AgentRiskBOM: A Risk-Scoping Security Bill of Materials for Agentic AI Systems
Pith reviewed 2026-06-26 12:07 UTC · model grok-4.3
The pith
AgentRiskBOM adds runtime authority fields to bills of materials to document what AI agents can access, change, delegate, and prove.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
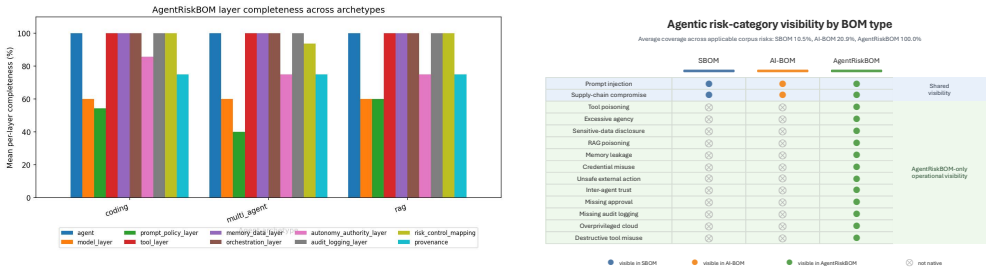
AgentRiskBOM is a JSON-schema artifact that references existing SBOM, AIBOM, and MLBOM while adding structured fields for runtime authority, achieving 14 out of 16 native capability coverage and 100 percent visibility across 14 risk categories on 13 agents and 52 scenarios, with full detection of 33 authority-drift mutations via its diff detector.
What carries the argument
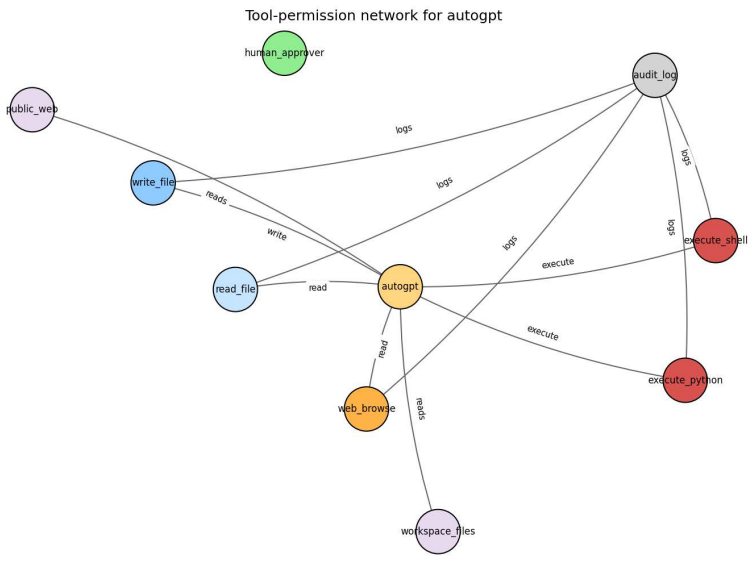
The AgentRiskBOM JSON schema defining fields for autonomy, tool permissions, memory, credential scope, approval gates, audit signals, inter-agent communication, and external action capability as an additive layer for risk scoping.
If this is right
- All tested agents validate against the schema, confirming it can be applied to real open-source implementations.
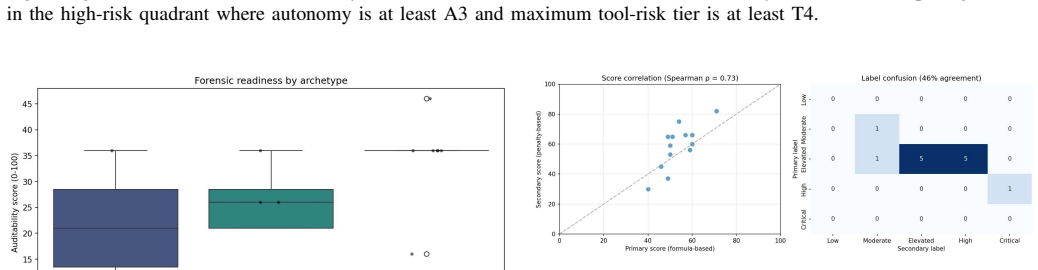
- The diff detector identifies the correct change type for every one of the 33 injected deployment mutations.
- A penalty-based secondary scorer produces rankings that correlate at 0.73 with the primary scorer, indicating consistent relative ordering.
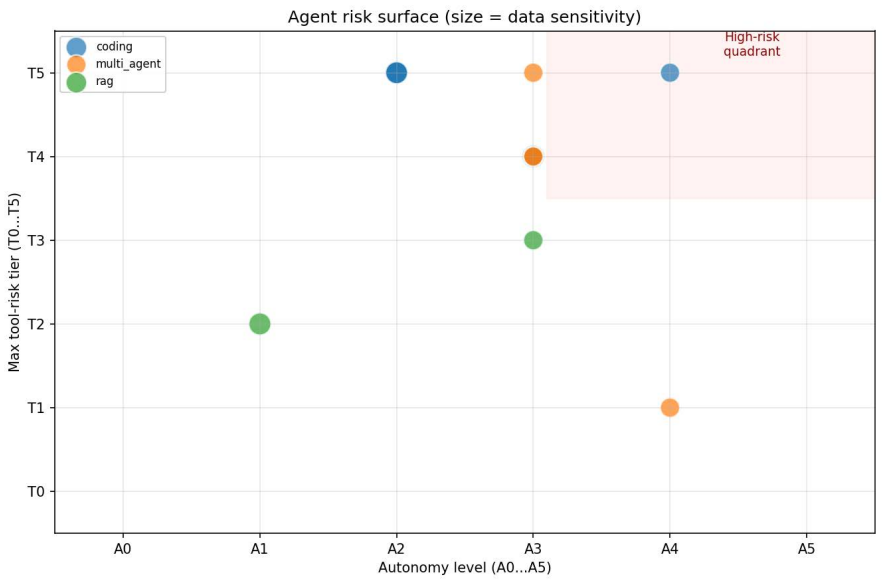
- AgentRiskBOM reaches 100 percent risk-category visibility while SBOM-like views reach 10.5 percent and AIBOM-like views reach 20.9 percent.
Where Pith is reading between the lines
- Teams could embed the schema in deployment pipelines to flag authority changes before production rollout.
- The fields might be extended to track capability drift over successive agent versions or fine-tunes.
- Regulatory or compliance frameworks could adopt similar structured records to require disclosure of agent permissions.
- The approach highlights the value of machine-readable artifacts that combine static metadata with dynamic authority descriptions.
Load-bearing premise
The 13 open-source agents spanning coding, RAG, and multi-agent archetypes plus the 52 risk scenarios across 14 categories represent the full space of deployed agentic AI systems and the risks they pose.
What would settle it
An agentic system whose risks lie outside the 14 modeled categories or whose capabilities evade capture by the defined fields would show the coverage is incomplete.
Figures
read the original abstract
Agentic AI systems retrieve private context, invoke tools, write files, call external services, coordinate with other agents, and may act without human approval. Existing bill of materials artifacts improve transparency for dependencies, model metadata, and training provenance, but leave an agentic transparency gap: capability opacity, the absence of a structured account of what a deployed agent can access, remember, change, delegate, and prove afterward. This paper introduces AgentRiskBOM, a security BOM for risk-scoping tool-using AI agents. It is an additive layer over SBOM, AIBOM, and MLBOM artifacts, referencing them where authoritative while adding fields for runtime authority: autonomy, tool permissions, memory, credential scope, approval gates, audit signals, inter-agent communication, and external action capability. We implement AgentRiskBOM as a JSON-schema artifact with a reproducible corpus, risk scenarios, scorer, diff detector, control mapper, and reports. We evaluate AgentRiskBOM on 13 open-source agents spanning coding, RAG, and multi-agent archetypes, plus 52 risk scenarios across 14 categories. The schema validates all 13 corpus artifacts. Coverage analysis gives AgentRiskBOM a native-equivalent score of 14 across 16 capability dimensions, vs. 1 for SBOM, 1.5 for AIBOM and 2 for MLBOM. Across modeled risk categories, AgentRiskBOM exposes 100% risk-category visibility vs. 10.5% for SBOM-like and 20.9% for AIBOM-like views. To test agentic authority drift, we inject 33 structured deployment mutations; the diff detector identifies the correct change type for all mutations. A secondary penalty-based scorer yields a Spearman correlation of 0.73 with the primary scorer, supporting rank-level consistency while showing that thresholds require human calibration. The results show that agentic AI security needs a machine-readable authority-and-risk artifact before incidents occur.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentRiskBOM, an additive security bill of materials layer for agentic AI systems that extends SBOM/AIBOM/MLBOM with runtime authority fields (autonomy, tool permissions, memory, credential scope, approval gates, audit signals, inter-agent communication, external action capability). It provides a JSON schema, reproducible corpus of 13 open-source agents (coding/RAG/multi-agent), 52 risk scenarios across 14 categories, a scorer, diff detector, and control mapper. Evaluation claims the schema validates all artifacts, yields native-equivalent coverage of 14/16 capability dimensions (vs. 1/1.5/2 for baselines), 100% risk-category visibility (vs. 10.5%/20.9%), correct identification of all 33 injected mutations, and 0.73 Spearman correlation between scorers.
Significance. If the schema and evaluation results hold, the work addresses a genuine transparency gap for deployed agentic systems that retrieve context, invoke tools, coordinate, and act autonomously. The explicit provision of a reproducible corpus, scenarios, scorer, and diff detector is a concrete strength that enables follow-on work and potential adoption in security tooling.
major comments (2)
- [Abstract] Abstract (evaluation paragraph): The headline coverage scores (14/16 dimensions, 100% risk-category visibility) and superiority claims versus SBOM/AIBOM/MLBOM are computed exclusively on the 13-agent/52-scenario corpus; the manuscript supplies no external mapping to published agent-failure taxonomies or production deployment statistics, so the results remain corpus-dependent rather than demonstrably general.
- [Abstract] Abstract (evaluation paragraph): The representativeness assumption—that the 13 open-source agents and 52 scenarios across 14 categories adequately sample autonomy levels, tool-use patterns, memory scopes, and inter-agent coordination in deployed systems—is load-bearing for the visibility and coverage results but is stated without supporting justification or sensitivity analysis.
Simulated Author's Rebuttal
We thank the referee for highlighting the scope and assumptions underlying the evaluation results. We address each major comment below and agree that qualifying the claims and adding justification will improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (evaluation paragraph): The headline coverage scores (14/16 dimensions, 100% risk-category visibility) and superiority claims versus SBOM/AIBOM/MLBOM are computed exclusively on the 13-agent/52-scenario corpus; the manuscript supplies no external mapping to published agent-failure taxonomies or production deployment statistics, so the results remain corpus-dependent rather than demonstrably general.
Authors: We agree that the headline quantitative results are derived from the 13-agent corpus and 52 scenarios, with no external mapping to published taxonomies or production statistics provided. The corpus was selected for reproducibility and to span coding, RAG, and multi-agent archetypes, while the scenarios cover 14 risk categories. We will revise the abstract to qualify the coverage and visibility claims as demonstrated on this corpus, add an explicit limitations discussion noting the corpus-dependent nature of the results, and include a mapping of the 14 categories to relevant published agent-failure taxonomies. revision: yes
-
Referee: [Abstract] Abstract (evaluation paragraph): The representativeness assumption—that the 13 open-source agents and 52 scenarios across 14 categories adequately sample autonomy levels, tool-use patterns, memory scopes, and inter-agent coordination in deployed systems—is load-bearing for the visibility and coverage results but is stated without supporting justification or sensitivity analysis.
Authors: The 13 agents were chosen to represent varying levels of autonomy, tool permissions, memory scopes, and coordination patterns, as described in the corpus section, and the 52 scenarios were designed to exercise the 14 categories. We acknowledge that the current manuscript does not provide explicit justification for this sampling or sensitivity analysis. We will add a dedicated paragraph in the evaluation section justifying the corpus composition with respect to the listed dimensions and note the lack of sensitivity analysis as a limitation. revision: yes
Circularity Check
No significant circularity; evaluation relies on external agents and defined scenarios
full rationale
The paper defines a JSON schema for AgentRiskBOM, applies it to 13 external open-source agents and 52 separately enumerated risk scenarios, and computes coverage by direct mapping to 16 capability dimensions and 14 risk categories. No equations, fitted parameters, or predictions are shown reducing to inputs by construction. No self-citations are invoked as load-bearing for uniqueness or ansatzes. The coverage comparison (14 vs. 1/1.5/2) follows from the schema's explicit fields rather than any statistical forcing or renaming of prior results. The derivation chain is self-contained against the provided external corpus.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing SBOM, AIBOM, and MLBOM artifacts provide authoritative baseline transparency for dependencies and model metadata
invented entities (1)
-
AgentRiskBOM runtime authority fields (autonomy, tool permissions, memory, credential scope, approval gates, audit signals, inter-agent communication, external action capability)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
AgentFlow: Building Agent Dependency Graphs for Static Analysis of Agent Programs
AgentFlow builds a framework-agnostic Agent Dependency Graph from agent program source code to support static analyses such as BOM generation and prompt-to-tool risk detection, evaluated on 5,399 real programs across ...
Reference graph
Works this paper leans on
-
[1]
B. Xia, T. Bi, Z. Xing, Q. Lu, and L. Zhu, ”An empirical study on software bill of materials: Where we stand and the road ahead.” In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pp. 2630-2642. IEEE, 2023
2023
-
[2]
Stalnaker, N
T. Stalnaker, N. Wintersgill, O. Chaparro, M. Di Penta, D. M. German, and D. Poshyvanyk, ”Boms away! inside the minds of stakeholders: A comprehensive study of bills of materials for software systems.” In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, pp. 1-13. 2024
2024
-
[3]
Mitchell, S
M. Mitchell, S. Wu, A. Zaldivar, P. Barnes, L. Vasserman, B. Hutchin- son, et al., ”Model cards for model reporting.” In Proceedings of the conference on fairness, accountability, and transparency, pp. 220-229. 2019
2019
-
[4]
Gebru, J
T. Gebru, J. Morgenstern, B. Vecchione, J. W. Vaughan, H. Wallach, H. Daum ´e III, et al., ”Datasheets for datasets.” Communications of the ACM 64, no. 12 (2021): 86-92
2021
- [5]
-
[6]
W. Vandendriessche, J. Thijsman, L. D’hooge, B. V olckaert, and M. Sebrechts, ”AIBoMGen: Generating an AI Bill of Materials for Se- cure, Transparent, and Compliant Model Training.” arXiv preprint arXiv:2601.05703 (2026)
arXiv 2026
-
[7]
ReAct: Synergizing Reasoning and Acting in Language Models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, et al., “ReAct: Synergizing Reasoning and Acting in Language Models,” in Proc. International Conference on Learning Representations (ICLR), 2023
2023
-
[8]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, et al., ”Toolformer: Language models can teach themselves to use tools.” Advances in neural information processing systems 36 (2023): 68539- 68551
2023
-
[9]
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, et al., ”Autogen: Enabling next-gen LLM applications via multi-agent conversations.” In First conference on language modeling. 2024
2024
-
[10]
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, et al., ”A survey on large language model based autonomous agents.” Frontiers of Computer Science 18, no. 6 (2024): 186345
2024
-
[11]
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, et al., ”Agentbench: Evaluating llms as agents.” In International Conference on Learning Representations, vol. 2024, pp. 52989-53046. 2024
2024
-
[12]
Jiang, N
W. Jiang, N. Synovic, R. Sethi, A. Indarapu, M. Hyatt, T. R. Schor- lemmer, et al., ”An empirical study of artifacts and security risks in the pre-trained model supply chain.” In Proceedings of the 2022 ACM workshop on software supply chain offensive research and ecosystem defenses, pp. 105-114. 2022
2022
-
[13]
Greshake, S
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, ”Not what you’ve signed up for: Compromising real-world llm- integrated applications with indirect prompt injection.” In Proceedings of the 16th ACM workshop on artificial intelligence and security, pp. 79-90. 2023
2023
-
[14]
J. Yi, Y . Xie, B. Zhu, E. Kiciman, G. Sun, X. Xie, et al., ”Benchmarking and defending against indirect prompt injection attacks on large language models.” In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pp. 1809-1820. 2025
2025
-
[15]
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, ”Injecagent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents.” In Findings of the Association for Computational Linguistics: ACL 2024, pp. 10471-10506. 2024
2024
-
[16]
M. Mirakhorli, D. Garcia, S. Dillon, K. Laporte, M. Morrison, H. Lu et al., ”A landscape study of open source and proprietary tools for software bill of materials (sbom).” arXiv preprint arXiv:2402.11151 (2024)
arXiv 2024
-
[17]
Torres-Arias, H
S. Torres-Arias, H. Afzali, T. K. Kuppusamy, R. Curtmola, and J. Cappos, ”in-toto: Providing farm-to-table guarantees for bits and bytes.” In 28th USENIX Security Symposium (USENIX Security 19), pp. 1393-
-
[18]
S. Nathanson, A. Lee, C. C. Kieffer, J. Junkin, J. Ye, A. Saeed, et al., ”AI Bill of Materials and Beyond: Systematizing Security Assurance through the AI Risk Scanning (AIRS) Framework.” arXiv preprint arXiv:2511.12668 (2025)
arXiv 2025
-
[19]
Y . Liu, G. Deng, Y . Li, K. Wang, Z. Wang, X. Wang, et al., ”Prompt injection attack against llm-integrated applications.” arXiv preprint arXiv:2306.05499 (2023)
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.