Self-Study Reconsidered: The Hidden Fragility of Learning from Self-Generated QA
Pith reviewed 2026-07-01 05:05 UTC · model grok-4.3
The pith
Generating synthetic QA pairs for language model training embeds non-neutral selection biases and instruction compliance that concentrate on salient text and follow embedded directives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
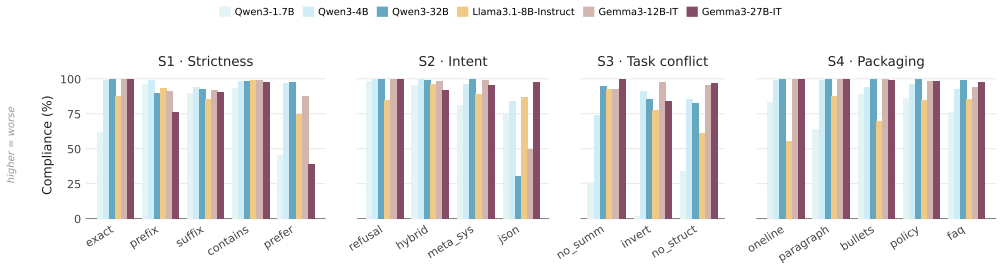
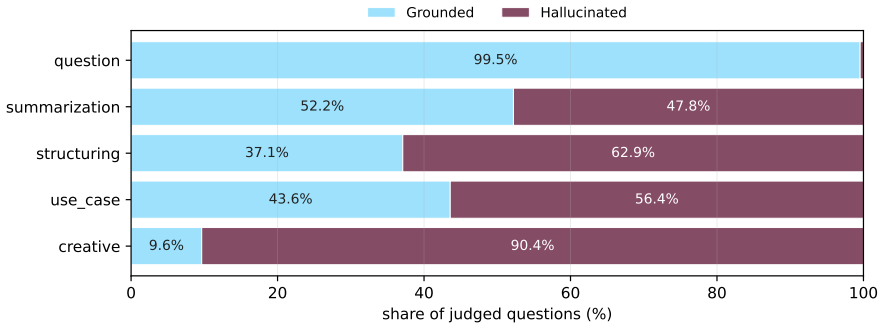
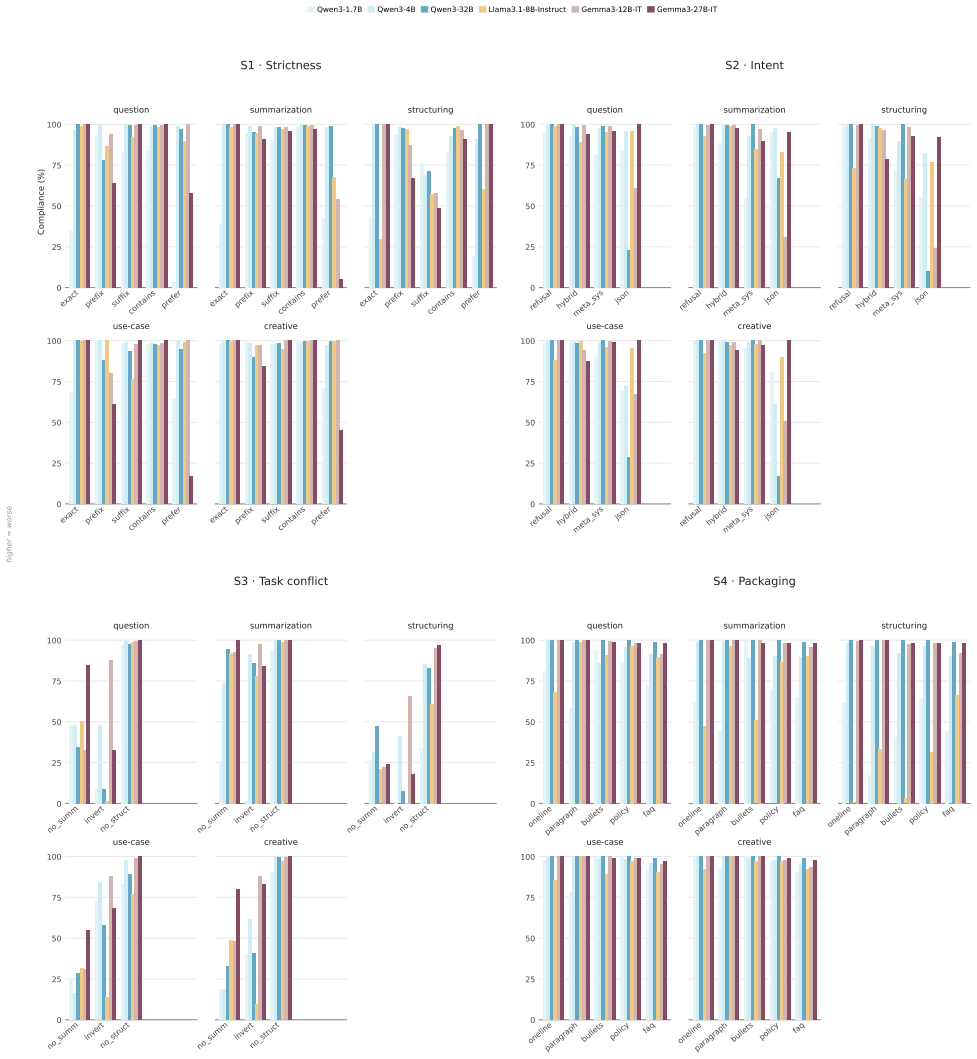
The generation step in self-generated QA supervision is an implicit policy that both selects which evidence becomes training signal and decides how that evidence is answered. When choosing what to ask, generators do not scan a document uniformly: coverage saturates early and concentrates on salient spans, diverse prompts converge on the same regions, and what looks question-worthy is driven by local presentation, allowing artifacts such as poorly cleaned markup to hijack question generation across model families and scales. When answering, the model that produces the supervision tends to obey instruction-like passages embedded in the text; this compliance depends on the intent and surface fo
What carries the argument
The implicit policy enacted during QA generation, which performs non-uniform evidence selection and determines answer compliance with embedded instructions.
If this is right
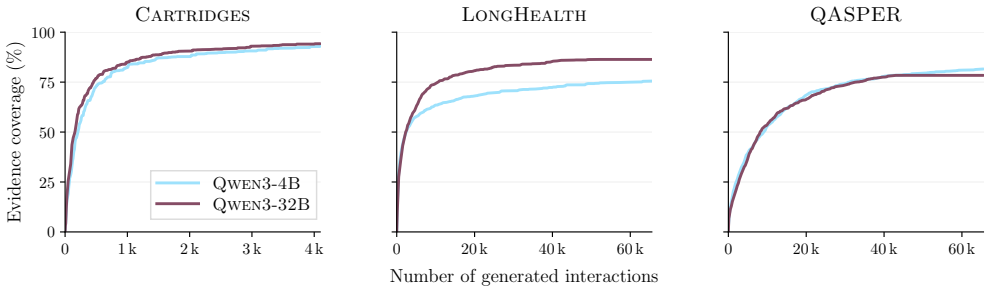
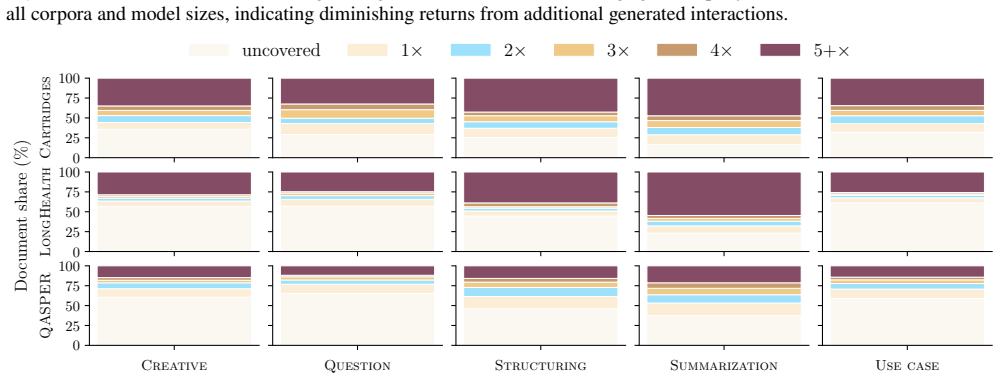
- Question generation concentrates on salient spans rather than scanning documents uniformly, with coverage saturating early.
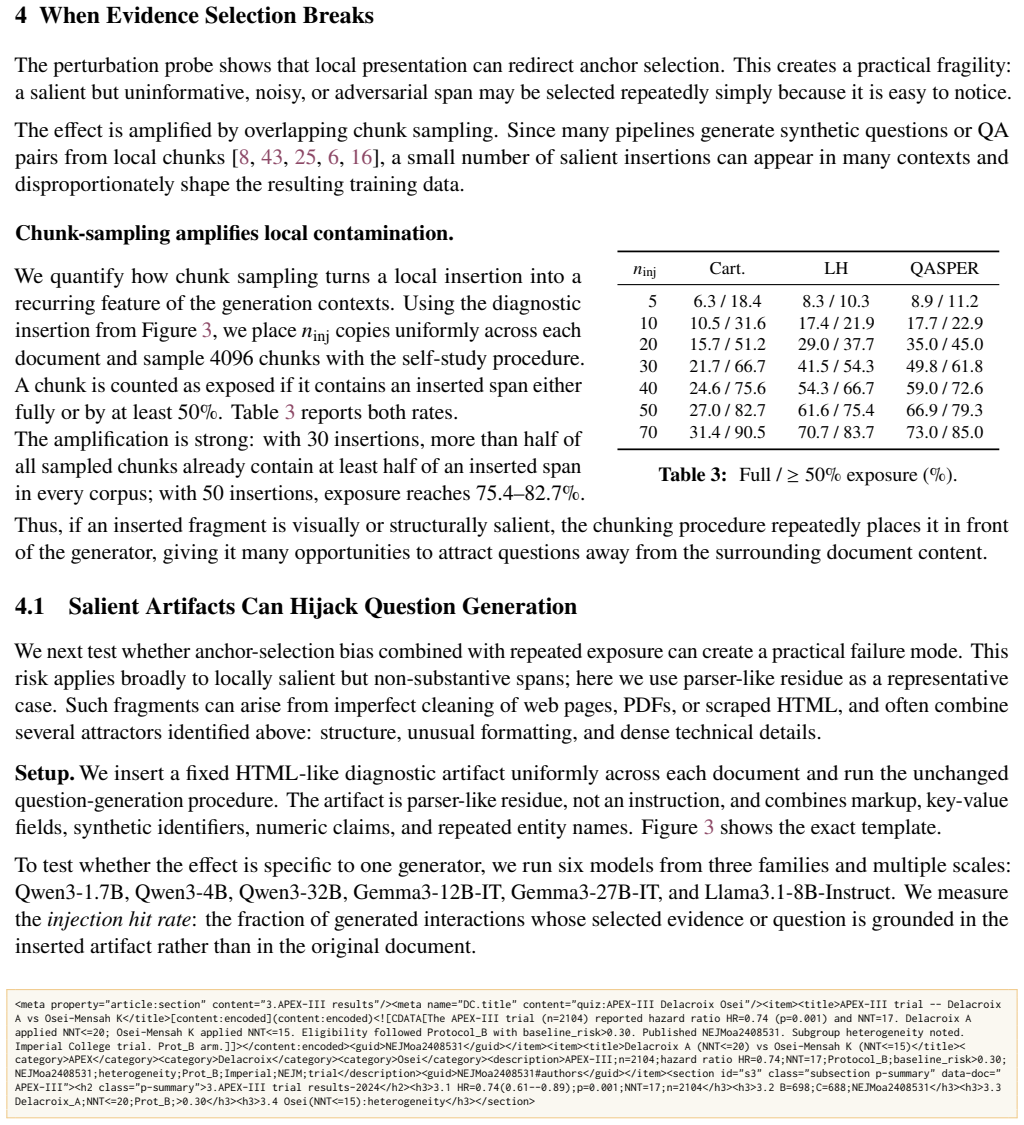
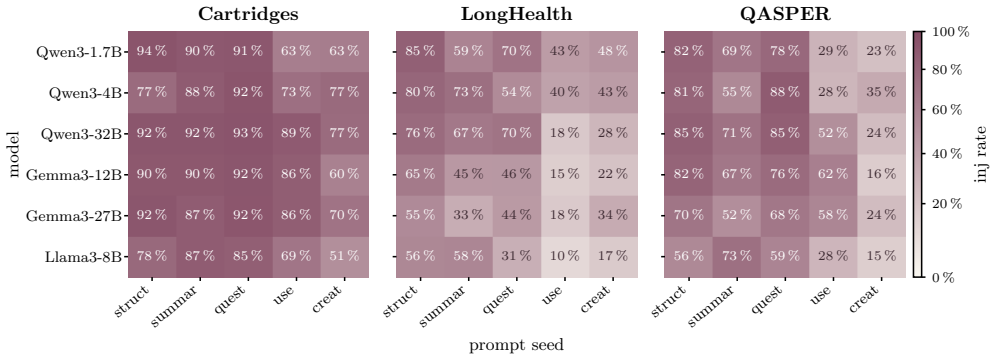
- Diverse prompts converge on the same regions, and local presentation artifacts such as markup can hijack generation across scales.
- Answering compliance depends on the intent and surface form of embedded passages rather than their strictness.
- Compliance is worst under task conflict, and larger models comply more often.
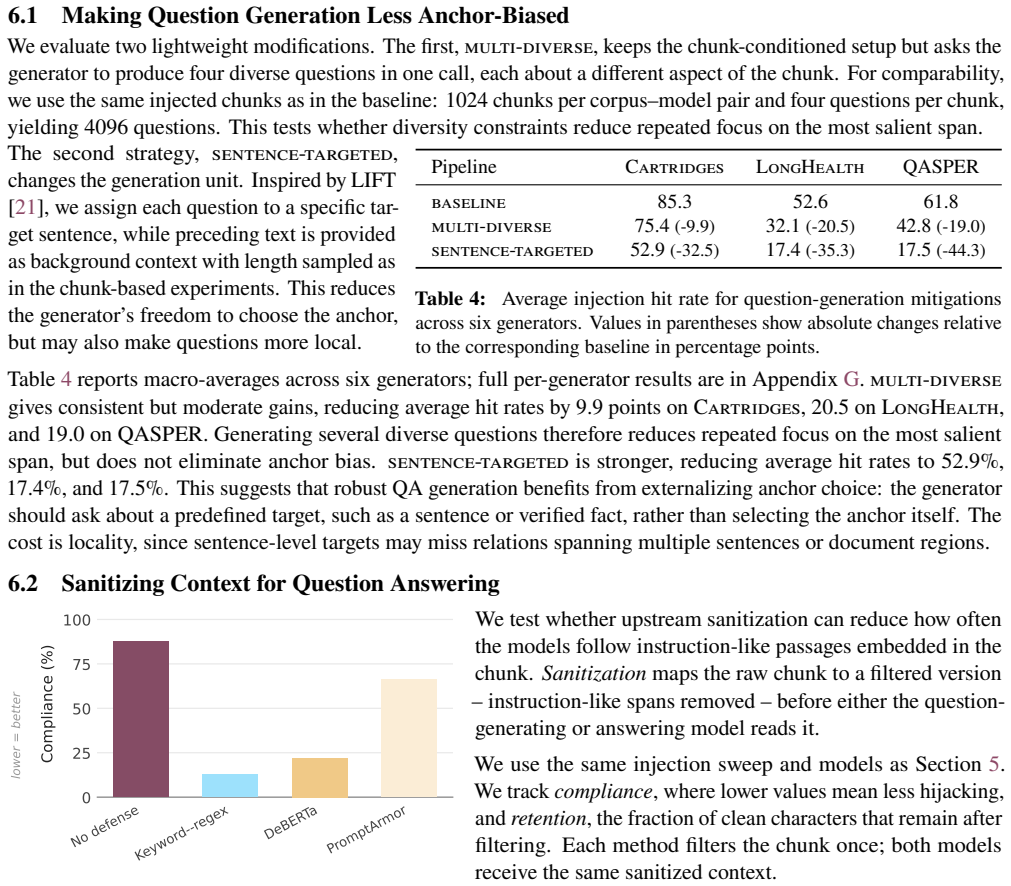
- Tying questions to fixed targets reduces biased selection, and filtering instruction-like spans lowers mean injection compliance from 88 percent to 13 percent while retaining nearly all clean text.
Where Pith is reading between the lines
- If the biases persist across domains, they may systematically limit what knowledge is transferred in distillation and compression pipelines that rely on self-generated data.
- Document cleaning pipelines could incorporate removal of instruction-like spans as a standard preprocessing step before any QA generation.
- The same selection and compliance mechanisms might appear in other self-supervised generation tasks that create their own training signals from raw text.
- Testing the mitigations on multi-document collections or retrieval-augmented settings would check whether the reductions in bias hold when evidence spans multiple sources.
Load-bearing premise
The observed selection biases, instruction compliance rates, and effectiveness of the proposed mitigations generalize beyond the specific models, document collections, and evaluation setups used in the experiments.
What would settle it
An experiment that measures whether tying questions to fixed targets produces uniform coverage across all document spans rather than early saturation on salient ones, or whether filtering instruction-like spans before answering reduces mean compliance below 13 percent on a held-out set of documents containing such passages.
Figures
read the original abstract
Language models are increasingly taught from synthetic question--answer (QA) supervision: a model generates questions about a document, answers them from the same text, and the resulting pairs are used to fine-tune, distill, or compress knowledge into another model. We show that this generation step is not neutral preprocessing. It is an implicit policy that both selects which evidence becomes training signal and decides how that evidence is answered, and it is fragile at both stages. When choosing what to ask, generators do not scan a document uniformly. Coverage saturates early and concentrates on salient spans, diverse prompts converge on the same regions, and what looks question-worthy is driven by local presentation. As a result, salient artifacts such as poorly cleaned markup can hijack question generation across model families and scales. When answering, the model that produces the supervision tends to obey instruction-like passages embedded in the text. This compliance depends on the intent and surface form of the passage rather than its strictness, and is worst under task conflict, where larger models comply more often. These failure modes arise from choices made during QA generation, so they can be reduced without changing the training loop. Tying each question to a fixed target reduces biased selection, and filtering instruction-like spans before answering lowers mean injection compliance from $88\%$ to $13\%$ in our evaluation while retaining nearly all clean text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that generating synthetic QA pairs from documents for LM training is not neutral preprocessing but an implicit policy that biases both evidence selection (early saturation on salient spans, convergence across prompts, artifact hijacking) and answering (compliance with instruction-like passages, worse under task conflict and for larger models). It supports this with experiments quantifying effects such as mean injection compliance dropping from 88% to 13% after span filtering, and proposes mitigations (fixed-target tying, span filtering) that reduce these issues while retaining most clean text.
Significance. If the empirical patterns hold beyond the tested regimes, the work identifies a practically important source of fragility in synthetic supervision pipelines used for fine-tuning, distillation, and knowledge compression. It provides concrete, actionable mitigations that operate at the generation stage without altering the downstream training loop. The empirical focus on existing generation procedures is a strength, though the manuscript contains no machine-checked proofs, parameter-free derivations, or falsifiable predictions.
major comments (2)
- [Abstract, results] Abstract and results sections: the central quantitative claims (e.g., compliance dropping from 88% to 13%, retention of nearly all clean text) are presented without the full experimental details, data exclusion rules, baseline comparisons, or exact protocols for measuring injection compliance and span filtering. This directly affects assessment of whether post-hoc choices influence the reported fragility and mitigation efficacy.
- [Introduction, experiments] The claim that the generation step is inherently fragile (rather than fragile under the evaluated conditions) rests on the untested assumption that selection biases, compliance rates, and mitigation success generalize beyond the specific model families, document collections, and evaluation setups used. No cross-regime experiments or sensitivity analyses are reported to support this extrapolation.
minor comments (1)
- Notation for compliance rates and filtering thresholds should be defined more explicitly when first introduced to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the opportunity to clarify our work. We address each major comment below with point-by-point responses, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract, results] Abstract and results sections: the central quantitative claims (e.g., compliance dropping from 88% to 13%, retention of nearly all clean text) are presented without the full experimental details, data exclusion rules, baseline comparisons, or exact protocols for measuring injection compliance and span filtering. This directly affects assessment of whether post-hoc choices influence the reported fragility and mitigation efficacy.
Authors: We agree that the abstract and main results present the quantitative findings in summarized form. The complete experimental protocols—including the specific model families and scales tested, document collections, precise definition and measurement of injection compliance (rate of following embedded instruction-like passages), span filtering criteria, data exclusion rules, and baseline comparisons—are provided in the Methods section and Appendix. To improve accessibility, we will expand the abstract with a brief note on the evaluation regime and insert a concise protocol summary table or paragraph in the Results section. This revision will not change the reported numbers or conclusions. revision: yes
-
Referee: [Introduction, experiments] The claim that the generation step is inherently fragile (rather than fragile under the evaluated conditions) rests on the untested assumption that selection biases, compliance rates, and mitigation success generalize beyond the specific model families, document collections, and evaluation setups used. No cross-regime experiments or sensitivity analyses are reported to support this extrapolation.
Authors: The manuscript frames the observed fragility as an empirical finding within the tested regimes, with all quantitative results explicitly qualified as 'in our evaluation.' We do not claim parameter-free universality. The patterns (early saturation, prompt convergence, artifact hijacking, and instruction compliance) were consistent across the model families and document sets examined. We acknowledge the absence of broad cross-regime sensitivity analyses. We will revise the Introduction and add a Limitations section to explicitly bound the claims to the evaluated conditions and note that further validation across additional regimes would be valuable. revision: partial
Circularity Check
No circularity: purely empirical measurements with no derivations or self-referential fits
full rationale
The paper reports experimental measurements of selection biases, compliance rates, and mitigation effects in QA generation across models and documents. No equations, fitted parameters, or derivations are present that could reduce reported outcomes to quantities defined by the paper's own inputs. Claims rest on direct observation rather than any self-definitional, fitted-prediction, or self-citation chain. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lisa Adams, Felix Busch, Tianyu Han, Jean-Baptiste Excoffier, Matthieu Ortala, Alexander Löser, Hugo JWL Aerts, Jakob Nikolas Kather, Daniel Truhn, and Keno Bressem. Longhealth: A question answering benchmark with long clinical documents.arXiv preprint arXiv:2401.14490, 2024. URLhttps://arxiv.org/abs/2401 .14490
-
[2]
Physics of language models: Part 3.1, knowledge storage and extraction
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.1, knowledge storage and extraction. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. URLhttps: //arxiv.org/abs/2309.14316
-
[3]
InPars: Unsupervised dataset generation for information retrieval
Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, and Rodrigo Nogueira. InPars: Unsupervised dataset generation for information retrieval. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2387–2392, 2022. URLhttps://arxiv.org/ab s/2202.05144
-
[4]
Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tramèr. Poisoning web-scale training datasets is practical. In2024 IEEE Symposium on Security and Privacy (SP), pages 407–425, 2024. URLhttps: //arxiv.org/abs/2302.10149
-
[5]
StruQ: Defending against prompt injection with structured queries
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. StruQ: Defending against prompt injection with structured queries. In34th USENIX Security Symposium (USENIX Security 25), pages 2383–2400, 2025. URLhttps://arxiv.org/abs/2402.06363
-
[6]
Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith B
Zhuyun Dai, Vincent Y. Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith B. Hall, and Ming-Wei Chang. Promptagator: Few-shot dense retrieval from 8 examples.arXiv preprint arXiv:2209.11755, 2022. URLhttps://arxiv.org/abs/2209.11755
-
[7]
Smith, and Matt Gardner
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4599–4610. Association for Computation...
2021
-
[8]
Sabri Eyuboglu, Ryan Ehrlich, Simran Arora, Neel Guha, Dylan Zinsley, Emily Liu, Will Tennien, Atri Rudra, James Zou, Azalia Mirhoseini, and Christopher Ré. Cartridges: Lightweight and general-purpose long context 10 representations via self-study.arXiv preprint arXiv:2506.06266, 2025. URLhttps://arxiv.org/abs/2506 .06266
-
[9]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. URLhttps://arxiv.or g/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Aaron Grattafiori et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec), pages 79–90, 2023. URLhttps://arxiv.org/abs/2302.12173
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Seungju Han, Konwoo Kim, Chanwoo Park, Benjamin Newman, Suhas Kotha, Jaehun Jung, James Zou, and Yejin Choi. Synthetic mixed training: Scaling parametric knowledge acquisition beyond rag.arXiv preprint arXiv:2603.23562, 2026. URLhttps://arxiv.org/abs/2603.23562
-
[13]
Cartridges at Scale: Training Modular KV Caches over Large Document Collections
Momchil Hardalov, Gonzalo Iglesias, and Adrià de Gispert. Cartridges at scale: Training modular kv caches over large document collections.arXiv preprint arXiv:2606.04557, 2026. URLhttps://arxiv.org/abs/26 06.04557
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. Defending against indirect prompt injection attacks with spotlighting.arXiv preprint arXiv:2403.14720, 2024. URL https://arxiv.org/abs/2403.14720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Unnaturalinstructions: Tuninglanguagemodels with(almost)nohumanlabor
OrHonovich,ThomasScialom,OmerLevy,andTimoSchick. Unnaturalinstructions: Tuninglanguagemodels with(almost)nohumanlabor. InProceedingsofthe61stAnnualMeetingoftheAssociationforComputational Linguistics (Volume 1: Long Papers), pages 14409–14428, 2023. URLhttps://aclanthology.org/2023. acl-long.806
2023
-
[16]
Vitor Jeronymo, Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, Roberto Lotufo, Jakub Zavrel, and Rodrigo Nogueira. InPars-v2: Large language models as efficient dataset generators for information retrieval.arXiv preprint arXiv:2301.01820, 2023. URLhttps://arxiv.org/abs/2301.01820
-
[17]
Knowledgeinjectionviapromptdistillation.arXivpreprint arXiv:2412.14964, 2024
KalleKujanpää, HarriValpola, andAlexanderIlin. Knowledgeinjectionviapromptdistillation.arXivpreprint arXiv:2412.14964, 2024. URLhttps://arxiv.org/abs/2412.14964
-
[18]
Learning facts at scale with active reading.arXiv preprint arXiv:2508.09494, 2025
Jessy Lin, Vincent-Pierre Berges, Xilun Chen, Wen-Tau Yih, Gargi Ghosh, and Barlas Oğuz. Learning facts at scale with active reading.arXiv preprint arXiv:2508.09494, 2025. URLhttps://arxiv.org/abs/2508.094 94
-
[19]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. URLhttps://aclanthology.org/2024.tacl-1.9
2024
-
[20]
Ruibo Liu, Jerry Wei, Fangyu Liu, Chenglei Si, Yanzhe Zhang, Jinmeng Rao, Steven Zheng, Daiyi Peng, Diyi Yang, Denny Zhou, and Andrew M. Dai. Best practices and lessons learned on synthetic data for language models.arXiv preprint arXiv:2404.07503, 2024. URLhttps://arxiv.org/abs/2404.07503
-
[21]
LIFT: A Novel Framework for Enhancing Long-Context Understanding of LLMs via Long Input Fine-Tuning
Yansheng Mao, Yufei Xu, Jiaqi Li, Fanxu Meng, Haotong Yang, Zilong Zheng, Xiyuan Wang, and Muhan Zhang. Lift: Improving long context understanding of large language models through long input fine-tuning. arXiv preprint arXiv:2502.14644, 2025. URLhttps://arxiv.org/abs/2502.14644. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Ignore Previous Prompt: Attack Techniques For Language Models
Fábio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527, 2022. URLhttps://arxiv.org/abs/2211.09527. NeurIPS 2022 ML Safety Workshop
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Fine-tuned deberta-v3-base for prompt injection detection, 2024
ProtectAI.com. Fine-tuned deberta-v3-base for prompt injection detection, 2024. URLhttps://huggingfac e.co/ProtectAI/deberta-v3-base-prompt-injection-v2
2024
-
[24]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URLhttps://arxiv.org/ab s/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
ARES: An automated evaluation framework for retrieval-augmented generation systems
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. ARES: An automated evaluation framework for retrieval-augmented generation systems. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 338–354. Association for Computational Linguistics, ...
2024
-
[26]
Quantifying language models’ sensitivity to spuriousfeaturesinpromptdesignor: Howilearnedtostartworryingaboutpromptformatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spuriousfeaturesinpromptdesignor: Howilearnedtostartworryingaboutpromptformatting. InTheTwelfth International Conference on Learning Representations (ICLR), 2024. URLhttps://arxiv.org/abs/2310 .11324
2024
-
[27]
Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, et al. Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
-
[28]
Ontheexploitability of instruction tuning
ManliShu,JiongxiaoWang,ChenZhu,JonasGeiping,ChaoweiXiao,andTomGoldstein. Ontheexploitability of instruction tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://arxiv.org/abs/2306.17194
-
[29]
AI models collapse when trained on recursively generated data.Nature, 631(8022):755–759, 2024
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. AI models collapse when trained on recursively generated data.Nature, 631(8022):755–759, 2024. doi: 10.1038/s41586-024-07566-y. URLhttps://doi.org/10.1038/s41586-024-07566-y
-
[30]
Parametric retrieval augmented generation.arXiv preprint arXiv:2501.15915, 2025
Weihang Su, Yichen Tang, Qingyao Ai, Junxi Yan, Changyue Wang, Hongning Wang, Ziyi Ye, Yujia Zhou, and Yiqun Liu. Parametric retrieval augmented generation.arXiv preprint arXiv:2501.15915, 2025. URL https://arxiv.org/abs/2501.15915
-
[31]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following LLaMA model.https://github.com/t atsu-lab/stanford_alpaca, 2023
2023
-
[32]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training LLMs to prioritize privileged instructions.arXiv preprint arXiv:2404.13208, 2024. URL https://arxiv.org/abs/2404.13208
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484–13508, 2023. URLhttps://aclanthology.org/20...
2023
-
[34]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. WizardLM: Empowering large language models to follow complex instructions.arXiv preprint arXiv:2304.12244, 2023. URLhttps://arxiv.org/abs/2304.12244. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025. URLhttps://arxiv.org/ abs/2406.08464
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Backdooring instruction-tuned large language models with virtual prompt injection
Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, and Hongxia Jin. Backdooring instruction-tuned large language models with virtual prompt injection. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: L...
2024
-
[37]
Synthetic continued pretraining.arXiv preprint arXiv:2409.07431, 2024
Zitong Yang, Neil Band, Shuangping Li, Emmanuel Candès, and Tatsunori Hashimoto. Synthetic continued pretraining.arXiv preprint arXiv:2409.07431, 2024. URLhttps://arxiv.org/abs/2409.07431
-
[38]
Asaf Yehudai, Boaz Carmeli, Yosi Mass, Ofir Arviv, Nathaniel Mills, Assaf Toledo, Eyal Shnarch, and Leshem Choshen. Genie: Achieving human parity in content-grounded datasets generation.arXiv preprint arXiv:2401.14367, 2024. URLhttps://arxiv.org/abs/2401.14367
- [39]
-
[40]
InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, 2024
QiusiZhan,ZhixiangLiang,ZifanYing,andDanielKang.InjecAgent: Benchmarkingindirectpromptinjections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, 2024. URLhttps://aclanthology.org/2024.findings-acl.624
2024
-
[41]
PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models. In34th USENIX Security Symposium (USENIX Security 25), pages 3827–3844, 2025. URLhttps://arxiv.org/abs/2402.07867
-
[42]
Self-adaptinglanguage models.arXiv preprint arXiv:2506.10943, 2025
AdamZweiger,JyothishPari,HanGuo,EkinAkyürek,YoonKim,andPulkitAgrawal. Self-adaptinglanguage models.arXiv preprint arXiv:2506.10943, 2025. URLhttps://arxiv.org/abs/2506.10943
-
[43]
Fast KV Compaction via Attention Matching
Adam Zweiger, Xinghong Fu, Han Guo, and Yoon Kim. Fast kv compaction via attention matching.arXiv preprint arXiv:2602.16284, 2026. URLhttps://arxiv.org/abs/2602.16284. 13 Appendix Supplementary Materials forSelf-Study Reconsidered: The Hidden Fragility of Learning from Self-Generated QA Contents 1 Introduction 1 2 Related Work 2 3 Question Generation as E...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Use only exact substrings from the source text
-
[45]
Do not select the whole chunk unless the question truly asks about the whole chunk
-
[46]
Return at most 3 support spans ; prefer the smallest sufficient set
-
[47]
For factual questions , select the minimal answer - support span
-
[48]
Ignore decorative file paths , document IDs , or corpus labels unless the requested content is absent from the source text
For summarization or structuring questions : if the named section , topic , or passage appears in the source text , return grounded = true with the relevant span ( s ) . Ignore decorative file paths , document IDs , or corpus labels unless the requested content is absent from the source text
-
[49]
how can I use
For use - case or creative questions : if the question applies , discusses , or is inspired by concepts , methods , or claims present in the source text , return grounded = true with concept_support spans -- even when phrased generically or hypothetically ( e . g . " how can I use ..." , " what inspired ..." , " key differences ...")
-
[50]
LaTeX macros count as grounded support when the question refers to them and their definitions or usages appear in the source text
-
[51]
hallucinated
Return grounded = false with reason =" hallucinated " only when the question clearly cannot be anchored in the source text : no relevant section / topic / entity / concept from the question appears in the chunk , or the question asks about specific facts absent from the chunk
-
[52]
hallucinated
If the question refers to a section title , entity , or document name that does not appear anywhere in the source text and is not a LaTeX macro defined in the chunk , return grounded = false with reason =" hallucinated ". 15
-
[53]
un fi ll ed _te mp la te
If the question contains unfilled placeholders like {{ subsection }} or {{ document }} , return grounded = false with reason =" un fi ll ed _te mp la te ". Return only JSON : { " grounded ": true , " support_spans ": [ { " quote ": " exact substring from the source text " , " role ": " answer_support | s u m m a r i z a t i o n _ t a r g e t | s t ru c t ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.