, Zhenfei Yin, Philip Torr, Wanli Ouyang, and Lei Bai. Comas: Co-evolving multi-agent systems via interaction rewards.arXiv preprint arXiv:2510.08529, 2025. 2
-
[49]
Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems,
Yingxuan Yang, Huacan Chai, Shuai Shao, Yuanyi Song, Siyuan Qi, Renting Rui, and Weinan Zhang. Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems,
- [50]
-
[51]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022. 2, 5, 24
2022
-
[52]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Learning to discover at test time.arXiv preprint, 2026
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, and Yu Sun. Learning to discover at test time.arXiv preprint, 2026. 26
2026
-
[54]
Dynamic role assignment for multi-agent debate.arXiv preprint arXiv:2601.17152, 2026
Miao Zhang, Junsik Kim, Siyuan Xiang, Jian Gao, and Cheng Cao. Dynamic role assignment for multi-agent debate.arXiv preprint arXiv:2601.17152, 2026. 17
-
[55]
Reso: A reward-driven self-organizing llm-based multi-agent system for reasoning tasks
Heng Zhou, Hejia Geng, Xiangyuan Xue, Li Kang, Yiran Qin, Zhiyong Wang, Zhenfei Yin, and Lei Bai. Reso: A reward-driven self-organizing llm-based multi-agent system for reasoning tasks. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15990–16009, 2025. 9
2025
-
[56]
Andy Zhu and Yingjun Du. A role-aware multi-agent framework for financial education question answering with llms.arXiv preprint arXiv:2509.09727, 2025. 17 13 Appendix - Table of Contents A Pseudo Code 16 B Extended Related Works 17 C Theoretical Motivations 17 C.1 Market selection drives bids toward value . . . . . . . . . . . . . . . . . . . . . . 18 C.2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.