Segment-level Tree Search for Long Meeting Document Summarization
Pith reviewed 2026-06-27 18:49 UTC · model grok-4.3
The pith
A 7B model using segment-level Monte Carlo tree search matches 72B models on long meeting summarization while producing length-appropriate outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
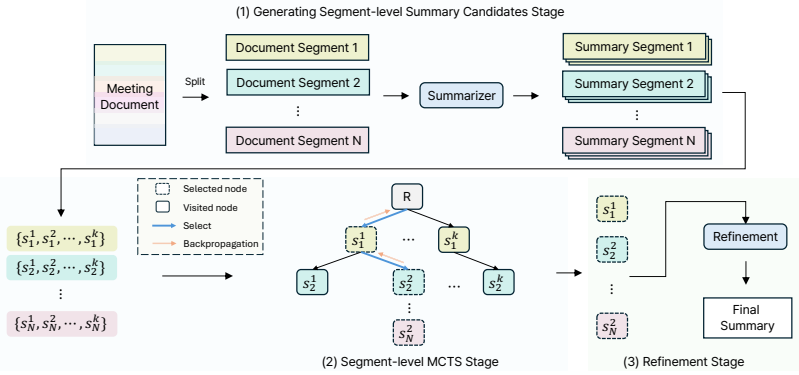
S3 partitions a long meeting document into segments, creates multiple summary candidates per segment as nodes in a search tree, applies self-reward-guided Monte Carlo tree search to identify the highest-scoring combination, and refines that combination into the final summary; the resulting output matches the quality of much larger models while remaining training-free and length-appropriate.
What carries the argument
Monte Carlo tree search over per-segment summary candidates, scored by the generating model's own self-reward signals.
If this is right
- Segment-level candidate generation plus search replaces end-to-end generation and reduces cumulative error from early extraction stages.
- The same 7B model reaches parity with 72B models on meeting summarization benchmarks.
- Summaries produced this way better match reference lengths than direct generation approaches.
- No task-specific training or external preference data is required for the method to function.
- The framework can be applied directly to other long conversational documents beyond meetings.
Where Pith is reading between the lines
- Similar segment-and-search composition may allow smaller models to handle other long-form generation tasks without scaling model size.
- If self-reward proves unreliable on certain meeting types, hybrid scoring with lightweight external checks could be added without retraining.
- The method implies that explicit search over local decisions can substitute for global context modeling in long documents.
- Testing S3 on non-meeting long documents such as transcripts or reports would reveal how far the segment-tree approach generalizes.
Load-bearing premise
Self-reward scores from the same model reliably identify good combinations of segment summaries, and fixed segment boundaries do not remove essential cross-segment context required for overall coherence.
What would settle it
Human or stronger-model evaluation showing that S3 summaries lose coherence across segment boundaries or that self-reward rankings fail to predict actual summary quality when compared against external metrics.
Figures
read the original abstract
Meeting documents are challenging to summarize due to their length and complex conversational structure. Existing approaches typically adopt multi-stage pipelines that extract information prior to summarization; however, these approaches often suffer from cumulative error propagation without intermediate validation, a limitation further amplified by short and low-quality reference summaries. We propose segment-level summarization via Monte Carlo Tree Search (S3), a training-free framework that constructs a final summary by composing segment-level summary candidates. S3 partitions a long document into segments and generates multiple summary candidates per segment, forming nodes of a search tree. The best-scoring combination is selected via self-reward-guided tree search and refined into the final output. Despite using a 7B model, S3 achieves performance comparable to larger 72B models while producing length-appropriate summaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes S3, a training-free framework for summarizing long meeting documents. It partitions the input into segments, generates multiple candidate summaries per segment using a 7B model, builds a search tree over combinations, and selects the best path via Monte Carlo tree search guided by self-reward scores from the same model. The final summary is refined from the selected combination. The central claim is that this yields performance comparable to 72B models while producing length-appropriate outputs and avoiding cumulative errors from multi-stage pipelines.
Significance. If the self-reward reliably ranks segment combinations and the resulting summaries are coherent, the approach would demonstrate that smaller models can match much larger ones on long-document tasks through algorithmic composition rather than scale or training. The training-free design and explicit handling of segment-level candidates are strengths that could influence efficient inference methods in summarization.
major comments (3)
- [§3.3] §3.3 (Self-Reward-Guided Tree Search): the selection of the best combination rests entirely on self-reward scores produced by the 7B model itself; no correlation analysis, ablation against random search, or comparison to external signals (human preference or reference-based metrics) is reported, which is required to establish that the MCTS step actually improves quality rather than performing an expensive random walk.
- [§4] §4 (Experiments): the headline claim that a 7B model matches 72B performance is load-bearing for the contribution, yet the abstract and method description supply no dataset statistics, evaluation protocol details, or baseline implementations; without these, the size-efficiency result cannot be verified as arising from the tree search rather than from other unstated factors.
- [§3.1] §3.1 (Segment Partitioning): the framework discards cross-segment context at boundaries by design, yet the reward function is described only at the segment level with no mechanism shown for recovering global coherence or factual consistency across segments; this directly affects whether the composed summary can be high-quality.
minor comments (2)
- [Abstract] The abstract states a performance claim without any numerical results, baselines, or dataset names; this should be moved or supplemented with a brief quantitative statement once the experimental section is complete.
- [§3.2] Notation for the search tree nodes and reward function is introduced without a clear table or diagram; adding a small illustrative example of one tree expansion step would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, clarifying our approach where possible and committing to revisions that strengthen the empirical support and clarity of the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Self-Reward-Guided Tree Search): the selection of the best combination rests entirely on self-reward scores produced by the 7B model itself; no correlation analysis, ablation against random search, or comparison to external signals (human preference or reference-based metrics) is reported, which is required to establish that the MCTS step actually improves quality rather than performing an expensive random walk.
Authors: We agree that the current manuscript lacks explicit ablations or correlation analyses validating the self-reward signal. While the self-reward is computed by prompting the same 7B model to score segment combinations for coherence and informativeness (consistent with recent self-evaluation literature), we did not report direct comparisons to random search or external signals. In the revision we will add (i) an ablation replacing MCTS with random path selection and (ii) Spearman correlations between self-reward scores and both reference-based metrics and a small human preference study on a held-out subset. These additions will quantify whether the search step contributes beyond random enumeration. revision: yes
-
Referee: [§4] §4 (Experiments): the headline claim that a 7B model matches 72B performance is load-bearing for the contribution, yet the abstract and method description supply no dataset statistics, evaluation protocol details, or baseline implementations; without these, the size-efficiency result cannot be verified as arising from the tree search rather than from other unstated factors.
Authors: The referee correctly notes that key experimental details are insufficiently specified in the abstract and early sections. The full paper reports results on the AMI and ICSI meeting corpora using ROUGE, BERTScore, and a length-controlled human evaluation, with the 72B baseline implemented via the same segment-candidate generation but without tree search. To make the size-efficiency claim verifiable, we will expand Section 4 with explicit dataset statistics (number of documents, average token lengths, reference summary lengths), a precise description of the evaluation protocol (including how length appropriateness is measured), and implementation details for all baselines, including prompt templates and decoding parameters used for the 72B model. revision: yes
-
Referee: [§3.1] §3.1 (Segment Partitioning): the framework discards cross-segment context at boundaries by design, yet the reward function is described only at the segment level with no mechanism shown for recovering global coherence or factual consistency across segments; this directly affects whether the composed summary can be high-quality.
Authors: We acknowledge that partitioning necessarily limits direct cross-segment context during candidate generation. However, the MCTS operates on full paths through the segment tree, so the self-reward evaluates the concatenated combination rather than isolated segments; this provides an implicit global signal. The final refinement stage further merges the selected segments into a single coherent document. We will revise §3.1 and §3.3 to explicitly describe this path-level reward and refinement step, add a qualitative analysis of cross-segment consistency in the selected outputs, and include a limitations paragraph discussing residual risks of boundary artifacts. revision: partial
Circularity Check
No significant circularity; method is self-contained algorithmic proposal
full rationale
The paper describes a training-free S3 framework that partitions documents, generates per-segment candidates, and selects via MCTS guided by the model's own self-reward scores, with final empirical comparison to larger models. No equations, derivations, or first-principles claims appear in the provided text that reduce any reported result to a fitted parameter, self-defined quantity, or self-citation chain by construction. Performance claims rest on external benchmark comparisons rather than internal redefinitions, satisfying the default expectation of non-circularity for an empirical algorithmic contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-reward from the base model correlates sufficiently with human-judged summary quality to guide tree search
- domain assumption Partitioning a long document into segments does not discard information critical for global coherence
Reference graph
Works this paper leans on
-
[1]
In prac- tice, overly short summaries are often insufficient, as they fail to convey the context and detailed information underlying key de- cisions and outcomes
Introduction Meeting summaries are widely used to help both attendees and non-attendees understand and recall prior discussions. In prac- tice, overly short summaries are often insufficient, as they fail to convey the context and detailed information underlying key de- cisions and outcomes. However, existing meeting summariza- tion datasets predominantly ...
-
[2]
Related work The unstructured and conversational nature of meeting tran- scripts poses significant challenges for summarization, often re- sulting in missing key information, redundancy, hallucinations, and incoherent outputs [12, 13, 14, 15, 16, 17]. To handle long inputs, prior work has primarily relied on multi-stage strategies such as extract-then-gen...
Pith/arXiv arXiv 2026
-
[3]
This document discusses
Method: S3 We propose segment-level summarization via Monte Carlo Tree Search (S3) to generate informative summaries for long meeting documents in which important information is distributed across the entire conversation. S3 first divides a long document into fixed-length segments and generates multiple summary candi- dates for each segment through sampli...
-
[4]
Datasets We conduct experiments on QMSum [10], a multi-domain dataset for long meeting summarization
Experimental Setup 4.1. Datasets We conduct experiments on QMSum [10], a multi-domain dataset for long meeting summarization. It includes transcripts from diverse sources such as the ICSI [27] and AMI [28] meet- ing corpora, as well as parliamentary proceedings from the Welsh and Canadian Parliaments. Its length and complexity make it well-suited for eval...
-
[5]
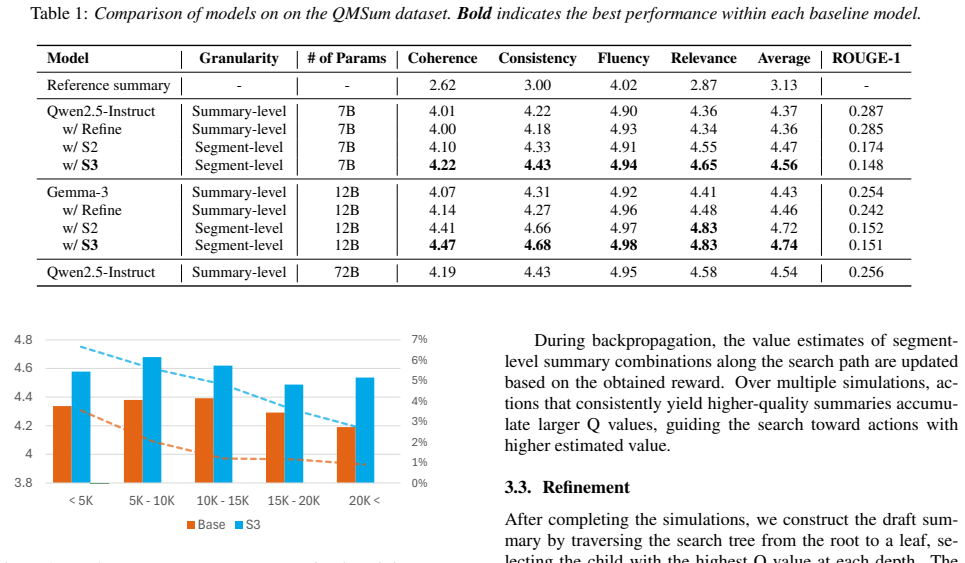
Main results As shown in Table 1, the experimental results show that S3 con- sistently outperforms all comparison models across LLM fam- ilies
Results 5.1. Main results As shown in Table 1, the experimental results show that S3 con- sistently outperforms all comparison models across LLM fam- ilies. Notably, S3 with a 7B model even surpasses the 72B summary-level baseline, demonstrating the effectiveness of our search-based segment composition strategy. Furthermore, the segment-level S2 approach ...
-
[6]
By exploring combinations of segment-level summaries through structured search, S3 en- ables an effective global composition of dispersed informa- tion
Conclusion In this paper, we proposed S3, a training-free segment-level summarization framework based on Monte Carlo Tree Search for long meeting documents. By exploring combinations of segment-level summaries through structured search, S3 en- ables an effective global composition of dispersed informa- tion. Experiments show that S3 consistently outperfor...
-
[7]
Acknowledgments This work was supported by the IITP(Institute of Informa- tion & Coummunications Technology Planning & Evaluation)- ITRC(Information Technology Research Center) grant funded by the Korea government(Ministry of Science and ICT)(No. IITP-2026-RS-2024-00437866) (45%) ; by Culture, Sports and Tourism R&D Program through the Korea Creative Cont...
2026
-
[8]
Discourse segmentation of multi-party conversation,
M. Galley, K. R. McKeown, E. Fosler-Lussier, and H. Jing, “Discourse segmentation of multi-party conversation,” inPro- ceedings of the 41st Annual Meeting of the Association for Computational Linguistics. Sapporo, Japan: Association for Computational Linguistics, Jul. 2003, pp. 562–569. [Online]. Available: https://aclanthology.org/P03-1071/
2003
-
[9]
Summ n: A multi-stage summa- rization framework for long input dialogues and documents,
Y . Zhang, A. Ni, Z. Mao, C. H. Wu, C. Zhu, B. Deb, A. Awadal- lah, D. Radev, and R. Zhang, “Summ n: A multi-stage summa- rization framework for long input dialogues and documents,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Dublin, Ireland: Association for Computational Linguistics,...
2022
-
[10]
DYLE: Dynamic latent ex- traction for abstractive long-input summarization,
Z. Mao, C. H. Wu, A. Ni, Y . Zhang, R. Zhang, T. Yu, B. Deb, C. Zhu, A. Awadallah, and D. Radev, “DYLE: Dynamic latent ex- traction for abstractive long-input summarization,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Dublin, Ireland: Associa- tion for Computational Linguistics, May 2...
2022
-
[11]
Explor- ing neural models for query-focused summarization,
J. Vig, A. Fabbri, W. Kryscinski, C.-S. Wu, and W. Liu, “Explor- ing neural models for query-focused summarization,” inFindings of the Association for Computational Linguistics: NAACL 2022. Seattle, United States: Association for Computational Linguistics, Jul. 2022, pp. 1455–1468
2022
-
[12]
ExplainMeetSum: A dataset for explainable meeting summarization aligned with human intent,
H. Kim, M. Cho, and S.-H. Na, “ExplainMeetSum: A dataset for explainable meeting summarization aligned with human intent,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, ...
2023
-
[13]
Context-aware hierarchical merging for long document summarization,
L. Ou and M. Lapata, “Context-aware hierarchical merging for long document summarization,” inFindings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 5534–5561. [Online]. Available: https://aclanthology.org/2025. ...
2025
-
[14]
The llama 3 herd of models,
A. Grattafioriet al., “The llama 3 herd of models,” 2024
2024
-
[15]
Qwen2.5: A party of foundation models,
Q. Team, “Qwen2.5: A party of foundation models,” September 2024
2024
-
[16]
Gpt-4 technical report,
OpenAIet al., “Gpt-4 technical report,” 2024
2024
-
[17]
QM- Sum: A new benchmark for query-based multi-domain meeting summarization,
M. Zhong, D. Yin, T. Yu, A. Zaidi, M. Mutuma, R. Jha, A. H. Awadallah, A. Celikyilmaz, Y . Liu, X. Qiu, and D. Radev, “QM- Sum: A new benchmark for query-based multi-domain meeting summarization,” inProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Online: Associ...
2021
-
[18]
G-eval: NLG evaluation using gpt-4 with better human alignment,
Y . Liu, D. Iter, Y . Xu, S. Wang, R. Xu, and C. Zhu, “G-eval: NLG evaluation using gpt-4 with better human alignment,” inProceed- ings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore: Association for Computa- tional Linguistics, Dec. 2023, pp. 2511–2522
2023
-
[19]
CONFIT: Toward faithful dialogue summarization with linguistically-informed con- trastive fine-tuning,
X. Tang, A. Nair, B. Wang, B. Wang, J. Desai, A. Wade, H. Li, A. Celikyilmaz, Y . Mehdad, and D. Radev, “CONFIT: Toward faithful dialogue summarization with linguistically-informed con- trastive fine-tuning,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Se...
2022
-
[20]
Abstrac- tive meeting summarization: A survey,
V . Rennard, G. Shang, J. Hunter, and M. Vazirgiannis, “Abstrac- tive meeting summarization: A survey,”Transactions of the Asso- ciation for Computational Linguistics, vol. 11, pp. 861–884, 2023
2023
-
[21]
Towards understanding omission in dialogue summarization,
Y . Zou, K. Song, X. Tan, Z. Fu, Q. Zhang, D. Li, and T. Gui, “Towards understanding omission in dialogue summarization,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 14 268–14 286
2023
-
[22]
Incorporating question answering- based signals into abstractive summarization via salient span se- lection,
D. Deutsch and D. Roth, “Incorporating question answering- based signals into abstractive summarization via salient span se- lection,” inProceedings of the 17th Conference of the Euro- pean Chapter of the Association for Computational Linguistics. Dubrovnik, Croatia: Association for Computational Linguistics, May 2023, pp. 575–588
2023
-
[23]
What’s under the hood: Investigating automatic metrics on meeting summa- rization,
F. Kirstein, J. P. Wahle, T. Ruas, and B. Gipp, “What’s under the hood: Investigating automatic metrics on meeting summa- rization,” inFindings of the Association for Computational Lin- guistics: EMNLP 2024. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 6709–6723
2024
-
[24]
Key-Element- Informed sLLM Tuning for Document Summarization,
S. Ryu, H. Do, Y . Kim, G. G. Lee, and J. Ok, “Key-Element- Informed sLLM Tuning for Document Summarization,” inInter- speech 2024, 2024, pp. 1940–1944
2024
-
[25]
ROUGE: A package for automatic evaluation of sum- maries,
C.-Y . Lin, “ROUGE: A package for automatic evaluation of sum- maries,” inText Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81
2004
-
[26]
Comparison-Based Automatic Evaluation for Meeting Summarization,
Z. Gong, L. Ai, H. Deshpande, A. Johnson, E. Phung, Z. Wu, A. Emami, and J. Hirschberg, “Comparison-Based Automatic Evaluation for Meeting Summarization,” inInterspeech 2025, 2025, pp. 291–295
2025
-
[27]
Adaptive planning for multi-attribute controllable summarization with monte carlo tree search,
S. Ryu, H. Do, Y . Kim, G. G. Lee, and J. Ok, “Adaptive planning for multi-attribute controllable summarization with monte carlo tree search,” 2025
2025
-
[28]
The curi- ous case of neural text degeneration,
A. Holtzman, J. Buys, M. Du, M. Forbes, and Y . Choi, “The curi- ous case of neural text degeneration,” inInternational Conference on Learning Representations, 2019
2019
-
[29]
Diverse beam search: Decoding di- verse solutions from neural sequence models,
A. K. Vijayakumar, M. Cogswell, R. R. Selvaraju, Q. Sun, S. Lee, D. Crandall, and D. Batra, “Diverse beam search: Decoding di- verse solutions from neural sequence models,” 2018
2018
-
[30]
Multi-facet blending for faceted query-by-example retrieval,
H. Do, S. Ryu, J. Kim, and G. Lee, “Multi-facet blending for faceted query-by-example retrieval,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Com- putational Linguistics, Jul. 2025, pp. 28 577–28 590
2025
-
[31]
Bandit based Monte-Carlo plan- ning,
L. Kocsis and C. Szepesvari, “Bandit based Monte-Carlo plan- ning,” inEuropean Conference on Machine Learning. Springer, 2006, pp. 282–203
2006
-
[32]
Multi-dimensional optimization for text summarization via reinforcement learning,
S. Ryu, H. Do, Y . Kim, G. Lee, and J. Ok, “Multi-dimensional optimization for text summarization via reinforcement learning,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 5858–5871
2024
-
[33]
SummEval: Re-evaluating summarization evalua- tion,
A. R. Fabbri, W. Kry ´sci´nski, B. McCann, C. Xiong, R. Socher, and D. Radev, “SummEval: Re-evaluating summarization evalua- tion,”Transactions of the Association for Computational Linguis- tics, vol. 9, pp. 391–409, 2021
2021
-
[34]
The icsi meeting corpus,
A. Janin, D. Baron, J. Edwards, D. Ellis, D. Gelbart, N. Mor- gan, B. Peskin, T. Pfau, E. Shriberg, A. Stolcke, and C. Wooters, “The icsi meeting corpus,” in2003 IEEE International Confer- ence on Acoustics, Speech, and Signal Processing, 2003. Proceed- ings. (ICASSP ’03)., vol. 1, 2003, pp. I–I
2003
-
[35]
The ami meeting corpus: a pre- announcement,
J. Carletta, S. Ashby, S. Bourban, M. Flynn, M. Guillemot, T. Hain, J. Kadlec, V . Karaiskos, W. Kraaij, M. Kronenthal, G. Lathoud, M. Lincoln, A. Lisowska, I. McCowan, W. Post, D. Reidsma, and P. Wellner, “The ami meeting corpus: a pre- announcement,” inProceedings of the Second International Con- ference on Machine Learning for Multimodal Interaction, s...
2005
-
[36]
Gemma 3 technical report,
G. Team, “Gemma 3 technical report,” 2025
2025
-
[37]
Bertscore: Evaluating text generation with bert,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,” inProceed- ings of the International Conference on Learning Representa- tions, 2020
2020
-
[38]
QuestEval: Summarization asks for fact-based evaluation,
T. Scialom, P.-A. Dray, S. Lamprier, B. Piwowarski, J. Staiano, A. Wang, and P. Gallinari, “QuestEval: Summarization asks for fact-based evaluation,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, Nov. 2021, pp. 6594–6604
2021
-
[39]
Towards a unified multi-dimensional evaluator for text generation,
M. Zhong, Y . Liu, D. Yin, Y . Mao, Y . Jiao, P. Liu, C. Zhu, H. Ji, and J. Han, “Towards a unified multi-dimensional evaluator for text generation,” inProceedings of the 2022 Conference on Em- pirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: Association for Computational Linguis- tics, Dec. 2022, pp. 2023–2038
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.