Delayed Repression and Emergent Instability in Adaptive Multi-Agent Systems
Pith reviewed 2026-06-29 00:12 UTC · model grok-4.3
The pith
Institutional processing delays alone can destabilize otherwise stable multi-agent systems through a supercritical Hopf bifurcation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
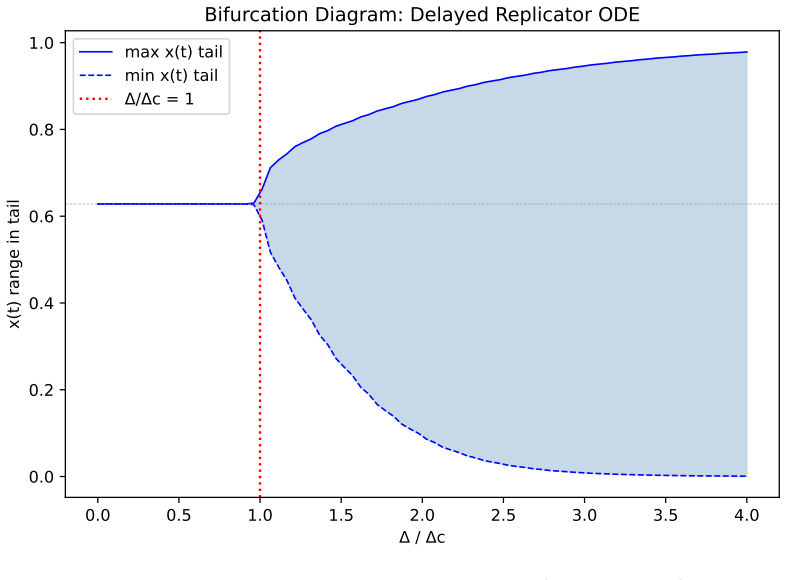
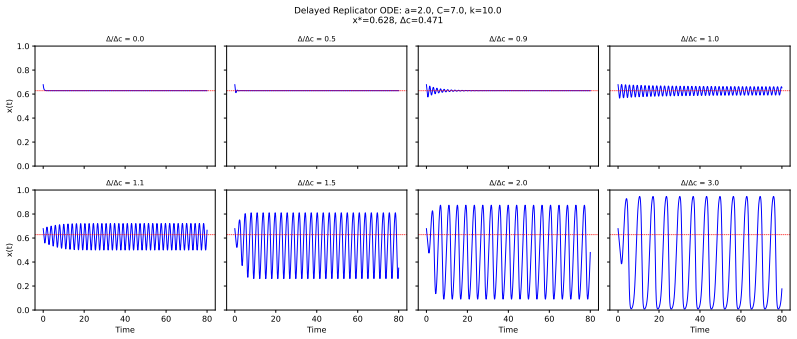
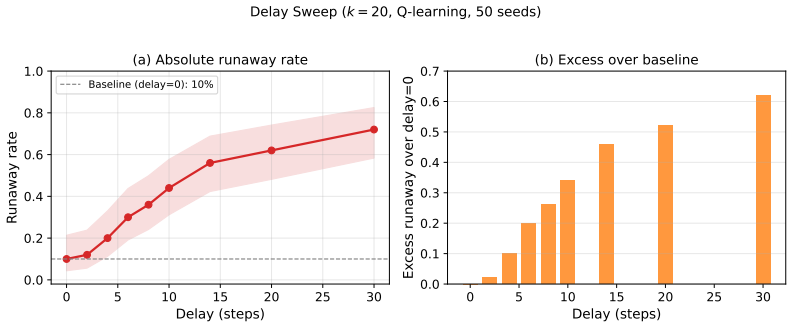
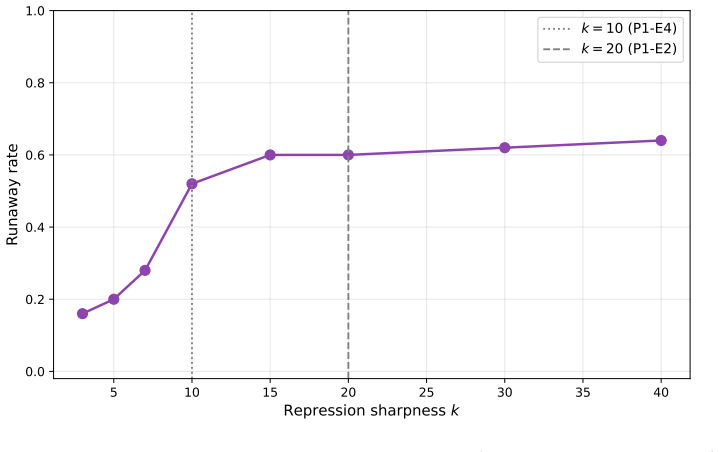
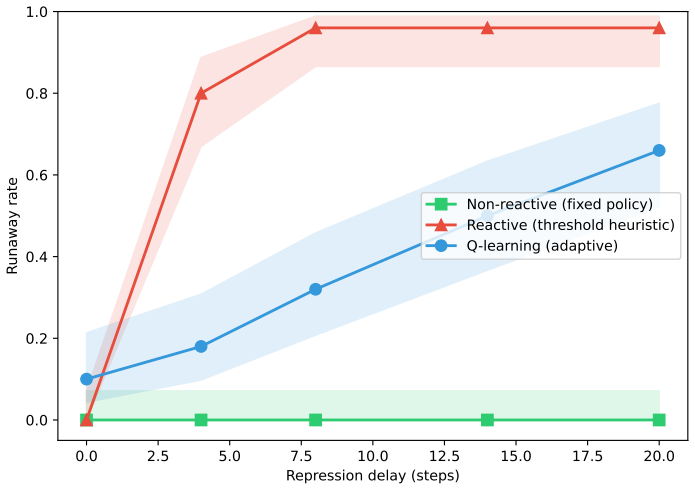
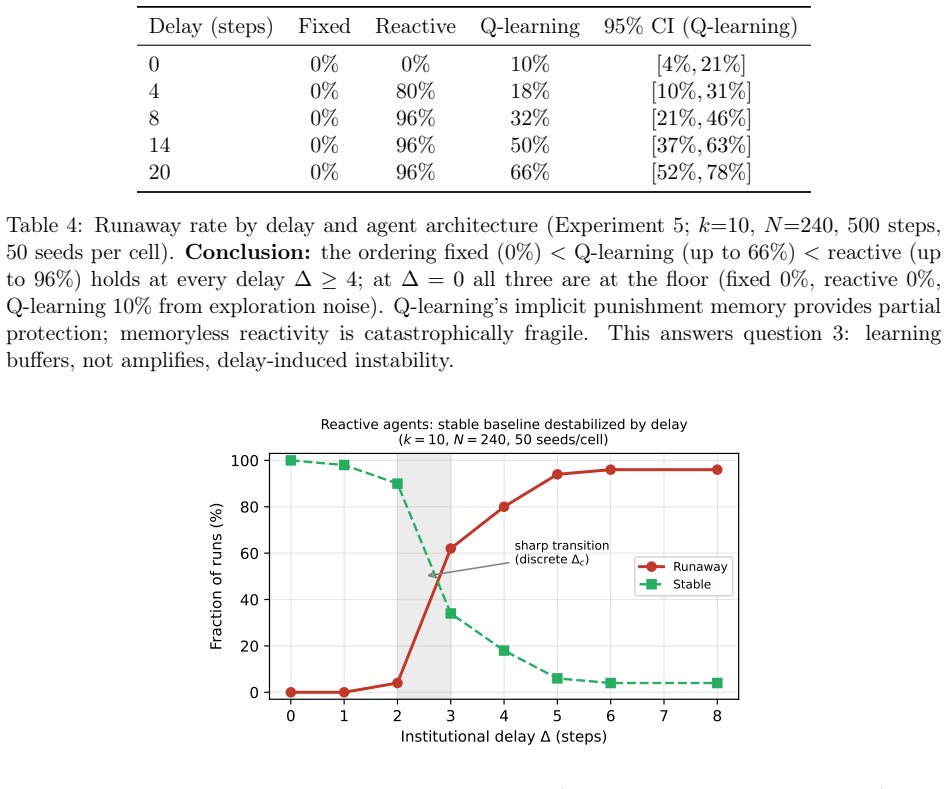
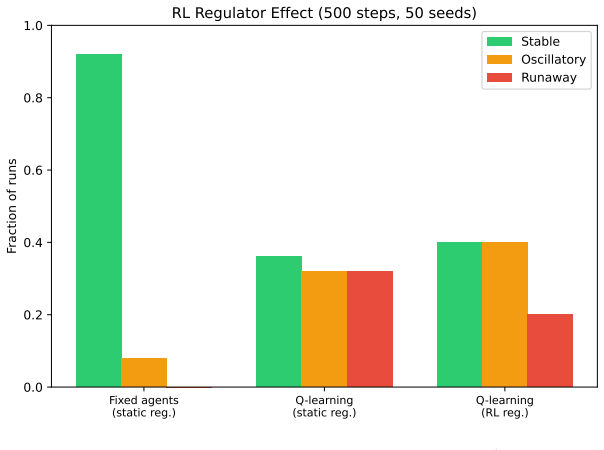
In the delayed replicator equation with lagged institutional alarm, a closed-form critical delay exists beyond which the unique interior equilibrium loses stability through a Hopf bifurcation; center manifold reduction proves the bifurcation is supercritical for every sigmoid response function, yielding bounded large-amplitude oscillations. Simulations confirm that fixed-policy agents remain stable at all delays, reactive threshold agents reach 96 percent runaway by delay 8, and Q-learning agents reach only 66 percent runaway at delay 20, because value functions encode punishment memory that buffers immediate exploitation of low-alarm windows.
What carries the argument
The delayed replicator equation with lagged institutional punishment signal, whose local stability is analyzed by locating the Hopf bifurcation point and applying center manifold reduction to classify its type.
If this is right
- Beyond the critical delay the interior equilibrium loses stability.
- The resulting oscillations remain bounded rather than growing without limit.
- Fixed-policy agents exhibit zero runaway at every tested delay.
- Reactive threshold agents exhibit 96 percent runaway once delay reaches or exceeds 8.
- Q-learning agents exhibit intermediate resilience because value functions retain memory of past punishments.
Where Pith is reading between the lines
- If agents can coordinate their responses to the lagged signal, the effective critical delay may decrease.
- Institutions that shorten processing time or add forward-looking components could raise the stability threshold without changing agent rules.
- The same lag mechanism could be tested in other domains where agents respond to delayed negative feedback, such as market regulation or content platforms.
Load-bearing premise
Agents gain from radical behavior and receive punishment only from a lagged institutional signal, with no external shocks, coordination among agents, or malicious intent.
What would settle it
Compute the model's closed-form critical delay for a chosen sigmoid response, then run the replicator or agent simulation at delays just below and just above that value to check whether large-amplitude oscillations appear exactly at the predicted threshold.
Figures
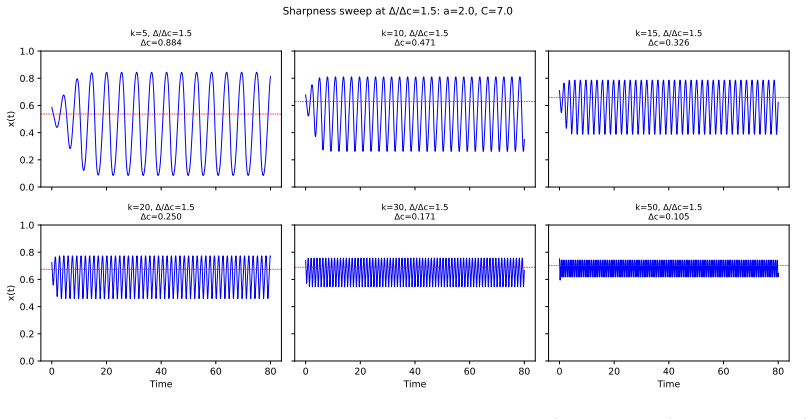
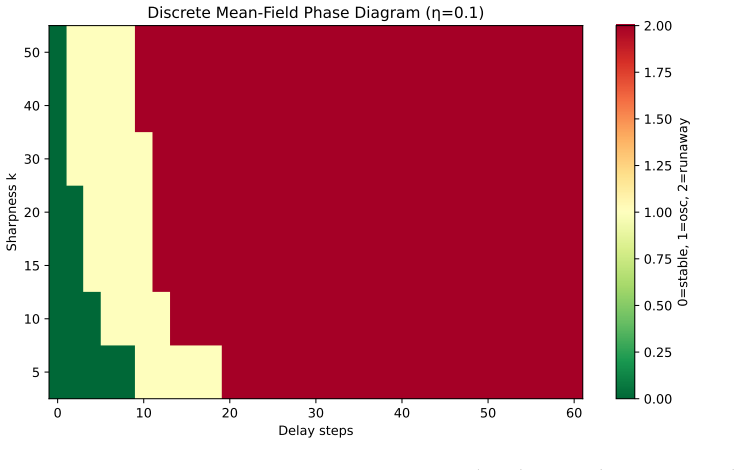
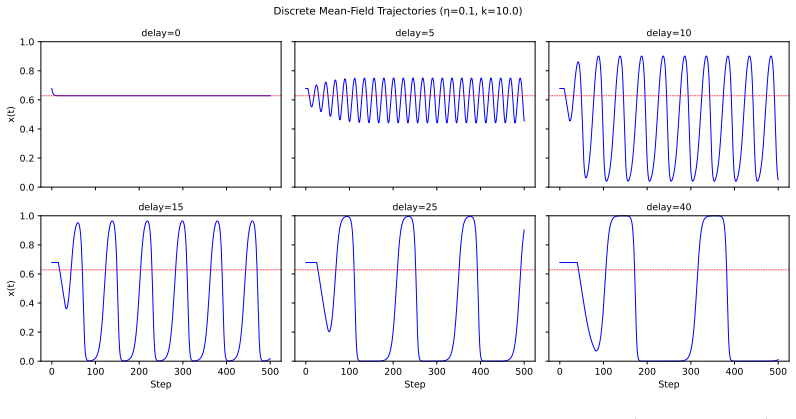
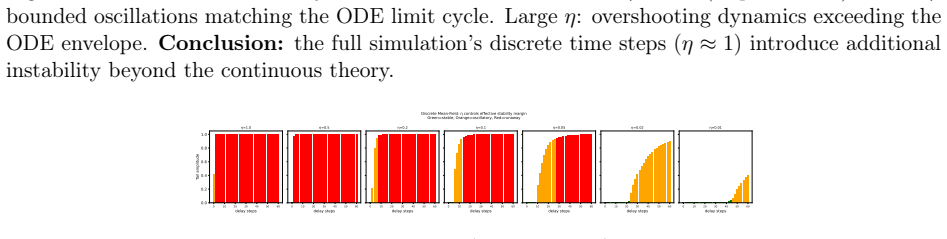
read the original abstract
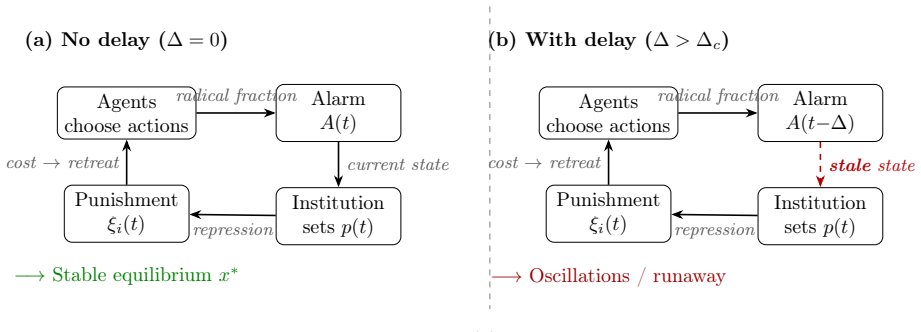
Regulatory institutions (from content moderation platforms to financial supervisors) observe, deliberate, and intervene only after a characteristic delay. We ask whether this processing lag alone can destabilize a multi-agent system that would otherwise remain stable, without exogenous shocks, coordination among agents, or malicious actors. We study this in two stages. First, we analyze a delayed replicator equation in which autonomous agents benefit from radical behavior but face punishment based on a lagged institutional alarm signal. We derive a closed-form critical delay beyond which the unique interior equilibrium loses stability through a Hopf bifurcation, and prove via center manifold reduction that the bifurcation is supercritical (bounded oscillations, not explosive growth) for the entire sigmoid response family. Second, we embed N=240 agents on a network with reinforcement learning (tabular Q-learning) and cross institutional delay with three decision architectures: fixed-policy, reactive (a memoryless threshold heuristic), and Q-learning. The hierarchy is opposite to the naive expectation that learning amplifies instability. Reactive agents are perfectly stable without delay yet collapse once delay is introduced (96% runaway by delay >= 8); fixed-policy agents are immune (0% at all delays); Q-learning agents are only partially resilient (66% at delay 20). The destabilizing ingredient is reactivity to delayed signals, not learning: agents that immediately exploit low-alarm windows trigger oscillatory feedback loops, while learning buffers this through punishment memory encoded in value functions. Throughout, "runaway" denotes bounded large-amplitude oscillation crossing a radical-fraction threshold, consistent with the supercritical bifurcation, not unbounded growth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies whether institutional processing delays alone can destabilize multi-agent systems. It first analyzes a delayed replicator equation where agents gain from radical behavior but receive lagged punishment via a sigmoid institutional response. It derives a closed-form critical delay at which the interior equilibrium loses stability via Hopf bifurcation and uses center-manifold reduction to prove the bifurcation is supercritical for the full sigmoid family. It then runs N=240 agent simulations on a network with tabular Q-learning, comparing fixed-policy, reactive threshold, and Q-learning architectures across delays; reactive agents show 96% runaway at delay >=8, fixed-policy remain stable at 0%, and Q-learning reach 66% at delay 20. The key conclusion is that reactivity to delayed signals, not learning per se, drives the instability, producing bounded large-amplitude oscillations consistent with the supercritical bifurcation.
Significance. If the closed-form delay and center-manifold proof hold, the work supplies a rigorous, parameter-free mechanism by which pure lag in regulatory feedback can induce endogenous oscillatory instability in otherwise stable multi-agent populations. The explicit demonstration that the bifurcation remains supercritical across the sigmoid family is a strength, as is the simulation hierarchy that isolates reactivity as the destabilizing factor and shows learning can buffer rather than amplify instability. These elements would be of interest to researchers in multi-agent systems, evolutionary game theory, and institutional design.
major comments (1)
- [Abstract / replicator analysis] Abstract and replicator-analysis section: the central claim is a closed-form critical delay for Hopf bifurcation together with a center-manifold proof of supercriticality for the entire sigmoid family, yet the characteristic equation, the explicit expression for the critical delay, and the normal-form coefficients obtained from the reduction are not supplied, so the algebraic correctness and coverage of the sigmoid family cannot be verified.
minor comments (1)
- [Simulation stage] Simulation stage: the reported runaway percentages (96%, 0%, 66%) are given without error bars, number of independent runs, or exclusion criteria, which limits assessment of robustness even though these results are secondary to the analytic claim.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for identifying the need for greater algebraic transparency in the replicator analysis. The comment correctly notes that the characteristic equation, explicit critical-delay formula, and normal-form coefficients are not supplied in the current version. We will revise the manuscript to include these derivations so that the Hopf bifurcation result and the supercriticality claim for the full sigmoid family can be verified directly.
read point-by-point responses
-
Referee: [Abstract / replicator analysis] Abstract and replicator-analysis section: the central claim is a closed-form critical delay for Hopf bifurcation together with a center-manifold proof of supercriticality for the entire sigmoid family, yet the characteristic equation, the explicit expression for the critical delay, and the normal-form coefficients obtained from the reduction are not supplied, so the algebraic correctness and coverage of the sigmoid family cannot be verified.
Authors: We agree that the characteristic equation, the closed-form expression for the critical delay, and the normal-form coefficients from the center-manifold reduction are absent from the submitted manuscript. This prevents independent checking of the bifurcation threshold and of the claim that the bifurcation remains supercritical for every member of the sigmoid family. In the revised manuscript we will insert the full derivation: the linearized delayed replicator equation, the resulting characteristic equation, the explicit formula for the critical delay τ* obtained from the Hopf condition, and the normal-form coefficients computed via center-manifold reduction that establish supercriticality uniformly across the sigmoid parameter range. These additions will be placed in the main replicator-analysis section (or a short appendix if length constraints require it) with all intermediate algebraic steps shown. revision: yes
Circularity Check
No significant circularity; derivations are direct from model equations
full rationale
The paper derives the closed-form critical delay and proves supercritical Hopf bifurcation via center manifold reduction explicitly from the delayed replicator equation and sigmoid response family. These steps are standard mathematical analysis applied to the stated model, not reductions to fitted inputs, self-definitions, or self-citation chains. Simulations report empirical outcomes from agent architectures under varying delays, without evidence that results are forced by parameter choice or prior author work. The derivation chain is self-contained against the model assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The system follows a delayed replicator equation in which agents gain from radical behavior but receive lagged punishment from an institutional alarm signal.
Forward citations
Cited by 1 Pith paper
-
Delayed Verification Destabilizes Multi-Agent LLM Belief: Instability Thresholds and Optimal Corrector Placement
Models delayed verification in multi-agent LLMs as graph consensus, derives stability thresholds (inverse golden ratio for delay two) via grounded Laplacian, and gives a supermodular greedy rule for corrector placemen...
Reference graph
Works this paper leans on
-
[1]
Stability of evolutionarily stable strategies in discrete replicator dynamics with time delay
Jan Alboszta and Jacek Miekisz. Stability of evolutionarily stable strategies in discrete replicator dynamics with time delay. Journal of Theoretical Biology, 231 0 (2): 0 175--179, 2004. doi:10.1016/j.jtbi.2004.06.012
-
[2]
Discrete and continuous distributed delays in replicator dynamics
Nesrine Ben-Khalifa, Rachid El-Azouzi, and Yezekael Hayel. Discrete and continuous distributed delays in replicator dynamics. Dynamic Games and Applications, 8 0 (4): 0 713--732, 2018. doi:10.1007/s13235-017-0225-7
-
[3]
Reinforcement learning with random delays
Yann Bouteiller, Simon Ramstedt, Giovanni Beltrame, Christopher Pal, and Jonathan Binas. Reinforcement learning with random delays. In International Conference on Learning Representations (ICLR), 2021
2021
-
[4]
Delay-aware multi-agent reinforcement learning for cooperative and competitive environments
Baiming Chen, Mengdi Xu, Zuxin Liu, Liang Li, and Ding Zhao. Delay-aware multi-agent reinforcement learning for cooperative and competitive environments. arXiv preprint arXiv:2005.05441, 2020
-
[5]
Acting in delayed environments with non-stationary markov policies
Esther Derman, Gal Dalal, and Shie Mannor. Acting in delayed environments with non-stationary markov policies. In International Conference on Learning Representations (ICLR), 2021
2021
-
[6]
Linton C. Freeman. A set of measures of centrality based on betweenness. Sociometry, 40 0 (1): 0 35--41, 1977. doi:10.2307/3033543
-
[7]
Michelle Girvan and Mark E. J. Newman. Community structure in social and biological networks. Proceedings of the National Academy of Sciences, 99 0 (12): 0 7821--7826, 2002. doi:10.1073/pnas.122653799
-
[8]
Multi-agent deep reinforcement learning: A survey
Sven Gronauer and Klaus Diepold. Multi-agent deep reinforcement learning: A survey. Artificial Intelligence Review, 55: 0 895--943, 2022. doi:10.1007/s10462-021-09996-w
-
[9]
Introduction to Functional Differential Equations, volume 99 of Applied Mathematical Sciences
Jack K Hale and Sjoerd M Verduyn Lunel. Introduction to Functional Differential Equations, volume 99 of Applied Mathematical Sciences. Springer, 1993
1993
-
[10]
Theory and Applications of Hopf Bifurcation, volume 41 of London Mathematical Society Lecture Note Series
Brian D Hassard, Nicholas D Kazarinoff, and Yieh-Hei Wan. Theory and Applications of Hopf Bifurcation, volume 41 of London Mathematical Society Lecture Note Series. Cambridge University Press, 1981
1981
-
[11]
Evolutionary Games and Population Dynamics
Josef Hofbauer and Karl Sigmund. Evolutionary Games and Population Dynamics. Cambridge University Press, 1998
1998
-
[12]
Paul W. Holland, Kathryn Blackmond Laskey, and Samuel Leinhardt. Stochastic blockmodels: First steps. Social Networks, 5 0 (2): 0 109--137, 1983. doi:10.1016/0378-8733(83)90021-7
-
[13]
On delayed discrete evolutionary dynamics
Ryota Iijima. On delayed discrete evolutionary dynamics. Journal of Theoretical Biology, 300: 0 1--6, 2012. doi:10.1016/j.jtbi.2012.01.001
-
[14]
Delay Differential Equations with Applications in Population Dynamics
Yang Kuang. Delay Differential Equations with Applications in Population Dynamics. Academic Press, 1993
1993
-
[15]
Erez Lieberman, Christoph Hauert, and Martin A. Nowak. Evolutionary dynamics on graphs. Nature, 433 0 (7023): 0 312--316, 2005. doi:10.1038/nature03204
-
[16]
Fixation probabilities in evolutionary dynamics under weak selection
Alex McAvoy and Benjamin Allen. Fixation probabilities in evolutionary dynamics under weak selection. Journal of Mathematical Biology, 82: 0 14, 2021. doi:10.1007/s00285-021-01568-4
-
[17]
Evolutionary game theory and population dynamics
Jacek Miekisz. Evolutionary game theory and population dynamics. In Multiscale Problems in the Life Sciences, volume 1940 of Lecture Notes in Mathematics, pages 269--316. Springer, 2008. doi:10.1007/978-3-540-78362-6_5
-
[18]
Evolutionary dynamics of the delayed replicator--mutator equation: Limit cycle and cooperation
Sourabh Mittal, Archan Mukhopadhyay, and Sagar Chakraborty. Evolutionary dynamics of the delayed replicator--mutator equation: Limit cycle and cooperation. Physical Review E, 101 0 (4): 0 042410, 2020. doi:10.1103/PhysRevE.101.042410
-
[19]
Javad Mohamadichamgavi and Marek Bodnar. Bifurcation analysis of replicator dynamics with logistic growth and strategy-dependent time delays in snowdrift game. Dynamic Games and Applications, 2025. doi:10.1007/s13235-025-00671-1
-
[20]
Martin A. Nowak. Five rules for the evolution of cooperation. Science, 314 0 (5805): 0 1560--1563, 2006. doi:10.1126/science.1133755
-
[21]
Hisashi Ohtsuki, Christoph Hauert, Erez Lieberman, and Martin A. Nowak. A simple rule for the evolution of cooperation on graphs and social networks. Nature, 441 0 (7092): 0 502--505, 2006. doi:10.1038/nature04605
-
[22]
Matja z Perc, Jes \'u s G \'o mez-Garde \ n es, Attila Szolnoki, Luis M. Flor \'i a, and Yamir Moreno. Evolutionary dynamics of group interactions on structured populations: A review. Journal of the Royal Society Interface, 10 0 (80): 0 20120997, 2013. doi:10.1098/rsif.2012.0997
-
[23]
Matja z Perc, Jillian J. Jordan, David G. Rand, Zhen Wang, Stefano Boccaletti, and Attila Szolnoki. Statistical physics of human cooperation. Physics Reports, 687: 0 1--51, 2017. doi:10.1016/j.physrep.2017.05.004
-
[24]
Francisco C. Santos and Jorge M. Pacheco. Scale-free networks provide a unifying framework for the emergence of cooperation. Physical Review Letters, 95 0 (9): 0 098104, 2005. doi:10.1103/PhysRevLett.95.098104
-
[25]
Critical Transitions in Nature and Society
Marten Scheffer. Critical Transitions in Nature and Society. Princeton University Press, 2009
2009
-
[26]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. MIT Press, 2018
2018
-
[27]
Gy \"o rgy Szab \'o and G \'a bor F \'a th. Evolutionary games on graphs. Physics Reports, 446 0 (4--6): 0 97--216, 2007. doi:10.1016/j.physrep.2007.04.004
-
[28]
Peter D. Taylor and Leo B. Jonker. Evolutionary stable strategies and game dynamics. Mathematical Biosciences, 40 0 (1--2): 0 145--156, 1978. doi:10.1016/0025-5564(78)90077-9
-
[29]
Stochastic dynamics of invasion and fixation
Arne Traulsen, Martin A Nowak, and Jorge M Pacheco. Stochastic dynamics of invasion and fixation. Physical Review E, 74 0 (1): 0 011909, 2006. doi:10.1103/PhysRevE.74.011909
-
[30]
Hopf bifurcations in delayed rock--paper--scissors replicator dynamics
Elizabeth Wesson and Richard Rand. Hopf bifurcations in delayed rock--paper--scissors replicator dynamics. Dynamic Games and Applications, 6 0 (1): 0 139--156, 2016. doi:10.1007/s13235-015-0138-2
-
[31]
Elizabeth Wesson, Richard H. Rand, and David G. Rand. Hopf bifurcations in two-strategy delayed replicator dynamics. International Journal of Bifurcation and Chaos, 26 0 (1): 0 1650006, 2016. doi:10.1142/S0218127416500061
-
[32]
Thomas A. Wettergren. Replicator dynamics of evolutionary games with different delays on costs and benefits. Applied Mathematics and Computation, 458: 0 128228, 2023. doi:10.1016/j.amc.2023.128228
-
[33]
Cooperator driven oscillation in a time-delayed feedback-evolving game
Fang Yan, Xiaojie Chen, Zhipeng Qiu, and Attila Szolnoki. Cooperator driven oscillation in a time-delayed feedback-evolving game. New Journal of Physics, 23: 0 053017, 2021. doi:10.1088/1367-2630/abf205
-
[34]
Multi-agent reinforcement learning: A selective overview of theories and algorithms
Kaiqing Zhang, Zhuoran Yang, and Tamer Ba s ar. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Handbook of Reinforcement Learning and Control, Studies in Systems, Decision and Control, pages 321--384. Springer, 2021
2021
-
[35]
Multi-agent reinforcement learning with reward delays
Yuyang Zhang, Runyu Zhang, Yuantao Gu, and Na Li. Multi-agent reinforcement learning with reward delays. In Proceedings of the 5th Annual Learning for Dynamics and Control Conference (L4DC), volume 211 of PMLR, pages 692--704, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.