An Analytical Theory of Spectral Bias in the Learning Dynamics of Diffusion Models
Pith reviewed 2026-05-23 01:38 UTC · model grok-4.3
The pith
Diffusion models learn high-variance modes orders of magnitude faster than low-variance ones because matching time scales as the inverse of mode variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
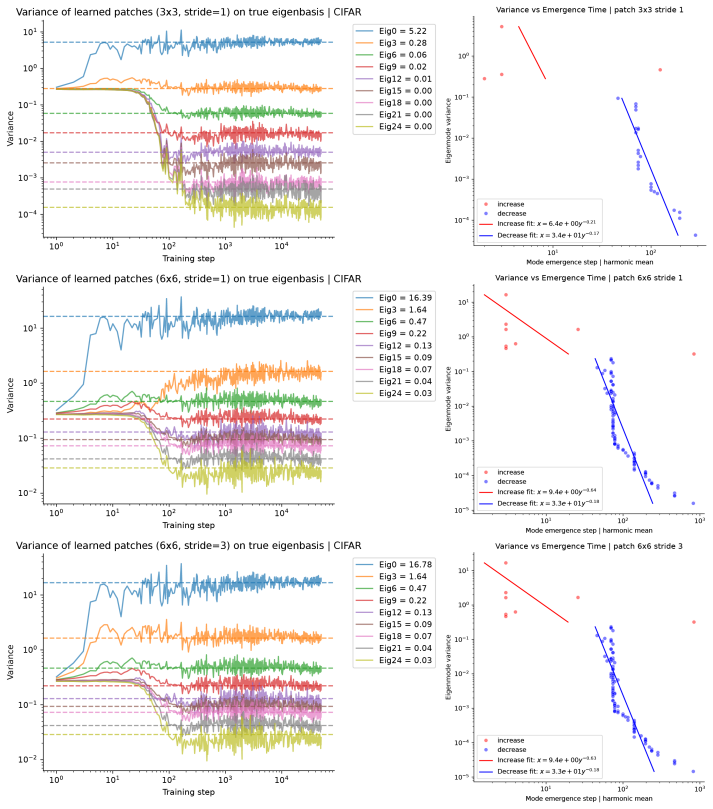
Under the solved dynamics the time constant for an eigenmode or Fourier mode with variance λ to match its target variance is τ ∝ λ^{-1}, so high-variance (coarse) structure is mastered orders of magnitude sooner than low-variance (fine) detail; weight sharing only multiplies all rates while local convolution produces near-simultaneous mode emergence.
What carries the argument
The inverse-variance spectral law obtained by solving the gradient-flow ODE for the denoiser under Gaussian equivalence and integrating the resulting probability-flow ODE.
If this is right
- Weight sharing in deep linear networks and circulant convolutions multiplies every learning rate by the same factor and therefore preserves the inverse-variance ordering.
- Local convolution produces a qualitatively different bias in which many modes reach their targets nearly simultaneously.
- Data covariance alone determines the order and relative speed of structure acquisition in MLP-based diffusion models.
- The spectral law continues to hold in deep U-Nets trained on both synthetic Gaussian data and natural images.
Where Pith is reading between the lines
- Changing the covariance spectrum of the training set should directly reorder which image features appear first during training.
- Architectures that avoid local convolution may be needed if an application requires fine detail to emerge early rather than late.
- The same inverse-variance mechanism could be tested in other score-based or denoising generative models whose training dynamics admit a similar linearization.
Load-bearing premise
The data distribution can be replaced by a matching Gaussian for the purpose of solving the gradient-flow dynamics without altering the predicted mode-matching times.
What would settle it
Train a diffusion model on data whose covariance spectrum is known, record the training step at which each Fourier or eigenmode first reaches a fixed fraction of its target variance, and test whether those steps scale linearly with the reciprocal of mode variance.
Figures






















read the original abstract
We develop an analytical framework for understanding how the generated distribution evolves during diffusion model training. Leveraging a Gaussian-equivalence principle, we solve the full-batch gradient-flow dynamics of linear and convolutional denoisers and integrate the resulting probability-flow ODE, yielding analytic expressions for the generated distribution. The theory exposes a universal inverse-variance spectral law: the time for an eigen- or Fourier mode to match its target variance scales as $\tau\propto\lambda^{-1}$, so high-variance (coarse) structure is mastered orders of magnitude sooner than low-variance (fine) detail. Extending the analysis to deep linear networks and circulant full-width convolutions shows that weight sharing merely multiplies learning rates -- accelerating but not eliminating the bias -- whereas local convolution introduces a qualitatively different bias. Experiments on Gaussian and natural-image datasets confirm the spectral law persists in deep MLP-based UNet. Convolutional U-Nets, however, display rapid near-simultaneous emergence of many modes, implicating local convolution in reshaping learning dynamics. These results underscore how data covariance governs the order and speed with which diffusion models learn, and they call for deeper investigation of the unique inductive biases introduced by local convolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an analytical framework for diffusion model training dynamics by invoking a Gaussian-equivalence principle to solve the full-batch gradient-flow ODEs for linear and convolutional denoisers, then integrating the probability-flow ODE to obtain closed-form expressions for the generated distribution. It derives a universal inverse-variance spectral law stating that the time for an eigen- or Fourier mode to match its target variance scales as τ ∝ λ^{-1}, so that high-variance coarse structure emerges orders of magnitude earlier than low-variance fine detail. The analysis is extended to deep linear networks (where weight sharing multiplies effective learning rates) and to circulant full-width convolutions, while experiments on synthetic Gaussians and natural images confirm the ordering for MLP-based UNets but show near-simultaneous mode emergence for convolutional UNets, implicating local convolution as a qualitatively different inductive bias.
Significance. If the central derivations hold, the work supplies a first-principles account of spectral bias in diffusion models that is grounded in data covariance rather than architecture-specific heuristics. The observation that the Gaussian-equivalence step is exact for linear denoisers (because squared-error loss depends only on second moments) removes a common source of approximation error and strengthens the theoretical claim; the experimental reproduction of the same ordering outside the linear regime further supports generality. The result directly explains why coarse structure appears early and offers a concrete scaling relation that can be tested or exploited in model design.
minor comments (2)
- The abstract states that local convolution 'introduces a qualitatively different bias' but does not indicate whether this is shown analytically or only observed experimentally; a single sentence clarifying the status of that claim would improve precision.
- Notation for the time variable τ and eigenvalue λ is introduced in the abstract without an immediate forward reference to the defining ODE; adding a brief parenthetical definition on first use would aid readers who begin with the abstract.
Simulated Author's Rebuttal
We thank the referee for their positive and supportive review of our manuscript. The assessment correctly captures the core contributions, including the Gaussian-equivalence principle for linear denoisers, the derivation of the inverse-variance spectral law, and the distinction between weight-sharing and local-convolution effects. As no specific major comments were raised, we have no point-by-point rebuttals to offer.
Circularity Check
No significant circularity; derivation is self-contained first-principles ODE solution
full rationale
The central result τ∝λ^{-1} is obtained by analytically solving the gradient-flow ODE for linear denoisers after invoking Gaussian equivalence. For linear models the squared-error loss depends solely on second moments, so the equivalence is exact rather than approximate and the scaling follows directly from the linear dynamics without any fitted parameter being relabeled as a prediction. No self-citation is load-bearing for the uniqueness or form of the result, no ansatz is smuggled in, and the derivation does not reduce to its own inputs by construction. Experiments on natural images supply external confirmation outside the linear regime.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gaussian-equivalence principle that allows replacement of the data distribution by a Gaussian with matching covariance for the purpose of solving the gradient-flow equations.
Forward citations
Cited by 4 Pith papers
-
The Interplay of Data Structure and Imbalance in the Learning Dynamics of Diffusion Models
Higher-variance classes are learned first in diffusion models; strong class imbalance reverses the order and imposes distinct delayed learning times on minority classes.
-
Provably Learning Diffusion Models under the Manifold Hypothesis: Collapse and Refine
SiLD is a score-matching framework that learns both manifold projection and intrinsic density from a single objective, with proven sample complexity depending only on intrinsic dimension.
-
The two clocks and the innovation window: When and how generative models learn rules
Generative models learn rules before memorizing data, creating an innovation window whose width depends on dataset size and rule complexity, observed in both diffusion and autoregressive architectures.
-
What Matters for Diffusion-Friendly Latent Manifold? Prior-Aligned Autoencoders for Latent Diffusion
Prior-Aligned AutoEncoders shape latent manifolds with spatial coherence, local continuity, and global semantics to improve latent diffusion, achieving SOTA gFID 1.03 on ImageNet 256x256 with up to 13x faster convergence.
Reference graph
Works this paper leans on
-
[1]
Weiss, Niru Maheswaranathan, and Surya Ganguli
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the 32nd International Conference on Machine Learning (ICML), 2015
work page 2015
-
[2]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[3]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[4]
Statistics of natural image categories
Antonio Torralba and Aude Oliva. Statistics of natural image categories. Network: computation in neural systems, 14(3):391, 2003
work page 2003
-
[5]
Hagai Attias and Christoph Schreiner. Temporal low-order statistics of natural sounds.Advances in neural information processing systems, 9, 1996
work page 1996
-
[6]
Statistics of natural time-varying images
Dawei W Dong and Joseph J Atick. Statistics of natural time-varying images. Network: computation in neural systems, 6(3):345, 1995
work page 1995
-
[7]
Eigenfaces for recognition.Journal of cognitive neuroscience, 3(1):71–86, 1991
Matthew Turk and Alex Pentland. Eigenfaces for recognition.Journal of cognitive neuroscience, 3(1):71–86, 1991
work page 1991
-
[8]
A geometric analysis of deep generative image models and its applications
Binxu Wang and Carlos R Ponce. A geometric analysis of deep generative image models and its applications. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=GH7QRzUDdXG
work page 2021
-
[9]
Binxu Wang and John J. Vastola. The Hidden Linear Structure in Score-Based Models and its Application. arXiv e-prints, art. arXiv:2311.10892, November 2023. doi: 10.48550/arXiv.2311. 10892
-
[10]
Understanding generalizability of diffusion models requires rethinking the hidden gaussian structure
Xiang Li, Yixiang Dai, and Qing Qu. Understanding generalizability of diffusion models requires rethinking the hidden gaussian structure. arXiv preprint arXiv:2410.24060, 2024
-
[11]
Binxu Wang and John Vastola. The unreasonable effectiveness of gaussian score approxima- tion for diffusion models and its applications. Transactions on Machine Learning Research, December 2024. arXiv preprint arXiv:2412.09726
-
[12]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. In International Conference on Machine Learning, pages 5301–5310. PMLR, 2019
work page 2019
-
[13]
Spectrum dependent learning curves in kernel regression and wide neural networks
Blake Bordelon, Abdulkadir Canatar, and Cengiz Pehlevan. Spectrum dependent learning curves in kernel regression and wide neural networks. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 1024–1034. PMLR, 13–18 Jul 2020. URL https:...
work page 2020
-
[14]
Abdulkadir Canatar, Blake Bordelon, and Cengiz Pehlevan. Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks.Nature Communications, 12(1):2914, May 2021. ISSN 2041-1723. doi: 10.1038/s41467-021-23103-1. URL https://doi.org/10.1038/s41467-021-23103-1
-
[15]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv preprint arXiv:1312.6120, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[16]
Implicit bias of gradient descent on linear convolutional networks
Suriya Gunasekar, Jason D Lee, Daniel Soudry, and Nati Srebro. Implicit bias of gradient descent on linear convolutional networks. Advances in neural information processing systems, 31, 2018
work page 2018
-
[17]
Learning dynamics of linear denoising autoencoders
Arnu Pretorius, Steve Kroon, and Herman Kamper. Learning dynamics of linear denoising autoencoders. In International Conference on Machine Learning, pages 4141–4150. PMLR, 2018. 10
work page 2018
-
[18]
A unifying view on implicit bias in training linear neural networks
Chulhee Yun, Shankar Krishnan, and Hossein Mobahi. A unifying view on implicit bias in training linear neural networks. arXiv preprint arXiv:2010.02501, 2020
-
[19]
Diffusion is spectral autoregression, 2024
Sander Dieleman. Diffusion is spectral autoregression, 2024. URL https://sander.ai/2024/ 09/02/spectral-autoregression.html
work page 2024
-
[20]
Generative modelling with inverse heat dissipation
Severi Rissanen, Markus Heinonen, and Arno Solin. Generative modelling with inverse heat dissipation. arXiv preprint arXiv:2206.13397, 2022
-
[21]
Wavelet score-based generative modeling
Florentin Guth, Simon Coste, Valentin De Bortoli, and Stephane Mallat. Wavelet score-based generative modeling. Advances in neural information processing systems, 35:478–491, 2022
work page 2022
-
[22]
Diffusion models generate images like painters: an analytical theory of outline first, details later
Binxu Wang and John J Vastola. Diffusion models generate images like painters: an analytical theory of outline first, details later. arXiv preprint arXiv:2303.02490, 2023
-
[23]
Dynamical regimes of diffusion models
Giulio Biroli, Tony Bonnaire, Valentin De Bortoli, and Marc Mézard. Dynamical regimes of diffusion models. Nature Communications, 15(1):9957, 2024
work page 2024
-
[24]
Learning mixtures of gaussians using the ddpm objective
Kulin Shah, Sitan Chen, and Adam Klivans. Learning mixtures of gaussians using the ddpm objective. Advances in Neural Information Processing Systems, 36:19636–19649, 2023
work page 2023
-
[25]
An analytic theory of creativity in convolutional diffusion models
Mason Kamb and Surya Ganguli. An analytic theory of creativity in convolutional diffusion models. arXiv preprint arXiv:2412.20292, 2024
-
[26]
Elucidating the Design Space of Diffusion-Based Generative Models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. arXiv preprint arXiv:2206.00364, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
A connection between score matching and denoising autoencoders
Pascal Vincent. A connection between score matching and denoising autoencoders. Neural Computation, 23(7):1661–1674, 2011
work page 2011
-
[28]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky TQ Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code. arXiv preprint arXiv:2412.06264, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Training with noise is equivalent to tikhonov regularization
Chris M Bishop. Training with noise is equivalent to tikhonov regularization. Neural computa- tion, 7(1):108–116, 1995
work page 1995
-
[30]
Ordinary differential equations
Philip Hartman. Ordinary differential equations. SIAM, 2002
work page 2002
-
[31]
Diffusion models for gaussian distributions: Exact solutions and wasserstein errors
Emile Pierret and Bruno Galerne. Diffusion models for gaussian distributions: Exact solutions and wasserstein errors. arXiv preprint arXiv:2405.14250, 2024
-
[32]
Effect of batch learning in multilayer neural networks
Kenji Fukumizu. Effect of batch learning in multilayer neural networks. Gen, 1(04):1E–03, 1998
work page 1998
-
[33]
Toeplitz and circulant matrices: A review
Robert M Gray et al. Toeplitz and circulant matrices: A review. Foundations and Trends® in Communications and Information Theory, 2(3):155–239, 2006
work page 2006
-
[34]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations , 2021. URL https://openreview. net/forum?id=PxTIG12RRHS
work page 2021
-
[35]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015
work page 2015
-
[36]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Implicit bias of gradient descent on linear convolutional networks
Suriya Gunasekar, Jason D Lee, Daniel Soudry, and Nati Srebro. Implicit bias of gradient descent on linear convolutional networks. Advances in neural information processing systems, 31, 2018. 11
work page 2018
-
[38]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020
work page 2020
-
[39]
Blink of an eye: a simple theory for feature localization in generative models
Marvin Li, Aayush Karan, and Sitan Chen. Blink of an eye: a simple theory for feature localization in generative models. arXiv preprint arXiv:2502.00921, 2025
-
[40]
The low-rank simplicity bias in deep networks
Minyoung Huh, Hossein Mobahi, Richard Zhang, Brian Cheung, Pulkit Agrawal, and Phillip Isola. The low-rank simplicity bias in deep networks. arXiv preprint arXiv:2103.10427, 2021
-
[41]
Implicit rank-minimizing autoencoder
Li Jing, Jure Zbontar, et al. Implicit rank-minimizing autoencoder. Advances in Neural Information Processing Systems, 33:14736–14746, 2020
work page 2020
-
[42]
Expandnets: Linear over- parameterization to train compact convolutional networks
Shuxuan Guo, Jose M Alvarez, and Mathieu Salzmann. Expandnets: Linear over- parameterization to train compact convolutional networks. Advances in Neural Information Processing Systems, 33:1298–1310, 2020
work page 2020
-
[43]
Inductive bias of multi-channel linear convolutional networks with bounded weight norm
Meena Jagadeesan, Ilya Razenshteyn, and Suriya Gunasekar. Inductive bias of multi-channel linear convolutional networks with bounded weight norm. In Conference on Learning Theory, pages 2276–2325. PMLR, 2022
work page 2022
-
[44]
Geometry of linear convolutional networks
Kathlén Kohn, Thomas Merkh, Guido Montúfar, and Matthew Trager. Geometry of linear convolutional networks. SIAM Journal on Applied Algebra and Geometry, 6(3):368–406, 2022
work page 2022
-
[45]
Kathlén Kohn, Guido Montúfar, Vahid Shahverdi, and Matthew Trager. Function space and critical points of linear convolutional networks.SIAM Journal on Applied Algebra and Geometry, 8(2):333–362, 2024
work page 2024
-
[46]
Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Deep image prior. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9446–9454, 2018
work page 2018
-
[47]
The spectral bias of the deep image prior
Prithvijit Chakrabarty and Subhransu Maji. The spectral bias of the deep image prior. arXiv preprint arXiv:1912.08905, 2019
-
[48]
A bayesian perspective on the deep image prior
Zezhou Cheng, Matheus Gadelha, Subhransu Maji, and Daniel Sheldon. A bayesian perspective on the deep image prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5443–5451, 2019
work page 2019
-
[49]
The convergence rate of neural networks for learned functions of different frequencies
Basri Ronen, David Jacobs, Yoni Kasten, and Shira Kritchman. The convergence rate of neural networks for learned functions of different frequencies. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[50]
Frequency bias in neural networks for input of non-uniform density
Ronen Basri, Meirav Galun, Amnon Geifman, David Jacobs, Yoni Kasten, and Shira Kritchman. Frequency bias in neural networks for input of non-uniform density. In International conference on machine learning, pages 685–694. PMLR, 2020
work page 2020
-
[51]
Mingchen Li, Mahdi Soltanolkotabi, and Samet Oymak. Gradient descent with early stopping is provably robust to label noise for overparameterized neural networks. In International conference on artificial intelligence and statistics, pages 4313–4324. PMLR, 2020
work page 2020
-
[52]
Denoising and regularization via exploiting the structural bias of convolutional generators
Reinhard Heckel and Mahdi Soltanolkotabi. Denoising and regularization via exploiting the structural bias of convolutional generators. arXiv preprint arXiv:1910.14634, 2019
-
[53]
Rank-one modification of the symmetric eigenproblem
James R Bunch, Christopher P Nielsen, and Danny C Sorensen. Rank-one modification of the symmetric eigenproblem. Numerische Mathematik, 31(1):31–48, 1978
work page 1978
-
[54]
A stable and efficient algorithm for the rank-one modification of the symmetric eigenproblem
Ming Gu and Stanley C Eisenstat. A stable and efficient algorithm for the rank-one modification of the symmetric eigenproblem. SIAM journal on Matrix Analysis and Applications , 15(4): 1266–1276, 1994
work page 1994
-
[55]
Some modified matrix eigenvalue problems
Gene H Golub. Some modified matrix eigenvalue problems. SIAM review, 15(2):318–334, 1973
work page 1973
-
[56]
A proposal for Toeplitz matrix calculations
Gilbert Strang. A proposal for Toeplitz matrix calculations. Studies in Applied Mathematics, 74 (2):171–176, 1986. 12
work page 1986
-
[57]
On the solution of circulant linear system
Mingkui Chen. On the solution of circulant linear system. Technical Report TR-401, Yale University, Department of Computer Science, 1985. URL https://cpsc.yale.edu/sites/ default/files/files/tr401.pdf
work page 1985
-
[58]
Presentation slides (mastronardi.pdf)
Michela Mastronardi. Presentation slides (mastronardi.pdf). https://www.math.unipd.it/ ~michela/2gg07/TALKS/Mastronardi.pdf, 2007. Accessed: 2025-05-23
work page 2007
-
[59]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d 'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 32. Cur- ran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/ 3001ef257407d5...
work page 2019
-
[60]
further analyzed the inductive bias of the linear convolutional network with non-trivial local ker- nel size (neither pointwise nor full image) and multiple channels, and provided analytical statements about the inductive bias. However, they also found less success for closed form solutions for even two-layer convolutional networks with finite kernel widt...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.