Perceptual compensation for tonal context in self-supervised speech models
Pith reviewed 2026-06-27 00:31 UTC · model grok-4.3
The pith
Purely self-supervised speech models show no compensation for tonal context in their embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
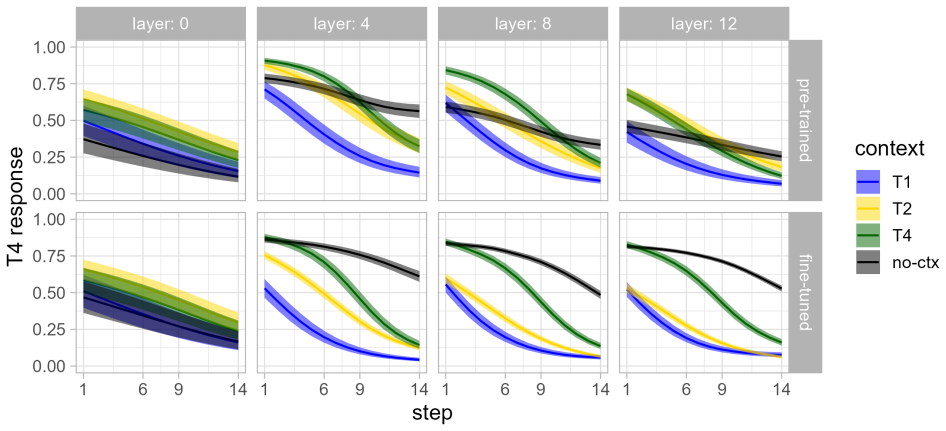
The study finds no evidence of compensation for tonal context in the embedding similarities of the purely pre-trained wav2vec2.0 model. Probing classifiers exhibit some compensation in addition to expected layer-wise gains in tone categorization, but these outputs fail to match human performance on isolated test syllables. The findings indicate that supervised objectives may be necessary to encourage abstraction of at least some phonological regularities, in contrast to previous reports of phonological sensitivity emerging from pre-training alone.
What carries the argument
wav2vec2.0 embeddings and probing classifiers applied to a Mandarin tone compensation task
If this is right
- Self-supervised pre-training by itself does not produce compensation for phonological context in speech embeddings.
- Fine-tuning on an ASR task introduces measurable compensation effects alongside better categorization.
- Human-like performance on isolated syllables requires training signals beyond pure self-supervision.
- Claims that phonological structure sensitivity emerges automatically from pre-training do not hold for this tonal compensation case.
Where Pith is reading between the lines
- Models may need explicit phonological supervision to capture context-dependent regularities that do not emerge from general acoustic prediction.
- Testing other phonological phenomena could reveal which abstractions are learnable without labels and which are not.
- Future model design might incorporate targeted phonological objectives during pre-training to close the gap with human listeners.
Load-bearing premise
Embedding similarities and probing classifier outputs on this pseudo-replication experiment serve as valid measures of the perceptual compensation observed in human listeners.
What would settle it
Observing that the pre-trained model's embedding similarities or classifier outputs on the same isolated Mandarin tone syllables match human compensation patterns would falsify the no-evidence claim.
Figures
read the original abstract
This study examines the extent to which the wav2vec2.0 architecture exhibits evidence of compensation for phonological context. We conducted a pseudo-replication of a perceptional compensation experiment on Mandarin Chinese tones, and compared the embedding similarities and probing classifier outputs between a purely self-supervised pre-trained model and a model fine-tuned for Mandarin ASR. No evidence of compensation was found in the embedding similarities of the purely pre-trained model. Probing classifiers showed some evidence of compensation in addition to the expected layer-wise improvements in categorization, but failed to replicate human performance on isolated test syllables. Our findings contrast with previous reports of sensitivity to phonological structure emerging through pre-training alone, and suggest that supervised objectives may be necessary to encourage the abstraction of at least some types of phonological regularities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a pseudo-replication of a human perceptual compensation experiment for Mandarin Chinese tones using wav2vec2.0. It compares embedding cosine similarities and probing classifier performance between a purely self-supervised pre-trained model and the same architecture fine-tuned for Mandarin ASR. The central findings are that no evidence of compensation appears in the pre-trained model's embeddings, while probing shows some evidence of compensation plus expected layer-wise gains in categorization accuracy, yet the fine-tuned model still fails to match human performance on isolated test syllables. The authors conclude that supervised objectives may be necessary to induce abstraction of at least some phonological regularities.
Significance. If the embedding-similarity and probing metrics are accepted as faithful proxies, the work would demonstrate that purely self-supervised pre-training on wav2vec2.0 does not induce the context-dependent tonal normalization observed in human listeners, in contrast to earlier reports of phonological sensitivity arising from pre-training alone. The direct, controlled comparison of pre-trained versus fine-tuned variants supplies a clear test of the contribution of the supervised objective. This supplies falsifiable, quantitative evidence on the linguistic abstractions inducible by different training regimes.
major comments (1)
- [Abstract and implied Methods/Results sections] The central claim (no compensation in pre-trained embeddings; only partial evidence after fine-tuning) is load-bearing on the assumption that cosine similarity between context-altered tone embeddings and probing accuracy on isolated syllables constitute valid stand-ins for the perceptual compensation effect documented in human listeners. The manuscript provides no correlation with human response data, no validation that stimulus construction replicates the original experiment, and no layer-specific sensitivity analysis; without these, the reported null result could arise from metric insensitivity rather than absence of the regularity (see Abstract and the description of the embedding-similarity and probing analyses).
minor comments (2)
- [Abstract] The abstract reports outcomes without any statistical details (sample sizes, significance tests, exact similarity or accuracy values) that would allow readers to assess the strength of the 'some evidence' claim.
- [Implied Methods section] The description of the probing classifier (architecture, training procedure, choice of layers) and the precise definition of 'isolated test syllables' is absent, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the validity of our proxy measures. We respond point by point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: The central claim (no compensation in pre-trained embeddings; only partial evidence after fine-tuning) is load-bearing on the assumption that cosine similarity between context-altered tone embeddings and probing accuracy on isolated syllables constitute valid stand-ins for the perceptual compensation effect documented in human listeners. The manuscript provides no correlation with human response data, no validation that stimulus construction replicates the original experiment, and no layer-specific sensitivity analysis; without these, the reported null result could arise from metric insensitivity rather than absence of the regularity (see Abstract and the description of the embedding-similarity and probing analyses).
Authors: We acknowledge that our conclusions rest on the use of cosine similarity and probing classifiers as proxies. These are standard techniques in the speech representation learning literature for detecting phonological regularities in model embeddings. The stimuli were constructed to match the tonal contexts and syllable pairs from the original human perceptual compensation study on Mandarin tones; we will add an explicit side-by-side comparison of stimulus parameters in the revised Methods section to make this replication transparent. We already report probing accuracy broken down by layer and observe the expected monotonic improvement, but will expand this into a dedicated sensitivity analysis subsection examining how compensation effects vary across layers. Direct correlation with human response data is outside the scope of the present work, which focuses on whether the regularity emerges under different training regimes rather than on behavioral simulation; we will add an explicit limitations paragraph discussing this choice. These targeted additions constitute a partial revision that addresses the referee's concerns while preserving the manuscript's core contribution. revision: partial
Circularity Check
No circularity: empirical measurements of embeddings and probes are direct outputs, not reductions to inputs
full rationale
The paper conducts an experimental pseudo-replication comparing cosine similarities of tone embeddings and probing classifier accuracies between a pre-trained wav2vec2.0 model and a fine-tuned Mandarin ASR variant. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. Claims rest on direct experimental contrasts with human data as an external benchmark, with no self-definitional loops or ansatzes smuggled via prior author work. This is the standard case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embedding similarities and probing classifier performance on tone categorization reflect perceptual compensation for tonal context
Reference graph
Works this paper leans on
-
[1]
Introduction This paper aims to contribute to our understanding of the role of phonological context in speech perception through computa- tional modeling. We do so by exploring how one neural speech architecture, wav2vec2.0 [1], represents lexical tones in differ- ent phonological contexts. By treating wav2vec2.0 as a compu- tational model of perceptual i...
Pith/arXiv arXiv 2026
-
[2]
Like segments, the phonetic realization of tones is heavily influenced by car- ryover coarticulation
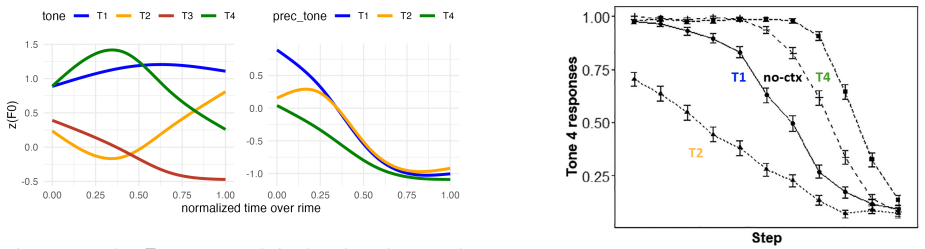
Background Most lexical syllables in Mandarin Chinese bear one of four tones: high-level Tone 1 ([ba1]八‘eight’), high-rising Tone 2 ([ba2]拔‘to pull’), low-falling(-rising) Tone 3 ([ba3]把‘to take’) or high-falling Tone 4 ([ba4]爸‘father’). Like segments, the phonetic realization of tones is heavily influenced by car- ryover coarticulation. For example, alth...
-
[3]
Methods 3.1. Stimuli To investigate whether wav2vec2.0 displays a similar bias in its responses, we generated continua of Mandarin syllables with fixed segmental material butF0contours varying between canonical T3 and T4 endpoints. Typical for psycholinguistic studies, [21] tested a small number of stimuli on a large number of participants. Since model re...
-
[4]
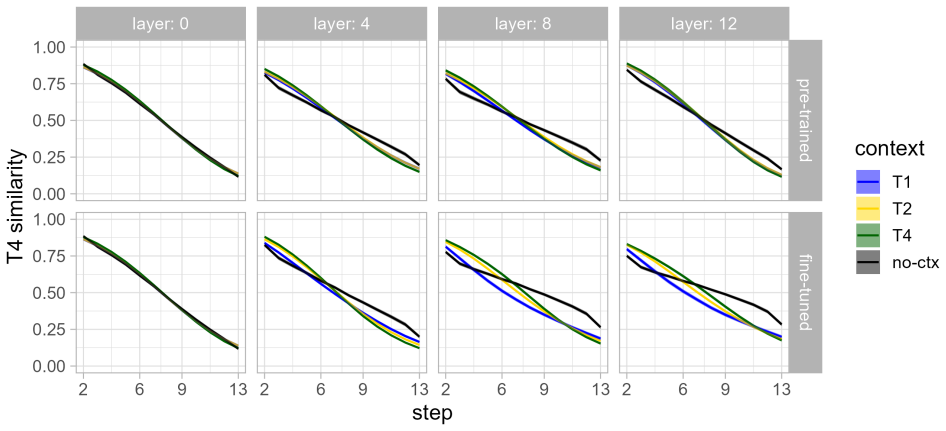
Results Here we only show the results for layer 0 (CNN output) and layers 4, 8, and 12; results for other layers follow similar trends. 4.1. Embedding similarities Embedding similarities for both PT and FT checkpoints are shown in Fig. 3. There is no evidence of sensitivity to context in the PT embeddings (top row). There appears to be a small effect of t...
-
[5]
Purely self-supervised representations showed no evidence of the baseline-centered boundary shifts that characterized perceptual compensation for tonal coarticulation in [21]
Discussion This study explored the extent to which two wav2vec2.0 mod- els, one pre-trained and one fine-tuned, exhibited evidence of compensation for phonological context. Purely self-supervised representations showed no evidence of the baseline-centered boundary shifts that characterized perceptual compensation for tonal coarticulation in [21]. While so...
-
[6]
Generative AI Use Disclosure No generative AI or AI-assisted technologies were used in the research process or the preparation of this manuscript
-
[7]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inProc. NIPS, 2020, pp. 12 449–12 460
2020
-
[8]
A rational account of percep- tual compensation for coarticulation,
M. Sonderegger and A. Yu, “A rational account of percep- tual compensation for coarticulation,”Proceedings of the Annual Meeting of the Cognitive Science Society, vol. 32, p. 375–380, 2010
2010
-
[9]
Influence of vocalic context on per- ception of the [ R ]-[s] distinction,
V . A. Mann and B. H. Repp, “Influence of vocalic context on per- ception of the [ R ]-[s] distinction,”Perception & Psychophysics, vol. 28, no. 3, pp. 213–228, 1980
1980
-
[10]
On the causes of compensation for coarticula- tion: Evidence for phonological mediation,
H. Mitterer, “On the causes of compensation for coarticula- tion: Evidence for phonological mediation,”Perception & Psy- chophysics, vol. 68, no. 7, p. 1227–1240, 2006
2006
-
[11]
Young infants’ perception of liquid coarticulatory influences on following stop consonants,
C. A. Fowler, C. T. Best, and G. W. McRoberts, “Young infants’ perception of liquid coarticulatory influences on following stop consonants,”Perception & Psychophysics, vol. 48, no. 6, pp. 559– 570, 1990
1990
-
[12]
Perceptual compen- sation for coarticulation by Japanese quail,
A. J. Lotto, K. R. Kluender, and L. L. Holt, “Perceptual compen- sation for coarticulation by Japanese quail,”The Journal of the Acoustical Society of America, vol. 102, no. 2, pp. 1134–1140, 1997
1997
-
[13]
Speech perception,
R. L. Diehl, A. J. Lotto, and L. L. Holt, “Speech perception,” Annual Review of Psychology, vol. 55, no. 1, pp. 149–179, 2004
2004
-
[14]
Speech perception,
A. G. Samuel, “Speech perception,”Annual Review of Psychol- ogy, vol. 62, no. 1, pp. 49–72, 2011
2011
-
[15]
Self-supervised speech representation learning: A review,
A. Mohamed, H.-y. Lee, L. Borgholt, J. D. Havtorn, J. Edin, C. Igel, K. Kirchhoff, S.-W. Li, K. Livescu, L. Maaløeet al., “Self-supervised speech representation learning: A review,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1179–1210, 2022
2022
-
[16]
Phonetic analysis of self-supervised representations of English speech,
D. Wells, H. Tang, and K. Richmond, “Phonetic analysis of self-supervised representations of English speech,” inINTER- SPEECH, 2022, pp. 3583–3587
2022
-
[17]
What do self-supervised speech models know about words?
A. Pasad, C.-M. Chien, S. Settle, and K. Livescu, “What do self-supervised speech models know about words?”Transac- tions of the Association for Computational Linguistics, vol. 12, p. 372–391, 2024
2024
-
[18]
What can an accent identifier learn? probing phonetic and prosodic information in a wav2vec2-based accent identification model,
M. Yang, R. C. M. C. Shekar, O. Kang, and J. H. L. Hansen, “What can an accent identifier learn? probing phonetic and prosodic information in a wav2vec2-based accent identification model,” inINTERSPEECH, 2023, pp. 1923–1927
2023
-
[19]
Encoding of lexical tone in self-supervised models of spoken lan- guage,
G. Shen, M. Watkins, A. Alishahi, A. Bisazza, and G. Chrupała, “Encoding of lexical tone in self-supervised models of spoken lan- guage,” inProc. NAACL, 2024, pp. 4250–4261
2024
-
[20]
A layer-wise analysis of Man- darin and English suprasegmentals in SSL speech models,
A. de la Fuente and D. Jurafsky, “A layer-wise analysis of Man- darin and English suprasegmentals in SSL speech models,” inIN- TERSPEECH, 2024
2024
-
[21]
Visualizing phoneme category adaptation in Deep Neural Networks,
O. Scharenborg, S. Tiesmeyer, M. Hasegawa-Johnson, and N. De- hak, “Visualizing phoneme category adaptation in Deep Neural Networks,” inINTERSPEECH, 2018, pp. 1482–1486
2018
-
[22]
Do self-supervised speech models de- velop human-like perception biases?
J. Millet and E. Dunbar, “Do self-supervised speech models de- velop human-like perception biases?” inProc. ACL 60, 2022, pp. 7591–7605
2022
-
[23]
Per- ception of phonological assimilation by neural speech recognition models,
C. Pouw, M. d. H. Kloots, A. Alishahi, and W. Zuidema, “Per- ception of phonological assimilation by neural speech recognition models,”Computational Linguistics, vol. 50, no. 4, pp. 1557– 1585, 2024
2024
-
[24]
Human-like linguistic biases in neural speech models: Phonetic categorization and phonotactic constraints in wav2vec2.0,
M. de Heer Kloots and W. Zuidema, “Human-like linguistic biases in neural speech models: Phonetic categorization and phonotactic constraints in wav2vec2.0,” inINTERSPEECH, 2024
2024
-
[25]
Feature parsing: Feature cue mapping in spoken word recognition,
D. W. Gow, “Feature parsing: Feature cue mapping in spoken word recognition,”Perception & Psychophysics, vol. 65, no. 4, pp. 575–590, 2003
2003
-
[26]
A cross-linguistic examination of assimilation context effects,
D. W. Gow and A. M. Im, “A cross-linguistic examination of assimilation context effects,”Journal of Memory and Language, vol. 51, no. 2, pp. 279–296, 2004
2004
-
[27]
The influence of preceding speech and nonspeech contexts on Mandarin tone identification,
H. Zhang, H. Ding, and W.-S. Lee, “The influence of preceding speech and nonspeech contexts on Mandarin tone identification,” Journal of Phonetics, vol. 93, p. 101154, 2022
2022
-
[28]
Production and perception of coarticulated tones,
Y . Xu, “Production and perception of coarticulated tones,”The Journal of the Acoustical Society of America, vol. 95, no. 4, p. 2240–2253, 1994
1994
-
[29]
AISHELL-3: A multi-speaker Mandarin TTS corpus,
Y . Shi, H. Bu, X. Xu, S. Zhang, and M. Li, “AISHELL-3: A multi-speaker Mandarin TTS corpus,” inINTERSPEECH, 2021, pp. 2756–2760
2021
-
[30]
Context effect in the categorical percep- tion of Mandarin tones,
F. Chen and G. Peng, “Context effect in the categorical percep- tion of Mandarin tones,”Journal of Signal Processing Systems, vol. 82, no. 2, p. 253–261, 2016
2016
-
[31]
Context effects in the perception of lexi- cal tone,
R. A. Fox and Y .-Y . Qi, “Context effects in the perception of lexi- cal tone,”Journal of Chinese Linguistics, vol. 18, no. 2, pp. 261– 284, 1990
1990
-
[32]
Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi,
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Son- deregger, “Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi,” inINTERSPEECH, 2017
2017
-
[33]
Introducing Parsel- mouth: A Python interface to Praat,
Y . Jadoul, B. Thompson, and B. de Boer, “Introducing Parsel- mouth: A Python interface to Praat,”Journal of Phonetics, vol. 71, pp. 1–15, 2018
2018
-
[34]
Praat: doing phonetics by computer [Computer program],
P. Boersma and D. Weenink, “Praat: doing phonetics by computer [Computer program],” Version 6.1.38, retrieved 2 January 2021 http://www.praat.org/, 2021
2021
-
[35]
Transformers: State-of- the-Art Natural Language Processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. Le Scao, S. Gug- ger, M. Drame, Q. Lhoest, and A. Rush, “Transformers: State-of- the-Art Natural Language Processing,” inProceedings of the 2020 Conference on Empirical Met...
2020
-
[36]
Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized lin- ear models,
S. N. Wood, “Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized lin- ear models,”Journal of the Royal Statistical Society Series B: Sta- tistical Methodology, vol. 73, no. 1, pp. 3–36, 2011
2011
-
[37]
Probing acoustic represen- tations for phonetic properties,
D. Ma, N. Ryant, and M. Liberman, “Probing acoustic represen- tations for phonetic properties,” inICASSP, 2021, pp. 311–315
2021
-
[38]
What do self-supervised speech models know about Dutch? Analyzing advantages of language-specific pre-training,
M. d. H. Kloots, H. Mohebbi, C. Pouw, G. Shen, W. Zuidema, and M. Bentum, “What do self-supervised speech models know about Dutch? Analyzing advantages of language-specific pre-training,” inProc. Interspeech 2025, 2025, pp. 256–260
2025
-
[39]
Word stress in self- supervised speech models: A cross-linguistic comparison,
M. Bentum, L. ten Bosch, and T. O. Lentz, “Word stress in self- supervised speech models: A cross-linguistic comparison,” in Proc. Interspeech 2025, 2025, pp. 251–255
2025
-
[40]
Bigger is not always better: The effect of context size on speech pre-training,
S. Robertson and E. Dunbar, “Bigger is not always better: The effect of context size on speech pre-training,”arXiv:2312.01515, 2023
arXiv 2023
-
[41]
Effective context in neural speech models,
Y . Meng, S. Goldwater, and H. Tang, “Effective context in neural speech models,” inINTERSPEECH, 2025, pp. 246–250
2025
-
[42]
Mandarin lexical tones: A corpus-based study of word length, syllable position and prosodic position on duration,
Y . Wu, M. Adda-Decker, and L. Lamel, “Mandarin lexical tones: A corpus-based study of word length, syllable position and prosodic position on duration,” inINTERSPEECH, 2020, pp. 1908–1912
2020
-
[43]
Probing classifiers: Promises, shortcomings, and advances,
Y . Belinkov, “Probing classifiers: Promises, shortcomings, and advances,”Computational Linguistics, vol. 48, no. 1, pp. 207– 219, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.