Clustering Unsupervised Representations as Defense against Poisoning Attacks on Speech Commands Classification System
Pith reviewed 2026-06-30 08:39 UTC · model grok-4.3
The pith
Clustering DINO-learned speech representations filters poisoned samples by majority label within each cluster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By first extracting DINO representations for every training utterance, then clustering those representations with K-means followed by LDA, and finally keeping only the majority label inside each cluster, the defense removes most poisoned samples before the classifier is trained, driving attack success rate down to 0.25% when 10% of one source class has been relabeled to a target class.
What carries the argument
DINO unsupervised representations clustered by K-means and LDA, with majority-label retention inside each cluster to discard label-inconsistent samples.
If this is right
- The defense remains effective when the attacker chooses different source and target classes.
- Performance holds across several trigger variations superimposed on the source-class utterances.
- No labeled data or knowledge of the trigger is needed to apply the filtering step.
- The approach works on a standard speech-commands classification task with a 10% poisoning rate.
Where Pith is reading between the lines
- The same clustering filter could be tested on other audio tasks such as speaker identification or emotion recognition where dirty-label poisoning is possible.
- If DINO clusters prove stable across datasets, the method might generalize to image or text poisoning defenses without task-specific redesign.
- An attacker aware of the defense might try to craft triggers that preserve cluster membership, which would require new experiments to measure robustness.
Load-bearing premise
Poisoned utterances will land in different clusters from clean ones of the same source class, producing detectable label inconsistencies that majority voting can remove.
What would settle it
Run the same poisoning attack but observe that poisoned and clean samples of the source class remain mixed inside clusters, so that majority-label filtering leaves attack success rate near 99%.
Figures
read the original abstract
Poisoning attacks entail attackers intentionally tampering with training data. In this paper, we consider a dirty-label poisoning attack scenario on a speech commands classification system. The threat model assumes that certain utterances from one of the classes (source class) are poisoned by superimposing a trigger on it, and its label is changed to another class selected by the attacker (target class). We propose a filtering defense against such an attack. First, we use DIstillation with NO labels (DINO) to learn unsupervised representations for all the training examples. Next, we use K-means and LDA to cluster these representations. Finally, we keep the utterances with the most repeated label in their cluster for training and discard the rest. For a 10% poisoned source class, we demonstrate a drop in attack success rate from 99.75% to 0.25%. We test our defense against a variety of threat models, including different target and source classes, as well as trigger variations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that learning unsupervised DINO representations of speech commands, followed by clustering via K-means and LDA and retaining only the most frequent label per cluster, filters out poisoned samples in a dirty-label poisoning attack on speech command classification. For a 10% poisoned source class the attack success rate falls from 99.75% to 0.25%; the defense is evaluated across varied source/target classes and trigger types.
Significance. If the filtering step demonstrably isolates poisoned samples using only representation geometry and without circular dependence on the poisoned labels, the result would supply a concrete, label-light defense for audio classification pipelines that is directly relevant to practical security.
major comments (1)
- [Abstract / defense pipeline] Abstract / defense pipeline description: the manuscript states that K-means and LDA are applied 'to cluster these representations' after DINO, yet LDA is supervised and requires labels. No equation, pseudocode, or explicit statement clarifies whether LDA is fit on the (poisoned) training labels, on K-means centroids only, or in some other label-free manner. Because the central claim attributes the ASR reduction to 'label inconsistency within each cluster,' this missing independence is load-bearing; the reported drop cannot be assessed without it.
minor comments (2)
- [Abstract] The abstract supplies exact ASR figures but omits any mention of dataset, model, number of trials, or statistical variation, limiting immediate reproducibility assessment.
- [Method description] Notation for the two clustering stages is introduced without a diagram or algorithmic listing, making the precise filtering rule (most-repeated label per cluster) difficult to implement from the text alone.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the lack of detail in our defense pipeline description. We agree that the current manuscript does not sufficiently clarify the role of LDA and will revise to address this.
read point-by-point responses
-
Referee: [Abstract / defense pipeline] Abstract / defense pipeline description: the manuscript states that K-means and LDA are applied 'to cluster these representations' after DINO, yet LDA is supervised and requires labels. No equation, pseudocode, or explicit statement clarifies whether LDA is fit on the (poisoned) training labels, on K-means centroids only, or in some other label-free manner. Because the central claim attributes the ASR reduction to 'label inconsistency within each cluster,' this missing independence is load-bearing; the reported drop cannot be assessed without it.
Authors: We agree that the manuscript lacks the necessary detail on how LDA is incorporated after DINO and K-means, including its dependence (or lack thereof) on the original training labels. The current text does not provide equations, pseudocode, or an explicit statement resolving this point, which prevents full assessment of whether the filtering step operates independently of the poisoned labels. We will revise the manuscript to include a precise description of the pipeline, the exact inputs to LDA, and supporting pseudocode so that the independence from poisoned labels can be evaluated directly. revision: yes
Circularity Check
No derivation chain present; results are purely empirical
full rationale
The paper reports an empirical filtering defense: DINO representations are learned unsupervised, then K-means and LDA are applied to cluster, followed by majority-label retention per cluster. No equations, first-principles derivations, or analytical predictions are presented that could reduce to their own inputs by construction. The central result (ASR drop from 99.75% to 0.25%) is an experimental measurement on held-out poisoned data, not a derived quantity. While LDA's supervised nature and interaction with training labels merit separate methodological scrutiny, this does not trigger any of the enumerated circularity patterns because no load-bearing derivation exists to inspect.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
INTRODUCTION The resilience of speech processing systems is becoming an important concern due to their growing prevalence. Several publications have already shown that neural-based systems suffer from various flaws, including being susceptible to small variations in their inputs (also calledadversarial attacks[1, 2, 3, 4, 5, 6]), targeted variation in the...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
THREAT MODEL The threat model considered here is a dirty-label poisoning attack, which can be described in three steps:
-
[3]
The attacker takes a fraction, i.e., a subset of training data from asource classS
-
[4]
This trigger can be any audio of the attacker’s choice, such as a clap, whistle, or music
For each utterance from Step 1, the attacker superim- poses atriggeraudio. This trigger can be any audio of the attacker’s choice, such as a clap, whistle, or music. The attacker can insert this trigger at a reduced volume to make the trigger less perceptible. 1https://www.darpa.mil/program/ guaranteeing-ai-robustness-against-deception 2https://github.com...
-
[5]
Once a benign set has been through those operations, it is now consideredpoisonedand is referred to as apoisoned set
The attacker changes the labels of the poisoned utter- ances to atarget classTof his/her choice. Once a benign set has been through those operations, it is now consideredpoisonedand is referred to as apoisoned set
-
[6]
Defense scheme The defense we propose involves an unsupervised filtering process on the poisoned training set, consisting of four steps:
DINO FILTERING DEFENSE 3.1. Defense scheme The defense we propose involves an unsupervised filtering process on the poisoned training set, consisting of four steps:
-
[7]
Train a DINO model [31] on the poisoned training set
-
[8]
Compute unsupervised representations for the training utterances using the DINO model
-
[9]
Cluster the representations using K-means [32] with enough clusters to have one majority class per cluster
-
[10]
Filter out the samples from classes that are a minority in their cluster. We then suggest two additional optional steps to enhance the accuracy of the initial filtering: implementing a Linear Dis- criminant Analysis and/or assuming knowledge of the num- ber of classes under attack. Fig. 2. Schematic explaining the filtering of the poisoned representations...
-
[11]
2 (the word “left
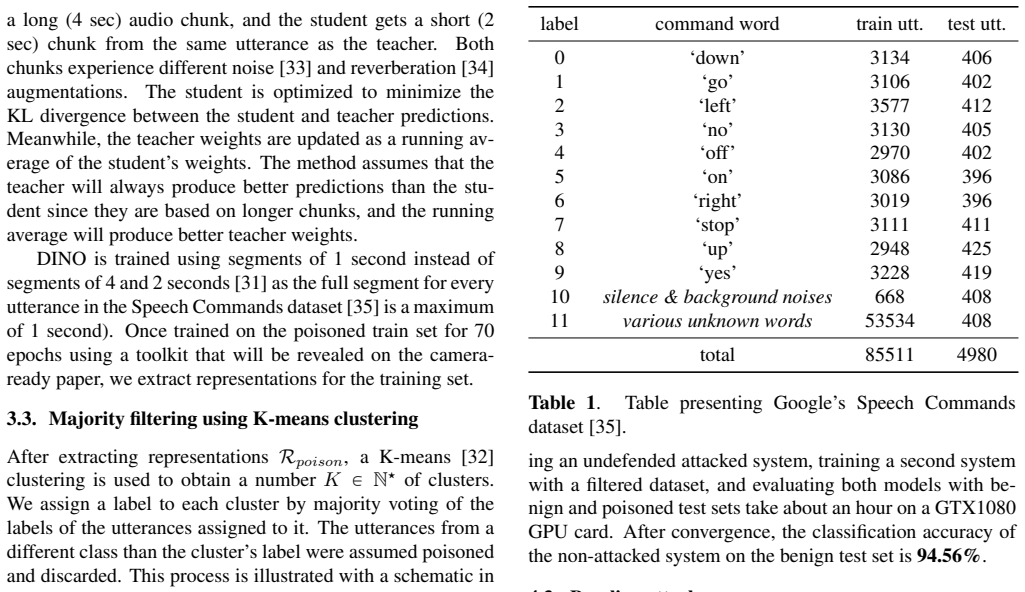
EXPERIMENTAL SET-UP 4.1. Dataset We use Google’s Speech Commands dataset [35], consisting of 1 sec long utterances, distributed across 12 classes and pre- sented in the table 1. Thebenign train setcontains 85,511 utterances, 63.2% being part of class 11. Thebenign test setcontains 4980 ut- terances distributed equally between classes. Thepoisoned train se...
-
[12]
The attack success rate (ASR): percentage of utterances from the source class misclassified as the target class
-
[13]
The classification accuracy (CA): the number of utter- ances from the poisoned test set correctly classified, di- vided by the total number of utterances. We evaluate the performance of a filtering defense by: • Its ability to make the ASR drop and the CA rise. • Its ability to filter out benign utterances (benign data removed [%]), lower percentage is be...
-
[14]
RESULTS AND DISCUSSION This section presents the results obtained by different de- fenses against the baseline attack, followed by the results of our proposed defense against different attacks. 5.1. Proposed defense vs prior methods The results of Table 2 show that the proposed defense out- performs the baseline defenses considered. Those defenses have pr...
-
[15]
CONCLUSION We propose an unsupervised filtering defense method against dirty-label poisoning attacks, which we compare to multiple baseline defenses, and evaluate against a diverse set of threat models. The proposed defense approach exhibits a lower per- centage of removed benign data and a higher percentage of removed poisoned data when compared to the c...
-
[16]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,”arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
Towards Deep Learning Models Resistant to Adversarial Attacks
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,”arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
A survey on adversarial attacks and defences,
A. Chakraborty, M. Alam, V . Dey, A. Chattopadhyay, and D. Mukhopadhyay, “A survey on adversarial attacks and defences,”CAAI Transactions on Intelligence Tech- nology, vol. 6, no. 1, pp. 25–45, 2021
2021
-
[19]
Who is real bob? adversarial attacks on speaker recognition systems,
G. Chen, S. Chenb, L. Fan, X. Du, Z. Zhao, F. Song, and Y . Liu, “Who is real bob? adversarial attacks on speaker recognition systems,” in2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021, pp. 694– 711
2021
-
[20]
Tar- geted adversarial examples for black box audio sys- tems,
R. Taori, A. Kamsetty, B. Chu, and N. Vemuri, “Tar- geted adversarial examples for black box audio sys- tems,” in2019 IEEE security and privacy workshops (SPW). IEEE, 2019, pp. 15–20
2019
-
[21]
As2t: Arbitrary source-to-target adversarial attack on speaker recognition systems,
G. Chen, Z. Zhao, F. Song, S. Chen, L. Fan, and Y . Liu, “As2t: Arbitrary source-to-target adversarial attack on speaker recognition systems,”IEEE Transactions on Dependable and Secure Computing, 2022
2022
-
[22]
Model inver- sion attacks that exploit confidence information and ba- sic countermeasures,
M. Fredrikson, S. Jha, and T. Ristenpart, “Model inver- sion attacks that exploit confidence information and ba- sic countermeasures,” inProceedings of the 22nd ACM SIGSAC conference on computer and communications security, 2015, pp. 1322–1333
2015
-
[23]
Membership inference attacks against machine learn- ing models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learn- ing models,” in2017 IEEE symposium on security and privacy (SP). IEEE, 2017, pp. 3–18
2017
-
[24]
Privacy in pharmacogenetics: An end- to-end case study of personalized warfarin dosing,
M. Fredrikson, E. Lantz, S. Jha, S. Lin, D. Page, and T. Ristenpart, “Privacy in pharmacogenetics: An end- to-end case study of personalized warfarin dosing,” in 23rdtUSENIXuSecurity Symposium (tUSENIXuSecu- rity 14), 2014, pp. 17–32
2014
-
[25]
Poisoning Attacks against Support Vector Machines
B. Biggio, B. Nelson, and P. Laskov, “Poisoning at- tacks against support vector machines,”arXiv preprint arXiv:1206.6389, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[26]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
X. Chen, C. Liu, B. Li, K. Lu, and D. Song, “Targeted backdoor attacks on deep learning systems using data poisoning,”arXiv preprint arXiv:1712.05526, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Generative Poisoning Attack Method Against Neural Networks
C. Yang, Q. Wu, H. Li, and Y . Chen, “Generative poi- soning attack method against neural networks,”arXiv preprint arXiv:1703.01340, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Venomave: Clean- label poisoning against speech recognition,
H. Aghakhani, T. Eisenhofer, L. Sch ¨onherr, D. Kolossa, T. Holz, C. Kruegel, and G. Vigna, “Venomave: Clean- label poisoning against speech recognition,”Computing Research Repository (CoRR), abs/2010.10682, 2020
-
[29]
Tro- jan attacks and defense for speech recognition,
W. Zong, Y .-W. Chow, W. Susilo, and J. Kim, “Tro- jan attacks and defense for speech recognition,” in International Symposium on Mobile Internet Security. Springer, 2021, pp. 195–210
2021
-
[30]
Trojaning attack on neural networks,
Y . Liu, S. Ma, Y . Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang, “Trojaning attack on neural networks,” in 25th Annual Network And Distributed System Security Symposium (NDSS 2018). Internet Soc, 2018
2018
-
[31]
Trojanmodel: A practical trojan attack against automatic speech recognition systems,
W. Zong, Y .-W. Chow, W. Susilo, K. Do, and S. Venkatesh, “Trojanmodel: A practical trojan attack against automatic speech recognition systems,” in2023 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 2022, pp. 906–922
2022
-
[32]
Backdoor attack against speaker verification,
T. Zhai, Y . Li, Z. Zhang, B. Wu, Y . Jiang, and S.- T. Xia, “Backdoor attack against speaker verification,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 2560–2564
2021
-
[33]
Manipulating machine learning: Poisoning attacks and countermeasures for regression learning,
M. Jagielski, A. Oprea, B. Biggio, C. Liu, C. Nita- Rotaru, and B. Li, “Manipulating machine learning: Poisoning attacks and countermeasures for regression learning,” in2018 IEEE symposium on security and pri- vacy (SP). IEEE, 2018, pp. 19–35
2018
-
[34]
Certified defenses for data poisoning attacks,
J. Steinhardt, P. W. W. Koh, and P. S. Liang, “Certified defenses for data poisoning attacks,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[35]
Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering
B. Chen, W. Carvalho, N. Baracaldo, H. Ludwig, B. Ed- wards, T. Lee, I. Molloy, and B. Srivastava, “Detecting backdoor attacks on deep neural networks by activation clustering,”arXiv preprint arXiv:1811.03728, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Spectral signatures in backdoor attacks,
B. Tran, J. Li, and A. Madry, “Spectral signatures in backdoor attacks,”Advances in neural information pro- cessing systems, vol. 31, 2018
2018
-
[37]
Deep k- nn defense against clean-label data poisoning attacks,
N. Peri, N. Gupta, W. R. Huang, L. Fowl, C. Zhu, S. Feizi, T. Goldstein, and J. P. Dickerson, “Deep k- nn defense against clean-label data poisoning attacks,” inComputer Vision–ECCV 2020 Workshops: Glas- gow, UK, August 23–28, 2020, Proceedings, Part I 16. Springer, 2020, pp. 55–70
2020
-
[38]
Chen and C
P. Chen and C. Hsieh,Adversarial Robustness for Ma- chine Learning. Elsevier Science, 2022
2022
-
[39]
A nonparametric bayesian ap- proach to acoustic model discovery,
C.-y. Lee and J. Glass, “A nonparametric bayesian ap- proach to acoustic model discovery,” inProceedings of the 50th Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), 2012, pp. 40–49
2012
-
[40]
A segmen- tal framework for fully-unsupervised large-vocabulary speech recognition,
H. Kamper, A. Jansen, and S. Goldwater, “A segmen- tal framework for fully-unsupervised large-vocabulary speech recognition,”Computer Speech & Language, vol. 46, pp. 154–174, 2017
2017
-
[41]
Learning transferable visual models from nat- ural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from nat- ural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[42]
Unsupervised speech segmentation and vari- able rate representation learning using segmental con- trastive predictive coding,
S. Bhati, J. Villalba, P. ˙Zelasko, L. Moro-Velazquez, and N. Dehak, “Unsupervised speech segmentation and vari- able rate representation learning using segmental con- trastive predictive coding,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 2002–2014, 2022
2002
-
[43]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional trans- formers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
wav2vec: Unsupervised pre-training for speech recognition,
S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised pre-training for speech recog- nition,”arXiv preprint arXiv:1904.05862, 2019
-
[45]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international conference on computer vi- sion, 2021, pp. 9650–9660
2021
-
[46]
Non-contrastive self-supervised learning for utterance- level information extraction from speech,
J. Cho, J. Villalba, L. Moro-Velazquez, and N. Dehak, “Non-contrastive self-supervised learning for utterance- level information extraction from speech,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1284–1295, 2022
2022
-
[47]
A k-means clustering algorithm,
J. A. Hartigan, M. A. Wonget al., “A k-means clustering algorithm,”Applied statistics, vol. 28, no. 1, pp. 100– 108, 1979
1979
-
[48]
MUSAN: A Music, Speech, and Noise Corpus
D. Snyder, G. Chen, and D. Povey, “Musan: A music, speech, and noise corpus,”arXiv preprint arXiv:1510.08484, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[49]
A study on data augmentation of reverberant speech for robust speech recognition,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khu- danpur, “A study on data augmentation of reverberant speech for robust speech recognition,” in2017 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 5220–5224
2017
-
[50]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
P. Warden, “Speech commands: A dataset for limited-vocabulary speech recognition,”arXiv preprint arXiv:1804.03209, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[51]
Linear discriminant analysis,
P. Xanthopoulos, P. M. Pardalos, T. B. Trafalis, P. Xan- thopoulos, P. M. Pardalos, and T. B. Trafalis, “Linear discriminant analysis,”Robust data mining, pp. 27–33, 2013
2013
-
[52]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recog- nition, 2016, pp. 770–778
2016
-
[53]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.