Needles at Scale: LLM-Assisted Target Selection for Windows Vulnerability Research
Pith reviewed 2026-06-28 16:46 UTC · model grok-4.3
The pith
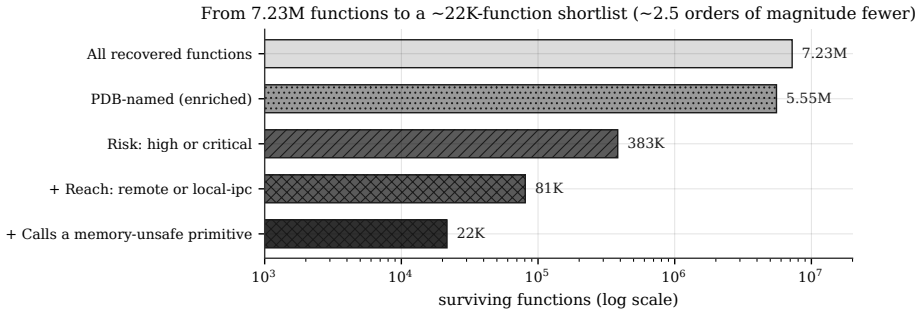
A batch pipeline recovers symbols and applies low-cost LLM labels to reduce 7.2 million Windows functions to a 22,000-function shortlist for vulnerability research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
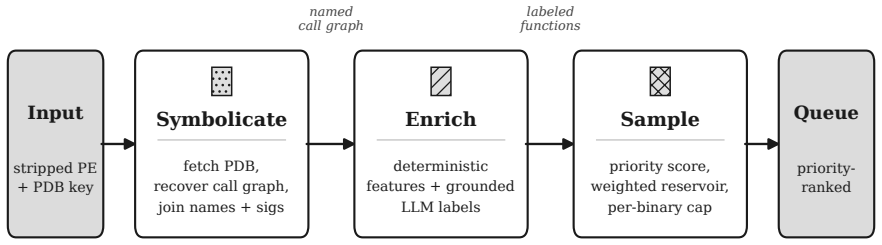
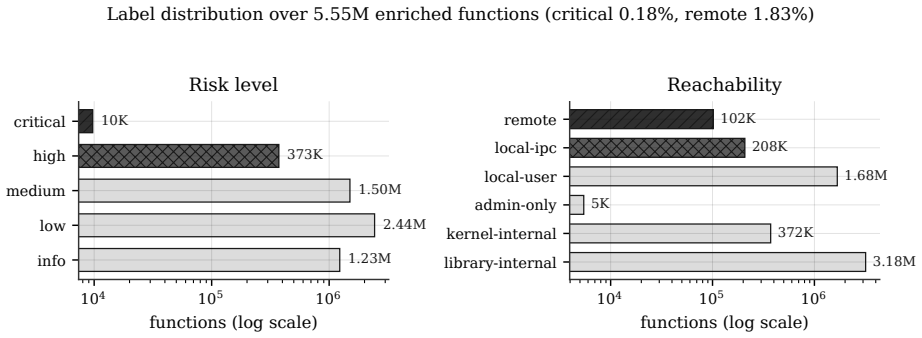
The central claim is that the Symbolicate-Enrich-Sample pipeline produces a queryable, priority-ranked research queue from production Windows binaries: it recovers symbols by auto-fetching public files and joining them to the call graph, attaches cheap structural features, conditions a low-cost language model on those features to assign reachability tier, risk level, bug-class hypothesis and rationale, and draws diverse prioritized batches via importance sampling, yielding markedly selective labels whose deterministic filters reduce 7,231,419 functions to a roughly 22,000-function shortlist of candidate needles.
What carries the argument
The Symbolicate-Enrich-Sample pipeline, which recovers symbols, attaches structural features, obtains LLM labels for reachability/risk/bug-class, and performs priority-weighted sampling to create the selection substrate.
If this is right
- A human analyst or LLM agent can now examine a shortlist of roughly 22,000 functions instead of millions.
- The prioritization layer serves as a substrate on which any downstream detector or agent can run.
- Stacking deterministic filters on the LLM labels produces the candidate-needle queue at whole-OS scope.
- The pipeline operates at low cost in batch mode on a full production Windows image.
Where Pith is reading between the lines
- The same symbol-recovery-plus-LLM-labeling pattern could be applied to large software corpora outside Windows.
- The characterized failure modes of the labeling step suggest concrete places to add further deterministic checks.
- The shortlist could be used as training data to improve future models that predict vulnerability-prone functions.
- Periodic re-runs of the pipeline on updated Windows images would maintain a living research queue.
Load-bearing premise
The reachability tier, risk level, and bug-class hypotheses produced by the low-cost language model from structural features are accurate enough that the shortlist contains a useful concentration of actual vulnerabilities.
What would settle it
An audit that measures the density of confirmed vulnerabilities inside the 22K shortlist versus a random sample drawn from the remaining functions.
Figures
read the original abstract
The attack surface of a modern operating system is a haystack: thousands of signed binaries and millions of functions, almost none relevant to any given vulnerability. A human analyst or an LLM agent must pick the function worth reading before analyzing it. At whole-OS scope, this target selection, not the analysis, is the binding constraint. We present Symbolicate-Enrich-Sample, a low-cost batch pipeline that turns a corpus of production Windows binaries into a queryable, priority-ranked research queue. We (i) recover function-level symbols for stripped vendor binaries by auto-fetching the public symbol files and joining them to a recovered call graph; (ii) attach cheap, deterministic structural features to each named function and, conditioned on those features, use a low-cost language model to assign a reachability tier, a risk level, a bug-class hypothesis, and a rationale; and (iii) draw diverse, prioritized batches via a priority-weighted importance sampler. The contribution is a selection substrate: the prioritization layer a downstream detector or LLM agent runs on top of. Across a whole Windows image of 7,231,419 functions, the labels are markedly selective, and stacking deterministic filters on them leaves a ~22K-function shortlist: the candidate needles, few enough for a human or agent to work through. We characterize the pipeline's selectivity and its failure modes, describe the methodology, and report aggregate statistics; we withhold the derived dataset for legal and dual-use reasons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the Symbolicate-Enrich-Sample pipeline for whole-OS target selection on Windows. It recovers symbols for 7,231,419 functions across stripped binaries, attaches deterministic structural features, prompts a low-cost LLM to assign reachability tier, risk level, and bug-class hypotheses with rationales, then stacks deterministic filters and a priority-weighted sampler to produce a ~22K-function shortlist. The stated contribution is this selection substrate; the paper reports aggregate selectivity statistics and failure-mode characterization but withholds the derived dataset.
Significance. If the LLM labels concentrate actual vulnerabilities, the pipeline would address a genuine bottleneck by reducing millions of functions to a human- or agent-scale queue. The low-cost batch design, explicit stacking of deterministic filters on LLM outputs, and importance sampler for diversity are practical strengths that could be reused. The work supplies reproducible pipeline details and large-scale aggregate statistics on a production Windows image.
major comments (2)
- [Abstract] Abstract: the central claim that the ~22K shortlist consists of 'candidate needles' usable for vulnerability research depends on LLM reachability/risk/bug-class labels correlating with real bugs. The manuscript supplies only aggregate selectivity statistics and failure-mode descriptions; no precision/recall, baseline comparisons, mapping to known CVEs, or expert review of a label sample is reported. This leaves open whether selectivity reflects vulnerability signal or LLM structural priors.
- [Pipeline and evaluation description] Pipeline and evaluation description: the reachability tier, risk level, and bug-class hypotheses are produced by the LLM conditioned only on structural features, yet no quantitative validation (e.g., agreement with disclosed vulnerabilities or inter-rater reliability with experts) is provided to support downstream utility. Without such evidence the shortlist's claimed value for human or agent analysis remains untested.
minor comments (1)
- [Methodology] The manuscript could add a table summarizing the exact structural features fed to the LLM and the prompt template(s) used, to improve reproducibility of the labeling step.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment below, clarifying the scope of the contribution as a selection substrate rather than a validated vulnerability detector. We agree that stronger evidence of correlation with real bugs would strengthen downstream claims and will make targeted revisions for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the ~22K shortlist consists of 'candidate needles' usable for vulnerability research depends on LLM reachability/risk/bug-class labels correlating with real bugs. The manuscript supplies only aggregate selectivity statistics and failure-mode descriptions; no precision/recall, baseline comparisons, mapping to known CVEs, or expert review of a label sample is reported. This leaves open whether selectivity reflects vulnerability signal or LLM structural priors.
Authors: The manuscript does not claim or demonstrate that the LLM labels correlate with actual vulnerabilities; the stated contribution is the reproducible pipeline that produces a queryable, priority-ranked queue from structural features and low-cost LLM inference. Selectivity is reported with respect to the generated labels and stacked deterministic filters, along with failure-mode characterization. We will revise the abstract to replace 'candidate needles' with language that explicitly frames the shortlist as functions prioritized by reachability and risk hypotheses (not proven bug correlation) to prevent overstatement. revision: partial
-
Referee: [Pipeline and evaluation description] Pipeline and evaluation description: the reachability tier, risk level, and bug-class hypotheses are produced by the LLM conditioned only on structural features, yet no quantitative validation (e.g., agreement with disclosed vulnerabilities or inter-rater reliability with experts) is provided to support downstream utility. Without such evidence the shortlist's claimed value for human or agent analysis remains untested.
Authors: The design deliberately conditions the LLM only on cheap structural features because source code and full semantic context are unavailable for stripped production binaries. The paper quantifies how selective the resulting labels become after filtering and sampling, but does not include precision/recall, CVE mapping, or expert inter-rater studies. We will add an explicit limitations paragraph in the evaluation section noting that downstream utility for bug discovery remains untested in this work and would require separate validation. revision: partial
- Providing precision/recall, baseline comparisons, mapping to known CVEs, or expert review of labels would require releasing the full derived dataset (withheld for legal and dual-use reasons) or substantial additional expert annotation resources outside the paper's scope of describing the pipeline and aggregate statistics.
Circularity Check
No circularity: applied pipeline with no derivations or fitted predictions
full rationale
The manuscript is a description of an engineering pipeline (Symbolicate-Enrich-Sample) that recovers symbols, attaches structural features, uses an LLM to assign reachability/risk/bug-class labels, and applies deterministic filters to produce a shortlist. No equations, parameters, or derivations are present. Selectivity arises from explicit stacking of filters on LLM outputs rather than any self-referential construction, fitted input renamed as prediction, or load-bearing self-citation chain. The work is self-contained as a methodological substrate report; absence of ground-truth validation is a correctness/evidence issue, not circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Public symbol files for Windows binaries can be auto-fetched and accurately joined to a recovered call graph.
- domain assumption Structural features plus a low-cost LLM can produce labels (reachability, risk, bug class) that are useful for prioritization.
Forward citations
Cited by 1 Pith paper
-
The Linux IOCTL Census: A Source-Derived Database of the Linux Kernel Control-Code Surface
Presents the Linux IOCTL Census, a source-derived database of 586 dispatch points, 1289 command codes, 3583 input sinks and 1298 permission gates extracted from the kernel, with capability-ungated surface separated an...
Reference graph
Works this paper leans on
-
[1]
SecVulEval: Benchmarking LLMs for real-world C/C++ vulnerability detection, 2025
Md Basim Uddin Ahmed, Nima Shiri Harzevili, Jiho Shin, Hung Viet Pham, and Song Wang. SecVulEval: Benchmarking LLMs for real-world C/C++ vulnerability detection, 2025. https://arxiv.org/abs/2505.19828
-
[2]
arXiv preprint arXiv:2510.18508 (2025), https://arxiv.org/abs/2510.18508
Osama Al Haddad, Muhammad Ikram, Ejaz Ahmed, and Young Lee. Prompting the priorities: A first look at evaluating LLMs for vulnerability triage and prioritization, 2025. https: //arxiv.org/abs/2510.18508
-
[3]
Marcel Böhme, Van-Thuan Pham, Manh-Dung Nguyen, and Abhik Roychoudhury. Directed greybox fuzzing. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 2329–2344, 2017.https://doi.org/10.1145/3133956. 3134020
-
[4]
Pavlos S. Efraimidis and Paul G. Spirakis. Weighted random sampling with a reservoir. Information Processing Letters, 97(5):181–185, 2006.https://doi.org/10.1016/j.ipl.2005 .11.003
-
[5]
LLM Agents can Autonomously Exploit One-day Vulnerabilities
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. LLM agents can autonomously exploit one-day vulnerabilities, 2024.https://arxiv.org/abs/2404.08144
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Xiuting Ge, Chunrong Fang, Xuanye Li, Weisong Sun, Daoyuan Wu, Juan Zhai, Shangwei Lin, Zhihong Zhao, Yang Liu, and Zhenyu Chen. Machine learning for actionable warning identification: A comprehensive survey, 2024.https://arxiv.org/abs/2312.00324
-
[7]
From naptime to big sleep: Using large language models to catch vulnerabilities in real-world code, 2024.https://projectzero.google/2024/10/fro m-naptime-to-big-sleep.html
Google Project Zero (Big Sleep Team). From naptime to big sleep: Using large language models to catch vulnerabilities in real-world code, 2024.https://projectzero.google/2024/10/fro m-naptime-to-big-sleep.html. 8
2024
-
[8]
O(N) the money: Scaling vulnerability research with LLMs, 2025
Caleb Gross. O(N) the money: Scaling vulnerability research with LLMs, 2025. https: //noperator.dev/posts/on-the-money/
2025
-
[9]
Caleb Gross. Sift or get off the PoC: Applying information retrieval to vulnerability research with SiftRank, 2025.https://arxiv.org/abs/2512.06155
-
[10]
Sarah Heckman and Laurie Williams. A systematic literature review of actionable alert identifi- cation techniques for automated static code analysis.Information and Software Technology, 53(4):363–387, 2011.https://doi.org/10.1016/j.infsof.2010.12.007
-
[11]
Needle in a haystack: Automated and scalable vulnerability hunting in the Windows ALPC sea
Haoyi Liu, Feng Dong, Yunpeng Tian, Mu Zhang, Xuefeng Li, Fangming Gu, Zhiniang Peng, and Haoyu Wang. Needle in a haystack: Automated and scalable vulnerability hunting in the Windows ALPC sea. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2025.https://doi.org/10.1145/3719027.3765180
-
[12]
Winbindex: An index of Windows binaries, 2021.https://winbindex.m417z.com/
m417z. Winbindex: An index of Windows binaries, 2021.https://winbindex.m417z.com/
2021
-
[13]
Large language model for vulnerability detection and repair: Literature review and the road ahead, 2024.https://arxiv.org/abs/24 04.02525
Xin Zhou, Sicong Cao, Xiaobing Sun, and David Lo. Large language model for vulnerability detection and repair: Literature review and the road ahead, 2024.https://arxiv.org/abs/24 04.02525. 9
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.