Selective Capability Unlearning in End-to-End Spoken Language Understanding
Pith reviewed 2026-06-26 00:53 UTC · model grok-4.3
The pith
Binding Subspace isolates intent directions in spoken language models to stop reconstruction of suppressed functionalities from forced prefixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that capability persistence in autoregressive SLU models arises from intent-conditioned directions in representation space, and that Binding Subspace (BSU) can isolate and attenuate these directions to reduce forced-prefix recoverability of unlearned intent-slot pairs while preserving performance on retained tasks.
What carries the argument
Binding Subspace (BSU), a representation-level framework that isolates and attenuates intent-conditioned directions underlying the intent-to-slot mapping in autoregressive models.
If this is right
- Suppressing a target intent no longer permits reconstruction of its slot structure when the intent prefix is externally supplied.
- Performance on retained intents and slots remains largely unchanged after attenuation.
- The method applies across multiple SLU benchmarks with consistent reduction in recoverability.
- Representation-level intervention addresses the structural failure that output-level suppression cannot fix.
Where Pith is reading between the lines
- Similar subspace attenuation could be tested on other autoregressive language models for selective unlearning of behaviors.
- If intent directions are low-rank, this might generalize to multi-intent or hierarchical SLU tasks.
- Deployed systems could use BSU to enforce policy changes by updating representations without full retraining.
Load-bearing premise
That intent-conditioned directions exist as isolatable linear or low-rank structures in the model's representation space and attenuating them does not degrade performance on retained intents and slots.
What would settle it
Measuring recoverability rates before and after BSU on a held-out SLU benchmark; if forced-prefix accuracy stays high or retained task accuracy drops sharply, the claim fails.
Figures

read the original abstract
Modern spoken language understanding (SLU) systems are increasingly deployed in real-world settings, where specific functionalities may need to be removed due to policy or safety constraints. In SLU, a functionality corresponds to an intent and its associated slot-generation behavior. However, in autoregressive models, suppressing a target intent does not eliminate the conditional mapping that generates slots conditioned on that intent. When the intent prefix is externally supplied, the model can reconstruct the original intent-slot structure. We identify this structural failure as \textbf{\emph{capability persistence}}. We propose \textit{\underline{B}inding \underline{S}ubspace (BSU)}, a representation-level framework that isolates and attenuates intent-conditioned directions underlying this mapping. Across SLU benchmarks, BSU substantially reduces forced-prefix recoverability while preserving retained performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies capability persistence in autoregressive end-to-end SLU models, where suppressing a target intent fails to eliminate the conditional intent-to-slot mapping when an external intent prefix is supplied. It proposes the Binding Subspace (BSU) framework, which isolates intent-conditioned directions in representation space and attenuates them to achieve selective unlearning. Experiments across SLU benchmarks report that BSU reduces forced-prefix recoverability while preserving performance on retained intents and slots.
Significance. If the empirical results hold, the work offers a representation-level approach to selective unlearning that targets persistent conditional mappings without requiring full model retraining. This is relevant for policy-compliant deployment of SLU systems. The contribution lies in formalizing capability persistence via forced-prefix recoverability and demonstrating a subspace attenuation procedure that maintains retained-task performance.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from an explicit statement of the precise mathematical definition of the intent-conditioned directions and the attenuation operator used in BSU (e.g., projection or scaling factor).
- [Experiments] Clarify the exact metric for 'forced-prefix recoverability' (e.g., exact match rate, slot F1 under prefix) and how it is computed on the test sets.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work identifying capability persistence in autoregressive SLU models and proposing the Binding Subspace (BSU) framework for selective unlearning. We appreciate the recommendation for minor revision and note that no specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper defines capability persistence as the failure of intent suppression to eliminate conditional slot mappings, then proposes the BSU method to isolate and attenuate intent-conditioned directions at the representation level, with claims resting on empirical benchmark results for reduced recoverability and preserved performance. No equations, derivations, fitted parameters, or self-citations appear in the text that would reduce any result to its inputs by construction; the argument is an empirical proposal evaluated externally on SLU benchmarks and is self-contained without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Autoregressive SLU models generate slots conditioned on intent prefixes even after intent suppression.
invented entities (1)
-
Binding Subspace (BSU)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Selective Capability Unlearning in End-to-End Spoken Language Understanding
Introduction Spoken language understanding (SLU) constitutes a core com- ponent of conversational systems. It enables devices like voice assistants and spoken interfaces to extract structured semantic information directly from speech [1, 2, 3, 4]. Modern end-to- end SLU models [5, 6] directly map acoustic input to seman- tic outputs and are widely adapted...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Problem Formulation We consider an end-to-end spoken language understanding (SLU) model that maps an input speech signalx∈ Xto a structured semantic frame represented as a token sequence y= (y 1, . . . , yT ). The sequence follows a fixed format in which the initial tokens encode an intent labeli∈ I, followed by slot-type and slot-value tokenss∈ S. The mo...
-
[3]
Rather than suppressing only the marginal intent probabilityp θ(if |x), BSU targets hidden-state direc- tions associated with intent-conditioned slot generation
BSU: Binding Subspace Unlearning Building on this formulation, we introduceBinding Subspace Unlearning (BSU), a two-stage unlearning framework that in- tervenes in the model’s representation space to mitigate capa- bility persistence. Rather than suppressing only the marginal intent probabilityp θ(if |x), BSU targets hidden-state direc- tions associated w...
-
[4]
Experimental Setup 4.1. Datasets and Task Setup Datasets.We evaluate selective capability unlearning on SLURP [1], a standard end-to-end SLU benchmark dataset with each utterance annotated by an intent and corresponding slot- value pairs. To assess cross-lingual robustness, we additionally evaluate the French subset of SpeechMASSIVE [16], which fol- lows ...
-
[5]
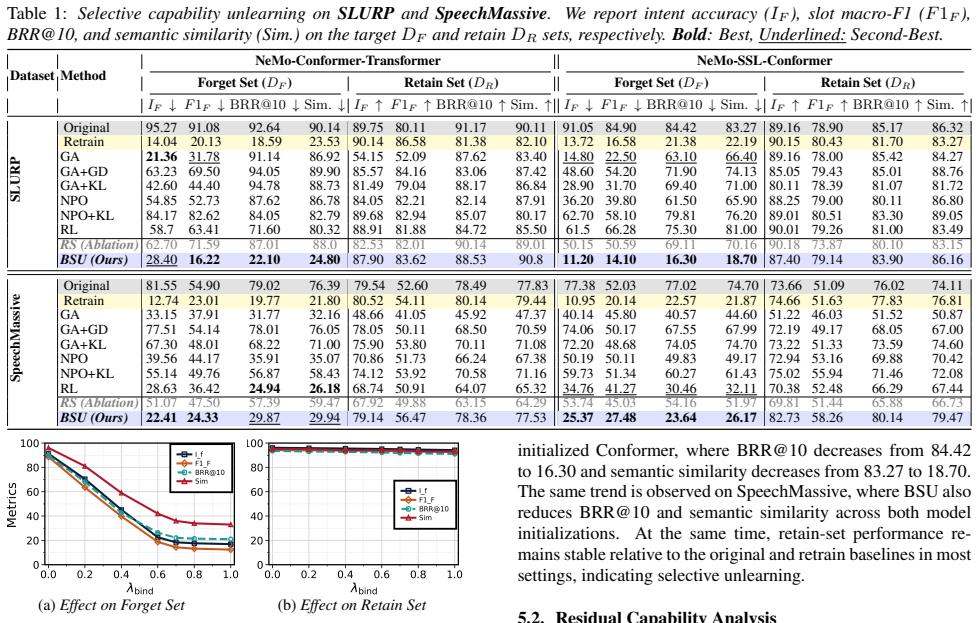
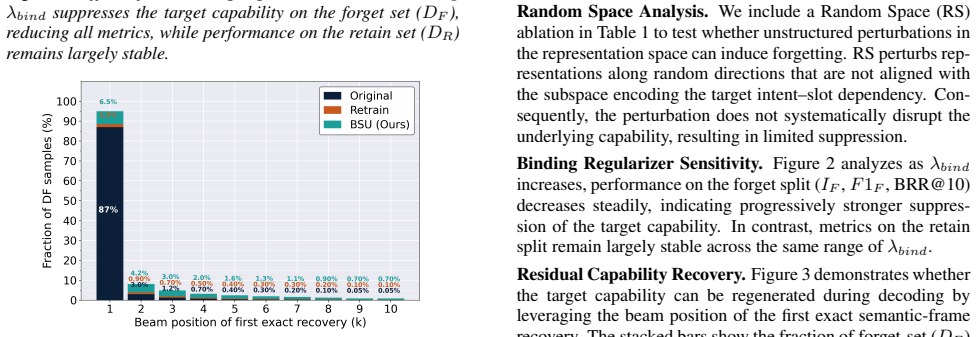
Results and Analysis 5.1. Comparison with Baselines We evaluate whether slot content associated with the target in- tent can still be generated when the intent prefix is provided at test time, while the performance on non-target intents is pre- served. As shown in Table 1, gradient and preference-based baselines (GA, GA+KL, NPO) reduce marginal intent pre...
-
[6]
We proposeBinding Subspace Un- learning (BSU), which removes this dependency by targeting representation-level binding directions
Conclusion In this work, we show that suppressing marginal intent pre- diction alone does not eliminate the conditional mapping gov- erning slot generation, leading to capability persistence under forced-prefix decoding. We proposeBinding Subspace Un- learning (BSU), which removes this dependency by targeting representation-level binding directions. Exper...
-
[7]
Acknowledgments We acknowledge the institutional and computational support provided by the Department of Data Science and Engineering, Indian Institute of Science Education and Research Bhopal
-
[8]
Generative AI Use Disclosure Generative AI tools were used only for language editing and polishing. All scientific content, experimental design, analyses, results, and conclusions were developed and verified by the au- thors, who take full responsibility for the content of this paper
-
[9]
Slurp: A spoken language understanding resource package,
E. Bastianelli, A. Vanzo, P. Swietojanski, and V . Rieser, “Slurp: A spoken language understanding resource package,” inProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 7252–7262
2020
-
[10]
Y . Wang, A. Boumadane, and A. Heba, “A fine-tuned wav2vec 2.0/hubert benchmark for speech emotion recognition, speaker verification and spoken language understanding,”arXiv preprint arXiv:2111.02735, 2021
-
[11]
Espnet-slu: Advancing spoken language understanding through espnet,
S. Arora, S. Dalmia, P. Denisov, X. Chang, Y . Ueda, Y . Peng, Y . Zhang, S. Kumar, K. Ganesan, B. Yanet al., “Espnet-slu: Advancing spoken language understanding through espnet,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7167– 7171
2022
-
[12]
Integration of pre-trained networks with continuous token interface for end-to-end spoken language understanding,
S. Seo, D. Kwak, and B. Lee, “Integration of pre-trained networks with continuous token interface for end-to-end spoken language understanding,” inICASSP 2022-2022 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7152–7156
2022
-
[13]
H. Huang, J. Balam, and B. Ginsburg, “Leveraging pretrained asr encoders for effective and efficient end-to-end speech intent classification and slot filling,”arXiv preprint arXiv:2307.07057, 2023
-
[14]
Leveraging acoustic and lin- guistic embeddings from pretrained speech and language mod- els for intent classification,
B. Sharma, M. Madhavi, and H. Li, “Leveraging acoustic and lin- guistic embeddings from pretrained speech and language mod- els for intent classification,” inICASSP 2021-2021 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 7498–7502
2021
-
[15]
From speech to data: Unraveling google’s use of voice data for user profiling,
X. Ma and S. Chen, “From speech to data: Unraveling google’s use of voice data for user profiling,”arXiv preprint arXiv:2403.05586, 2024
-
[16]
Recent trends in deep learning based personality detection,
Y . Mehta, N. Majumder, A. Gelbukh, and E. Cambria, “Recent trends in deep learning based personality detection,”Artificial In- telligence Review, vol. 53, no. 4, pp. 2313–2339, 2020
2020
-
[17]
A. Koudounas, C. Savelli, F. Giobergia, and E. Baralis, “” alexa, can you forget me?” machine unlearning benchmark in spoken language understanding,”arXiv preprint arXiv:2505.15700, 2025
-
[18]
The eu general data protection regulation (gdpr),
P. V oigt and A. V on dem Bussche, “The eu general data protection regulation (gdpr),”A practical guide, 1st ed., Cham: Springer In- ternational Publishing, vol. 10, no. 3152676, pp. 10–5555, 2017
2017
-
[19]
An introduction to the california consumer pri- vacy act (ccpa),
E. Goldman, “An introduction to the california consumer pri- vacy act (ccpa),”Santa Clara Univ. Legal Studies Research Paper, 2020
2020
-
[20]
Machine unlearning: Solu- tions and challenges,
J. Xu, Z. Wu, C. Wang, and X. Jia, “Machine unlearning: Solu- tions and challenges,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 8, no. 3, pp. 2150–2168, 2024
2024
-
[21]
A learning algorithm for contin- ually running fully recurrent neural networks,
R. J. Williams and D. Zipser, “A learning algorithm for contin- ually running fully recurrent neural networks,”Neural computa- tion, vol. 1, no. 2, pp. 270–280, 1989
1989
-
[22]
Sok: Machine unlearning for large language models,
J. Ren, Y . Xing, Y . Cui, C. C. Aggarwal, and H. Liu, “Sok: Machine unlearning for large language models,”arXiv preprint arXiv:2506.09227, 2025
-
[23]
To- wards unbounded machine unlearning,
M. Kurmanji, P. Triantafillou, J. Hayes, and E. Triantafillou, “To- wards unbounded machine unlearning,”Advances in neural infor- mation processing systems, vol. 36, pp. 1957–1987, 2023
1957
-
[24]
Speech-massive: A multilingual speech dataset for slu and be- yond,
B. Lee, I. Calapodescu, M. Gaido, M. Negri, L. Besacieret al., “Speech-massive: A multilingual speech dataset for slu and be- yond,” inProceedings of Interspeech2024, 2024, pp. 817–821
2024
-
[25]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Eval- uating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
BERTScore: Evaluating Text Generation with BERT
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,”arXiv preprint arXiv:1904.09675, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[27]
Large language model unlearning,
Y . Yao, X. Xu, and Y . Liu, “Large language model unlearning,” Advances in Neural Information Processing Systems, vol. 37, pp. 105 425–105 475, 2024
2024
-
[28]
Extracting training data from large language models,
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingssonet al., “Extracting training data from large language models,” in30th USENIX security symposium (USENIX Security 21), 2021, pp. 2633–2650
2021
-
[29]
The Curious Case of Neural Text Degeneration
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y . Choi, “The curious case of neural text degeneration,”arXiv preprint arXiv:1904.09751, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[30]
Diverse beam search for improved description of complex scenes,
A. Vijayakumar, M. Cogswell, R. Selvaraju, Q. Sun, S. Lee, D. Crandall, and D. Batra, “Diverse beam search for improved description of complex scenes,” inProceedings of the AAAI Con- ference on Artificial Intelligence, vol. 32, no. 1, 2018
2018
-
[31]
Sentence-bert: Sentence embed- dings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embed- dings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 2019, pp. 3982–3992
2019
-
[32]
Eternal sunshine of the spotless net: Selective forgetting in deep networks,
A. Golatkar, A. Achille, and S. Soatto, “Eternal sunshine of the spotless net: Selective forgetting in deep networks,” inProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9304–9312
2020
-
[33]
Amnesiac machine learn- ing,
L. Graves, V . Nagisetty, and V . Ganesh, “Amnesiac machine learn- ing,” inProceedings of the AAAI conference on artificial intelli- gence, vol. 35, no. 13, 2021, pp. 11 516–11 524
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.