ProSarc: Prosody-Aware Sarcasm Recognition Framework via Temporal Prosodic Incongruity
Pith reviewed 2026-06-28 01:17 UTC · model grok-4.3
The pith
Sarcasm in speech arises from mismatch between local prosodic changes and the utterance's overall emotional baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
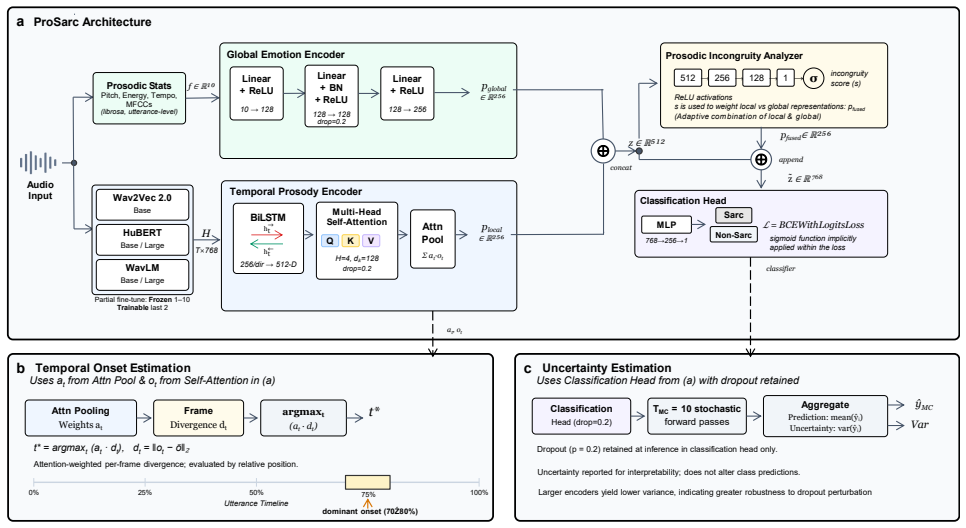
The paper claims that sarcasm manifests as temporal prosodic incongruity—the mismatch between local prosodic dynamics and the utterance-level emotional baseline—and that dual encoding paths feeding a Prosodic Incongruity Analyzer can produce a scalar score enabling accurate classification of sarcastic speech from audio alone.
What carries the argument
The Prosodic Incongruity Analyzer, which takes outputs from a Global Emotion Encoder and a Temporal Prosody Encoder (BiLSTM plus multi-head attention) to compute a scalar incongruity score used for classification.
If this is right
- The approach yields higher performance than prior audio-only methods on the MUStARD++ dataset.
- It extends to spontaneous speech on PodSarc and cross-lingual speech on MuSaG.
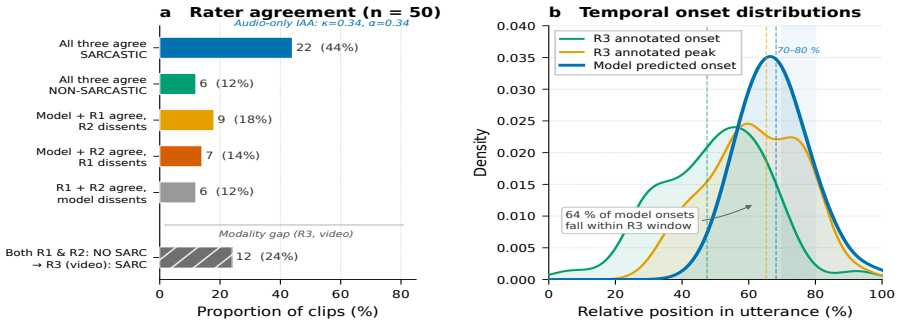
- Monte Carlo dropout uncertainty estimates align with human ratings of perceptual ambiguity.
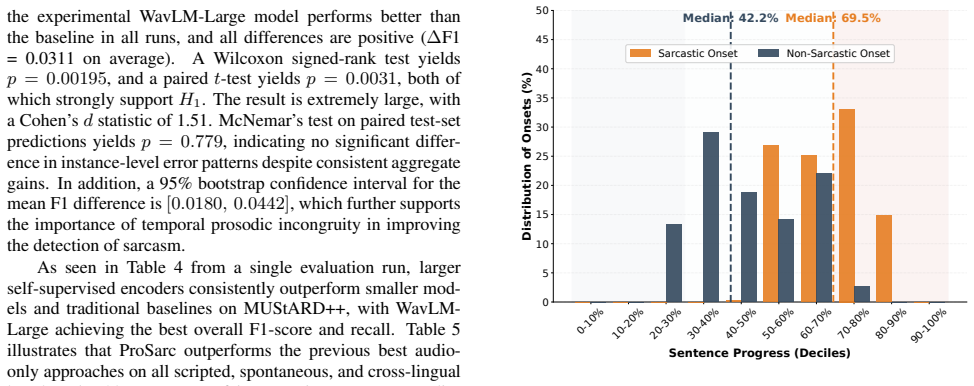
- An attention mechanism localizes sarcastic onset in the utterance without frame-level labels.
- Repeated statistical tests confirm the specific role of incongruity modeling in the results.
Where Pith is reading between the lines
- The same mismatch calculation could be tested on other speech phenomena that involve emotional inconsistency, such as irony or polite deception.
- Onset localization might support real-time tools that flag confusing moments during live voice calls or meetings.
- Cross-dataset success suggests prosodic incongruity features may require little language-specific tuning.
- Adding the audio score to existing text-based sarcasm systems could create stronger multimodal detectors.
Load-bearing premise
The scalar incongruity score produced from the dual encoding paths accurately reflects sarcasm through temporal mismatch, without independent validation of the global emotional baseline or frame-level grounding.
What would settle it
A collection of human-labeled sarcastic and non-sarcastic utterances where the model's incongruity scores show no reliable difference between the groups, or where the attention-highlighted onsets fail to overlap with human-annotated sarcastic windows.
Figures

read the original abstract
We present ProSarc, an audio-only framework that detects sarcasm by modelling temporal prosodic incongruity, that is, the mismatch between local prosodic dynamics and the utterance-level emotional baseline. Dual encoding paths, a Global Emotion Encoder and a Temporal Prosody Encoder (BiLSTM + multi-head attention), feed a Prosodic Incongruity Analyzer that produces a scalar incongruity score for classification. Monte Carlo dropout provides uncertainty estimates, and an attention-based mechanism localises sarcastic onset without frame-level labels. ProSarc outperforms prior audio-only methods on MUStARD++ (F1=75.3) and generalises to spontaneous (PodSarc, F1=62.9) and cross-lingual speech (MuSaG, F1=65.6). Ten-run validation confirms the contribution of incongruity modelling (Wilcoxon p=0.002, Cohen's d=1.51). Human evaluation shows that model uncertainty tracks perceptual ambiguity and predicted onsets align with human-annotated temporal windows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ProSarc, an audio-only sarcasm detection framework that models temporal prosodic incongruity as the mismatch between an utterance-level emotional baseline (Global Emotion Encoder) and local prosodic dynamics (Temporal Prosody Encoder using BiLSTM + multi-head attention). These feed a Prosodic Incongruity Analyzer producing a scalar score for classification, with Monte Carlo dropout for uncertainty and attention for onset localization. It reports F1=75.3 on MUStARD++, generalization to PodSarc (F1=62.9) and MuSaG (F1=65.6), ten-run statistical validation of the incongruity component (Wilcoxon p=0.002, Cohen's d=1.51), and human evaluation alignment.
Significance. If the incongruity mechanism is shown to be specifically grounded rather than a proxy for general prosodic features, the work would offer a concrete advance in interpretable audio-only sarcasm detection with cross-dataset and cross-lingual generalization. The reported statistical tests and human evaluations are positive indicators of robustness, but the absence of direct validation for the scalar score weakens the mechanistic claim.
major comments (2)
- [Abstract / Prosodic Incongruity Analyzer description] Abstract and implied Methods: The central claim requires that the scalar output of the Prosodic Incongruity Analyzer specifically encodes sarcasm via mismatch between the Global Emotion Encoder baseline and Temporal Prosody Encoder dynamics. No independent validation is described (e.g., correlation of the score with human incongruity ratings, ablation isolating baseline computation, or comparison to non-sarcastic prosodic variation), so performance gains could arise from encoder capacity alone rather than the claimed mechanism.
- [Abstract] Abstract: The ten-run validation and Wilcoxon test are cited to confirm the contribution of incongruity modelling, yet without details on the exact ablation (e.g., which component is removed or how the scalar is computed in the control condition) it is impossible to verify that the test isolates the temporal mismatch rather than other model differences.
minor comments (1)
- [Abstract] Abstract: Dataset splits, error bars on F1 scores, and exact training details are not mentioned, which would aid reproducibility even if not load-bearing.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. Below we provide point-by-point responses to the major comments, indicating where revisions will be made to address the concerns about validation and ablation details.
read point-by-point responses
-
Referee: [Abstract / Prosodic Incongruity Analyzer description] Abstract and implied Methods: The central claim requires that the scalar output of the Prosodic Incongruity Analyzer specifically encodes sarcasm via mismatch between the Global Emotion Encoder baseline and Temporal Prosody Encoder dynamics. No independent validation is described (e.g., correlation of the score with human incongruity ratings, ablation isolating baseline computation, or comparison to non-sarcastic prosodic variation), so performance gains could arise from encoder capacity alone rather than the claimed mechanism.
Authors: The referee correctly notes the absence of direct independent validation for the scalar score. While the ten-run statistical validation and human evaluation provide supporting evidence, we agree that this could be strengthened. We will revise the manuscript to include additional ablation details isolating the baseline computation and discuss the limitations of the current validation approach. revision: partial
-
Referee: [Abstract] Abstract: The ten-run validation and Wilcoxon test are cited to confirm the contribution of incongruity modelling, yet without details on the exact ablation (e.g., which component is removed or how the scalar is computed in the control condition) it is impossible to verify that the test isolates the temporal mismatch rather than other model differences.
Authors: We will provide expanded details in the revised manuscript on the exact ablation procedure, specifying the removed components and the computation of the scalar in the control condition to demonstrate that it isolates the temporal mismatch. revision: yes
Circularity Check
No significant circularity; model outputs are derived from architecture and validated externally
full rationale
The provided abstract and description show a standard neural architecture (Global Emotion Encoder + Temporal Prosody Encoder feeding Prosodic Incongruity Analyzer) whose scalar output is used for downstream classification and evaluated on held-out benchmarks (MUStARD++, PodSarc, MuSaG) with statistical tests. No equations, fitted-parameter-as-prediction steps, or self-citation chains are quoted that would make the incongruity score equivalent to its inputs by construction. The derivation chain remains self-contained against external data and does not reduce to renaming or self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Sarcasm in spoken language is conveyed largely through prosodic cues, including pitch contour, timing, and intensity, rather than through lexical markers alone [1, 2, 3]. While mul- timodal systems that fuse text, audio, and vision have advanced sarcasm detection on benchmarks such as MUStARD++ [4, 5], audio is typically treated as an auxilia...
-
[2]
We propose an audio-only sarcasm detection framework that explicitlymodels temporal prosodic incongruity between lo- cal dynamics and a global emotional baseline, rather than relying on implicit temporal encoding or the utterance-level statistics
-
[3]
We introduce a weak-supervision mechanism for tempo- ral sarcasm onset estimation using attention-weighted per- frame divergence, providing an interpretable temporal anal- ysis without requiring fine-grained annotations
-
[4]
We evaluate on four benchmarks spanning scripted, sponta- neous, and cross-lingual settings, demonstrating consistent improvements over prior audio-only methods with rigorous statistical validation (Wilcoxonp=0.002, Cohen’sd=1.51)
-
[5]
We incorporate MC dropout uncertainty estimation and vali- date through human evaluation that model confidence tracks perceptual ambiguity: predicted uncertainty identifies a zone of genuine inter-annotator disagreement (κ=0.34), and a monotonic confidence gradient aligns with human consen- sus
-
[6]
Related Work Prosodic Foundations of SarcasmPsycholinguistic evidence establishes that sarcasm is signalled through characteristic prosodic patterns. Rockwell [1] showed that sarcastic speech exhibits lower pitch, slower rate, and greater intensity relative to sincere utterances. Cheang and Pell [2] extended this find- ing cross-linguistically, identifyin...
Pith/arXiv arXiv 2026
-
[7]
Methodology Given an audio utteranceAwith labely∈ {0,1}, ProSarc predicts sarcasm from audio alone. Our main hypothesis is that sarcasm appears in the form oftemporal prosodic incongruity which refers to utterance-wise prosodic trends that differ from the computed emotional baseline. As illustrated in Figure 1, the model encodes audio through two parallel...
2022
-
[8]
Datasets We evaluate ProSarc on four sarcasm benchmarks covering scripted, spontaneous, and cross-lingual settings (Table 3)
Experimental Setup 4.1. Datasets We evaluate ProSarc on four sarcasm benchmarks covering scripted, spontaneous, and cross-lingual settings (Table 3). MUStARD and MUStARD++ consist of short English clips from scripted television dialogues [4, 5]. PodSarc contains spontaneous podcast speech with greater acoustic variability and weaker prosodic exaggeration ...
-
[9]
with context
Results and Analysis 5.1. Main Results The performance of the proposed ProSarc is summarized in Ta- ble 2. ProSarc achieves its strong performance on the MUS- tARD dataset, with an accuracy of 74.4% and an F1-score of 77.0%, and on MUStARD++ (73.3% and 75.3%), which are scripted TV dialogue dataset. The performance on sponta- neous datasets such as PodSar...
2023
-
[10]
Conclusion We presented ProSarc, an audio-only framework that models sarcasm as temporal prosodic incongruity between local dy- namics and a global emotional baseline. On MUStARD++ (F1 = 75.3), ProSarc outperforms prior audio-only methods, and generalises to spontaneous speech (PodSarc, F1 = 62.9) and cross-lingual data (MuSaG, F1 = 65.6), with statistica...
-
[11]
No generative AI was used to produce the research ideas, experimental design, code, analyses, results, or scientific claims, which are entirely the authors’ own
Generative AI Use Disclosure The authors used LLM-based tool (ChatGPT) solely for edito- rial assistance: improving clarity, grammar, conciseness, and stylistic consistency of the manuscript text. No generative AI was used to produce the research ideas, experimental design, code, analyses, results, or scientific claims, which are entirely the authors’ own...
-
[12]
Spectral Deferred Correction Methods for Ordinary Differential Equations
P. Rockwell, “Lower, slower, louder: V ocal cues of sarcasm,” Journal of Psycholinguistic Research, vol. 29, no. 5, pp. 483–495, 2000. [Online]. Available: https://doi.org/10.1023/A: 1005120109296
work page doi:10.1023/a: 2000
-
[13]
Acoustic markers of sarcasm in cantonese and english,
H. S. Cheang and M. D. Pell, “Acoustic markers of sarcasm in cantonese and english,”The Journal of the Acoustical Society of America, vol. 126, no. 3, pp. 1394–1405, 09 2009. [Online]. Available: https://doi.org/10.1121/1.3177275
-
[14]
Prosodic contrasts in ironic speech,
G. A. Bryant, “Prosodic contrasts in ironic speech,”Discourse Processes, vol. 47, no. 7, pp. 545–566, 2010. [Online]. Available: https://doi.org/10.1080/01638530903531972
-
[15]
A multimodal corpus for emotion recognition in sarcasm,
A. Ray, S. Mishra, A. Nunna, and P. Bhattacharyya, “A multimodal corpus for emotion recognition in sarcasm,” inPro- ceedings of the Thirteenth Language Resources and Evaluation Conference. Marseille, France: European Language Resources Association, Jun. 2022, pp. 6992–7003. [Online]. Available: https://aclanthology.org/2022.lrec-1.756/
2022
-
[16]
Towards multimodal sarcasm detection (an Obviously perfect paper),
S. Castro, D. Hazarika, V . P ´erez-Rosas, R. Zimmermann, R. Mihalcea, and S. Poria, “Towards multimodal sarcasm detection (an Obviously perfect paper),” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M `arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul. 2...
2019
-
[17]
MELD: A multimodal multi-party dataset for emotion recognition in conversations,
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihalcea, “MELD: A multimodal multi-party dataset for emotion recognition in conversations,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M `arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul...
2019
-
[18]
Speech emotion recognition: two decades in a nutshell, benchmarks, and ongoing trends,
B. W. Schuller, “Speech emotion recognition: two decades in a nutshell, benchmarks, and ongoing trends,”Commun. ACM, vol. 61, no. 5, p. 90–99, Apr. 2018. [Online]. Available: https://doi.org/10.1145/3129340
-
[19]
Deep cnn-based inductive trans- fer learning for sarcasm detection in speech,
X. Gao, S. Nayak, and M. Coler, “Deep cnn-based inductive trans- fer learning for sarcasm detection in speech,” inProc. Interspeech 2022, 09 2022, pp. 2323–2327
2022
-
[20]
Atten- tion is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Atten- tion is all you need,” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017. [Online]. Avail- able: https:...
2017
-
[21]
Dropout as a bayesian approxima- tion: Representing model uncertainty in deep learning,
Y . Gal and Z. Ghahramani, “Dropout as a bayesian approxima- tion: Representing model uncertainty in deep learning,”Proceed- ings of The 33rd International Conference on Machine Learning, 06 2015
2015
-
[22]
Are You Being Sar- castic? Prosodic Cues to Irony Perception in German,
S. F ¨unfgeld, A. Braun, and K. Zahner-Ritter, “Are You Being Sar- castic? Prosodic Cues to Irony Perception in German,” inInter- speech 2025, 2025, pp. 5373–5377
2025
-
[23]
A functional trade-off between prosodic and semantic cues in conveying sar- casm,
Z. Li, X. Gao, Y . Zhang, S. Nayak, and M. Coler, “A functional trade-off between prosodic and semantic cues in conveying sar- casm,” inProc. Interspeech 2024, 2024, pp. 1070–1074
2024
-
[24]
ACM Computing Surveys 50(5):1--22
A. Joshi, P. Bhattacharyya, and M. J. Carman, “Automatic sarcasm detection: A survey,”ACM Comput. Surv., vol. 50, no. 5, Sep. 2017. [Online]. Available: https://doi.org/10.1145/3124420
-
[25]
Fracking sarcasm using neural network,
A. Ghosh and T. Veale, “Fracking sarcasm using neural network,” inProceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, A. Balahur, E. van der Goot, P. V ossen, and A. Montoyo, Eds. San Diego, California: Association for Computational Linguistics, Jun. 2016, pp. 161–169. [Online]. Available: http...
2016
-
[26]
A large self- annotated corpus for sarcasm,
M. Khodak, N. Saunshi, and K. V odrahalli, “A large self- annotated corpus for sarcasm,” inProceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), N. Calzolari, K. Choukri, C. Cieri, T. Declerck, S. Goggi, K. Hasida, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, S. Piperidis, and T. Tokun...
2018
-
[27]
Zico and Morency, Louis-Philippe and Salakhutdinov, Ruslan
Y . H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L. Morency, and R. Salakhutdinov, “Multimodal transformer for unaligned multimodal language sequences,” inProceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, A. Korhonen, D. R. Traum, and L. M `arquez,...
-
[28]
Spoken in jest, detected in earnest: A systematic review of sar- casm recognition—multimodal fusion, challenges, and fu- ture prospects,
X. Gao, S. Nayak, and M. Coler, “Spoken in jest, detected in earnest: A systematic review of sar- casm recognition—multimodal fusion, challenges, and fu- ture prospects,”IEEE Transactions on Affective Comput- ing, vol. 16, pp. 2526–2544, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:281194741
2025
-
[29]
Intra-modal relation and emotional incongruity learning using graph attention networks for multimodal sarcasm detection,
D. Raghuvanshi, X. Gao, Z. Li, S. Bansal, M. Coler, N. Kumar, and S. Nayak, “Intra-modal relation and emotional incongruity learning using graph attention networks for multimodal sarcasm detection,”ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, 2025. [Online]. Available: https://api.semantics...
2025
-
[30]
Leveraging Large Language Models for Sarcastic Speech Annotation in Sar- casm Detection,
Z. Li, Y . Zhang, X. Gao, S. Nayak, and M. Coler, “Leveraging Large Language Models for Sarcastic Speech Annotation in Sar- casm Detection,” inInterspeech 2025, 2025, pp. 3973–3977
2025
-
[31]
Musag: A multimodal german sarcasm dataset with full-modal annotations,
A. Scott, M. Z ¨ufle, and J. Niehues, “Musag: A multimodal german sarcasm dataset with full-modal annotations,”ArXiv, vol. abs/2510.24178, 2025. [Online]. Available: https://api. semanticscholar.org/CorpusID:282400655
arXiv 2025
-
[32]
Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network,
G. Trigeorgis, F. Ringeval, R. Brueckner, E. Marchi, M. A. Nico- laou, B. Schuller, and S. Zafeiriou, “Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network,” in2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 5200–5204
2016
-
[33]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” inProceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY , USA: Curran Associates Inc., 2017, p. 6405–6416
2017
-
[34]
What uncertainties do we need in bayesian deep learning for computer vision?
A. Kendall and Y . Gal, “What uncertainties do we need in bayesian deep learning for computer vision?” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017. [Online]. Available: https://proceedings.neurips.cc/paper file...
2017
-
[35]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 12 449–12 460. [Online]. Available: https://proceedings.neur...
2020
-
[36]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W. Hsu, B. Bolte, Y . H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE ACM Trans. Audio Speech Lang. Process., vol. 29, pp. 3451–3460,
-
[37]
Available: https://doi.org/10.1109/TASLP.2021
[Online]. Available: https://doi.org/10.1109/TASLP.2021. 3122291
-
[38]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[39]
Information sieve: Content leakage reduction in end-to-end prosody transfer for ex- pressive speech synthesis,
X. Dai, C. Gong, L. Wang, and K. Zhang, “Information sieve: Content leakage reduction in end-to-end prosody transfer for ex- pressive speech synthesis,” inInterspeech 2021, 2021, pp. 131– 135
2021
-
[40]
An automated approach to identify sarcasm in low- resource language,
S. Khan, I. Qasim, W. Khan, A. Khan, J. Khan, A. Qahmash, and Y . Ghadi, “An automated approach to identify sarcasm in low- resource language,”PLOS ONE, vol. 19, 12 2024
2024
-
[41]
The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,
F. Eyben, K. R. Scherer, B. W. Schuller, J. Sundberg, E. Andr ´e, C. Busso, L. Y . Devillers, J. Epps, P. Laukka, S. S. Narayanan, and K. P. Truong, “The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,”IEEE Transactions on Affective Computing, vol. 7, no. 2, pp. 190–202, 2016
2016
-
[42]
Emotion Recognition from Speech Using wav2vec 2.0 Embeddings,
L. Pepino, P. Riera, and L. Ferrer, “Emotion Recognition from Speech Using wav2vec 2.0 Embeddings,” inInterspeech 2021, 2021, pp. 3400–3404
2021
-
[43]
Comparison of deep learning models for automatic detection of sarcasm context on the MUStARD dataset,
A.-C. B ˘aroiu and S ¸. Tr ˘aus ¸an-Matu, “Comparison of deep learning models for automatic detection of sarcasm context on the MUStARD dataset,”Electronics, vol. 12, no. 3, 2023. [Online]. Available: https://www.mdpi.com/2079-9292/12/3/666
2023
-
[44]
X. Gao, S. Bansal, K. Gowda, Z. Li, S. Nayak, N. Kumar, and M. Coler, “Amused: An attentive deep neural network for multimodal sarcasm detection incorporating bi-modal data augmentation,”CoRR, vol. abs/2412.10103, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2412.10103
-
[45]
Sarcasm in Sight and Sound: Benchmarking and Expansion to Improve Multimodal Sarcasm Detection,
S. Bhosale, A. Chaudhuri, A. L. R. Williams, D. Tiwari, A. Dutta, X. Zhu, P. Bhattacharyya, and D. Kanojia, “Sarcasm in Sight and Sound: Benchmarking and Expansion to Improve Multimodal Sarcasm Detection,”arXiv e-prints, p. arXiv:2310.01430, Sep. 2023
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.