A Conflict-Aware Penalty and Statistical Loss Framework for Balancing Modalities and Enhancing Stability in Multimodal Sentiment Analysis
Pith reviewed 2026-06-29 11:57 UTC · model grok-4.3
The pith
Penalizing gradient norm conflicts at each step balances text, acoustic, and visual contributions in multimodal sentiment analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Conflict-aware Penalty (CP) detects and penalizes gradient norm conflicts at each training step to prevent the dominant text modality from suppressing acoustic and visual signals and from interfering with the Statistical Loss (SL) objective that aligns predicted distribution statistics with empirical input statistics; when embedded in a unified framework that also uses adaptive modality encoding, gated cross-modal fusion, and unimodal auxiliary heads, this produces balanced, stable optimization that yields state-of-the-art results on CMU-MOSI with ablation studies confirming each component's contribution.
What carries the argument
The Conflict-aware Penalty (CP), a per-step mechanism that identifies and penalizes gradient norm conflicts arising between modalities during backpropagation.
If this is right
- The three modalities contribute more equally to the final sentiment prediction.
- The statistical alignment objective can optimize without repeated interference from stronger modality gradients.
- Overall training exhibits fewer destabilizing oscillations caused by conflicting gradient magnitudes.
- Unimodal auxiliary heads supply additional learning signals that reinforce the balanced multimodal representation.
- Performance exceeds prior multimodal sentiment models on the CMU-MOSI benchmark.
Where Pith is reading between the lines
- The same per-step penalty might reduce the need for hand-tuned modality weights in other fusion architectures.
- If the mechanism works on CMU-MOSI it could be tested on datasets where visual or acoustic encoders are stronger than text to check symmetry of the effect.
- The approach leaves open whether similar conflict detection could be applied inside the fusion layer itself rather than only at the gradient level.
Load-bearing premise
That gradient norm conflicts are the dominant cause of text suppression and that penalizing them at each training step will produce balanced, stable optimization without requiring changes to the underlying encoders or loss landscape.
What would settle it
An ablation on CMU-MOSI in which the conflict-aware penalty and statistical loss are added yet gradient norms remain imbalanced across modalities or final accuracy shows no gain over the baseline without these terms.
Figures
read the original abstract
Multimodal Sentiment Analysis (MSA) fuses text, acoustic, and visual streams to infer sentiment. Because pre-trained text encoders are far more expressive than their acoustic and visual counterparts, the text modality tends to dominate optimization, suppressing weaker modalities and inducing gradient norm conflicts that destabilize training. To address this, we propose a Conflict-aware Penalty (CP) that detects and penalizes gradient norm conflicts at each training step, and a Statistical Loss (SL) that aligns predicted distribution statistics with empirical input statistics. Crucially, CP prevents dominant modality gradients from interfering with the SL objective, enabling synergistic training within a unified framework incorporating adaptive modality encoding, gated cross-modal fusion, and unimodal auxiliary heads. Experiments on CMU-MOSI demonstrate state-of-the-art performance, with ablation studies confirming the effectiveness of each component.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Conflict-Aware Penalty (CP) to detect and penalize gradient-norm conflicts between modalities during training and a Statistical Loss (SL) to align predicted distribution statistics with empirical input statistics in multimodal sentiment analysis. The overall framework combines these with adaptive modality encoding, gated cross-modal fusion, and unimodal auxiliary heads. It claims state-of-the-art performance on CMU-MOSI, supported by ablation studies that confirm the contribution of each component.
Significance. If the performance gains are shown to arise specifically from the conflict-penalization and statistical-alignment mechanisms rather than from the auxiliary architectural elements, the approach could supply a lightweight, training-time method for stabilizing optimization when one modality (typically text) dominates. The hypothesis that gradient-norm conflicts are a primary driver of modality suppression is plausible and, if validated with intermediate diagnostics, would add a useful diagnostic lens to multimodal training literature.
major comments (3)
- [Abstract] Abstract: the central claim that 'Experiments on CMU-MOSI demonstrate state-of-the-art performance, with ablation studies confirming the effectiveness of each component' is presented without any reported metrics, baselines, error bars, dataset statistics, or ablation tables, leaving the experimental outcome unevaluated.
- [Framework description] Framework description (abstract and § on CP/SL): no equation or algorithmic definition is supplied for the Conflict-aware Penalty, nor are any per-modality gradient-norm trajectories, conflict statistics, or before/after dominance ratios reported; without these diagnostics the attribution of gains to CP rather than to gated fusion or auxiliary heads remains untested.
- [Ablation studies] Ablation studies: the assertion that ablations confirm each component is made without presenting the corresponding performance deltas, tables, or controls that isolate CP from SL and from the rest of the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the manuscript's presentation of results and technical details can be strengthened. We will revise the paper to address these points by adding the requested metrics, equations, diagnostics, and ablation tables.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments on CMU-MOSI demonstrate state-of-the-art performance, with ablation studies confirming the effectiveness of each component' is presented without any reported metrics, baselines, error bars, dataset statistics, or ablation tables, leaving the experimental outcome unevaluated.
Authors: We agree that the abstract should provide concrete numerical support for the claims. In the revision, we will expand the abstract to report key metrics (MAE, Pearson correlation, accuracy) on CMU-MOSI, list the main baselines, note error bars or variance across runs, and briefly mention dataset statistics along with a high-level reference to the ablation outcomes. revision: yes
-
Referee: [Framework description] Framework description (abstract and § on CP/SL): no equation or algorithmic definition is supplied for the Conflict-aware Penalty, nor are any per-modality gradient-norm trajectories, conflict statistics, or before/after dominance ratios reported; without these diagnostics the attribution of gains to CP rather than to gated fusion or auxiliary heads remains untested.
Authors: We acknowledge the need for explicit definitions and supporting diagnostics. The revised manuscript will include the mathematical formulation and algorithmic steps for the Conflict-aware Penalty. We will also add figures or tables displaying per-modality gradient-norm trajectories, conflict statistics, and before/after dominance ratios to help attribute gains specifically to CP. revision: yes
-
Referee: [Ablation studies] Ablation studies: the assertion that ablations confirm each component is made without presenting the corresponding performance deltas, tables, or controls that isolate CP from SL and from the rest of the architecture.
Authors: We will strengthen the ablation section by including full tables with performance deltas for each component (CP, SL, gated fusion, auxiliary heads). These will incorporate controls that isolate CP and SL from the other architectural elements, allowing readers to evaluate their individual contributions. revision: yes
Circularity Check
No circularity; empirical framework with no derivation chain
full rationale
The paper proposes CP and SL components within a multimodal framework and validates them via experiments and ablations on CMU-MOSI, presenting performance as an experimental outcome rather than any derived prediction. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the provided text or abstract. The central claims rest on empirical results and component ablations, which are independent of the method itself and do not reduce to inputs by construction. This is a standard empirical contribution with no detectable circularity in any derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Multimodal Sentiment Analysis (MSA) aims to infer hu- man sentiment by jointly modeling text, acoustic, and visual streams [1, 2]. Pre-trained language models such as BERT [3] and DeBERTa [4] have dramatically raised the ceiling for text- based understanding, and a wave of fusion architectures— ranging from tensor-based methods [5, 6] and cro...
-
[2]
and, by keeping gradient pressure balanced, prevents the dominant modality from destabilising the SL objective (Chal- lenge 2). We build CP into a unified multimodal framework that also incorporates Adaptive Modality Encoding (AME) with reparameterisation [15], gated cross-modal fusion [16], uni- modal auxiliary heads [17], and reconstruction regularisati...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
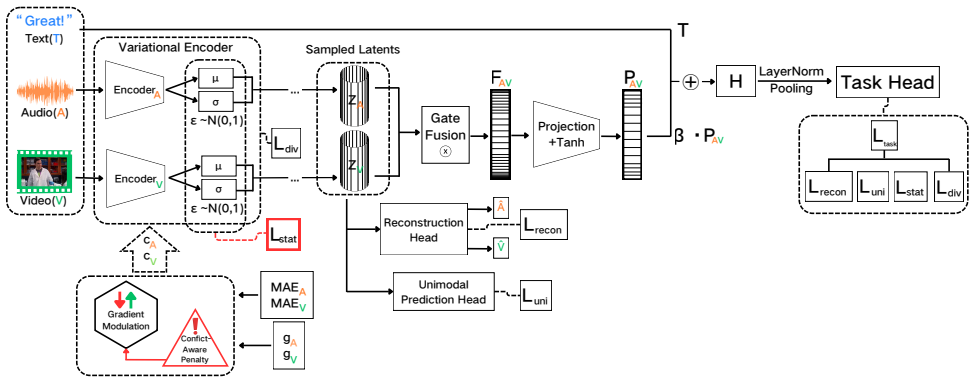
Method We design a multimodal fusion model (Fig. 1) that processes text, acoustic, and visual inputs through the following pipeline: (i) adaptive modality encoding with reparameterization, (ii) gated cross-modal fusion with residual injection into the text backbone, (iii) final prediction via a task head, and (iv) auxiliary supervision via reconstruction ...
-
[4]
The feature diversity lossL div encourages maximizing information entropy to avoid redundant representations. The overall objective is: L=L task +λ reconLrecon +λ uniLuni +λ divLdiv +λ statLstat,(4) whereL recon = 1 2 ∥A− ˆA∥2 2 +∥V− ˆV∥2 2 andL uni aggre- gates the sentiment regression losses from the unimodal heads of each modality. Step 4: Gradient Mod...
-
[5]
G r e a t !
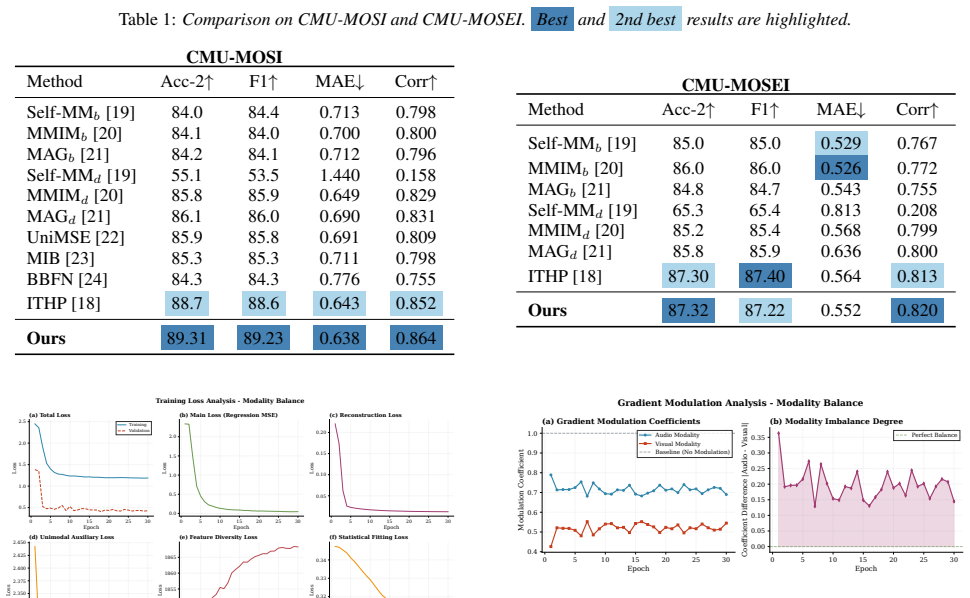
Experiments 3.1. Settings We evaluate on CMU-MOSI [1] and CMU-MOSEI [2]. CMU- MOSI comprises 2,199 opinion video clips annotated with sen- timent intensity on a continuous[−3,3]scale, covering aligned text, acoustic, and visual streams. CMU-MOSEI is a larger benchmark of 23,500 sentence-level utterances from over 1,000 YouTube speakers across 250 topics, ...
-
[6]
CP mitigates gradient norm conflicts to balance modality optimization, while SL regular- izes training by aligning distribution statistics
Conclusion In this paper, we address modality imbalance and optimiza- tion instability in MSA by introducing a Conflict-aware Penalty (CP) and Statistical Loss (SL). CP mitigates gradient norm conflicts to balance modality optimization, while SL regular- izes training by aligning distribution statistics. Experiments on CMU-MOSI demonstrate state-of-the-ar...
-
[7]
All research ideas, experimental designs, pro- posed methods, data analysis, and conclusions were indepen- dently conceived and completed by the authors
Generative AI Use Disclosure In the preparation of this manuscript, the authors used gener- ative AI tools (e.g., large language models) solely for the pur- pose of refining the language and improving the fluency of cer- tain sentences. All research ideas, experimental designs, pro- posed methods, data analysis, and conclusions were indepen- dently concei...
-
[8]
MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos
A. Zadeh, R. Zellers, E. Pincus, and L.-P. Morency, “MOSI: Mul- timodal corpus of sentiment intensity and subjectivity analysis in online opinion videos,”arXiv preprint arXiv:1606.06259, 2016, arXiv:1606.06259
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph,
A. B. Zadeh, P. P. Liang, S. Poria, E. Cambria, and L.-P. Morency, “Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph,” inProceedings of the 56th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers). Association for Computa- tional Linguistics, 2018, pp. 2236–2246
2018
-
[10]
BERT: Pre- training of deep bidirectional transformers for language under- standing,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language under- standing,” inProceedings of NAACL-HLT, 2019, pp. 4171–4186
2019
-
[11]
DeBERTa: Decoding- enhanced BERT with disentangled attention,
P. He, X. Liu, J. Gao, and W. Chen, “DeBERTa: Decoding- enhanced BERT with disentangled attention,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[12]
Tensor Fusion Network for Multimodal Sentiment Analysis
A. Zadeh, M. Chen, S. Poria, E. Cambria, and L.-P. Morency, “Tensor fusion network for multimodal sentiment analysis,” in Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2017, pp. 1103–1114, arXiv:1707.07250
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Efficient Low-rank Multimodal Fusion with Modality-Specific Factors
Z. Liu, Y . Shen, V . B. Lakshminarasimhan, P. P. Liang, A. Zadeh, and L.-P. Morency, “Efficient low-rank multimodal fusion with modality-specific factors,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers). Association for Computational Linguis- tics, 2018, pp. 2247–2256, arXiv:1806.00064
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Multimodal Transformer for Unaligned Multimodal Language Sequences
Y .-H. H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L.-P. Morency, and R. Salakhutdinov, “Multimodal transformer for unaligned multi- modal language sequences,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. As- sociation for Computational Linguistics, 2019, pp. 6558–6569, arXiv:1906.00295
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Contrastive feature decomposition for multimodal sentiment analysis,
J. Yang, Y . Yu, D. Niu, W. Guo, and Y . Xu, “Contrastive feature decomposition for multimodal sentiment analysis,” inProceed- ings of the 61st Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2023, pp. 7617–7630
2023
-
[16]
A hybrid distributed cgan for audio-visual privacy preservation in multi- modal sentiment analysis,
Z. Wu, Q. Zhang, D. Miao, K. Yi, W. Fan, and L. Hu, “A hybrid distributed cgan for audio-visual privacy preservation in multi- modal sentiment analysis,” inProceedings of the Thirty-Third In- ternational Joint Conference on Artificial Intelligence, 2024, pp. 6550–6558, arXiv:2404.11938
-
[17]
Modality competition: What makes joint training of multi-modal network fail in deep learning ? (Provably),
Y . Huang, J. Lin, C. Zhou, H. Yang, and L. Huang, “Modality competition: What makes joint training of multi-modal network fail in deep learning ? (Provably),” inProceedings of the 39th In- ternational Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 162. PMLR, 2022, pp. 9226– 9259
2022
-
[18]
What makes training multi- modal classification networks hard ?
W. Wang, D. Tran, and M. Feiszli, “What makes training multi- modal classification networks hard ?” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2020, pp. 12 695–12 705
2020
-
[19]
Balanced mul- timodal learning via on-the-fly gradient modulation,
X. Peng, Y . Wei, A. Deng, D. Wang, and D. Hu, “Balanced mul- timodal learning via on-the-fly gradient modulation,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, 2022, pp. 8228–8237
2022
-
[20]
On-the-fly modulation for balanced multimodal learning,
Y . Wei, D. Hu, H. Du, and J.-R. Wen, “On-the-fly modulation for balanced multimodal learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, arXiv:2410.11582
-
[21]
Deep CORAL: Correlation alignment for deep domain adaptation,
B. Sun and K. Saenko, “Deep CORAL: Correlation alignment for deep domain adaptation,” inEuropean Conference on Computer Vision Workshops (ECCVW), 2016, pp. 443–450
2016
-
[22]
Auto-encoding variational Bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” inInternational Conference on Learning Representations (ICLR), 2014
2014
-
[23]
Gated multimodal units for information fusion,
J. Arevalo, T. Solorio, M. Montes-y G ´omez, and F. A. Gonz´alez, “Gated multimodal units for information fusion,” inInternational Conference on Learning Representations Workshop (ICLR-W), 2017
2017
-
[24]
Learning modality-specific representations with self-supervised multi-task learning for multi- modal sentiment analysis,
W. Yu, H. Xu, Z. Yuan, and J. Wu, “Learning modality-specific representations with self-supervised multi-task learning for multi- modal sentiment analysis,” inProceedings of the 35th AAAI Con- ference on Artificial Intelligence. AAAI Press, 2021, pp. 10 790– 10 797
2021
-
[25]
Neuro-inspired information-theoretic hierarchical perception for multimodal learning,
X. Xiao, G. Liu, G. Gupta, D. Cao, S. Li, Y . Li, T. Fang, M. Cheng, and P. Bogdan, “Neuro-inspired information-theoretic hierarchical perception for multimodal learning,” 2024. [Online]. Available: https://arxiv.org/abs/2404.09403
-
[26]
Learning modality-specific representations with self-supervised multi-task learning for mul- timodal sentiment analysis,
W. Yu, H. Xu, Z. Yuan, and J. Wu, “Learning modality-specific representations with self-supervised multi-task learning for mul- timodal sentiment analysis,” inProceedings of the AAAI Confer- ence on Artificial Intelligence, 2021
2021
-
[27]
Improving multimodal fusion with hierarchical mutual information maximization for multi- modal sentiment analysis,
W. Han, H. Chen, and S. Poria, “Improving multimodal fusion with hierarchical mutual information maximization for multi- modal sentiment analysis,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 9180–9192
2021
-
[28]
Integrating multimodal information in large pretrained transformers,
W. Rahman, M. K. Hasan, S. Lee, A. Zadeh, C. Mao, L.-P. Morency, and E. Hoque, “Integrating multimodal information in large pretrained transformers,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 2359–2369
2020
-
[29]
UniMSE: To- wards unified multimodal sentiment analysis and emotion recog- nition,
G. Hu, T.-E. Lin, Y . Zhao, G. Lu, Y . Wu, and Y . Li, “UniMSE: To- wards unified multimodal sentiment analysis and emotion recog- nition,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Com- putational Linguistics, 2022, pp. 7837–7851, arXiv:2211.11256
-
[30]
Multimodal information bottleneck: Learning minimal sufficient unimodal and multimodal represen- tations,
S. Mai, H. Hu, and S. Xing, “Multimodal information bottleneck: Learning minimal sufficient unimodal and multimodal represen- tations,”IEEE Transactions on Multimedia, 2022
2022
-
[31]
Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis,
W. Han, H. Chen, A. Gelbukh, A. Zadeh, L.-P. Morency, and S. Poria, “Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis,” inProceedings of the 2021 Inter- national Conference on Multimodal Interaction, 2021, pp. 6–15
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.