Cartridges at Scale: Training Modular KV Caches over Large Document Collections
Pith reviewed 2026-06-28 06:08 UTC · model grok-4.3
The pith
A training framework lets multiple per-document KV cartridges compose without accuracy collapse, scaling to million-token collections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
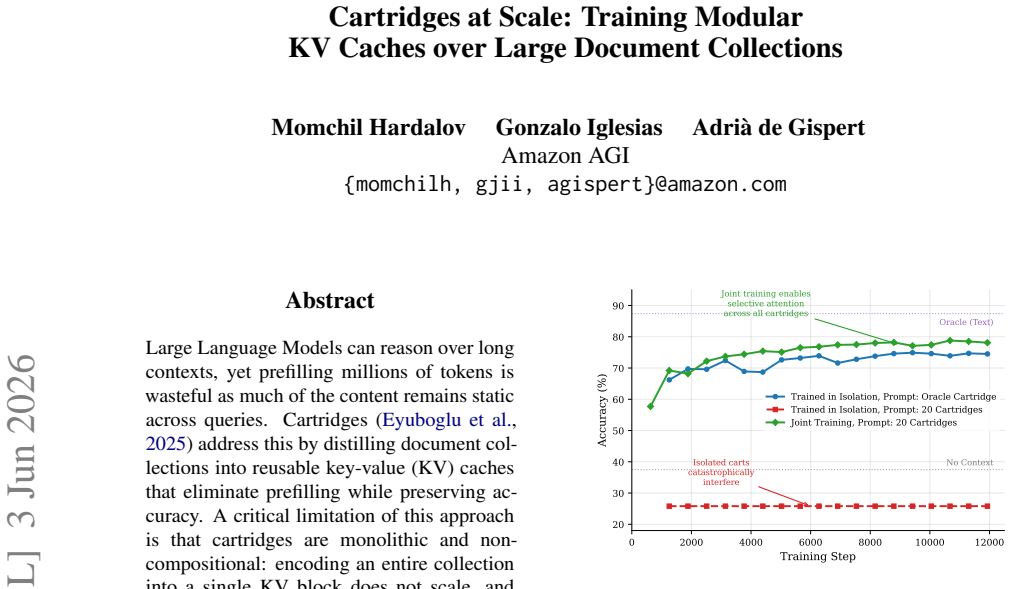
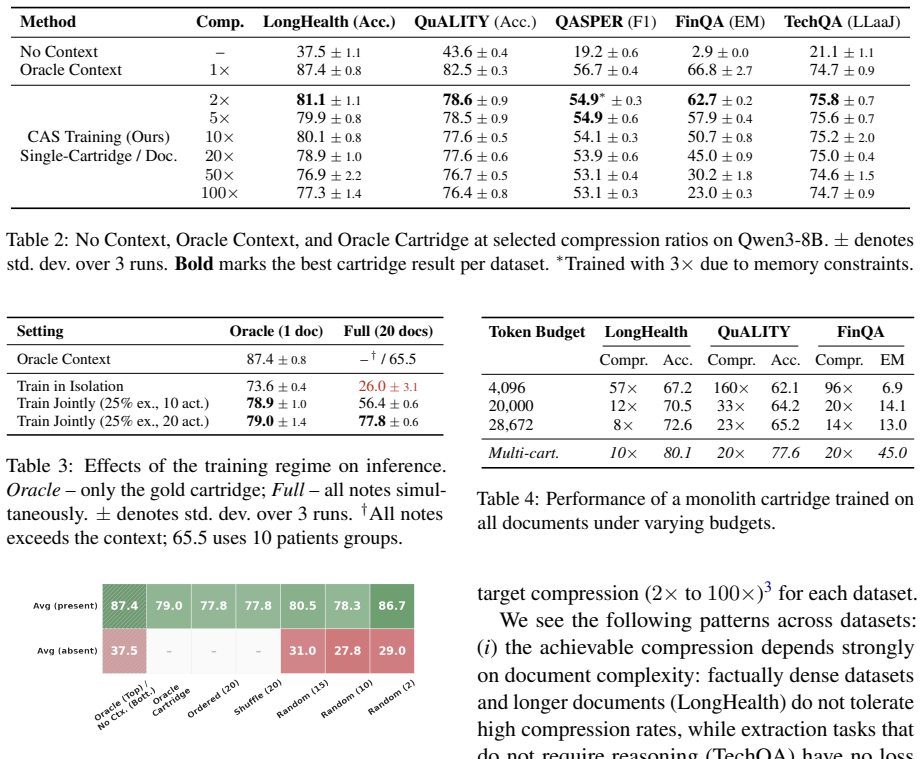
CAS trains hundreds of document-specific KV cartridges that can be mixed at inference time, scaling beyond the limits of monolithic caches to collections exceeding one million tokens while keeping oracle accuracy within 2-6 points of full in-context learning at high compression.
What carries the argument
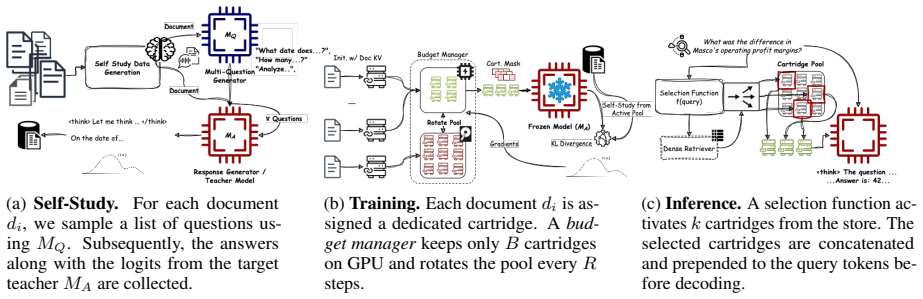
Dynamic distractor mixing during training together with a memory-efficient budget manager that rotates per-document cartridges between GPU memory and persistent storage.
If this is right
- Oracle cartridge selection reaches accuracy within 2-6 points of full in-context learning even at high compression.
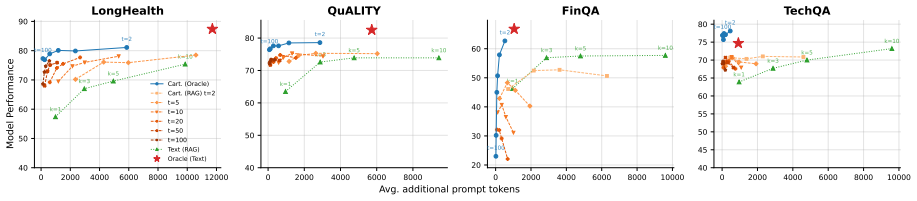
- When paired with retrieval for cartridge selection, the method matches or exceeds conventional RAG accuracy.
- Prompt token usage drops by a factor of 3-4 relative to standard RAG at comparable performance.
- Collections larger than one million tokens become feasible without retraining a single monolithic cache.
Where Pith is reading between the lines
- New documents could be added by training one additional cartridge and updating the retrieval index without touching existing ones.
- The same mixing principle might apply to other modular components such as tool-use caches or agent memory stores.
- The budget manager's rotation strategy could be adapted to multi-GPU or distributed settings for even larger collections.
Load-bearing premise
The training procedure with dynamic distractor mixing produces cartridges that remain accurate when mixed at inference without performance collapse.
What would settle it
Direct measurement of accuracy when mixing cartridges trained without distractor mixing versus with it, on the same collection size and query set.
Figures
read the original abstract
Large Language Models can reason over long contexts, yet prefilling millions of tokens is wasteful as much of the content remains static across queries. Cartridges address this by distilling document collections into reusable key-value (KV) caches that eliminate prefilling while preserving accuracy. A critical limitation of this approach is that cartridges are monolithic and non-compositional: encoding an entire collection into a single KV block does not scale, and naively mixing cartridges trained in isolation collapses performance to near chance. We introduce Cartridges at Scale (CAS), a training framework for scalable multi-cartridge learning with dynamic distractor mixing and a memory-efficient budget manager that rotates hundreds of per-document cartridges between GPU and persistent storage. Our approach scales to collections exceeding a million tokens, improving over a monolithic cartridge by 10-31 points at comparable token budgets. Oracle cartridge accuracy falls within 2-6 points of full in-context learning even at high compression. When paired with retrieval for cartridge selection, CAS matches or exceeds conventional RAG accuracy while consuming 3-4x fewer prompt tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cartridges at Scale (CAS), a training framework for modular KV caches (cartridges) distilled from large document collections. It claims that dynamic distractor mixing combined with a memory-efficient budget manager enables compositional cartridges that scale beyond a million tokens, yielding 10-31 point gains over monolithic cartridges at comparable budgets, oracle accuracy within 2-6 points of full in-context learning at high compression, and (with retrieval) matching or exceeding RAG accuracy at 3-4x lower prompt token cost.
Significance. If the reported gains are robust, the work would meaningfully advance efficient long-context inference by allowing reusable, mixable KV caches for static document collections, directly addressing the non-compositional limitation of prior monolithic cartridges.
major comments (2)
- [§3 (Methods)] The description of dynamic distractor mixing (including sampling procedure, mixing ratios, loss terms, and scheduling) and the budget manager rotation mechanism is provided only at a high level with no equations, pseudocode, or hyperparameter ranges. This is load-bearing for the central claim that naive mixing collapses performance while CAS succeeds, as the scaling results (10-31 point gains, no collapse on mixing) cannot be evaluated or reproduced without these details.
- [§4 (Experiments)] The quantitative results (10-31 point improvements, 2-6 point gap to ICL, 3-4x token savings vs RAG) are stated without reference to specific datasets, model sizes, compression ratios, number of documents, baselines, or ablation studies. This prevents assessment of whether the gains are supported by the data or sensitive to unstated experimental choices.
minor comments (2)
- [Abstract] The abstract introduces 'cartridges' without a one-sentence definition or citation to the prior monolithic cartridge work on first use.
- Notation for KV cache dimensions and compression ratios is used inconsistently between the abstract and later sections; a table of symbols would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the methods and experiments sections require additional detail to support reproducibility and evaluation of the central claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3 (Methods)] The description of dynamic distractor mixing (including sampling procedure, mixing ratios, loss terms, and scheduling) and the budget manager rotation mechanism is provided only at a high level with no equations, pseudocode, or hyperparameter ranges. This is load-bearing for the central claim that naive mixing collapses performance while CAS succeeds, as the scaling results (10-31 point gains, no collapse on mixing) cannot be evaluated or reproduced without these details.
Authors: We acknowledge that the current presentation of dynamic distractor mixing and the budget manager in §3 is high-level. In the revised manuscript we will expand this section to include the full equations governing the sampling procedure, mixing ratios, loss terms, and scheduling; pseudocode for the rotation mechanism; and the exact hyperparameter ranges employed. These additions will directly enable reproduction and evaluation of the reported scaling behavior. revision: yes
-
Referee: [§4 (Experiments)] The quantitative results (10-31 point improvements, 2-6 point gap to ICL, 3-4x token savings vs RAG) are stated without reference to specific datasets, model sizes, compression ratios, number of documents, baselines, or ablation studies. This prevents assessment of whether the gains are supported by the data or sensitive to unstated experimental choices.
Authors: We agree that §4 would benefit from explicit linkage to the underlying experimental details. The revision will update this section to cite the specific datasets, model sizes, compression ratios, document counts, baselines, and ablation studies that support each reported quantitative result, allowing readers to assess robustness and sensitivity. revision: yes
Circularity Check
No significant circularity; empirical training results are self-contained
full rationale
The paper describes an empirical training framework (CAS) that uses dynamic distractor mixing and a budget manager to produce compositional cartridges. Reported gains (10-31 points over monolithic, oracle within 2-6 of ICL, 3-4x token savings vs RAG) are presented as measured outcomes of this procedure on large collections, not as quantities derived by construction from fitted parameters or reduced to self-citations. The abstract and provided text contain no equations, uniqueness theorems, or ansatzes that loop back to the inputs; the central claims rest on experimental scaling results that remain falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dynamic distractor mixing during training produces compositional cartridges that remain effective when retrieved and combined at inference time.
Forward citations
Cited by 1 Pith paper
-
Self-Study Reconsidered: The Hidden Fragility of Learning from Self-Generated QA
Self-generated QA supervision for language models is fragile due to non-uniform question selection and instruction compliance during answering, with mitigations that reduce compliance from 88% to 13%.
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Information Processing Systems
Recurrent memory transformer. InAdvances in Neural Information Processing Systems. Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and Wen Xiao. 2025. Pyra- midKV: Dynamic KV cache compression based on pyramidal information funneling. InSecond Confer- ence on Language Modeling. Vittorio ...
2025
-
[2]
The TechQA dataset. InProceedings of the 58th Annual Meeting of the Association for Compu- tational Linguistics, pages 1269–1278, Online. Vivek Chari and Benjamin Van Durme. 2025. Com- pactor: Calibrated query-agnostic KV cache com- pression with approximate leverage scores.Preprint, arXiv:2507.08143. Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, ...
arXiv 2025
-
[3]
arXiv preprint arXiv:2510.00636
Expected attention: Kv cache compression by estimating attention from future queries distribution. arXiv preprint arXiv:2510.00636. Sabri Eyuboglu, Ryan Saul Ehrlich, Simran Arora, Neel Guha, Dylan Zinsley, Emily Ruoyu Liu, Atri Rudra, James Y . Zou, Azalia Mirhoseini, and Christopher Re
-
[4]
InES- FoMo III: 3rd Workshop on Efficient Systems for Foundation Models
Cartridges: Lightweight and general-purpose long context representations via self-study. InES- FoMo III: 3rd Workshop on Efficient Systems for Foundation Models. Leo Gao, Stella Biderman, Sid Black, Laurence Gold- ing, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, and 1 others. 2020. The pile: An 800gb dataset of di- ve...
Pith/arXiv arXiv 2020
-
[5]
arXiv preprint arXiv:2403.05527
Gear: An efficient kv cache compression recipe for near-lossless generative inference of llm. arXiv preprint arXiv:2403.05527. Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W. Lee, Sangdoo Yun, and Hyun Oh Song. 2026. KVzip: Query-agnostic KV cache compression with context reconstruction. InThe Thirty-ninth Annual Confer- ence on Neural Information Processi...
arXiv 2026
-
[6]
Maxime Louis, Hervé Déjean, and Stéphane Clin- chant
ZSMerge: Zero-shot KV cache compression for memory-efficient long-context LLMs.Preprint, arXiv:2503.10714. Maxime Louis, Hervé Déjean, and Stéphane Clin- chant. 2025. PISCO: Pretty simple compression for retrieval-augmented generation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 15506–15521, Vienna, Austria. Jesse Mu, Xian...
arXiv 2025
-
[7]
Yuxin Zhang, Yuxuan Du, Gen Luo, Yunshan Zhong, Zhenyu Zhang, Shiwei Liu, and Rongrong Ji
Qwen3 Technical Report.arXiv preprint arXiv:2505.09388. Yuxin Zhang, Yuxuan Du, Gen Luo, Yunshan Zhong, Zhenyu Zhang, Shiwei Liu, and Rongrong Ji. 2024. CaM: Cache merging for memory-efficient LLMs inference. InProceedings of the 41st International Conference on Machine Learning. Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi C...
Pith/arXiv arXiv 2024
-
[8]
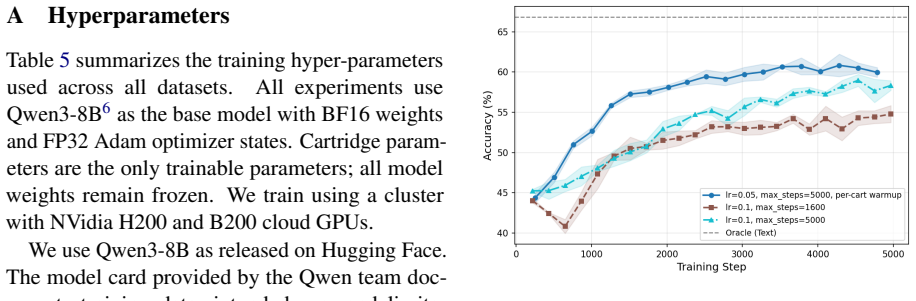
Fast KV compaction via attention matching. arXiv preprint arXiv:2602.16284. 12 A Hyperparameters Table 5 summarizes the training hyper-parameters used across all datasets. All experiments use Qwen3-8B6 as the base model with BF16 weights and FP32 Adam optimizer states. Cartridge param- eters are the only trainable parameters; all model weights remain froz...
Pith/arXiv arXiv 2025
-
[9]
Factual equivalence: Does the answer convey the same information as the reference answer?
-
[10]
Completeness: Does the answer address all parts of the question that the reference answer addresses?
-
[11]
Accuracy: Is the information in the answer consistent with the reference answer?
-
[12]
Additional information: If the answer contains more information than the reference answer, does it remain consistent and not contradict itself? Your response should be structured as follows:
-
[13]
A justification for your decision, explaining your reasoning based on the evaluation criteria
-
[14]
correct" or
A grade of either "correct" or "incorrect". Important note on deflections and invalid questions: - If the answer is a deflection or does not attempt to answer the question, grade it as "incorrect" unless the reference answer is also a deflection. - If both the answer and the reference answer indicate that the question is invalid or cannot be answered, gra...
2026
-
[15]
Answer Type: A formula is either a number or one of: add(f1, f2), subtract(f1, f2), multiply(f1, f2), divide(f1, f2), exp(f1, f2), greater(f1, f2)
-
[16]
Pay special attention to the table
Reasoning: Carefully analyze the context. Pay special attention to the table
-
[17]
<answer> FORMULA </answer>
Final Answer: "<answer> FORMULA </answer>" User: {context} Question: {question} LongHealthSystem: Please reference the patient medical records to answer the user’s questions. Choose the single best option and provide your answer exactly as it appears in the options. Wrap your answer in: <answer> The correct option text here </answer> User: {question} A. {...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.