Symmetry-Compatible Principle for Optimizer Design: Embeddings, LM Heads, SwiGLU MLPs, and MoE Routers
Pith reviewed 2026-06-30 18:39 UTC · model grok-4.3
The pith
The gradient update rule for each weight block should be equivariant under its symmetry group.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
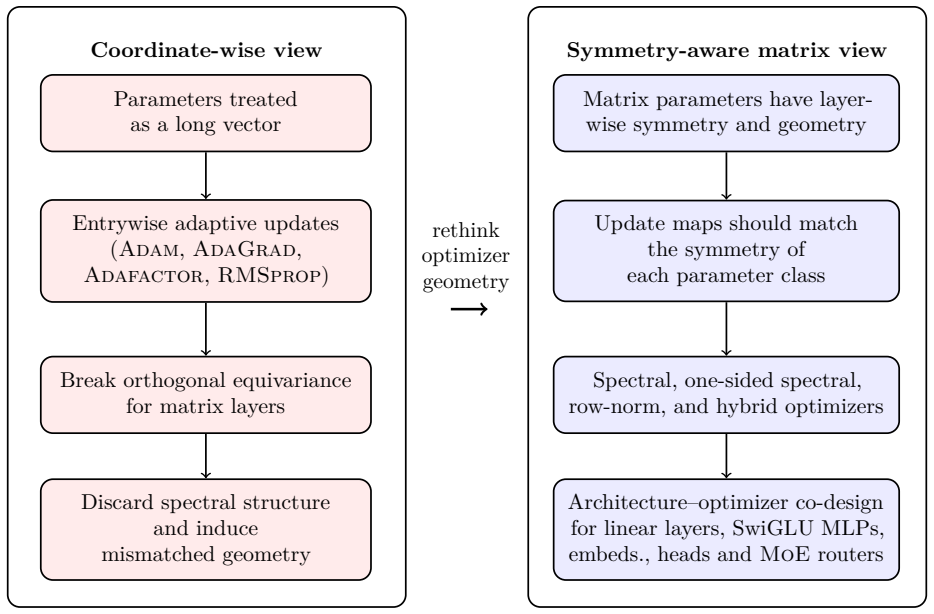
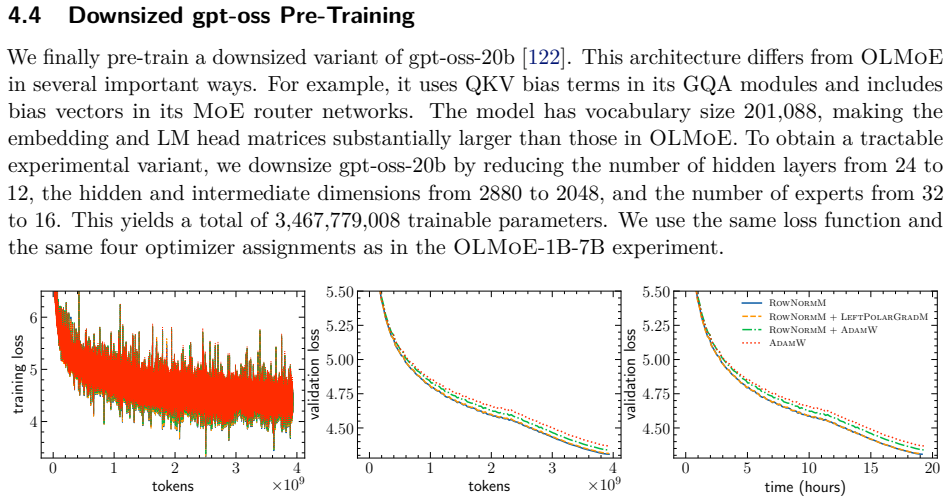
Following the symmetry-compatible principle yields an end-to-end layerwise optimizer stack in which each major matrix-valued parameter class is assigned an update whose equivariance matches its symmetry group, and these updates consistently improve final validation loss, reduce expert load imbalance, and improve training stability over AdamW.
What carries the argument
Symmetry-compatible principle requiring the gradient update rule to be equivariant under the symmetry group acting on the corresponding weight block.
If this is right
- Embeddings and LM heads receive one-sided spectral or row-norm updates.
- SwiGLU projections receive centered row-norm or hybrid spectral updates.
- MoE router matrices receive row-aware, column-aware, or left-spectral updates.
- Sparse MoE models exhibit reduced expert load imbalance.
- Several runs show controlled vocabulary-logit growth and improved router stability.
Where Pith is reading between the lines
- The same principle could be applied to attention weight matrices by identifying their relevant symmetry groups.
- Defaulting to coordinate-wise methods may be suboptimal once parameter symmetries are explicitly catalogued for a given architecture.
- The approach invites systematic classification of symmetry groups across common layer types before optimizer selection.
Load-bearing premise
That the identified symmetry groups for embeddings, SwiGLU, and MoE routers are the ones whose equivariance actually drives the observed gains rather than incidental details of the implementations.
What would settle it
An ablation in the same pre-training setups that replaces the symmetry-equivariant updates with otherwise identical rules that deliberately violate the relevant equivariance and shows no loss in performance or stability.
Figures





read the original abstract
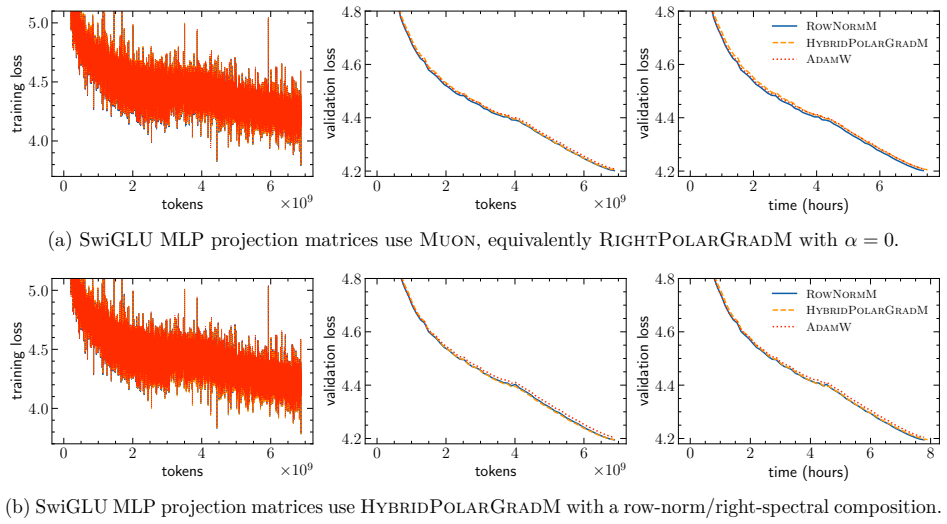
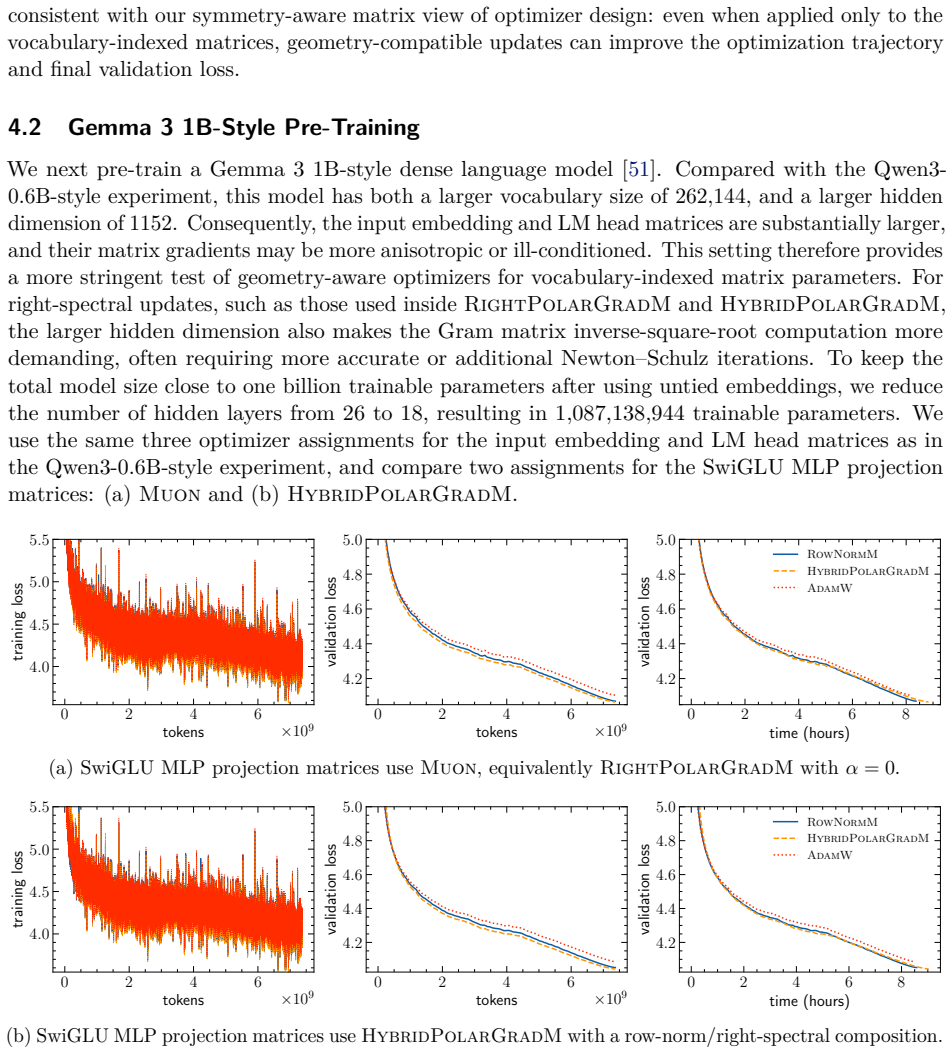
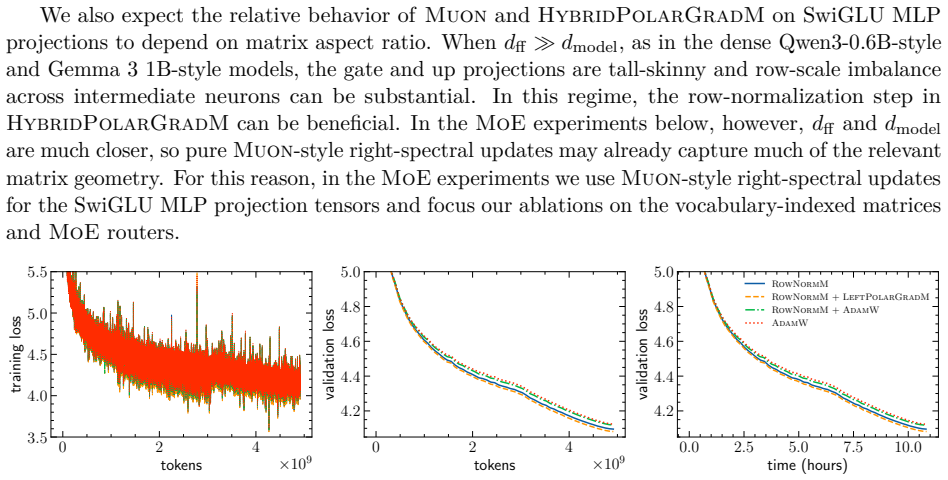
A striking geometric disparity has long persisted in the practice of deep learning. While modern neural network architectures naturally exhibit rich symmetry and equivariance properties, popular optimizers such as Adam and its variants operate inherently coordinate-wise, rendering them unable to respect the equivariance structures of the parameter space. We address this disparity by introducing a symmetry-compatible principle for optimizer design: the gradient update rule should be equivariant under the symmetry group acting on the corresponding weight block. Following this principle, we first provide a unified perspective on bi-orthogonally equivariant updates for general matrix layers, as employed by stochastic spectral descent, Muon, Scion, and polar gradient methods. More importantly, by moving from orthogonal groups to permutation and shared-shift symmetries, we derive symmetry-compatible optimizers for parameter blocks whose symmetries differ from those of general matrix layers: embedding and LM head matrices, SwiGLU MLP projections, and MoE router matrices. These constructions include one-sided spectral, row-norm, hybrid row-norm/spectral, row-aware, column-aware, centered row-norm, and left-spectral updates. They yield an end-to-end layerwise optimizer stack in which each major matrix-valued parameter class is assigned an update whose equivariance matches its symmetry group. We corroborate this principle through pre-training experiments on dense and sparse MoE language models, including Qwen3-0.6B-style, Gemma 3 1B-style, OLMoE-1B-7B-style, and downsized gpt-oss architectures. Across these experiments, symmetry-compatible update rules consistently improve final validation loss, reduce expert load imbalance in sparse MoE models, and in several cases control final vocabulary-logit growth, improve router stability, and overall training stability over the corresponding AdamW updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a symmetry-compatible principle for optimizer design: gradient updates for each parameter block should be equivariant under the symmetry group acting on that block. It unifies bi-orthogonally equivariant methods for general matrices and derives new families (one-sided spectral, row-norm, hybrid row-norm/spectral, centered row-norm, left-spectral) for blocks with permutation symmetry (embeddings, LM heads, MoE routers) or shared-shift symmetry (SwiGLU projections). These are assembled into an end-to-end layerwise optimizer stack and tested via pre-training on Qwen3-0.6B-style, Gemma 3 1B-style, OLMoE-1B-7B-style, and downsized gpt-oss models, with claims of improved validation loss, reduced expert load imbalance, better router stability, and controlled vocabulary-logit growth relative to AdamW.
Significance. If the reported gains can be isolated to the equivariance property rather than auxiliary normalization or scaling, the principle supplies a systematic, architecture-aware route to optimizer construction that goes beyond coordinate-wise methods. The unified treatment of bi-orthogonal updates and the explicit constructions for non-orthogonal symmetries are constructive contributions that could influence layer-specific optimizer design in large-model training.
major comments (2)
- [Experiments] Experiments section: the central claim that symmetry-compatible updates produce the observed gains in validation loss, load balance, and stability rests on comparisons solely against AdamW. No ablations or controls are described that hold normalization, centering, or spectral scaling fixed while breaking the stated equivariance (permutation or shared-shift), leaving open whether the functional forms' auxiliary properties, rather than equivariance, drive the results.
- [§3] §3 (derivations of row-norm, centered row-norm, and left-spectral updates): the update families are constructed to enforce the target equivariance, yet the same algebraic steps simultaneously introduce row-wise centering and norm-based scaling. Without a side-by-side comparison to a non-equivariant update that retains these auxiliary operations, the attribution of performance differences specifically to symmetry matching cannot be verified.
minor comments (1)
- [Abstract] Abstract: statements of 'consistent gains' and 'several cases' of improved stability are not accompanied by effect sizes, run counts, or statistical measures, making it difficult to assess practical significance from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the symmetry-compatible principle. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that symmetry-compatible updates produce the observed gains in validation loss, load balance, and stability rests on comparisons solely against AdamW. No ablations or controls are described that hold normalization, centering, or spectral scaling fixed while breaking the stated equivariance (permutation or shared-shift), leaving open whether the functional forms' auxiliary properties, rather than equivariance, drive the results.
Authors: We agree that dedicated ablations isolating equivariance from auxiliary operations (centering, row-norm scaling) would strengthen attribution. However, these auxiliaries are not independent add-ons; they arise necessarily from the algebraic conditions that enforce equivariance under the permutation or shared-shift groups, as derived in §3. A control that retains exactly those auxiliaries while breaking equivariance would require an ad-hoc construction outside the symmetry principle. In revision we will expand the Experiments section with an explicit discussion of this inseparability and note the limitation of the current controls. revision: yes
-
Referee: [§3] §3 (derivations of row-norm, centered row-norm, and left-spectral updates): the update families are constructed to enforce the target equivariance, yet the same algebraic steps simultaneously introduce row-wise centering and norm-based scaling. Without a side-by-side comparison to a non-equivariant update that retains these auxiliary operations, the attribution of performance differences specifically to symmetry matching cannot be verified.
Authors: The derivations begin from the equivariance requirement; centering and norm scaling are the direct algebraic consequences of that requirement rather than separate design choices. A non-equivariant update preserving the identical auxiliaries would not satisfy the group action and therefore falls outside the scope of the proposed principle. We will revise §3 to emphasize this derivation link and to acknowledge that empirical isolation via controls remains an open experimental question for future work. revision: yes
Circularity Check
No circularity: principle stated independently, updates derived from it, gains measured empirically on held-out metrics
full rationale
The paper introduces the symmetry-compatible principle as an independent design rule (gradient update equivariant under the symmetry group of each weight block). It then derives specific update families (one-sided spectral, row-norm, etc.) that satisfy the stated equivariance by construction for embedding/LM-head (permutation), SwiGLU (shared-shift), and MoE router (permutation) symmetries. These derivations are presented as following from the principle and prior bi-orthogonal work, not as predictions fitted to the target performance numbers. Final claims of improved validation loss, load balance, and stability are supported by direct comparisons to AdamW on held-out pre-training runs across multiple architectures; no step equates a claimed result to its own defining inputs or reduces to a self-citation chain. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The gradient update rule should be equivariant under the symmetry group acting on the corresponding weight block.
Forward citations
Cited by 1 Pith paper
-
Dead-Direction Conditioners: Gauge-Equivariant Preconditioning for Deep Networks
Dead-Direction Conditioners provide gauge-equivariant preconditioning by conditioning optimizer state on symmetry orbits, yielding improved resistance to over-training collapse and higher detection of dead directions ...
Reference graph
Works this paper leans on
-
[1]
Abbe and E
E. Abbe and E. Boix-Adsera. On the non-universality of deep learning: quantifying the cost of symmetry. InAdvances in Neural Information Processing Systems (NeurIPS). 2022
2022
- [2]
- [3]
-
[4]
Ainslie, J
J. Ainslie, J. Lee-Thorp, M. De Jong, Y. Zemlyanskiy, F. Lebrón, and S. Sanghai. GQA: Training gen- eralized multi-query transformer models from multi-head checkpoints. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). 2023
2023
-
[5]
Amsel, D
N. Amsel, D. Persson, C. Musco, and R. M. Gower. The Polar Express: Optimal matrix sign methods and their application to the Muon algorithm. InInternational Conference on Learning Representations (ICLR). 2026
2026
-
[6]
K. An, Y. Liu, R. Pan, S. Ma, D. Goldfarb, and T. Zhang. ASGO: Adaptive structured gradient optimization. InAdvances in Neural Information Processing Systems (NeurIPS). 2025
2025
- [7]
-
[8]
Q. Anthony, Y. Tokpanov, S. Szot, S. Rajagopal, P. Medepalli, R. Iyer, V. Shyam, A. Golubeva, A. Chaurasia, et al. Training foundation models on a full-stack AMD platform: Compute, networking, and system design.arXiv preprint arXiv:2511.17127, 2025
-
[9]
L. Autonne. Sur les groupes linéaires, réels et orthogonaux.Bulletin de la Société Mathématique de France, 30:121–134, 1902
1902
- [10]
-
[11]
Bernstein
J. Bernstein. Deriving Muon. 2025
2025
-
[12]
Bernstein
J. Bernstein. Modular manifolds.Thinking Machines Lab: Connectionism, 2025. https:// thinkingmachines.ai/blog/modular-manifolds/
2025
-
[13]
Bernstein and L
J. Bernstein and L. Newhouse. Old optimizer, new norm: An anthology. InOPT 2024: Optimization for Machine Learning. 2024
2024
-
[14]
Bernstein and L
J. Bernstein and L. Newhouse. Modular duality in deep learning. InProceedings of the International Conference on Machine Learning (ICML). 2025
2025
-
[15]
Bernstein, Y.-X
J. Bernstein, Y.-X. Wang, K. Azizzadenesheli, and A. Anandkumar. signSGD: Compressed optimisation for non-convex problems. InProceedings of the International Conference on Machine Learning (ICML). 2018
2018
-
[16]
Bhatia.Matrix Analysis, volume 169
R. Bhatia.Matrix Analysis, volume 169. Springer Science & Business Media, 2013
2013
-
[17]
T. Boissin, T. Massena, F. Mamalet, and M. Serrurier. Turbo-Muon: Accelerating orthogonality-based optimization with pre-conditioning.arXiv preprint arXiv:2512.04632, 2025
-
[18]
An Introduction to Vision-Language Modeling,
F. Bordes, R. Y. Pang, A. Ajay, A. C. Li, A. Bardes, S. Petryk, O. Mañas, Z. Lin, A. Mahmoud, et al. An introduction to vision-language modeling.arXiv preprint arXiv:2405.17247, 2024. 33
-
[19]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS). 2020
2020
-
[20]
Buchanan
S. Buchanan. A faster manifold Muon with ADMM.https://sdbuchanan.com/blog/manifold-muon/, 2025
2025
-
[21]
Carlson, V
D. Carlson, V. Cevher, and L. Carin. Stochastic spectral descent for restricted Boltzmann machines. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS). 2015
2015
-
[22]
Carlson, E
D. Carlson, E. Collins, Y.-P. Hsieh, L. Carin, and V. Cevher. Preconditioned spectral descent for deep learning. InAdvances in Neural Information Processing Systems (NeurIPS). 2015
2015
-
[23]
Carlson, Y.-P
D. Carlson, Y.-P. Hsieh, E. Collins, L. Carin, and V. Cevher. Stochastic spectral descent for discrete graphical models.IEEE Journal of Selected Topics in Signal Processing, 10(2):296–311, 2016
2016
-
[24]
On the Convergence of Muon and Beyond
D. Chang, Y. Liu, and G. Yuan. On the convergence of Muon and beyond.arXiv preprint arXiv:2509.15816, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
MuonEq: Balancing Before Orthogonalization with Lightweight Equilibration
D. Chang, Q. Shi, L. Zhang, Y. Li, R. Zhang, Y. Lu, Y. Liu, and G. Yuan. MuonEq: Balancing before orthogonalization with lightweight equilibration.arXiv preprint arXiv:2603.28254, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [26]
-
[27]
Y. Chen, Y. Chi, J. Fan, and C. Ma. Spectral methods for data science: A statistical perspective. Foundations and Trends®in Machine Learning, 14(5):566–806, 2021
2021
-
[28]
Chowdhery, S
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, et al. PaLM: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240):1–113, 2023
2023
-
[29]
M. Crawshaw, C. Modi, M. Liu, and R. M. Gower. An exploration of non-Euclidean gradient descent: Muon and its many variants.arXiv preprint arXiv:2510.09827, 2025
- [30]
-
[31]
Dao and A
T. Dao and A. Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InProceedings of the International Conference on Machine Learning (ICML). 2024
2024
-
[32]
Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier. Language modeling with gated convolutional networks. InProceedings of the International Conference on Machine Learning (ICML). 2017
2017
-
[33]
D. Davis and D. Drusvyatskiy. When do spectral gradient updates help in deep learning?arXiv preprint arXiv:2512.04299, 2025
-
[34]
DeepSeek-V4: Towards highly efficient million-token context intelligence
DeepSeek-AI. DeepSeek-V4: Towards highly efficient million-token context intelligence. 2026
2026
-
[35]
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, et al. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Dehghani, J
M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. Steiner, M. Caron, R. Geirhos, et al. Scaling vision transformers to 22 billion parameters. InProceedings of the International Conference on Machine Learning (ICML). 2023. 34
2023
-
[37]
S. Deng, Z. Ouyang, T. Pang, Z. Liu, R. Jin, S. Yu, and Y. Yang. RMNP: Row-momentum normalized preconditioning for scalable matrix-based optimization.arXiv preprint arXiv:2603.20527, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Dewulf, D
A. Dewulf, D. Pai, L. Yang, A. Zhang, and B. Keigwin. Aurora: A leverage-aware optimizer for rectangular matrices. 2026
2026
-
[39]
C. Ding, D. Sun, J. Sun, and K.-C. Toh. Spectral operators of matrices.Mathematical Programming, 168(1):509–531, 2018
2018
-
[40]
C. Ding, D. Sun, J. Sun, and K.-C. Toh. Spectral operators of matrices: Semismoothness and characterizations of the generalized Jacobian.SIAM Journal on Optimization, 30(1):630–659, 2020
2020
-
[41]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR). 2021
2021
-
[42]
Z. Du, H. He, and W. Su. Uncovering symmetry transfer in large language models via layer-peeled optimization.arXiv preprint arXiv:2605.12756, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [43]
-
[44]
Duchi, E
J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization.Journal of Machine Learning Research, 12:2121–2159, 2011
2011
-
[45]
R. Eschenhagen, A. Cai, T.-H. Lee, and H.-J. M. Shi. Clarifying Shampoo: Adapting spectral descent to stochasticity and the parameter trajectory.arXiv preprint arXiv:2602.09314, 2026
-
[46]
Eschenhagen, A
R. Eschenhagen, A. Immer, R. Turner, F. Schneider, and P. Hennig. Kronecker-factored approximate curvature for modern neural network architectures. InAdvances in Neural Information Processing Systems (NeurIPS). 2023
2023
-
[47]
Layer sharding for large-scale training with Muon.https://www.essential.ai/research/ infra, 2025
Essential AI. Layer sharding for large-scale training with Muon.https://www.essential.ai/research/ infra, 2025
2025
- [48]
-
[49]
O. Filatov, J. Wang, J. Ebert, and S. Kesselheim. Optimal scaling needs optimal norm.arXiv preprint arXiv:2510.03871, 2025
-
[50]
Frans, S
K. Frans, S. Levine, and P. Abbeel. A stable whitening optimizer for efficient neural network training. InAdvances in Neural Information Processing Systems (NeurIPS). 2025
2025
-
[51]
Gemma Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Memory-Efficient LLM Pretraining via Minimalist Optimizer Design
A. Glentis, J. Li, A. Han, and M. Hong. A minimalist optimizer design for LLM pretraining.arXiv preprint arXiv:2506.16659, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
GLM-4.5 Team, A. Zeng, X. Lv, Q. Zheng, Z. Hou, B. Chen, C. Xie, C. Wang, D. Yin, et al. GLM-4.5: Agentic, reasoning, and coding (ARC) foundation models.arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
GLM-5 Team, A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, et al. GLM-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026. 35
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Goldfarb, Y
D. Goldfarb, Y. Ren, and A. Bahamou. Practical quasi-Newton methods for training deep neural networks. InAdvances in Neural Information Processing Systems (NeurIPS). 2020
2020
-
[57]
S. Gong, S. Agarwal, Y. Zhang, J. Ye, L. Zheng, M. Li, C. An, P. Zhao, W. Bi, et al. Scaling diffusion language models via adaptation from autoregressive models. InInternational Conference on Learning Representations (ICLR). 2025
2025
- [58]
-
[59]
A. Gonon, A.-A. Muşat, and N. Boumal. Insights on Muon from simple quadratics.arXiv preprint arXiv:2602.11948, 2026
-
[60]
Gemma 4 model card
Google DeepMind. Gemma 4 model card. 2026
2026
-
[61]
E. Grishina, M. Smirnov, and M. Rakhuba. Accelerating Newton-Schulz iteration for orthogonalization via Chebyshev-type polynomials.arXiv preprint arXiv:2506.10935, 2025
-
[62]
Gu and T
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces. InProceedings of the Conference on Language Modeling (COLM). 2024
2024
- [63]
-
[64]
Gupta, T
V. Gupta, T. Koren, and Y. Singer. Shampoo: Preconditioned stochastic tensor optimization. In Proceedings of the International Conference on Machine Learning (ICML). 2018
2018
-
[65]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2016
2016
-
[66]
N. J. Higham. Computing the polar decomposition—with applications.SIAM Journal on Scientific and Statistical Computing, 7(4):1160–1174, 1986
1986
-
[67]
N. J. Higham. Stable iterations for the matrix square root.Numerical Algorithms, 15(2):227–242, 1997
1997
-
[68]
N. J. Higham.Functions of Matrices: Theory and Computation. Society for Industrial and Applied Mathematics, 2008
2008
-
[69]
Hoffmann, S
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de las Casas, L. A. Hendricks, J. Welbl, et al. Training compute-optimal large language models. InAdvances in Neural Information Processing Systems (NeurIPS). 2022
2022
-
[70]
R. A. Horn and C. R. Johnson.Topics in Matrix Analysis. Cambridge University Press, 1994
1994
-
[71]
R. A. Horn and C. R. Johnson.Matrix Analysis. Cambridge University Press, 2nd edition, 2012
2012
-
[72]
Y. Hu, H. Song, J. Deng, J. Wang, J. Chen, K. Zhou, Y. Zhu, J. Jiang, Z. Dong, et al. YuLan-Mini: Pushing the limits of open data-efficient language model. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) (Volume 1: Long Papers). 2025
2025
-
[73]
LiMuon: Light and Fast Muon Optimizer for Large Models
F. Huang, Y. Luo, and S. Chen. LiMuon: Light and fast Muon optimizer for large models.arXiv preprint arXiv:2509.14562, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de las Casas, E. B. Hanna, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [75]
-
[76]
Jiang, J
Z. Jiang, J. Gu, H. Zhu, and D. Pan. Pre-RMSNorm and Pre-CRMSNorm transformers: equivalent and efficient Pre-LN transformers. InAdvances in Neural Information Processing Systems (NeurIPS). 2023
2023
-
[77]
Jordan, J
K. Jordan, J. Bernstein, B. Rappazzo, @fernbear.bsky.social, B. Vlado, Y. Jiacheng, F. Cesista, B. Koszarsky, and @Grad62304977.modded-nanogpt: Speedrunning the NanoGPT baseline. 2024
2024
-
[78]
Jordan, Y
K. Jordan, Y. Jin, V. Boza, Y. Jiacheng, F. Cecista, L. Newhouse, and J. Bernstein. Muon: An optimizer for hidden layers in neural networks. 2024
2024
-
[79]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, et al. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[80]
Kasimbeg, F
P. Kasimbeg, F. Schneider, R. Eschenhagen, J. Bae, C. S. Sastry, M. Saroufim, B. Feng, L. Wright, E. Z. Yang, et al. Accelerating neural network training: An analysis of the AlgoPerf competition. In International Conference on Learning Representations (ICLR). 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.