TL++: Accuracy and Privacy Preserving Traversal Learning for Distributed Intelligent Systems
Pith reviewed 2026-06-25 20:57 UTC · model grok-4.3
The pith
TL++ recovers centralized mini-batch gradient behavior in distributed training by building virtual batches across nodes and exchanging only cut-layer activations rather than full models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
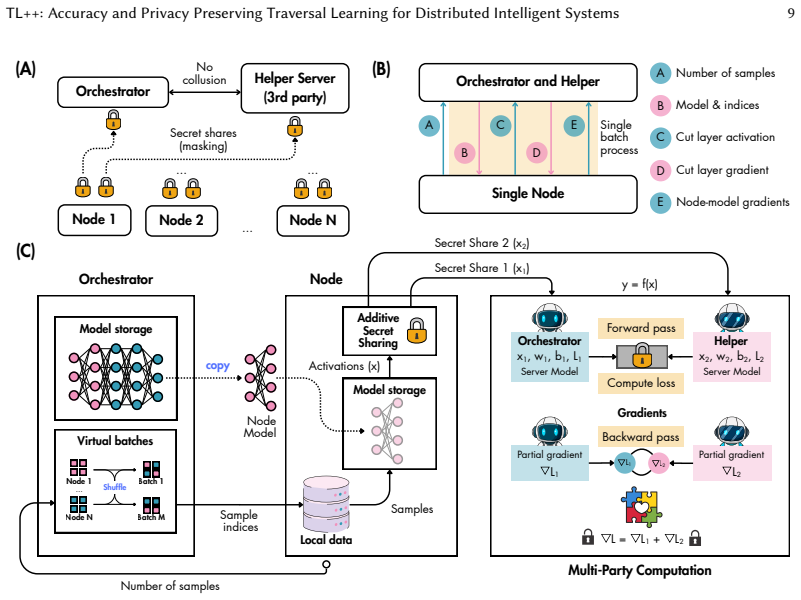
TL++ is a two-mode framework that, under explicit synchronization assumptions, constructs virtual batches across data silos so that cut-layer activations and gradients produce the same update direction as a centralized mini-batch; base mode transmits only those tensors while secure mode secret-shares them between an orchestrator and a helper server, keeping labels visible only to the orchestrator and limiting exactness to linear server paths.
What carries the argument
Virtual-batch construction under explicit synchronization assumptions, which recovers centralized mini-batch gradient statistics from cut-layer exchanges instead of full-model synchronization.
If this is right
- TL++ base cut 1 reaches 91.41 percent accuracy (SD 0.19) on CIFAR-10, more than 12 points above the strongest measured non-TL++ baseline.
- Exact secure cut 3 reaches 90.93 percent (SD 0.17) on the same task.
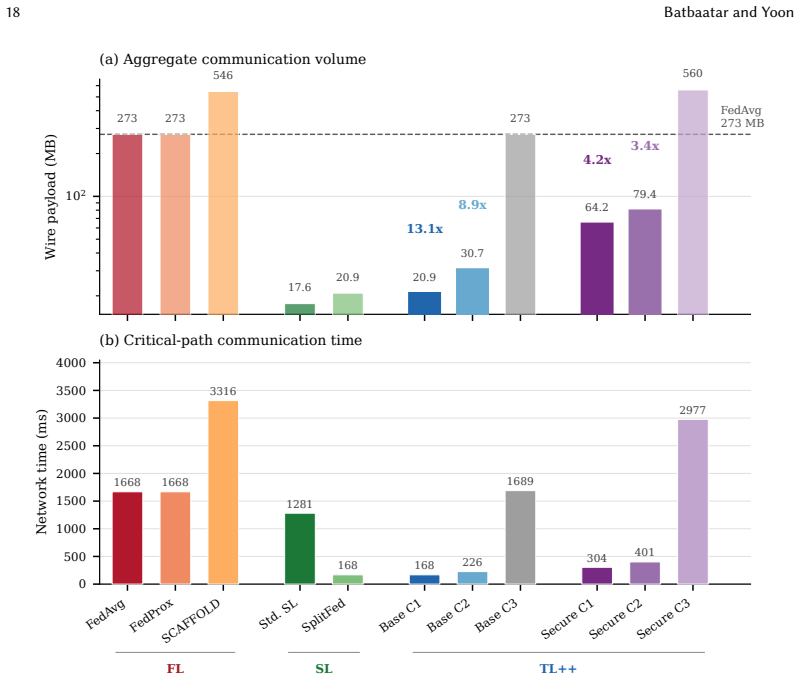
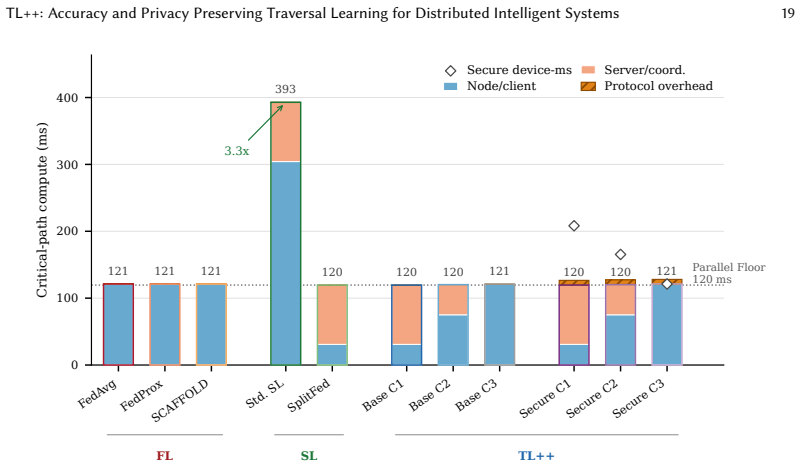
- Per-step communication drops by a factor of 13.1 relative to full-model synchronization.
- The same accuracy ordering holds for full fine-tuning and LoRA on BioGPT/PubMedQA.
- Protection is confined to a semi-honest two-server model; nonlinear operations still require MPC or approximation.
Where Pith is reading between the lines
- If the synchronization assumption can be relaxed to asynchronous or partially overlapping batches, the framework could apply to a wider range of edge-device deployments.
- The restriction of exact secure mode to linear or affine paths points to a concrete next step: replace the linear server path with lightweight nonlinear secure computation primitives.
- Because labels remain visible to the orchestrator, any end-to-end private label setting would require an additional protocol layer not described here.
Load-bearing premise
Nodes can be synchronized so that their partial batches together behave exactly like one centralized mini-batch.
What would settle it
Removing the synchronization step and virtual-batch construction and re-running the CIFAR-10 experiments yields accuracies no higher than standard split learning.
Figures
read the original abstract
Distributed intelligent systems increasingly need to train across data silos without centralizing raw data. Federated learning keeps data local but can suffer under heterogeneous partitions and requires repeated full-model exchange. Split learning reduces communication through cut-layer activations, but standard protocols generally do not recover centralized mini-batch gradient behavior and may expose activations and gradients in plaintext. We present TL++, a two-mode traversal-learning framework that constructs virtual batches across nodes to recover centralized mini-batch gradient behavior under explicit synchronization assumptions. Base mode exchanges cut-layer activations and gradients rather than full models. Secure mode secret-shares each cut-layer activation and gradient between an orchestrator and a non-colluding helper, preventing either server from observing plaintext cut-layer tensors. This protection is limited to a semi-honest two-server setting; labels and loss-related outputs remain visible to the orchestrator. In the lightweight secure path evaluated here, exactness requires a linear or affine server path, while nonlinear operations require nonlinear MPC or approximation. We formalize TL++, analyze communication and computation costs, and evaluate it against federated and split-learning baselines on CIFAR-10 and BioGPT/PubMedQA using full fine-tuning and LoRA. On CIFAR-10, TL++ base cut 1 and exact secure cut 3 achieve accuracies of 91.41% (SD 0.19) and 90.93% (SD 0.17), respectively, exceeding the strongest measured non-TL++ baseline by more than 12 percentage points. TL++ base cut 1 also reduces per-step communication by 13.1-fold relative to full-model synchronization. PubMedQA results similarly favor TL++. Overall, TL++ approaches centralized-training performance while reducing communication and providing activation-level secret sharing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TL++, a two-mode traversal-learning framework for distributed training across data silos without centralizing raw data. Base mode exchanges cut-layer activations and gradients to construct virtual batches that recover centralized mini-batch gradient behavior under explicit synchronization assumptions. Secure mode applies secret sharing to cut-layer tensors between an orchestrator and non-colluding helper in a semi-honest two-server setting (limited to linear/affine paths for exactness). Evaluations on CIFAR-10 report 91.41% (SD 0.19) accuracy for TL++ base cut 1 and 90.93% (SD 0.17) for exact secure cut 3, exceeding the strongest non-TL++ baseline by more than 12 percentage points, alongside a 13.1-fold per-step communication reduction relative to full-model synchronization. Similar favorable results are claimed for PubMedQA under full fine-tuning and LoRA.
Significance. If the synchronization assumptions hold in practice and the accuracy margins prove robust, TL++ could offer a meaningful advance in privacy-preserving distributed learning by bridging federated and split-learning approaches with activation-level protection and near-centralized performance at lower communication cost. The cost formalization and multi-dataset evaluation (including LoRA) strengthen its potential utility for heterogeneous data silos.
major comments (2)
- [Abstract] Abstract: The central accuracy claims (91.41% and 90.93% on CIFAR-10, >12pp margin) rest on explicit synchronization enabling virtual batches that exactly recover centralized mini-batch gradient behavior. No protocol details, latency model, or ablation under imperfect/delayed synchronization are supplied, which is load-bearing because the advantage over standard split learning disappears without it.
- [Abstract] Abstract: No information is given on baseline implementations, number of runs underlying the reported SD values, data partitioning strategy, or statistical testing, preventing assessment of whether the performance margins are reproducible and significant.
minor comments (1)
- [Abstract] The description of the 'lightweight secure path' versus full nonlinear MPC for exactness in secure mode would benefit from additional clarification on approximation methods for nonlinear operations.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments. We address each point below and will revise the manuscript accordingly to clarify the synchronization assumptions and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central accuracy claims (91.41% and 90.93% on CIFAR-10, >12pp margin) rest on explicit synchronization enabling virtual batches that exactly recover centralized mini-batch gradient behavior. No protocol details, latency model, or ablation under imperfect/delayed synchronization are supplied, which is load-bearing because the advantage over standard split learning disappears without it.
Authors: The manuscript explicitly qualifies all accuracy claims as holding under the stated synchronization assumptions (abstract and Section 3). The contribution is to show that virtual batches recover centralized mini-batch gradients when those assumptions hold, distinguishing TL++ from standard split learning. We agree that additional protocol details would improve clarity. In revision we will add a subsection detailing the synchronization protocol, a basic latency model based on per-round communication, and a qualitative discussion of sensitivity to delays. A full empirical ablation under imperfect synchronization lies outside the current experimental budget and is noted as future work. revision: partial
-
Referee: [Abstract] Abstract: No information is given on baseline implementations, number of runs underlying the reported SD values, data partitioning strategy, or statistical testing, preventing assessment of whether the performance margins are reproducible and significant.
Authors: These details appear in the full manuscript (Section 4). Baselines follow the standard federated and split-learning implementations cited therein; the reported SDs are computed over 5 independent runs; CIFAR-10 uses Dirichlet non-IID partitioning as described; and t-test p-values can be added. Because the comment targets the abstract, we will ensure the experimental section is explicitly cross-referenced and, space permitting, add a brief clause on run count to the abstract. revision: yes
Circularity Check
No circularity; empirical framework with independent experimental validation
full rationale
The paper introduces TL++ as a traversal-learning framework, formalizes it, analyzes costs, and reports empirical accuracies on CIFAR-10 and PubMedQA against baselines. No equations, uniqueness theorems, ansatzes, or fitted parameters are presented that reduce by construction to prior inputs or self-citations. The central claims rest on measured performance differences under stated synchronization assumptions, which are externally falsifiable via replication rather than tautological. This is a standard self-contained empirical systems paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Towards Value-Constrained Credit Assignment in Fully Delegated AI Cooperatives
Proposes value-constrained credit assignment via gradient filtering and traversal learning for fully delegated AI cooperatives.
Reference graph
Works this paper leans on
-
[1]
Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li , title =
Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep Learning with Differential Privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS ’16). ACM, New York, NY, USA, 308–318. doi:10.1145/2976749.2978318
-
[2]
Whatmough, and Venkatesh Saligrama
Durmus Alp Emre Acar, Yue Zhao, Ramon Matas, Matthew Mattina, Paul N. Whatmough, and Venkatesh Saligrama
-
[3]
InInternational Conference on Learning Representations
Federated Learning Based on Dynamic Regularization. InInternational Conference on Learning Representations. OpenReview.net, Virtual, 1–36. https://openreview.net/forum?id=B7v4QMR6Z9w
-
[4]
Ege Aktemur, Ege Zorlutuna, Kaan Bilgili, Tacettin Emre Bok, Berrin Yanikoglu, and Suha Orhun Mutluergil. 2024. Going Forward-Forward in Distributed Deep Learning.arXiv preprint arXiv:2404.08573abs/2404.08573 (2024), 1–9. doi:10.48550/arXiv.2404.08573
-
[5]
Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan Vojnovic. 2017. QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding. InAdvances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc., Long Beach, CA, USA, 1709–1720
2017
-
[6]
Erdenebileg Batbaatar, Jeonggeol Kim, Yongcheol Kim, and Young Yoon. 2025. Traversal Learning Coordination for lossless and efficient distributed learning.Expert Systems42, 11 (2025), e70141. doi:10.1111/exsy.70141
-
[7]
Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Anima Anandkumar. 2018. signSGD: Compressed Optimisation for Non-Convex Problems. InProceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 80). PMLR, Stockholm, Sweden, 560–569
2018
-
[8]
Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H.˜Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. 2017. Practical secure aggregation for privacy-preserving machine learning. InProceedings ACM Trans. Intell. Syst. Technol., Vol. 1, No. 1, Article . Publication date: June 2026. TL++: Accuracy and Privacy Preservin...
-
[9]
Jung Hee Cheon, Andrey Kim, Miran Kim, and Yongsoo Song. 2017. Homomorphic Encryption for Arithmetic of Approximate Numbers. InAdvances in Cryptology – ASIACRYPT 2017. Lecture Notes in Computer Science, Vol. 10624. Springer International Publishing, Cham, Switzerland, 409–437. doi:10.1007/978-3-319-70694-8_15
-
[10]
Ivan Damgård, Valerio Pastro, Nigel Smart, and Sarah Zakarias. 2012. Multiparty computation from somewhat homomorphic encryption. InAdvances in Cryptology – CRYPTO 2012. Lecture Notes in Computer Science, Vol. 7417. Springer Berlin Heidelberg, Berlin, Heidelberg, 643–662. doi:10.1007/978-3-642-32009-5_38
-
[11]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient Finetuning of Quantized LLMs. InAdvances in Neural Information Processing Systems, Vol. 36. Curran Associates, Inc., New Orleans, LA, USA, 10088–10115
2023
-
[12]
Cynthia Dwork. 2008. Differential privacy: A survey of results. InTheory and Applications of Models of Computation. Lecture Notes in Computer Science, Vol. 4978. Springer Berlin Heidelberg, Berlin, Heidelberg, 1–19. doi:10.1007/978-3- 540-79228-4_1
-
[13]
European Parliament and Council of the European Union. 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of Such Data, and Repealing Directive 95/46/EC (General Data Protection Regulation). Official Journ...
2016
-
[14]
Jonas Geiping, Hartmut Bauermeister, Hannah Dr"oge, and Michael Moeller. 2020. Inverting Gradients—How Easy Is It to Break Privacy in Federated Learning?. InAdvances in Neural Information Processing Systems, Vol. 33. Curran Associates, Inc., Virtual, 16937–16947
2020
-
[15]
Craig Gentry. 2009. Fully homomorphic encryption using ideal lattices. InProceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC ’09). ACM, Bethesda, MD, USA, 169–178. doi:10.1145/1536414.1536440
-
[16]
Ran Gilad-Bachrach, Nathan Dowlin, Kim Laine, Kristin Lauter, Michael Naehrig, and John Wernsing. 2016. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. InProceedings of the 33rd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 48). PMLR, New York, NY, USA, 201–210. https...
2016
-
[17]
Xavier Glorot and Yoshua Bengio. 2010. Understanding the Difficulty of Training Deep Feedforward Neural Networks. InProceedings of the 13th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 9). PMLR, Chia Laguna Resort, Sardinia, Italy, 249–256. https://proceedings.mlr.press/v9/glorot10a.html
2010
-
[18]
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Adi Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. 2017. Accurate, large minibatch SGD: Training ImageNet in 1 hour.arXiv preprint arXiv:1706.02677 abs/1706.02677 (2017), 1–11
Pith/arXiv arXiv 2017
-
[19]
Otkrist Gupta and Ramesh Raskar. 2018. Distributed learning of deep neural network over multiple agents.Journal of Network and Computer Applications116, 1 (2018), 1–8
2018
-
[20]
Zecheng He, Tianwei Zhang, and Ruby B. Lee. 2019. Model inversion attacks against collaborative inference. In Proceedings of the 35th Annual Computer Security Applications Conference (ACSAC ’19). ACM, New York, NY, USA, 148–162. doi:10.1145/3359789.3359824
-
[21]
Geoffrey Hinton. 2022. The Forward-Forward Algorithm: Some Preliminary Investigations.arXiv preprint arXiv:2212.13345abs/2212.13345 (2022), 1–16. doi:10.48550/arXiv.2212.13345
-
[22]
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-Efficient Transfer Learning for NLP. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97). PMLR, Long Beach, CA, USA, 2790–2799
2019
-
[23]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
-
[24]
InProceedings of the 10th International Conference on Learning Representations
LoRA: Low-rank adaptation of large language models. InProceedings of the 10th International Conference on Learning Representations. OpenReview.net, Virtual, 13 pages. https://openreview.net/forum?id=nZeVKeeFYf9
-
[25]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. PubMedQA: A dataset for biomedical research question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP ’19). Association for Computational Li...
2019
-
[26]
Chiraag Juvekar, Vinod Vaikuntanathan, and Anantha Chandrakasan. 2018. GAZELLE: A Low Latency Framework for Secure Neural Network Inference. In27th USENIX Security Symposium (USENIX Security 18). USENIX Association, Baltimore, MD, USA, 1651–1669. https://www.usenix.org/conference/usenixsecurity18/presentation/juvekar
2018
-
[27]
˜Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, and Rachel Cummings
Peter Kairouz, H. ˜Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, and Rachel Cummings. 2021. Advances and open problems in federated learning.Foundations and Trends®in Machine Learning14, 1–2 (2021), 1–210. https://www.nowpublishers.com/article/ ACM Trans. Intell. Sys...
2021
-
[28]
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh
-
[29]
InProceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol
SCAFFOLD: Stochastic controlled averaging for federated learning. InProceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 119). PMLR, Virtual, 5132–5143
-
[30]
Yu, Peter Richtárik, Ananda Theertha Suresh, and Dave Bacon
Jakub Konečný, H.˜Brendan McMahan, Felix X. Yu, Peter Richtárik, Ananda Theertha Suresh, and Dave Bacon. 2016. Federated learning: Strategies for improving communication efficiency.arXiv preprint arXiv:1610.05492abs/1610.05492, 1 (2016), 1–38
Pith/arXiv arXiv 2016
-
[31]
Alex Krizhevsky and Geoffrey Hinton. 2009. Learning multiple layers of features from tiny images.Technical Report1, 4 (2009), 1–60
2009
-
[32]
Nishant Kumar, Mayank Rathee, Nishanth Chandran, Divya Gupta, Aseem Rastogi, and Rahul Sharma. 2020. CrypTFlow: Secure TensorFlow Inference. In2020 IEEE Symposium on Security and Privacy. IEEE, San Francisco, CA, USA, 336–353
2020
-
[33]
Li Li, Yuxi Fan, Mike Tse, and Kuo-Yi Lin. 2020. A review of applications in federated learning.Computers & Industrial Engineering149, 1 (2020), 106854
2020
-
[34]
Qinbin Li, Bingsheng He, and Dawn Song. 2021. Model-Contrastive Federated Learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, Virtual, 10713–10722
2021
-
[35]
Tian Li, Shengyuan Hu, Ahmad Beirami, and Virginia Smith. 2021. Ditto: Fair and Robust Federated Learning Through Personalization. InProceedings of the 38th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 139). PMLR, Virtual, 6357–6368
2021
-
[37]
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. 2020. Federated optimization in heterogeneous networks. InProceedings of Machine Learning and Systems, Vol. 2. MLSys, Austin, TX, USA, 429–450
2020
-
[38]
Xiaoxiao Li, Meirui Jiang, Xiaofei Zhang, Michael Kamp, and Qi Dou. 2021. FedBN: Federated Learning on Non-IID Features via Local Batch Normalization. InInternational Conference on Learning Representations. OpenReview.net, Virtual, 1–18. https://openreview.net/forum?id=6YEQUn0QICG
2021
-
[39]
Yujun Lin, Song Han, Huizi Mao, Yu Wang, and William J. Dally. 2018. Deep gradient compression: Reducing the communication bandwidth for distributed training. InProceedings of the 6th International Conference on Learning Representations. OpenReview.net, Vancouver, BC, Canada, 14 pages. https://openreview.net/forum?id=SkhQHMW0W
2018
-
[40]
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. 2022. BioGPT: Generative Pre-trained Transformer for Biomedical Text Generation and Mining.Briefings in Bioinformatics23, 6 (2022), bbac409. doi:10.1093/bib/bbac409
-
[41]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication- efficient learning of deep networks from decentralized data. InProceedings of the 20th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 54). PMLR, Fort Lauderdale, FL, USA, 1273–1282
2017
-
[42]
Ilya Mironov. 2017. Rényi differential privacy. InProceedings of the 30th IEEE Computer Security Foundations Symposium (CSF ’17). IEEE, Santa Barbara, CA, USA, 263–275. doi:10.1109/CSF.2017.11
-
[43]
Pratyush Mishra, Ryan Lehmkuhl, Akshayaram Srinivasan, Wenting Zheng, and Raluca Ada Popa. 2020. Delphi: A Cryptographic Inference Service for Neural Networks. In29th USENIX Security Symposium (USENIX Security 20). USENIX Association, Virtual, 2505–2522. https://www.usenix.org/conference/usenixsecurity20/presentation/mishra
2020
-
[44]
Payman Mohassel and Peter Rindal. 2018. ABY3: A Mixed Protocol Framework for Machine Learning. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. ACM, Toronto, ON, Canada, 35–52
2018
-
[45]
Payman Mohassel and Yupeng Zhang. 2017. SecureML: A System for Scalable Privacy-Preserving Machine Learning. InProceedings of the 2017 IEEE Symposium on Security and Privacy (SP ’17). IEEE, San Jose, CA, USA, 19–38. doi:10. 1109/SP.2017.12
2017
-
[46]
John Nguyen, Kshitiz Malik, Maziar Sanjabi, and Michael Rabbat. 2022. Federated Learning with Buffered Asynchronous Aggregation. InProceedings of The 25th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 151). PMLR, Virtual, 3581–3607
2022
-
[47]
Arild Nøkland. 2016. Direct Feedback Alignment Provides Learning in Deep Neural Networks. InAdvances in Neural Information Processing Systems, Vol. 29. Curran Associates, Inc., Barcelona, Spain, 1–9. doi:10.48550/arXiv.1609.01596
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1609.01596 2016
-
[48]
Dario Pasquini, Giuseppe Ateniese, and Massimo Bernaschi. 2021. Unleashing the tiger: Inference attacks on split learning. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS ’21). ACM, New York, NY, USA, 2113–2129. doi:10.1145/3460120.3485259
-
[49]
Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Konečný, Sanjiv Kumar, and H
Sashank J. Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Konečný, Sanjiv Kumar, and H. Brendan McMahan. 2021. Adaptive Federated Optimization. InInternational Conference on Learning Representations. ACM Trans. Intell. Syst. Technol., Vol. 1, No. 1, Article . Publication date: June 2026. TL++: Accuracy and Privacy Preserving Tra...
2021
-
[50]
Amirhossein Reisizadeh, Aryan Mokhtari, Hamed Hassani, Ali Jadbabaie, and Ramtin Pedarsani. 2020. FedPAQ: A Communication-Efficient Federated Learning Method with Periodic Averaging and Quantization. InProceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 108). PM...
2020
-
[51]
Felix Sattler, Klaus-Robert Müller, and Wojciech Samek. 2019. Clustered federated learning: Model-agnostic distributed multi-task optimization under privacy constraints.arXiv preprint arXiv:1910.01991abs/1910.01991 (2019), 1–16. https://arxiv.org/abs/1910.01991
arXiv 2019
-
[52]
Sinem Sav, Apostolos Pyrgelis, Jean Louis Raisaro, David Froelicher, Juan Ramon Troncoso-Pastoriza, and Jean- Pierre Hubaux. 2024. CURE: Privacy-preserving split learning done right. arXiv preprint arXiv:2407.08977. https: //arxiv.org/abs/2407.08977
Pith/arXiv arXiv 2024
-
[53]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership Inference Attacks Against Machine Learning Models. InProceedings of the 2017 IEEE Symposium on Security and Privacy (SP ’17). IEEE, San Jose, CA, USA, 3–18. doi:10.1109/SP.2017.41
-
[54]
Karen Simonyan and Andrew Zisserman. 2015. Very Deep Convolutional Networks for Large-Scale Image Recognition. InProceedings of the 3rd International Conference on Learning Representations (ICLR ’15). Computational and Biological Learning Society, San Diego, CA, USA, 1–14. https://arxiv.org/abs/1409.1556
Pith/arXiv arXiv 2015
-
[55]
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A Simple Way to Prevent Neural Networks from Overfitting.Journal of Machine Learning Research15, 56 (2014), 1929–1958. https://jmlr.org/papers/v15/srivastava14a.html
2014
-
[56]
Sebastian U. Stich. 2019. Local SGD Converges Fast and Communicates Little. InInternational Conference on Learning Representations. OpenReview.net, New Orleans, LA, USA, 1–16. https://openreview.net/forum?id=S1g2JnRcFX
2019
-
[57]
Chandra Thapa, Pathum Chamikara Mahawaga Arachchige, Seyit Camtepe, and Lichao Sun. 2022. SplitFed: When federated learning meets split learning. InProceedings of the 36th AAAI Conference on Artificial Intelligence (AAAI ’22). AAAI Press, Virtual, 8485–8493. doi:10.1609/aaai.v36i8.20825
-
[58]
United States Congress. 1996. Health Insurance Portability and Accountability Act of 1996. Public Law 104–191, 110 Stat. 1936. https://aspe.hhs.gov/reports/health-insurance-portability-accountability-act-1996
1996
-
[59]
Praneeth Vepakomma, Otkrist Gupta, Tristan Swedish, and Ramesh Raskar. 2018. Split learning for health: Distributed deep learning without sharing raw patient data.arXiv preprint arXiv:1812.00564abs/1812.00564, 1 (2018), 1–6
Pith/arXiv arXiv 2018
-
[60]
Praneeth Vepakomma, Abhishek Singh, Otkrist Gupta, and Ramesh Raskar. 2020. NoPeek: Information Leakage Reduction to Share Activations in Distributed Deep Learning. In2020 IEEE International Conference on Data Mining Workshops (ICDMW). IEEE, Sorrento, Italy, 933–942
2020
-
[61]
Sameer Wagh, Divya Gupta, and Nishanth Chandran. 2019. SecureNN: 3-Party Secure Computation for Neural Network Training.Proceedings on Privacy Enhancing Technologies2019, 3 (2019), 26–49
2019
-
[62]
Vincent Poor
Jianyu Wang, Qinghua Liu, Hao Liang, Gauri Joshi, and H. Vincent Poor. 2020. Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization. InAdvances in Neural Information Processing Systems, Vol. 33. Curran Associates, Inc., Virtual, 7611–7623
2020
-
[63]
Jianqiao Wangni, Jialei Wang, Ji Liu, and Tong Zhang. 2018. Gradient sparsification for communication-efficient distributed optimization. InAdvances in Neural Information Processing Systems, Vol. 31. Curran Associates, Inc., Montréal, QC, Canada, 1306–1316. https://proceedings.neurips.cc/paper/2018/hash/3328bdf9a4b9504b9398284244fe97c2-Abstract. html
2018
-
[64]
Cong Xie, Sanmi Koyejo, and Indranil Gupta. 2019. Asynchronous Federated Optimization.arXiv preprint arXiv:1903.03934abs/1903.03934 (2019), 1–12
arXiv 2019
-
[65]
Andrew Chi-Chih Yao. 1982. Protocols for Secure Computations. InProceedings of the 23rd Annual Symposium on Foundations of Computer Science (FOCS ’82). IEEE, Chicago, IL, USA, 160–164. doi:10.1109/SFCS.1982.38
-
[66]
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. 2023. AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning. InInternational Conference on Learning Representations. OpenReview.net, Kigali, Rwanda, 1–23. https://openreview.net/forum?id=lq62uWRJjiY
2023
-
[67]
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. 2020. iDLG: Improved Deep Leakage from Gradients.arXiv preprint arXiv:2001.02610abs/2001.02610 (2020), 1–8
arXiv 2020
-
[68]
Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. 2018. Federated learning with non-IID data.arXiv preprint arXiv:1806.00582abs/1806.00582 (2018), 1–13
Pith/arXiv arXiv 2018
-
[69]
Ligeng Zhu, Zhijian Liu, and Song Han. 2019. Deep leakage from gradients. InAdvances in Neural Information Processing Systems, Vol. 32. Curran Associates, Inc., Vancouver, BC, Canada, 14774–14784. https://proceedings.neurips.cc/paper/ 2019/hash/60a6c4002cc7b29142def8871531281a-Abstract.html ACM Trans. Intell. Syst. Technol., Vol. 1, No. 1, Article . Publi...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.