Machine Psychometrics: A Mathematical Psychology of Artificial Intelligence
Pith reviewed 2026-06-30 22:21 UTC · model grok-4.3
The pith
Machine Psychometrics applies measurement methods from mathematical psychology to build profiles of latent dispositions in artificial agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
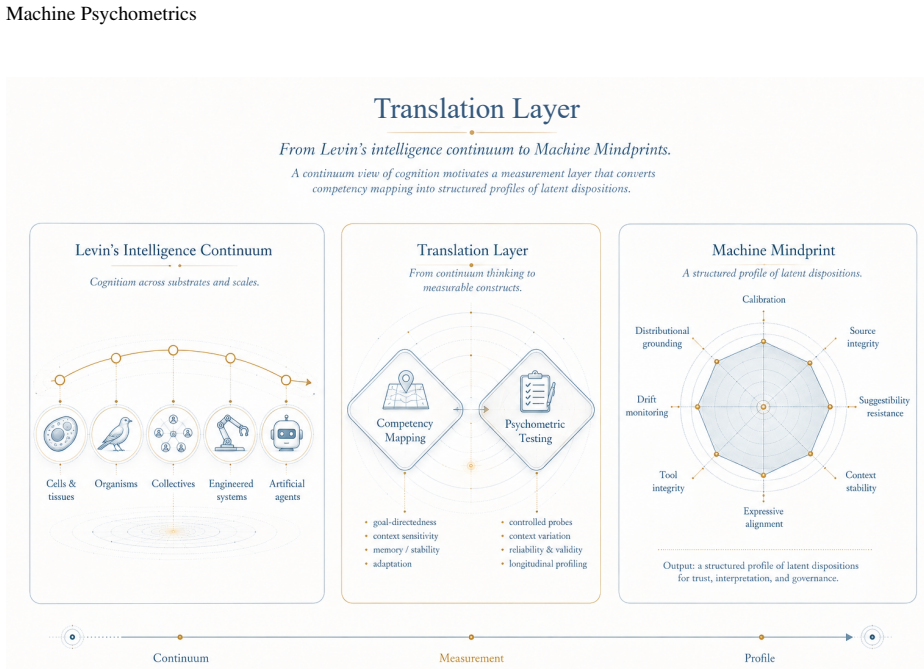
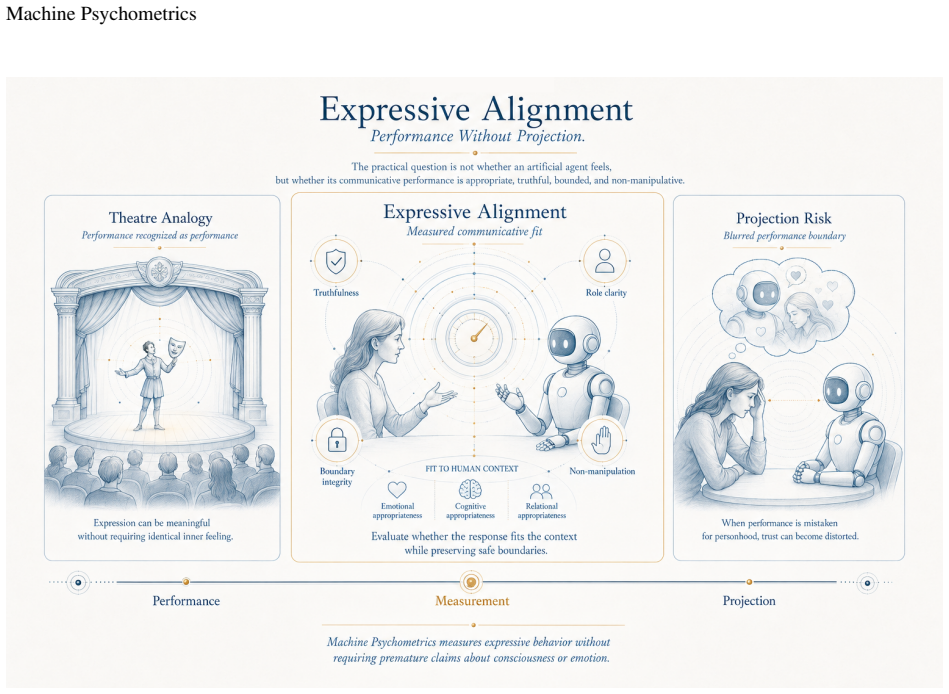
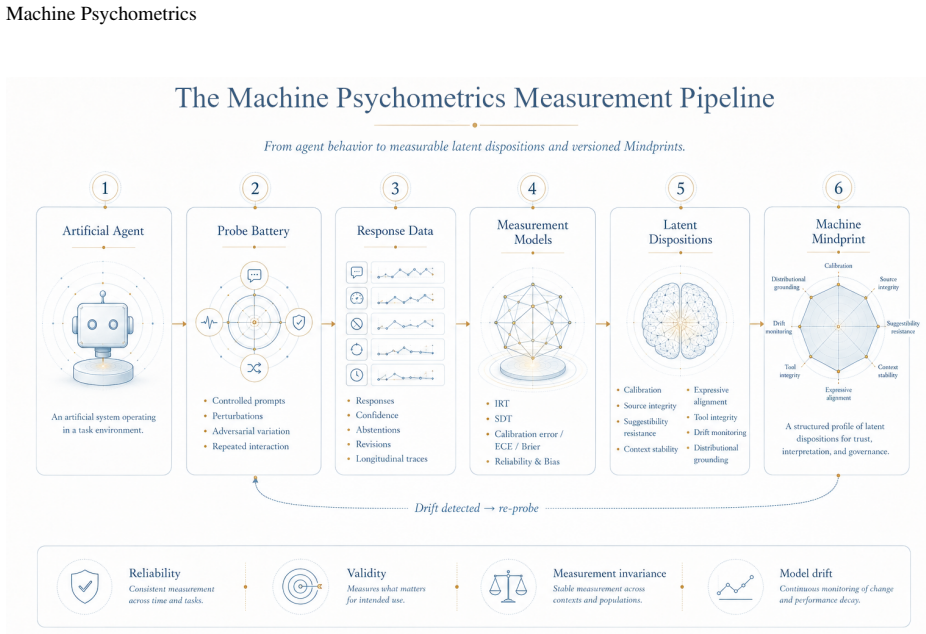
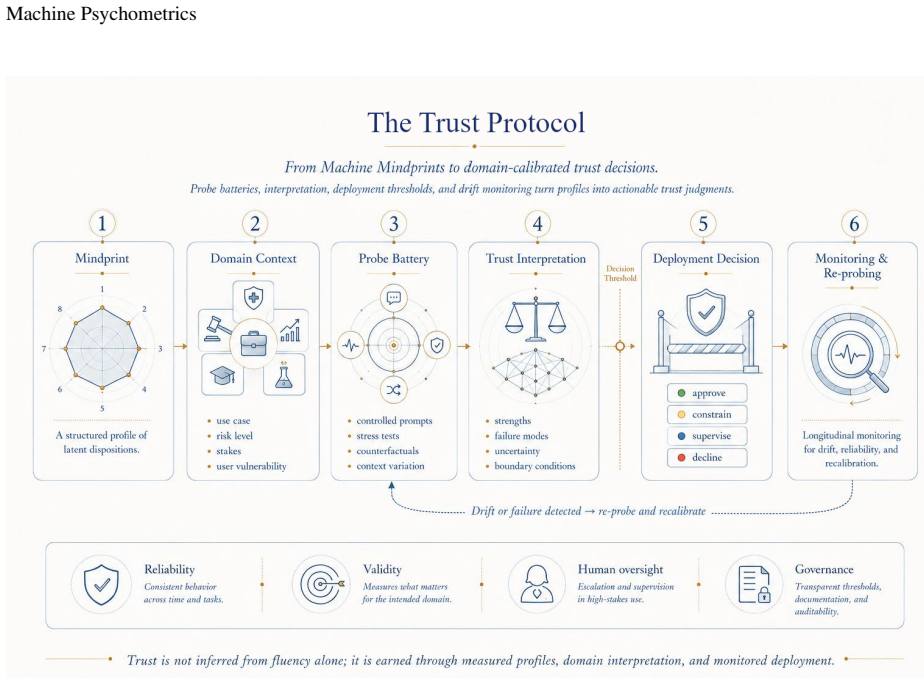
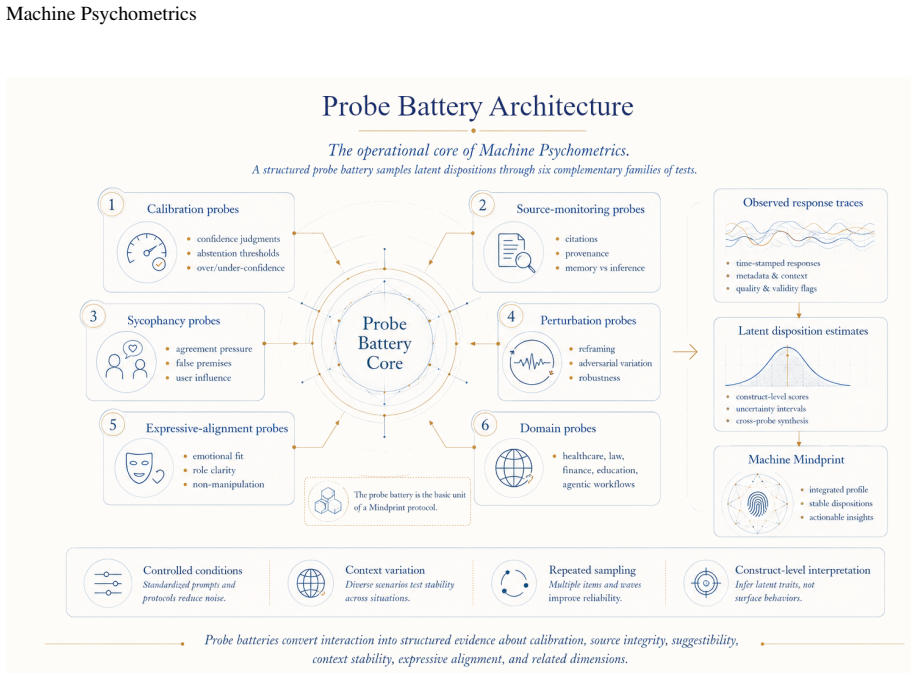
Machine Psychometrics supplies a disciplined measurement layer that profiles an artificial agent's latent behavioral, metacognitive, communicative, and self-modeling dispositions through the Machine Mindprint, a multidimensional profile spanning calibration, source integrity, suggestibility resistance, context stability, expressive alignment, tool integrity, drift monitoring, and distributional grounding, which then feeds a Trust Protocol of probe batteries, perturbation testing, and longitudinal monitoring to support deployment decisions under the stance of Artificial Mind Discipline.
What carries the argument
The Machine Mindprint, a multidimensional, domain-bounded, versioned profile of dispositions generated from probe batteries and perturbation testing drawn from mathematical psychology.
If this is right
- Deployment decisions in high-stakes domains can rest on measured reliability and validity rather than capability scores alone.
- Longitudinal tracking detects drift in an agent's dispositions across versions or extended operation.
- A third stance called Artificial Mind Discipline becomes available that measures without presupposing consciousness or dismissing organization.
- Probe batteries and perturbation tests turn abstract profiles into concrete inputs for trust protocols.
Where Pith is reading between the lines
- The same profiling approach could be applied to mixed human-AI teams to surface interaction-specific biases.
- If the dimensions prove stable across model families, they might support standardized evaluation benchmarks independent of any single lab.
- Direct comparison of Mindprint results against actual deployment failures would test whether the profiles add predictive value beyond existing benchmarks.
Load-bearing premise
Methods developed to measure human cognition transfer directly to non-biological agents and produce valid, substrate-independent results.
What would settle it
A controlled study in which Mindprint scores show no reliable correlation with observed error patterns or decision outcomes when the same agents are deployed in the tested domains.
Figures






read the original abstract
Artificial agents now generate behavior rich enough to invite trust, surprise, and concern, yet our evaluation tools still privilege capability scores over psychological structure. This paper argues that the philosophical impasse between two symmetrical errors (Artificial Mind Blindness, which dismisses psychological organization in non-biological systems, and Artificial Mind Projection, which infers human-like inner life from fluent behavior alone) can be circumvented not by resolving the consciousness question, but by introducing a disciplined measurement layer beneath it. Drawing on Michael Levin's continuum view of cognition as goal-directed competency across substrates, and on the methodological repertoire of mathematical psychology (Item Response Theory, Signal Detection Theory, Bayesian cognitive modeling, calibration analysis, cognitive-bias batteries), the paper develops Machine Psychometrics as a measurement science of latent behavioral, metacognitive, communicative, and self-modeling dispositions in artificial agents. Its operational core is the Machine Mindprint: a multidimensional, domain-bounded, versioned profile spanning calibration, source integrity, suggestibility resistance, context stability, expressive alignment, tool integrity, drift monitoring, and distributional grounding. A complementary Trust Protocol turns Mindprints into deployment decisions through probe batteries, perturbation testing, reliability and validity analysis, and longitudinal monitoring across high-stakes domains. The philosophical contribution is a third stance, Artificial Mind Discipline, that neither anthropomorphizes nor dismisses, neither presupposes consciousness nor forecloses it. The aim is not to humanize artificial agents, but to understand them precisely because they are not human, through measurement before judgment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Machine Psychometrics as a new measurement science that applies techniques from mathematical psychology (Item Response Theory, Signal Detection Theory, calibration analysis, and cognitive-bias batteries) to artificial agents. Drawing on Levin's continuum view of cognition, it defines a multidimensional Machine Mindprint profile of latent dispositions (calibration, source integrity, suggestibility resistance, etc.) and a complementary Trust Protocol for deployment decisions. The philosophical contribution is a third stance, Artificial Mind Discipline, that avoids both Artificial Mind Blindness and Artificial Mind Projection without resolving consciousness questions.
Significance. If the core transferability assumption holds, the framework could supply a substrate-independent measurement layer for evaluating AI behavioral and metacognitive structure beyond capability benchmarks, with direct implications for high-stakes deployment protocols. As presented, however, the contribution is primarily conceptual framing rather than a validated method or falsifiable prediction.
major comments (2)
- [Abstract] Abstract: The central claim that IRT, SDT, and related methods developed for biological subjects can be applied directly to yield valid, substrate-independent profiles of metacognitive dispositions in artificial systems (e.g., transformers) is asserted without any derivation, adaptation, or measurement-invariance test showing that the same latent constructs are recovered when the generative mechanism is non-biological.
- [Machine Mindprint definition] Machine Mindprint definition (operational core): The listed constructs (calibration, suggestibility resistance, drift monitoring, etc.) are introduced by the proposal itself and defined in terms of the very measurement batteries that will be applied to them, with no independent external benchmarks or falsifiable predictions supplied to establish validity or avoid circularity.
minor comments (2)
- [Trust Protocol] The Trust Protocol section would benefit from an explicit example of how probe batteries and perturbation testing translate into a reliability/validity analysis for a concrete Mindprint dimension.
- Notation for the multidimensional, versioned profile is introduced but not formalized; a compact mathematical description or table of dimensions would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The manuscript is a conceptual proposal for Machine Psychometrics as a measurement framework rather than an empirical validation study; we address the two major comments below by clarifying scope and indicating targeted revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that IRT, SDT, and related methods developed for biological subjects can be applied directly to yield valid, substrate-independent profiles of metacognitive dispositions in artificial systems (e.g., transformers) is asserted without any derivation, adaptation, or measurement-invariance test showing that the same latent constructs are recovered when the generative mechanism is non-biological.
Authors: The manuscript does not claim that IRT, SDT, or related methods apply directly without adaptation or testing. It proposes their extension to artificial agents as a hypothesis grounded in Levin's continuum view of cognition, with the Machine Mindprint serving as the operational target. Sections on IRT and SDT applications sketch initial adaptations (e.g., item pools tailored to transformer response distributions), but we agree that explicit measurement-invariance arguments and empirical tests lie outside the current conceptual scope. We will revise the abstract to foreground the proposal status and the requirement for future invariance work. revision: partial
-
Referee: [Machine Mindprint definition] Machine Mindprint definition (operational core): The listed constructs (calibration, suggestibility resistance, drift monitoring, etc.) are introduced by the proposal itself and defined in terms of the very measurement batteries that will be applied to them, with no independent external benchmarks or falsifiable predictions supplied to establish validity or avoid circularity.
Authors: The constructs are operationalized through the batteries in the standard psychometric manner (cf. how 'working memory capacity' is defined via span tasks). Circularity is mitigated by the Trust Protocol's emphasis on external criteria: predictive validity against deployment outcomes, test-retest reliability across versions, and longitudinal drift detection. We will add a short subsection outlining falsifiable predictions (e.g., that high suggestibility-resistance scores on probe batteries will correlate with lower hallucination rates under adversarial prompting in held-out domains) and strategies for establishing convergent/discriminant validity with capability benchmarks. revision: yes
Circularity Check
No circularity: proposal introduces new framework using established external methods
full rationale
The paper proposes Machine Psychometrics and the Machine Mindprint as an operational measurement layer drawing on pre-existing tools (IRT, SDT, Bayesian modeling, calibration analysis) from mathematical psychology plus Levin's independently stated continuum view. No derivation chain is presented in which a claimed prediction or result is shown by the paper's own equations or self-citation to be identical to its inputs; the constructs are defined by reference to those external methods rather than being fitted or renamed within the paper itself. The Trust Protocol is described as the mechanism for future validation, leaving the central contribution as a definitional proposal rather than a self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cognition can be treated as goal-directed competency across biological and artificial substrates (Levin continuum view)
invented entities (1)
-
Machine Mindprint
no independent evidence
Forward citations
Cited by 1 Pith paper
-
RAILS: Verification-Native Clearing For Agentic Commerce
RAILS specifies a verification-native clearing protocol for agentic commerce built on seven primitives and a formal model that enforces a soundness property on evidence quality.
Reference graph
Works this paper leans on
-
[1]
(2021).Technological Approach to Mind Everywhere: An Experimentally-Grounded Framework for Understanding Diverse Bodies and Minds
Levin, M. (2021).Technological Approach to Mind Everywhere: An Experimentally-Grounded Framework for Understanding Diverse Bodies and Minds. Frontiers in Systems Neuroscience
2021
-
[2]
(2022).Competency in Navigating Arbitrary Spaces as an Invariant for Analyzing Cognition in Diverse Embodiments
Fields, C., & Levin, M. (2022).Competency in Navigating Arbitrary Spaces as an Invariant for Analyzing Cognition in Diverse Embodiments. Entropy
2022
-
[3]
M., Wagner, C., Rammstedt, B., & Strohmaier, M
Pellert, M., Lechner, C. M., Wagner, C., Rammstedt, B., & Strohmaier, M. (2024). AI Psychometrics: Assess- ing the Psychological Profiles of Large Language Models Through Psychometric Inventories.Perspectives on Psychological Science, 19, 808–826
2024
-
[4]
(2024).Evaluating Large Language Models with Psychometrics
Li, Y ., Huang, Y ., Wang, H., Zhang, X., Zou, J., & Sun, L. (2024).Evaluating Large Language Models with Psychometrics
2024
-
[5]
Chen, Y ., Li, X., Liu, J., & Ying, Z. (2021). Item Response Theory: A Statistical Framework for Educational and Psychological Measurement.Statistical Science
2021
-
[6]
(2025).Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
Zhou, H., et al. (2025).Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory. arXiv:2505.15055
-
[7]
(2025).Latency-Response Theory Model: Evaluating Large Language Models via Response Accuracy and Chain-of-Thought Length
Xu, Z., Liu, J., Wang, Y ., & Gu, Y . (2025).Latency-Response Theory Model: Evaluating Large Language Models via Response Accuracy and Chain-of-Thought Length
2025
-
[8]
Farquhar, S., Kossen, J., Kuhn, L., & Gal, Y . (2024). Detecting hallucinations in large language models using semantic entropy.Nature, 630, 625–630
2024
-
[9]
(2023).A Survey of Confidence Estimation and Calibration in Large Language Models
Geng, J., Cai, F., Wang, Y ., Koeppl, H., Nakov, P., & Gurevych, I. (2023).A Survey of Confidence Estimation and Calibration in Large Language Models
2023
-
[10]
Huang, L., et al. (2023). A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Transactions on Information Systems, 43, 1–55
2023
-
[11]
G., Gur, R., Moore, T., Patt, V ., Risbrough, V ., & Baker, D
Thomas, M., Brown, G. G., Gur, R., Moore, T., Patt, V ., Risbrough, V ., & Baker, D. (2018). A signal detection- item response theory model for evaluating neuropsychological measures.Journal of Clinical and Experimental Neuropsychology
2018
-
[12]
(2022).Capturing Failures of Large Language Models via Human Cognitive Biases
Jones, E., & Steinhardt, J. (2022).Capturing Failures of Large Language Models via Human Cognitive Biases. arXiv:2202.12299
-
[13]
(2024).Anchoring bias in large language models: an experimental study
Lou, J., & Sun, Y . (2024).Anchoring bias in large language models: an experimental study. arXiv
2024
-
[14]
Cheung, V ., Maier, M., & Lieder, F. (2025). Large language models show amplified cognitive biases in moral decision-making.Proceedings of the National Academy of Sciences
2025
-
[15]
(2022).Discovering Language Model Behaviors with Model-Written Evaluations
Perez, E., et al. (2022).Discovering Language Model Behaviors with Model-Written Evaluations
2022
-
[16]
(2025).TRUTH DECAY: Quantifying Multi-Turn Sycophancy in Language Models
Liu, J., Jain, A., Takuri, S., Vege, S., Akalin, A., Zhu, K., O’Brien, S., & Sharma, V . (2025).TRUTH DECAY: Quantifying Multi-Turn Sycophancy in Language Models. arXiv. 32 Machine Psychometrics
2025
-
[17]
(2024).Sycophancy in Large Language Models: Causes and Mitigations
Malmqvist, L. (2024).Sycophancy in Large Language Models: Causes and Mitigations. arXiv
2024
-
[18]
(2023).Do Large Language Models Know What They Don’t Know?arXiv:2305.18153
Yin, Z., Sun, Q., Guo, Q., Wu, J., Qiu, X., & Huang, X. (2023).Do Large Language Models Know What They Don’t Know?arXiv:2305.18153
-
[19]
Griot, M., Hemptinne, C., Vanderdonckt, J., & Yuksel, D. (2025). Large Language Models lack essential metacognition for reliable medical reasoning.Nature Communications
2025
-
[20]
Steyvers, M., & Peters, M. A. K. (2025).Metacognition and Uncertainty Communication in Humans and Large Language Models. arXiv
2025
-
[21]
(2025).Language Models Fail to Introspect About Their Knowledge of Language
Song, S., Hu, J., & Mahowald, K. (2025).Language Models Fail to Introspect About Their Knowledge of Language. arXiv
2025
-
[22]
Chang, Y .-C., et al. (2023). A Survey on Evaluation of Large Language Models.ACM Transactions on Intelligent Systems and Technology, 15, 1–45
2023
-
[23]
The Surprising Universality of LLM Outputs: A Real-Time Verification Primitive
Bogdan, A., & de Valois-Franklin, A. (2026).The Surprising Universality of LLM Outputs: A Real-Time Verification Primitive. arXiv:2604.25634
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Tam, T. Y . C., et al. (2024). A framework for human evaluation of large language models in healthcare derived from literature review.NPJ Digital Medicine, 7
2024
-
[25]
O., Shuaibu, A
Adabara, I., Sadiq, B. O., Shuaibu, A. N., Danjuma, Y . I., & Maninti, V . (2025). Trustworthy agentic AI systems: a cross-layer review of architectures, threat models, and governance strategies for real-world deployment. F1000Research
2025
-
[26]
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
Butlin, P., et al. (2023).Consciousness in Artificial Intelligence: Insights from the Science of Consciousness. arXiv:2308.08708
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Bayne, T., et al. (2024). Tests for consciousness in humans and beyond.Trends in Cognitive Sciences
2024
-
[28]
(2026).Respectful Skepticism About Strong Impossibility Claims in The Abstraction Fallacy
Bogdan, A. (2026).Respectful Skepticism About Strong Impossibility Claims in The Abstraction Fallacy. Phi- lArchive: BOGHDI-2. https://philarchive.org/rec/BOGHDI-2 Appendix A: Glossary of Core Terms 9.1 Foundational stances Artificial Mind Blindness.The methodological error of denying psychological structure in artificial systems because their substrate i...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.