FalAR: A Large-scale Speaker-Annotated European Portuguese Speech Corpus of Parliamentary Sessions
Pith reviewed 2026-06-29 18:05 UTC · model grok-4.3
The pith
A new 5800-hour European Portuguese speech corpus from parliamentary sessions improves ASR word error rates by up to 14 percent when used for pre-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
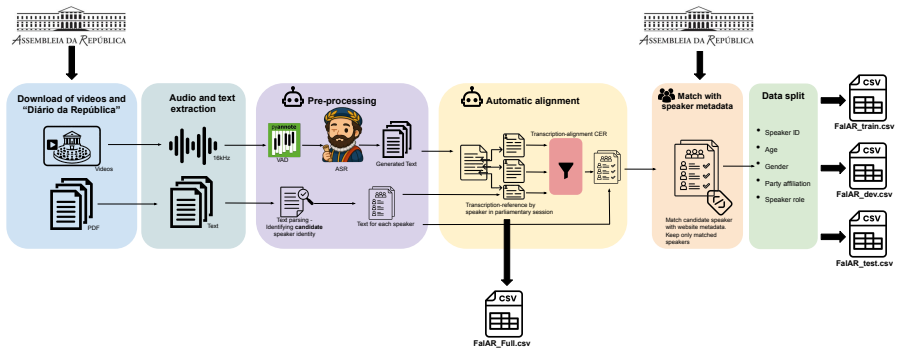
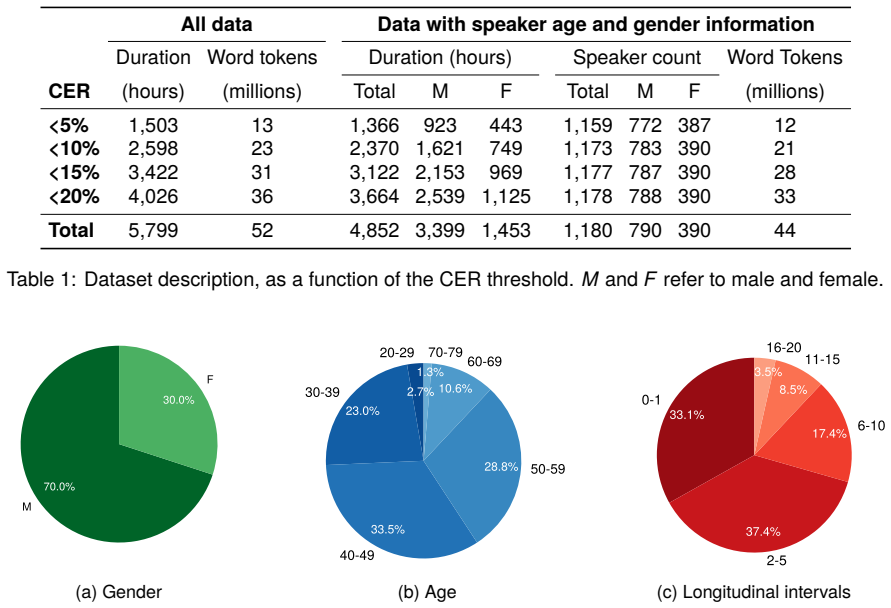
The authors present FalAR as a 5800-hour speaker-annotated corpus of European Portuguese parliamentary speech spanning approximately 20 years, with 4850 hours carrying identity metadata for 1180 speakers. The corpus is constructed by using a state-of-the-art EP CAMÕES ASR model to produce reference transcriptions for alignment. When FalAR is added as pre-training data, ASR models achieve up to 14 percent relative WER improvement over baselines that do not use it.
What carries the argument
The FalAR corpus itself, assembled through automatic transcription-reference alignment of parliamentary audio, functions as large-scale pre-training material that directly improves downstream ASR accuracy on European Portuguese.
If this is right
- ASR systems trained with FalAR data perform better on European Portuguese speech than those trained only on existing resources.
- Speaker metadata in the corpus supports experiments that separate performance by age, gender, or political role.
- Increasing the amount of aligned data from the corpus improves both alignment quality and final model accuracy.
- The parliamentary-domain recordings provide a consistent acoustic and linguistic setting for studying long-form speech recognition.
Where Pith is reading between the lines
- FalAR could be combined with Brazilian Portuguese corpora to study cross-variety transfer in ASR.
- The speaker annotations open the possibility of building models that adapt to individual parliamentary speakers or demographic groups.
- Similar collection pipelines could be applied to other languages that maintain public parliamentary recordings but lack large speech datasets.
- The 20-year span may allow studies of language change or diachronic shifts in parliamentary speech.
Load-bearing premise
The automatic transcriptions from the existing CAMÕES ASR model are accurate enough to support reliable alignment and useful model training.
What would settle it
Human verification on a random sample of the aligned transcriptions showing high word error rates, or new ASR models trained on FalAR failing to produce measurable WER gains on independent European Portuguese test sets.
Figures
read the original abstract
State-of-the-art performance for Automatic Speech Recognition (ASR) largely depends on the availability of large-scale labeled corpora. This creates a demand for increased data collection efforts, particularly for under-represented languages and dialectal varieties. Due to having considerably fewer speakers (around 11 million), European Portuguese (EP) is overshadowed by Brazilian Portuguese (BP) (around 200 million speakers) in currently available large-scale speech data resources, resulting in under-performing speech-based systems for EP users. To address this gap, and following similar data collection efforts for other languages, we present FalAR, a large-scale, speaker-annotated speech corpus of European Portuguese parliamentary sessions. Spanning approximately 20 years, FalAR comprises 5,800 hours of speech data. In addition, 4,850 hours have speaker identity annotations, for a total of 1,180 speakers with associated metadata including age, gender, political affiliation, and parliamentary role. The corpus was built using a state-of-the-art EP CAM\~OES ASR model for transcription-reference alignment. In this paper, we describe the data collection process, together with the main characteristics of the FalAR corpus. Furthermore, we evaluate the trade-off between data quantity and alignment accuracy on ASR performance, with our experiments demonstrating that incorporating FalAR as pre-training data yields up to 14% relative WER improvement over baseline models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FalAR, a 5,800-hour speaker-annotated European Portuguese speech corpus drawn from 20 years of parliamentary sessions. It describes corpus construction via the CAMÕES ASR model for transcription-reference alignment, supplies speaker metadata (age, gender, affiliation, role) for 1,180 speakers across 4,850 hours, and reports ASR experiments in which pre-training on FalAR yields up to 14% relative WER improvement over baselines.
Significance. If the automatic alignments prove reliable, FalAR would constitute a substantial new resource for an under-resourced language variety, enabling both scale and speaker-conditioned modeling that current EP corpora lack. The empirical WER gains, if reproducible with full experimental controls, would directly demonstrate the corpus's downstream utility.
major comments (2)
- [§4] §4 (ASR experiments): the reported 'up to 14% relative WER improvement' is presented without baseline model specifications, training/validation/test splits, or error bars, preventing assessment of whether the gain is robust or attributable to the new data.
- [§3.2] §3.2 (alignment procedure): no WER, CER, or alignment-error figures are supplied for the CAMÕES model on any human-annotated subset of FalAR, leaving the central assumption that the pseudo-labels are sufficiently accurate for both corpus construction and pre-training untested.
minor comments (2)
- [Introduction] The abstract and introduction could more explicitly contrast FalAR with existing EP resources (e.g., size, speaker coverage, domain).
- [§3] Speaker metadata statistics (distribution of age/gender/affiliation) would benefit from a dedicated table or figure for quick reference.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and commit to revisions that strengthen the manuscript's clarity and reproducibility.
read point-by-point responses
-
Referee: [§4] §4 (ASR experiments): the reported 'up to 14% relative WER improvement' is presented without baseline model specifications, training/validation/test splits, or error bars, preventing assessment of whether the gain is robust or attributable to the new data.
Authors: We agree that the experimental details are insufficient for full reproducibility and assessment. The revised manuscript will specify the baseline model architectures and hyperparameters, explicitly describe the train/validation/test splits (including how FalAR data was partitioned), and report error bars or results across multiple random seeds to quantify variability in the observed WER gains. revision: yes
-
Referee: [§3.2] §3.2 (alignment procedure): no WER, CER, or alignment-error figures are supplied for the CAMÕES model on any human-annotated subset of FalAR, leaving the central assumption that the pseudo-labels are sufficiently accurate for both corpus construction and pre-training untested.
Authors: The current version does not include quantitative alignment error metrics on a human-annotated subset. We will add a dedicated evaluation subsection reporting WER and CER of the CAMÕES model on any available human-annotated parliamentary data (or a newly annotated sample if feasible), along with a discussion of how alignment quality affects downstream pre-training utility. revision: yes
Circularity Check
Empirical ASR improvement measured on held-out data; no derivation reduces to inputs
full rationale
The paper's central claim is an empirical measurement: pre-training on FalAR yields up to 14% relative WER improvement over baselines. This is obtained by training ASR models on the new corpus (built via CAMÕES alignment) and evaluating WER on separate test sets. No equations, fitted parameters, or self-citations are invoked to derive the gain; the result is a direct experimental outcome rather than a quantity forced by the corpus construction. The CAMÕES labeling step is a data-generation choice whose quality is assumed but not part of any closed derivation loop within the paper. The reported trade-off experiments between quantity and alignment accuracy are likewise empirical comparisons, not self-referential reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
FalAR: A Large-scale Speaker-Annotated European Portuguese Speech Corpus of Parliamentary Sessions
Introduction Recent advances in Automatic Speech Recogni- tion (ASR) have been driven by a combination of architectural innovations (Dong et al., 2018; Karita et al., 2019; Gulati et al., 2020; Kim et al., 2023; Rekesh et al., 2023), increased computa- tional power, and the growing availability of large- scale labeled speech corpora (Chan et al., 2021; Ra...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Related Work The development of speech resources for EP has always been closely linked to the development of EP ASR systems, as evidenced by early exam- ples of data collection efforts for EP speech tech- nologies. For instance, BD-PUBLICO (Neto et al., 1997), a corpus of 25 hours of read newspaper articles was collected to be used as the training data of...
1997
-
[3]
for the development of speech-based tech- nologies. Likewise, ALERT (Trancoso et al., 2003), a broadcast news corpus comprising 74 hours of speech, was collected for and used to train the hybrid HMM/DNN AUDIMUS system, developed to automatically transcribe broadcast news in EP (Meinedo et al., 2001; Neto et al., 2008). As ASR architectures became more dat...
2003
-
[4]
In addition, there is a growing number of speech corpora compiled from parliamentary data
and ParlaMint-PT (Aires et al., 2024), with transcriptions of debates spanning 1976 to 2019 and 2005 to 2019, respectively. In addition, there is a growing number of speech corpora compiled from parliamentary data. These include large-scale corpora, such as Europarl-ASR (GarcésDíaz-Muníoetal.,2021)forEnglishaswell as corpora for under-represented language...
2024
-
[5]
Diário da República
FalAR The main objective of this work is to build a large- scale speech corpus for EP, leveraging the publicly available video recordings of Portuguese parlia- mentary meetings and corresponding manual tran- scriptions. To achieve this, we collected the recordings, ex- tracted and segmented the audio signals, and gen- erated automatic transcriptions. Thes...
2005
-
[6]
Data To assess the impact of the proposed corpus on the performance of ASR models for European Por- tuguese, we conduct a series of experiments using different data configurations
Experimental Setup 4.1. Data To assess the impact of the proposed corpus on the performance of ASR models for European Por- tuguese, we conduct a series of experiments using different data configurations. First, to determine the impact that different align- ment error rates have in downstream ASR sys- tems, we prepare five subsets of FalAR to train corres...
2025
-
[7]
An ASR model was ad- ditionally trained using solely CAMÕES, to provide a baseline with which to compare the FalAR-based models to
is 425 hours-long, whereas the test set is 46 hours-long, both comprising five domains, namely, read speech (RS), broadcast news (BN), talks and lectures (T/L), conversational speech (CS), and so- ciolinguistic interviews (SI). An ASR model was ad- ditionally trained using solely CAMÕES, to provide a baseline with which to compare the FalAR-based models t...
-
[8]
More specifically, we followed the LibriSpeech 960 (Panayotov et al., 2015) recipe in ESPnet for training, decoding, and evaluation
for the core implementation and evaluation of our work. More specifically, we followed the LibriSpeech 960 (Panayotov et al., 2015) recipe in ESPnet for training, decoding, and evaluation. All evaluated ASR models correspond to an E- Branchformer(Kimetal.,2023)with144Mtrainable parameters, using 8x downsampling (Rekesh et al.,
2015
-
[9]
Themodel’s encodercomprises17layers, whereasthedecoder isa6-layerTransformer,bothadaptedfromtheorig- inal recipe
and Flash Attention (Dao et al., 2022) to im- provetrainingandinferenceefficiency. Themodel’s encodercomprises17layers, whereasthedecoder isa6-layerTransformer,bothadaptedfromtheorig- inal recipe. For the encoder module, we applied Rotary Positional Embeddings (RoPE) (Su et al., 2024). We also adopted a piecewise-linear learn- ing rate schedule (Peng et a...
2022
-
[10]
In-domain performance Table2presentsthein-domainresultsfortheFalAR test set together with the out-of-domain perfor- mance on the CAMÕES benchmark, evaluated across its five domains
Results 5.1. In-domain performance Table2presentsthein-domainresultsfortheFalAR test set together with the out-of-domain perfor- mance on the CAMÕES benchmark, evaluated across its five domains. For the FalAR test set, we observe that per- formance generally improves as the training data size increases, with the largest gain and best overall performance o...
-
[11]
Conclusions This work introduces FalAR, to the best of our knowledge, the largest publicly available annotated European Portuguese speech corpus, totalling 5,800 hours of parliamentary speech data. Our results show that using FalAR as pre-training data followed by in-domain fine-tuning improves ASR performance across all domains of the CAMÕES benchmark wh...
2005
-
[12]
Ethical considerations and limitations The source data that we curated and analysed to compileFalARwasobtainedfrompubliclyavailable open data resources (see Section 3.1). In releasing the accompanying metadata, we deliberately omit personally identifiable informa- tion such as speaker names and dates of birth, and instead provide anonymised speaker identi...
-
[13]
(FCT) under projects UID/50021/2025 (DOI: https://doi.org/10.54499/UID/50021/
Acknowledgements Work supported by Portuguese national funds through Fundação para a Ciência e a Tecnologia, I.P. (FCT) under projects UID/50021/2025 (DOI: https://doi.org/10.54499/UID/50021/
-
[14]
and UID/PRR/50021/2025 (DOI:https:// doi.org/10.54499/UID/PRR/50021/2025) and by the Portuguese Recovery and Resilience Plan and NextGenerationEU European Union funds under project C644865762-00000008 (ACCELERAT.AI)
-
[15]
Céu Viana
Bibliographical References Alberto Abad, Isabel Trancoso, Nelson Neto, and M. Céu Viana. 2009. Porting an european por- tuguese broadcast news recognition system to brazilianportuguese. InInterspeech 2009,pages 92–95. José Aires, Aida Cardoso, Rui Pereira, and Amália Mendes. 2024. Compiling and exploring a Por- tuguese parliamentary corpus: ParlaMint-PT. ...
2009
-
[16]
MuAViC: A Multilingual Audio-Visual Cor- pus for Robust Speech Recognition and Robust Speech-to-Text Translation. InProc. Interspeech, pages 4064–4068. Rosana Ardila, Megan Branson, Kelly Davis, Michael Kohler, Josh Meyer, Michael Henretty, Reuben Morais, Lindsay Saunders, Francis Ty- ers, andGregorWeber.2020. CommonVoice: A Massively-Multilingual Speech ...
-
[17]
MOSEL: 950,000 hours of speech data for open-source speech foundation model train- ing on EU languages. InProc. EMNLP, pages 13934–13947, Miami, Florida, USA. Association for Computational Linguistics. Gonçal Garcés Díaz-Munío, Joan Albert Sil- vestre Cerdà, Javier Jorge-Cano, Adrián Giménez Pastor, Javier Iranzo-Sánchez, Pau Baquero-Arnal, Nahuel Roselló...
2021
-
[18]
A comparative study on transformer vs RNN in speech applications. InProc. ASRU. Kwangyoun Kim, Felix Wu, Yifan Peng, Jing Pan, Prashant Sridhar, Kyu J. Han, and Shinji Watan- abe. 2023. E-Branchformer: Branchformer with enhanced merging for speech recognition. In Proc. SL T. Andreas Kirkedal, Marija Stepanović, and Barbara Plank. 2020. FT Speech: Danish p...
2023
-
[19]
InInternational Con- ference on Speech and Computer, pages 137–
The parlaspeech collection of automati- cally generated speech and text datasets from parliamentary proceedings. InInternational Con- ference on Speech and Computer, pages 137–
-
[20]
MariaHelenaMateusandErnestod’Andrade.2000
Springer. MariaHelenaMateusandErnestod’Andrade.2000. The Phonology Of Portuguese. OxfordUniversity Press. Hugo Meinedo, Nuno. Souto, and João P. Neto
2000
-
[21]
Speech recognition of broadcast news for the European Portuguese language. InProc. ASRU, pages 319–322. Abdelrahman Mohamed, Hung-yi Lee, Lasse Borgholt, Jakob D. Havtorn, Joakim Edin, Chris- tian Igel, Katrin Kirchhoff, Shang-Wen Li, Karen Livescu,LarsMaaløe,TaraN.Sainath,andShinji Watanabe. 2022. Self-supervised speech repre- sentation learning: A revie...
2022
-
[22]
In5th International Conference on Spo- ken Language Processing (ICSLP 1998), page paper 0562
A large vocabulary continuous speech recognition hybrid system for the portuguese lan- guage. In5th International Conference on Spo- ken Language Processing (ICSLP 1998), page paper 0562. João P. Neto, Ciro Martins, Hugo Meinedo, and Luis B Almeida. 1997. The design of a large vocabulary speech corpus for Portuguese. In Proc. Eurospeech, pages 1707–1710. ...
1998
-
[23]
Robust speech recognition via large-scale weak supervision. InProc. ICML. DimaRekesh, NithinRaoKoluguri, SamuelKriman, SomshubraMajumdar,VahidNoroozi,HeHuang, OleksiiHrinchuk,KrishnaPuvvada,AnkurKumar, Jagadeesh Balam, and Boris Ginsburg. 2023. Fast conformer with linearly scalable attention for efficient speech recognition. InProc. ASRU, pages 1–8. Jean-...
2023
-
[24]
Google USM: Scaling Au- tomatic Speech Recognition Beyond 100 Languages,
Identification of common molecular subsequences.Journal of Molecular Biology, 147(1):195–197. Per Erik Solberg and Pablo Ortiz. 2022. The Nor- wegian parliamentary speech corpus. InProc. LREC, pages 1003–1008, Marseille, France. Eu- ropean Language Resources Association. Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. RoFo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.