EmoInstruct-TTS: Dual-Path Instruction-Guided Emotional Speech Synthesis
Pith reviewed 2026-06-27 16:59 UTC · model grok-4.3
The pith
EmoInstruct-TTS maps free-form instructions to a supervised embedding of 48 emotional states to control speech synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
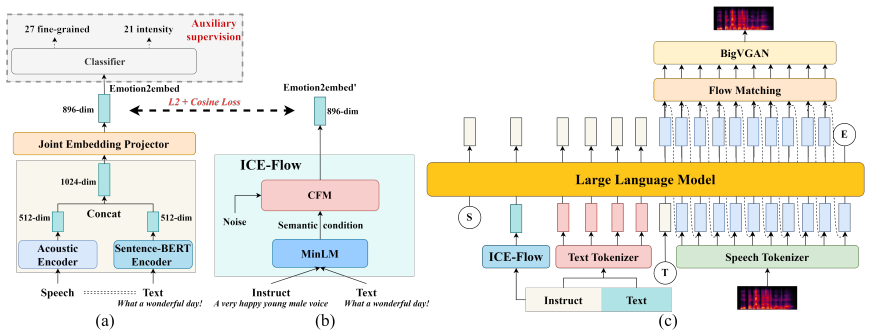
The authors claim that a dual-path architecture, consisting of the supervised Emotion2embed covering 48 emotional states with fine-grained intensity and the ICE-Flow model that produces acoustically grounded representations from arbitrary instructions, can be integrated into LLM-based TTS to deliver explicit emotional control without sacrificing semantic planning or acoustic quality.
What carries the argument
Emotion2embed, a supervised semantic-acoustic embedding spanning 48 emotional states and intensity levels, together with the ICE-Flow model that infers these embeddings from free-form instructions.
If this is right
- Users can control both emotion category and intensity level through ordinary sentences rather than discrete labels.
- The LLM component continues to manage semantic content while the emotion path supplies separate acoustic guidance.
- The resulting speech exhibits higher controllability and naturalness than strong existing baselines.
- Arbitrary instructions are converted into embeddings that remain tied to acoustic properties of real emotional speech.
Where Pith is reading between the lines
- The separation of instruction interpretation from synthesis could allow the embedding or flow components to be swapped for other modalities or languages.
- If the 48-state coverage proves sufficient, the same supervised embedding might support downstream tasks such as emotion recognition or affective dialogue systems.
- Real-time deployment would require checking whether the dual-path overhead remains acceptable when instructions arrive continuously.
Load-bearing premise
Emotion2embed is assumed to faithfully encode fine-grained intensity across all 48 states, and ICE-Flow is assumed to translate any natural-language instruction into these embeddings without losing acoustic grounding.
What would settle it
A listener study or acoustic analysis on held-out instructions that specify exact intensity levels (such as 'mildly surprised' versus 'intensely surprised') where the generated speech fails to show corresponding differences in measured emotional strength.
Figures


read the original abstract
Instruction-based controllable speech synthesis enables users to specify emotions through natural language. However, existing approaches often rely on coarse emotion labels and lack explicit modeling of fine-grained intensity. We propose EmoInstruct-TTS, a dual-path instruction-guided framework for emotional speech synthesis. We introduce Emotion2embed, a supervised semantic-acoustic emotion embedding covering 48 emotional states, including fine-grained categories and intensity levels. To infer embeddings from free-form instructions, we design an Instruction-Conditioned Emotion Flow Model (ICE-Flow) that generates acoustically grounded emotion representations. The inferred embeddings are integrated into an LLM-based synthesis pipeline to provide explicit emotional control while preserving semantic planning. Experiments show improved emotional controllability and speech naturalness over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EmoInstruct-TTS, a dual-path instruction-guided framework for emotional speech synthesis. It introduces Emotion2embed, a supervised semantic-acoustic embedding covering 48 emotional states with fine-grained categories and intensity levels, and the ICE-Flow model to infer acoustically grounded embeddings from free-form natural-language instructions. These embeddings are integrated into an LLM-based TTS pipeline to enable explicit emotional control while preserving semantic planning. Experiments are claimed to demonstrate improved emotional controllability and speech naturalness over strong baselines.
Significance. If the experimental claims hold with proper controls and metrics, the work could meaningfully advance controllable TTS by moving beyond coarse labels to natural-language instruction for fine-grained emotion and intensity. The separation of instruction-to-embedding mapping from the synthesis pipeline is a reasonable architectural choice that addresses a practical user need.
major comments (2)
- [Abstract] Abstract: the central claim that experiments show improved emotional controllability and speech naturalness is unsupported by any reported metrics, baselines, dataset details, or error analysis. Without these, the experimental contribution cannot be evaluated for post-hoc selection or missing controls.
- [Abstract] The assumption that Emotion2embed faithfully captures fine-grained intensity across 48 states and that ICE-Flow maps arbitrary instructions onto these embeddings without loss of acoustic grounding is load-bearing for the controllability claim, yet no validation (e.g., embedding similarity to ground-truth acoustics or ablation on mapping fidelity) is referenced.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract and the load-bearing assumptions in our work. We address each point below with references to the manuscript content and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that experiments show improved emotional controllability and speech naturalness is unsupported by any reported metrics, baselines, dataset details, or error analysis. Without these, the experimental contribution cannot be evaluated for post-hoc selection or missing controls.
Authors: The abstract summarizes the contribution concisely as is conventional, but the supporting details are provided in the full manuscript. Section 4 reports quantitative metrics for emotional controllability (e.g., classification accuracy and intensity correlation) and naturalness (MOS), along with the specific baselines, dataset statistics, and error analysis. We will revise the abstract to briefly reference these quantitative improvements and direct readers to the experimental section. revision: yes
-
Referee: [Abstract] The assumption that Emotion2embed faithfully captures fine-grained intensity across 48 states and that ICE-Flow maps arbitrary instructions onto these embeddings without loss of acoustic grounding is load-bearing for the controllability claim, yet no validation (e.g., embedding similarity to ground-truth acoustics or ablation on mapping fidelity) is referenced.
Authors: Validations for both components are included in the manuscript. Section 3.2 describes Emotion2embed training with supervision across the 48 states and reports similarity metrics to ground-truth acoustic embeddings; Section 4.2 presents ablations on ICE-Flow mapping fidelity. We will revise the abstract to explicitly reference these validation results to better support the controllability claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes EmoInstruct-TTS as a new dual-path framework introducing Emotion2embed (supervised embedding over 48 states) and ICE-Flow (instruction-conditioned model) integrated into an LLM pipeline. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described derivation. Experimental claims of improved controllability rest on external benchmarks rather than reducing to inputs by construction. The derivation chain is self-contained as a standard architectural proposal without any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Emotion2embed accurately represents 48 emotional states including fine-grained intensity levels
- domain assumption ICE-Flow can map free-form instructions to acoustically grounded embeddings without additional supervision at inference time
invented entities (2)
-
Emotion2embed
no independent evidence
-
ICE-Flow
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introduction Recent advances in neural text-to-speech (TTS) models have achieved speech naturalness and intelligibility approaching hu- man perception [1–6]. As TTS technology matures, research has increasingly shifted from neutral speech generation to con- trollable synthesis, where users specify attributes such as emo- tion, style, and prosody through e...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
As shown in Fig
Method EmoInstruct-TTS is a disentangled framework for instruction- guided emotional speech synthesis. As shown in Fig. 2, it consists of three components: an instruction-conditioned emo- tion generator, an LLM-based semantic encoder, and a speaker- conditioned TTS decoder followed by a neural vocoder. The framework separates semantic planning from emotio...
-
[3]
Experiments 3.1. Datasets and Training Setup We use the Emotional Speech Dataset (ESD) [32] and the Chi- nese Natural Complex Emotion Dataset (CNCED) [33]. The training data consist of two subsets constructed through a semi- automatic annotation pipeline. Dataset-Basecontains 49,903 utterances with automat- ically generated emotion captions produced by Ge...
-
[4]
By combining natural language instructions with structured emotion embeddings, the proposed system separates semantic planning from emotion-specific acoustic control
Conclusion This paper presentsEmoInstruct-TTS, a dual-path instruction- guided framework for controllable emotional speech synthe- sis. By combining natural language instructions with structured emotion embeddings, the proposed system separates semantic planning from emotion-specific acoustic control. Experiments show that EmoInstruct-TTS improves emotion...
-
[5]
Portaspeech: Portable and high-quality generative text-to-speech,
Y . Ren, J. Liu, and Z. Zhao, “Portaspeech: Portable and high-quality generative text-to-speech,” inAdvances in Neural Information Processing Systems, M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., vol. 34. Curran Associates, Inc., 2021, pp. 13 963–13 974. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2...
2021
-
[6]
Naturalspeech: End-to-end text-to-speech synthesis with human-level quality,
X. Tan, J. Chen, H. Liu, J. Conget al., “Naturalspeech: End-to-end text-to-speech synthesis with human-level quality,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 6, pp. 4234–4245, 2024
2024
-
[7]
K. Shen, Z. Ju, X. Tan, Y . Liu, Y . Leng, L. He, T. Qin, S. Zhao, and J. Bian, “Naturalspeech 2: Latent diffusion models are natu- ral and zero-shot speech and singing synthesizers,”arXiv preprint arXiv:2304.09116, 2023
-
[8]
Fireredtts-2: Towards long conversational speech generation for podcast and chatbot,
K. Xie, F. Shen, J. Li, F. Xie, X. Tang, and Y . Hu, “Fireredtts-2: Towards long conversational speech generation for podcast and chatbot,”arXiv preprint arXiv:2509.02020, 2025
-
[9]
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. JianZhao, K. Yu, and X. Chen, “F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 6255–6271
2025
-
[10]
Z. Jiang, Y . Ren, R. Li, S. Ji, B. Zhang, Z. Ye, C. Zhang, B. Jiong- hao, X. Yang, J. Zuoet al., “Megatts 3: Sparse alignment en- hanced latent diffusion transformer for zero-shot speech synthe- sis,”arXiv preprint arXiv:2502.18924, 2025
-
[11]
Styletts 2: towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,
Y . A. Li, C. Han, V . S. Raghavan, G. Mischler, and N. Mes- garani, “Styletts 2: towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,” inProceedings of the 37th International Conference on NeurIPS, 2023, pp. 19 594–19 621
2023
-
[12]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y . Wu, Z. Zhanget al., “Neural codec language models are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
K. Zhou, Y . Zhang, S. Zhao, H. Wanget al., “Emotional di- mension control in language model-based text-to-speech: Span- ning a broad spectrum of human emotions,”arXiv preprint arXiv:2409.16681, 2024
-
[14]
EME-TTS: Unlocking the Empha- sis and Emotion Link in Speech Synthesis,
H. Li, L. Qu, J. Hu, and T. Li, “EME-TTS: Unlocking the Empha- sis and Emotion Link in Speech Synthesis,” inInterspeech 2025, 2025, pp. 4368–4372
2025
-
[15]
Description-based controllable text-to-speech with cross-lingual voice control,
R. Yamamoto, Y . Shirahata, M. Kawamura, and K. Tachibana, “Description-based controllable text-to-speech with cross-lingual voice control,” inICASSP 2025-2025 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[16]
Au- diolm: A language modeling approach to audio generation,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonovet al., “Au- diolm: A language modeling approach to audio generation,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 31, pp. 2523–2533, 2023
2023
-
[17]
Natural language guidance for controllable TTS,
D. Lyth and S. King, “Natural language guidance of high-fidelity tts with synthetic annotations,”arXiv preprint arXiv:2402.01912, 2024
-
[18]
MPE-TTS: Customized Emotion Zero-Shot Text-To-Speech Using Multi- Modal Prompt,
Z. Wu, Y . Kang, S. Cao, L. Ma, Q. Li, and Q. Yang, “MPE-TTS: Customized Emotion Zero-Shot Text-To-Speech Using Multi- Modal Prompt,” inInterspeech 2025, 2025, pp. 4403–4407
2025
-
[19]
Instructaudio: Unified speech and music generation with natural language instruction,
C. Qiang, K. Yin, X. Wang, Y . Liang, J. Zhao, R. Fu, T. Wang, C. Gong, C. Zhang, L. Wanget al., “Instructaudio: Unified speech and music generation with natural language instruction,”arXiv preprint arXiv:2511.18487, 2025
-
[20]
Mintts: Modeling inten- sity in emotional speech synthesis,
D. Min, Y . Wang, Y . Ren, and J. Zhou, “Mintts: Modeling inten- sity in emotional speech synthesis,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[21]
Emoknob: Enhance voice cloning with fine-grained emotion control,
H. Chen, C. Run, and J. Hirschberg, “Emoknob: Enhance voice cloning with fine-grained emotion control,” inEMNLP, 2024
2024
-
[22]
SA-RAS: Speaker- Aware Style Retrieval Augmented Generation for Expressive Zero-Shot Text-to-Speech Synthesis,
X. Li, J. Xing, X. Xing, Z. Li, and X. Xu, “SA-RAS: Speaker- Aware Style Retrieval Augmented Generation for Expressive Zero-Shot Text-to-Speech Synthesis,” inInterspeech 2025, 2025, pp. 4388–4392
2025
-
[23]
NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tanget al., “Naturalspeech 3: Zero-shot speech syn- thesis with factorized codec and diffusion models,”arXiv preprint arXiv:2403.03100, 2024
-
[24]
S. Zhou, Y . Zhou, Y . He, X. Zhou, J. Wang, W. Deng, and J. Shu, “Indextts2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech,” arXiv preprint arXiv:2506.21619, 2025
-
[25]
Z. Du, Q. Chen, S. Zhang, K. Huet al., “Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on super- vised semantic tokens,”arXiv preprint arXiv:2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shiet al., “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Z. Du, C. Gao, Y . Wang, F. Yuet al., “Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training,” arXiv preprint arXiv:2505.17589, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guoet al., “Qwen3-tts technical report,” arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
V oicesculptor: Your voice, designed by you,
J. Hu, H. Chen, L. Ma, D. Guo, Q. Zhan, W. Li, H. Zhang, K. Xia, Z. Zhang, W. Tianet al., “V oicesculptor: Your voice, designed by you,”arXiv preprint arXiv:2601.10629, 2026
-
[30]
Expressive Prompting: Improving Emotion Intensity and Speaker Consistency in Zero-Shot TTS
H. Wang, C. Qiang, T. Wang, C. Gonget al., “Emopro: A prompt selection strategy for emotional expression in lm-based speech synthesis,”arXiv preprint arXiv:2409.18512, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Emovoice: Llm-based emo- tional text-to-speech model with freestyle text prompting,
G. Yang, C. Chen, Q. Chenet al., “Emovoice: Llm-based emo- tional text-to-speech model with freestyle text prompting,”arXiv preprint arXiv:2504.12867, 2025
-
[32]
Minimax-speech: In- trinsic zero-shot text-to-speech with a learnable speaker encoder,
B. Zhang, C. Guo, G. Yang, H. Yuet al., “Minimax-speech: In- trinsic zero-shot text-to-speech with a learnable speaker encoder,” arXiv preprint arXiv:2505.07916, 2025
-
[33]
C-pack: Pack- aged resources to advance general chinese embedding,
S. Xiao, Z. Liu, P. Zhang, and N. Muennighoff, “C-pack: Pack- aged resources to advance general chinese embedding,” 2023
2023
-
[34]
Ecapa- tdnn: Emphasized channel attention, propagation and aggrega- tion in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa- tdnn: Emphasized channel attention, propagation and aggrega- tion in tdnn based speaker verification,” inProc. IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 3830–3834
2020
-
[35]
all-minilm-l12-v2,
Sentence-Transformers, “all-minilm-l12-v2,” https://huggingface. co/sentence-transformers/all-MiniLM-L12-v2, 2021
2021
-
[36]
Seen and unseen emo- tional style transfer for voice conversion with a new emotional speech dataset,
K. Zhou, B. Sisman, R. Liu, and H. Li, “Seen and unseen emo- tional style transfer for voice conversion with a new emotional speech dataset,” inICASSP 2021-2021 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 920–924
2021
-
[37]
Chinese natural speech complex emotion dataset,
X. Wu, M. Xu, A. Hamdullaet al., “Chinese natural speech complex emotion dataset,” Science Data Bank, V1, 2025, cSTR:31253.11.sciencedb.20968. [Online]. Available: https: //cstr.cn/31253.11.sciencedb.20968
2025
-
[38]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen et al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabil- ities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Bigvgan: A universal neural vocoder with large-scale training,
S. Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon, “Bigvgan: A universal neural vocoder with large-scale training,” in11th International Conference on Learning Representations, ICLR 2023, 2023
2023
-
[40]
emotion2vec: Self-supervised pre-training for speech emotion representation,
Z. Ma, Z. Zheng, J. Ye, J. Li, Z. Gao, S. Zhang, and X. Chen, “emotion2vec: Self-supervised pre-training for speech emotion representation,” inFindings of the Association for Computational Linguistics ACL 2024, 2024, pp. 15 747–15 760
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.